
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 28
28
 4
4


在我们的日常生活中,数据无处不在。从社交媒体的帖子到在线购物的交易记录,我们每天都在产生和处理大量的数据。为了有效地管理这些数据,我们需要使用数据库。数据库是存储和管理数据的工具,它们可以按照不同的方式组织和处理数据。在这篇文章中,我们将重点介绍一种新型的数据库:向量数据库,并将其与传统的关系数据库和非关系数据库进行比较.
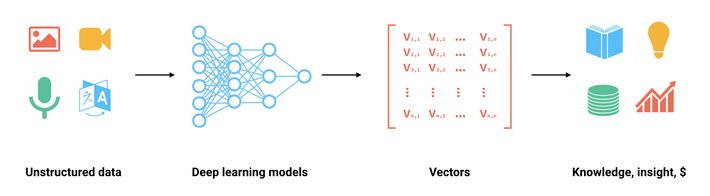
向量数据库是一种特殊类型的数据库,它可以存储和处理向量数据。向量数据通常用于表示多维度的数据点,例如在机器学习和人工智能中使用的数据。在向量数据库中,数据被表示为向量,这些向量可以在多维空间中进行比较和搜索。这种数据库的一个关键特性是它能够快速地找到与给定向量最相似的其他向量,这是通过计算向量之间的距离(例如欧氏距离或余弦相似度)来实现的.
向量数据库在许多领域都有应用,包括图像识别、自然语言处理、推荐系统等。例如,一个图像识别系统可能会将每个图像表示为一个向量,然后使用向量数据库来快速找到与给定图像最相似的其他图像.
关系数据库是最常见的数据库类型,它们使用表格的形式来存储数据,并通过预定义的关系来连接不同的表。关系数据库的一个主要优点是它们可以保证数据的一致性和完整性。然而,关系数据库在处理大规模、高维度的数据时可能会遇到困难。例如,如果我们想要在一个包含数百万条记录的数据库中找到与给定记录最相似的其他记录,我们可能需要进行大量的计算.
相比之下,向量数据库在处理这种类型的任务时更为高效。由于向量数据库可以直接在向量空间中进行搜索,它们可以快速地找到与给定向量最相似的其他向量。此外,向量数据库还可以处理非结构化的数据,如图像和文本,这是关系数据库无法做到的.
非关系数据库,也被称为NoSQL数据库,是一种灵活的数据库类型,它们可以处理各种类型的数据,包括结构化的、半结构化的和非结构化的数据。非关系数据库的一个主要优点是它们可以很好地处理大规模的数据,并且可以很容易地进行水平扩展。然而,非关系数据库在处理复杂的查询和高维度的数据时可能会遇到困难.
相比之下,向量数据库在处理高维度的数据和复杂的查询时更为高效。向量数据库可以在多维空间中进行搜索,这使得它们可以快速地找到与给定向量最相似的其他向量。此外,向量数据库还可以处理非结构化的数据,如图像和文本,这是非关系数据库在处理时可能会遇到困难的.

在市场上,有几种流行的向量数据库,包括Faiss、Milvus、Annoy和Pinecone等。下面我们将分别介绍这些数据库的特点和优缺点.
Faiss是由Facebook AI Research开发的一种高效的向量搜索和聚类工具库。它可以处理大规模的数据,并且可以在CPU和GPU上进行高效的计算。Faiss的一个主要优点是它的搜索速度非常快,这使得它在处理大规模的数据时非常有优势。然而,Faiss的一个缺点是它不支持在线的数据更新,这意味着如果我们需要添加或删除数据,我们可能需要重新构建整个索引.
Milvus是一种开源的向量数据库,它支持在线的数据更新和实时的向量搜索。Milvus的一个主要优点是它的灵活性,它支持多种类型的向量搜索算法,并且可以根据用户的需求进行定制。然而,Milvus的一个缺点是它的内存使用效率相对较低,这可能会在处理大规模的数据时成为一个问题.
Annoy是由Spotify开发的一种高效的向量搜索库,它可以在内存中存储大量的向量,并且可以快速地进行向量搜索。Annoy的一个主要优点是它的内存使用效率非常高,这使得它在处理大规模的数据时非常有优势。然而,Annoy的一个缺点是它不支持在线的数据更新,这意味着如果我们需要添加或删除数据,我们可能需要重新构建整个索引.
Pinecone是一种全托管的向量搜索服务,它可以处理大规模的数据,并且可以在云端进行高效的计算。Pinecone的一个主要优点是它的易用性,用户无需关心底层的实现细节,只需要通过API就可以进行向量搜索。然而,Pinecone的一个缺点是它是一种付费服务,对于一些小型项目或个人用户来说,成本可能会比较高.

