
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 30
30
 4
4


感谢 LB 学长的博文! 。
后缀是指从某个位置 \(i\) 开始到整个串末尾结束的一个特殊子串,也就是 \(S[i \dots|S|-1]\) .
计数排序 - OI Wiki (oi-wiki.org) 。
基数排序 - OI Wiki (oi-wiki.org) 。
后缀数组最主要的两个数组是 sa 和 rk .
sa 表示将所有后缀排序后第 \(i\) 小的后缀的编号,即编号数组.
rk 表示后缀 \(i\) 的排名,即排名数组.
这两个数组满足一个重要性质: sa[rk[i]] = rk[sa[i]] = i .
示例:
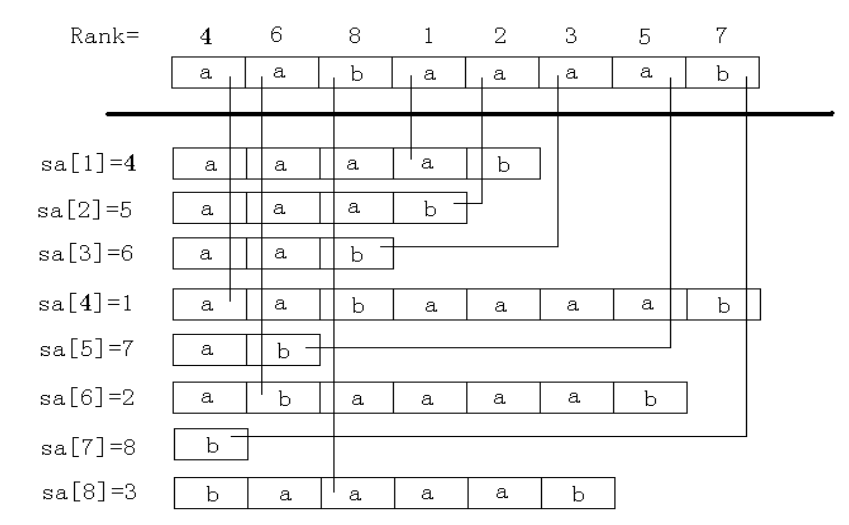
这个图很好理解.
将所有的后缀数组都 sort 一遍, sort 复杂度为 \(O_{n \log n}\) ,字符串比较复杂度为 \(O_{n}\) ,总的复杂度 \(O_{n^2 \log n}\) .
/*
The code was written by yifan, and yifan is neutral!!!
*/
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
template<typename T>
inline T read() {
T x = 0;
bool fg = 0;
char ch = getchar();
while (ch < '0' || ch > '9') {
fg |= (ch == '-');
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = (x << 3) + (x << 1) + (ch ^ 48);
ch = getchar();
}
return fg ? ~x + 1 : x;
}
const int N = 1e6 + 5;
int n;
char s[N];
string h[N];
pair<string, int> ans[N];
int main() {
scanf("%s", s + 1);
n = strlen(s + 1);
for (int i = 1; i <= n; ++ i) {
for (int j = i; j <= n; ++ j) {
h[i] += s[j];
}
ans[i] = {h[i], i};
}
sort(ans + 1, ans + n + 1);
for (int i = 1; i <= n; ++ i) {
cout << ans[i].second << ' ';
}
return 0;
}
先对长度为 \(1\) 的所有子串,即每个字符排序,得到排序后的 sa1 和 rk1 数组.
之后倍增:
用两个长度为 \(1\) 的子串的排名,即 rk1[i] 和 rk1[i + 1] ,作为排序的第一关键词和第二关键词,这样就可以对每个长度为 \(2\) 的子串进行排序,得到 sa2 和 rk2 ; 。
之后用两个长度为 \(2\) 的子串的排名,即 rk2[i] 和 rk2[i + 2] ,来作为排序的第一关键词和第二关键词。(为什么是 \(i + 2\) 呢,因为 rk2[i] 和 rk2[i + 1] 重复了 \(S_{i + 1}\) )这样就可以对每个长度为 \(4\) 的子串进行排序,得到 sa4 和 rk4 ; 。
重复上面的操作,用两个长度为 \(\dfrac{w}{2}\) 的子串的排名,即 rk[i] 和 rk[i + (w / 2)] ,来作为排序的第一关键词和第二关键词,直到 \(w \ge n\) ,最终得到的 sa 数组就是我们的答案数组.
