
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 28
28
 4
4


@ 。
Chunjun 官网 https://dtstack.github.io/chunjun-web/ 源码release最新版本1.12.8 。
Chunjun 文档地址 https://ververica.github.io/flink-cdc-connectors/master/ 。
Chunjun 源码地址 https://github.com/DTStack/chunjun 。
Chunjun是一个分布式集成框架,原名是FlinkX,由袋鼠云开源,其基于Flink的批流统一打造的数据同步工具,可以实现各种异构数据源之间的数据同步和计算.
ChunJun是一个基于 Flink 提供易用、稳定、高效的批流统一的数据集成工具,可以采集静态的数据如 MySQL,HDFS 等,也可以采集实时变化的数据如 binlog,Kafka等.
# 最新release版本源码flink12.7,如果是下载主线master版本,目前源码默认引入flink16.1,可以通过git clone https://github.com/DTStack/chunjun.git也可以直接http下main,由于是学习可使用master版本来踩坑
wget https://github.com/DTStack/chunjun/archive/refs/tags/v1.12.8.tar.gz
tar -xvf v1.12.8.tar.gz
# 进入源码目录
cd chunjun-1.12.8/
# 编译打包执行,下面两种选一
./mvnw clean package
sh build/build.sh
在根目录下生成 chunjun-dist 目录,官方提供丰富的示例程序,详细可以查看chunjun-examples目录 。
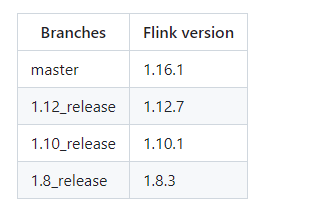
下表显示了ChunJun分支与flink版本的对应关系。如果版本没有对齐,在任务中会出现'Serialization Exceptions', 'NoSuchMethod Exception'等问题.
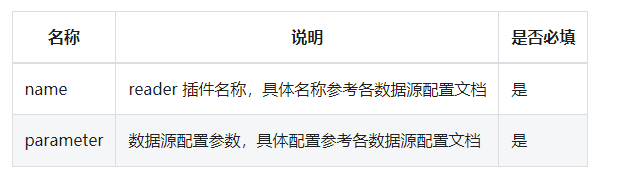
一个完整的 ChunJun 任务脚本配置包含 content, setting 两个部分。content 用于配置任务的输入源与输出源,其中包含 reader,writer。而 setting 则配置任务整体的环境设定,其中包含 speed,errorLimit,metricPluginConf,restore,log,dirty。总体结构如下所示:
{
"job" : {
"content" :[{
"reader" : {},
"writer" : {}
}],
"setting" : {
"speed" : {},
"errorLimit" : {},
"metricPluginConf" : {},
"restore" : {},
"log" : {},
"dirty":{}
}
}
}

reader 用于配置数据的输入源,即数据从何而来。具体配置如下所示:
"reader" : {
"name" : "xxreader",
"parameter" : {
......
}
}
Writer 用于配置数据的输出目的地,即数据写到哪里去。具体配置如下所示:
"writer" : {
"name" : "xxwriter",
"parameter" : {
......
}
}

详细使用查看官方的说明 。
进入Chunjun根目录,测试脚本执行本地环境,查看stream.json 。
{
"job": {
"content": [
{
"reader": {
"parameter": {
"column": [
{
"name": "id",
"type": "id"
},
{
"name": "name",
"type": "string"
},
{
"name": "content",
"type": "string"
}
],
"sliceRecordCount": [
"30"
],
"permitsPerSecond": 1
},
"table": {
"tableName": "sourceTable"
},
"name": "streamreader"
},
"writer": {
"parameter": {
"column": [
{
"name": "id",
"type": "id"
},
{
"name": "name",
"type": "string"
}
],
"print": true
},
"table": {
"tableName": "sinkTable"
},
"name": "streamwriter"
},
"transformer": {
"transformSql": "select id,name from sourceTable where CHAR_LENGTH(name) < 50 and CHAR_LENGTH(content) < 50"
}
}
],
"setting": {
"errorLimit": {
"record": 100
},
"speed": {
"bytes": 0,
"channel": 1,
"readerChannel": 1,
"writerChannel": 1
}
}
}
}
bash ./bin/chunjun-local.sh -job chunjun-examples/json/stream/stream.json
将依赖文件复制到Flink lib目录下,这个复制操作需要在所有Flink cluster机器上执行 。
cp -r chunjun-dist $FLINK_HOME/lib
启动Flink Standalone环境 。
sh $FLINK_HOME/bin/start-cluster.sh
准备mysql的数据,作为读取数据源 。
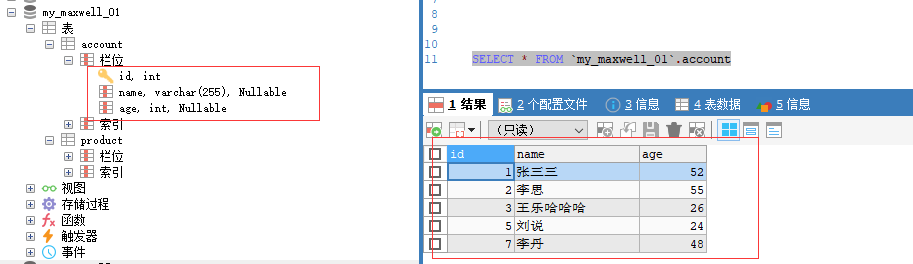
准备job文件,创建chunjun-examples/json/mysql/mysql_hdfs_polling_my.json 。
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column" : [
{
"name" : "id",
"type" : "bigint"
},{
"name" : "name",
"type" : "varchar"
},{
"name" : "age",
"type" : "bigint"
}
],
"splitPk": "id",
"splitStrategy": "mod",
"increColumn": "id",
"startLocation": "1",
"username": "root",
"password": "123456",
"queryTimeOut": 2000,
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://mysqlserver:3308/my_maxwell_01?useSSL=false"
],
"table": [
"account"
]
}
],
"polling": false,
"pollingInterval": 3000
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"fileType": "text",
"path": "hdfs://myns/user/hive/warehouse/chunjun.db/kudu_txt",
"defaultFS": "hdfs://myns",
"fileName": "pt=1",
"fieldDelimiter": ",",
"encoding": "utf-8",
"writeMode": "overwrite",
"column": [
{
"name": "id",
"type": "BIGINT"
},
{
"name": "VARCHAR",
"type": "VARCHAR"
},
{
"name": "age",
"type": "BIGINT"
}
],
"hadoopConfig": {
"hadoop.user.name": "root",
"dfs.ha.namenodes.ns": "nn1,nn2",
"fs.defaultFS": "hdfs://myns",
"dfs.namenode.rpc-address.ns.nn2": "hadoop1:9000",
"dfs.client.failover.proxy.provider.ns": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider",
"dfs.namenode.rpc-address.ns.nn1": "hadoop2:9000",
"dfs.nameservices": "myns",
"fs.hdfs.impl.disable.cache": "true",
"fs.hdfs.impl": "org.apache.hadoop.hdfs.DistributedFileSystem"
}
}
}
}
],
"setting" : {
"restore" : {
"restoreColumnName" : "id",
"restoreColumnIndex" : 0
},
"speed" : {
"bytes" : 0,
"readerChannel" : 3,
"writerChannel" : 3
}
}
}
}
启动同步任务 。
bash ./bin/chunjun-standalone.sh -job chunjun-examples/json/mysql/mysql_hdfs_polling_my.json
任务执行完后通过web控制台可以看到执行成功信息,查看HDFS路径数据也可以看到刚刚成功写入的数据 。