向量数据库是一种新型的数据库,它在处理高维度的数据和复杂的查询时具有显著的优势。与传统的关系数据库和非关系数据库相比,向量数据库可以更高效地处理大规模的、非结构化的数据,这使得它们在许多领域,如机器学习和人工智能,都有广泛的应用.
然而,向量数据库并不是万能的。在某些情况下,关系数据库和非关系数据库可能更为适合。例如,如果我们需要保证数据的一致性和完整性,或者我们需要处理的数据是结构化的,那么关系数据库可能是更好的选择。同样,如果我们需要处理大规模的数据,并且需要进行水平扩展,那么非关系数据库可能是更好的选择.
在市场上,有几种流行的向量数据库,包括Faiss、Milvus、Annoy和Pinecone等。这些数据库各有优缺点,我们需要根据我们的具体需求和应用场景来选择最适合的向量数据库.
总的来说,选择哪种类型的数据库取决于我们的具体需求和应用场景。无论是关系数据库、非关系数据库,还是向量数据库,它们都是我们数据处理工具箱中的重要工具,我们需要根据实际情况选择最适合的工具.
最后此篇关于向量数据库:新一代的数据处理工具的文章就讲到这里了,如果你想了解更多关于向量数据库:新一代的数据处理工具的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
28
4
 0
0
我想用一个向量执行以下操作。 a = np.array(np.arange(0, 4, 1)) 我想得到一个乘法,结果是一个矩阵 | 0 1 2 3 4 -| - - - - - - - 0
正如标题所述,我正在尝试使用 gsub,其中我使用向量作为“模式”和“替换”。目前,我的代码如下所示: names(x1) names(x1) [1] "2110023264A.Ms.Amp
所以当我需要做一些线性代数时,我更容易将向量视为列向量。因此,我更喜欢 (n,1) 这样的形状。 形状 (n,) 和 (n,1) 之间是否存在显着的内存使用差异? 什么是首选方式? 以及如何将 (n,
我不明白为什么 seq() 可以根据元素中是否存在小数点输出不同的类,而 c() 总是创建一个 num向量,无论是否存在小数。 例如: seqDec <- seq(1, 2, 0.5) # num v
机器学习与传统编程的一个重要区别在于机器学习比传统编程涉及了更多的数学知识。不过,随着机器学习的飞速发展,各种框架应运而生,在数据分析等应用中使用机器学习时,使用现成的库和框架成为常态,似乎越来越不需
寻找有关如何将 RegEnable 用作向量的示例/建议。此外,我想控制输入和使能信号成为 Vector 中寄存器索引的函数。 首先,我如何声明 RegEnable() 的 Vector,其次如何迭代
假设我有一个包含变量名称的向量 v1,我想为每个变量分配一个值(存储在单独的向量中)。我如何在没有迭代的情况下做到这一点? v1 <- c("a","b","c") v2 <- c(1,2,3) 我想
R 提供了三种类型来存储同质对象列表:向量、矩阵 和数组。 据我所知: 向量是一维数组的特殊情况 矩阵是二维数组的特例 数组还可以具有任意维度级别(包括 1 和 2)。 在向量上使用一维数组和在矩阵上
我正在绕着numpy/scipy中的所有选项转圈。点积、乘法、matmul、tensordot、einsum 等 我想将一维向量与二维矩阵(这将是稀疏csr)相乘并对结果求和,这样我就有了一个一维向量
我是一个 IDL 用户,正在慢慢切换到 numpy/scipy,并且有一个操作我在 IDL 中非常经常做,但无法用 numpy 重现: IDL> a = [2., 4] IDL> b = [3., 5
在python计算机图形工具包中,有一个vec3类型用于表示三分量向量,但是我如何进行以下乘法: 三分量向量乘以其转置结果得到 3*3 矩阵,如下例所示: a = vec3(1,1,1) matrix
我正在构建一款小型太空射击游戏。当涉及到空间物理学时,我曾经遇到过数学问题。 用文字描述如下:有一个最大速度。因此,如果您全速行驶,您的飞船将在屏幕上一遍又一遍地移动,就像在旧的小行星游戏中一样。如果
我正在尝试在 python 中实现 Vector3 类。如果我用 c++ 或 c# 编写 Vector3 类,我会将 X、Y 和 Z 成员存储为 float ,但在 python 中,我读到鸭式是要走
我是 Spark 和 Scala 的新手,我正在尝试阅读有关 MLlib 的文档。 http://spark.apache.org/docs/1.4.0/mllib-data-types.html上的
我有一个包含四个逻辑向量的数据框, v1 , v2 , v3 , v4 是对还是错。我需要根据 boolean 向量的组合对数据帧的每一行进行分类(例如, "None" , "v1 only" , "
我正在创建一个可视化来说明主成分分析的工作原理,方法是绘制一些实际数据的特征值(为了说明的目的,我将子集化为二维)。 我想要来自 this fantastic PCA tutorial 的这两个图的组
我有以下排序向量: > v [1] -1 0 1 2 4 5 2 3 4 5 7 8 5 6 7 8 10 11 如何在不遍历整个向量的情况下删除 -1、0 和 11
有什么方法可以让 R 对向量和其他序列数据结构使用基于零的索引,例如在 C 和 python 中。 我们有一些代码在 C 中进行一些数值处理,我们正在考虑将其移植到 R 中以利用其先进的统计功能,但是
我有一个函数可以查询我的数据库中最近的 X 个条目,它返回一个 map 向量,如下所示: [{:itemID "item1" :category "stuff" :price 5} {:itemI
我有 ([[AA ww me bl qw 100] [AA ee rr aa aa 100] [AA qq rr aa aa 90]] [[CC ww me bl qw 100] [CC ee rr

我是一名优秀的程序员,十分优秀!