示意图:

倍增的复杂度为 \(O_{\log n}\) , sort 复杂度为 \(O_{n \log n}\) ,总的复杂度 \(O_{n \log ^ 2 n}\) .
发现后缀数组值域即为 \(n\) ,又是多关键字排序,考虑基数排序。 上面已经给出一个用于比较的式子: (A[i] < A[j] or (A[i] = A[j] and B[i] < B[j])) ,倍增过程中 A[i], B[i] 大小关系已知,先将 B[i] 作为第二关键字排序,再将 A[i] 作为第一关键字排序,两次计数排序实现即可。 单次计数排序复杂度 \(O_{n+w}\) ( \(w\) 为值域,显然最大与 \(n\) 同阶),总时间复杂度变为 \(O_{n \log n}\) .
/*
The code was written by yifan, and yifan is neutral!!!
*/
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
template<typename T>
inline T read() {
T x = 0;
bool fg = 0;
char ch = getchar();
while (ch < '0' || ch > '9') {
fg |= (ch == '-');
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = (x << 3) + (x << 1) + (ch ^ 48);
ch = getchar();
}
return fg ? ~x + 1 : x;
}
const int N = 1e6 + 5;
int n, m;
int sa[N], oldsa[N], rk[N << 1], oldrk[N << 1], cnt[N];
// rk 第 i 个后缀的排名,sa 第 i 小的后缀的编号
char s[N];
int main() {
scanf("%s", s + 1);
n = strlen(s + 1);
m = 127;
/*--------------------------------*/
// 计数排序
for (int i = 1; i <= n; ++ i) {
++ cnt[rk[i] = s[i]];
}
for (int i = 1; i <= m; ++ i) {
cnt[i] += cnt[i - 1];
}
for (int i = n; i >= 1; -- i) {
sa[cnt[rk[i]] --] = i;
}
memcpy(oldrk + 1, rk + 1, n * sizeof(int));
/*--------------------------------*/
// 判重
for (int cur = 0, i = 1; i <= n; ++ i) {
if (oldrk[sa[i]] == oldrk[sa[i - 1]]) {
rk[sa[i]] = cur;
}
else {
rk[sa[i]] = ++ cur;
}
}
/*--------------------------------*/
for (int w = 1; w < n; w <<= 1, m = n) {
// 先按照第二关键词计数排序
memset(cnt, 0, sizeof cnt);
memcpy(oldsa + 1, sa + 1, n * sizeof(int));
for (int i = 1; i <= n; ++ i) {
++ cnt[rk[oldsa[i] + w]];
}
for (int i = 1; i <= m; ++ i) {
cnt[i] += cnt[i - 1];
}
for (int i = n; i >= 1; -- i) {
sa[cnt[rk[oldsa[i] + w]] --] = oldsa[i];
}
/*--------------------------------*/
// 再按照第一关键词计数排序
memset(cnt, 0, sizeof cnt);
memcpy(oldsa + 1, sa + 1, n * sizeof(int));
for (int i = 1; i <= n; ++ i) {
++ cnt[rk[oldsa[i]]];
}
for (int i = 1; i <= m; ++ i) {
cnt[i] += cnt[i - 1];
}
for (int i = n; i >= 1; -- i) {
sa[cnt[rk[oldsa[i]]] --] = oldsa[i];
}
/*--------------------------------*/
// 更新数组
memcpy(oldrk + 1, rk + 1, n * sizeof(int));
for (int cur = 0, i = 1; i <= n; ++ i) {
if (oldrk[sa[i]] == oldrk[sa[i - 1]] && oldrk[sa[i] + w] == oldrk[sa[i - 1] + w]) {
rk[sa[i]] = cur;
}
else {
rk[sa[i]] = ++ cur;
}
}
}
for (int i = 1; i <= n; ++ i) {
printf("%d ", sa[i]);
}
return 0;
}
sa 的最前面,在本次排序中, \(S[sa_i \dots sa_i+2^k−1]\) 是长度为 \(2^k\) 的子串 \(S[sai−2^k−1 \dots sai+2^k−1]\) 的后半截, sa[i] 的排名将作为排序的关键字。
for (p = 0, i = n; i > n - w; -- i) {
oldsa[++ p] = i;
}
for (int i = 1; i <= n; ++ i) {
if (sa[i] > w) { // 保证 sa[i] 是后半截的编号
oldsa[++ p] = sa[i] - w; // sa[i] 一定是后半截的编号,而我们要存的是前半截的开始编号
}
}
减小值域,每次对 rk 进行更新之后,我们都计算了一个 \(p\) ,这个 \(p\) 即是 rk 的值域,将值域改成它即可.
将 rk[id[i]] 存下来,减少不连续内存访问.
用函数 cmp 来计算是否重复.
若排名都不相同可直接生成后缀数组.
/*
The code was written by yifan, and yifan is neutral!!!
*/
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
template<typename T>
inline T read() {
T x = 0;
bool fg = 0;
char ch = getchar();
while (ch < '0' || ch > '9') {
fg |= (ch == '-');
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = (x << 3) + (x << 1) + (ch ^ 48);
ch = getchar();
}
return fg ? ~x + 1 : x;
}
const int N = 1e6 + 5;
int n, m;
int sa[N], oldsa[N], rk[N << 1], oldrk[N << 1], cnt[N], key[N];
// rk 第 i 个后缀的排名,sa 第 i 小的后缀的编号
char s[N];
inline bool cmp(int x, int y, int w) {
return oldrk[x] == oldrk[y] && oldrk[x + w] == oldrk[y + w];
}
int main() {
int i, p = 0;
scanf("%s", s + 1);
n = strlen(s + 1);
m = 127;
for (int i = 1; i <= n; ++ i) {
++ cnt[rk[i] = s[i]];
}
for (int i = 1; i <= m; ++ i) {
cnt[i] += cnt[i - 1];
}
for (int i = n; i >= 1; -- i) {
sa[cnt[rk[i]] --] = i;
}
for (int w = 1; ; w <<= 1, m = p) {
for (p = 0, i = n; i > n - w; -- i) {
oldsa[++ p] = i;
}
for (int i = 1; i <= n; ++ i) {
if (sa[i] > w) { // 保证 sa[i] 是后半截的编号
oldsa[++ p] = sa[i] - w; // sa[i] 一定是后半截的编号,而我们要存的是前半截的开始编号
}
}
memset(cnt, 0, sizeof cnt);
for (i = 1; i <= n; ++ i) {
++ cnt[key[i] = rk[oldsa[i]]];
}
for (i = 1; i <= m; ++ i) {
cnt[i] += cnt[i - 1];
}
for (i = n; i >= 1; -- i) {
sa[cnt[key[i]] --] = oldsa[i];
}
memcpy(oldrk + 1, rk + 1, n * sizeof(int));
for (p = 0, i = 1; i <= n; ++ i) {
rk[sa[i]] = cmp(sa[i], sa[i - 1], w) ? p : ++ p;
}
if (p == n) {
break ;
}
}
for (int i = 1; i <= n; ++ i) {
printf("%d ", sa[i]);
}
return 0;
}
后缀数组简介 - OI Wiki (oi-wiki.org) 。
「笔记」后缀数组 - Luckyblock - 博客园 (cnblogs.com) 。
最后此篇关于「学习笔记」后缀数组的文章就讲到这里了,如果你想了解更多关于「学习笔记」后缀数组的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
30
4
 0
0
关闭。这个问题是opinion-based .它目前不接受答案。 想要改进这个问题? 更新问题,以便 editing this post 可以用事实和引用来回答它. 关闭 9 年前。 Improve
介绍篇 什么是MiniApis? MiniApis的特点和优势 MiniApis的应用场景 环境搭建 系统要求 安装MiniApis 配置开发环境 基础概念 MiniApis架构概述
我正在从“JavaScript 圣经”一书中学习 javascript,但我遇到了一些困难。我试图理解这段代码: function checkIt(evt) { evt = (evt) ? e
package com.fastone.www.javademo.stringintern; /** * * String.intern()是一个Native方法, * 它的作用是:如果字
您会推荐哪些资源来学习 AppleScript。我使用具有 Objective-C 背景的传统 C/C++。 我也在寻找有关如何更好地开发和从脚本编辑器获取更快文档的技巧。示例提示是“查找要编写脚本的
关闭。这个问题不满足Stack Overflow guidelines .它目前不接受答案。 想改善这个问题吗?更新问题,使其成为 on-topic对于堆栈溢出。 4年前关闭。 Improve thi
关闭。这个问题不满足Stack Overflow guidelines .它目前不接受答案。 想改善这个问题吗?更新问题,使其成为 on-topic对于堆栈溢出。 7年前关闭。 Improve thi
关闭。这个问题不符合 Stack Overflow guidelines 。它目前不接受答案。 想改善这个问题吗?更新问题,以便堆栈溢出为 on-topic。 6年前关闭。 Improve this
我是塞内加尔的阿里。我今年60岁(也许这是我真正的问题-笑脸!!!)。 我正在学习Flutter和Dart。今天,我想使用给定数据模型的列表(它的名称是Mortalite,请参见下面的代码)。 我尝试
关闭。这个问题是off-topic .它目前不接受答案。 想改进这个问题? Update the question所以它是on-topic对于堆栈溢出。 9年前关闭。 Improve this que
学习 Cappuccino 的最佳来源是什么?我从事“传统”网络开发,但我对这个新框架非常感兴趣。请注意,我对 Objective-C 毫无了解。 最佳答案 如上所述,该网站是一个好地方,但还有一些其
我正在学习如何使用 hashMap,有人可以检查我编写的这段代码并告诉我它是否正确吗?这个想法是有一个在公司工作的员工列表,我想从 hashMap 添加和删除员工。 public class Staf
我正在尝试将 jQuery 与 CoffeScript 一起使用。我按照博客中的说明操作,指示使用 $ -> 或 jQuery -> 而不是 .ready() 。我玩了一下代码,但我似乎无法理解我出错
还在学习,还有很多问题,所以这里有一些。我正在进行 javascript -> PHP 转换,并希望确保这些做法是正确的。是$dailyparams->$calories = $calories;一条
我目前正在学习 SQL,以便从我们的 Magento 数据库制作一个简单的 RFM 报告,我目前可以通过导出两个查询并将它们粘贴到 Excel 模板中来完成此操作,我想摆脱 Excel 模板。 我认为
我知道我很可能会因为这个问题而受到抨击,但没有人问,我求助于你。这是否是一个正确的 javascript > php 转换 - 在我开始不良做法之前,我想知道这是否是解决此问题的正确方法。 JavaS
除了 Ruby-Doc 之外,哪些来源最适合获取一些示例和教程,尤其是关于 Ruby 中的 Tk/Tile?我发现自己更正常了 http://www.tutorialspoint.com/ruby/r
我只在第一次收到警告。这正常吗? >>> cv=LassoCV(cv=10).fit(x,y) C:\Python27\lib\site-packages\scikit_learn-0.14.1-py
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visit the
As it currently stands, this question is not a good fit for our Q&A format. We expect answers to be

我是一名优秀的程序员,十分优秀!