创建一个个Kafka的topic用于数据源读取 。
kafka-topics.sh --create --zookeeper zk1:2181,zk2:2181,zk3:2181 --replication-factor 3 --partitions 3 --topic my_test1
ClickHouse创建testdb数据库和sql_side_table表 。
CREATE DATABASE IF NOT EXISTS testdb;
CREATE TABLE if not exists sql_side_table
(
id Int64,
test1 Int64,
test2 Int64
) ENGINE = MergeTree()
PRIMARY KEY (id);
insert into sql_side_table values(1,11,101),(2,12,102),(3,13,103);
MySQL创建sql_sink_table表 。
CREATE TABLE `sql_sink_table` (
`id` bigint NOT NULL,
`name` varchar(100) COLLATE utf8mb4_general_ci DEFAULT NULL,
`test1` bigint DEFAULT NULL,
`test2` bigint DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
创建sql文件chunjun-examples/sql/clickhouse/kafka_clickhouse_my.sql 。
CREATE TABLE source (
id BIGINT,
name STRING
) WITH (
'connector' = 'kafka-x',
'topic' = 'my_test1',
'properties.bootstrap.servers' = 'kafka1:9092',
'properties.group.id' = 'dodge',
'format' = 'json'
);
CREATE TABLE side (
id BIGINT,
test1 BIGINT,
test2 BIGINT
) WITH (
'connector' = 'clickhouse-x',
'url' = 'jdbc:clickhouse://ck1:8123/testdb',
'table-name' = 'sql_side_table',
'username' = 'default',
'lookup.cache-type' = 'lru'
);
CREATE TABLE sink (
id BIGINT,
name VARCHAR,
test1 BIGINT,
test2 BIGINT
)WITH (
'connector' = 'mysql-x',
'url' = 'jdbc:mysql://mysqlserver:3306/test',
'table-name' = 'sql_sink_table',
'username' = 'root',
'password' = '123456',
'sink.buffer-flush.max-rows' = '1024',
'sink.buffer-flush.interval' = '10000',
'sink.all-replace' = 'true'
);
INSERT INTO sink
SELECT
s1.id AS id,
s1.name AS name,
s2.test1 AS test1,
s2.test2 AS test2
FROM source s1
JOIN side s2
ON s1.id = s2.id
启动同步任务 。
bash ./bin/chunjun-standalone.sh -job chunjun-examples/sql/clickhouse/kafka_clickhouse_my.sql
往kafka的my_test1这个topic写入数据 。
./kafka-console-producer.sh --broker-list cdh1:9092 --topic my_test1
{"id":1,"name":"sunhaiyang"}
{"id":2,"name":"gulili"}
查看MySQL的sql_sink_table表已经有刚才写入消息并关联出结果的数据 。

创建两个Kafka的topic,一个用于数据源读取,一个用于数据源写入 。
kafka-topics.sh --create --zookeeper zk1:2181,zk2:2181,zk3:2181 --replication-factor 3 --partitions 3 --topic my_test3
kafka-topics.sh --create --zookeeper zk1:2181,zk2:2181,zk3:2181 --replication-factor 3 --partitions 3 --topic my_test4
创建sql文件chunjun-examples/sql/kafka/kafka_kafka_my.sql 。
CREATE TABLE source_test (
id INT
, name STRING
, money decimal
, datethree timestamp
, `partition` BIGINT METADATA VIRTUAL -- from Kafka connector
, `topic` STRING METADATA VIRTUAL -- from Kafka connector
, `leader-epoch` int METADATA VIRTUAL -- from Kafka connector
, `offset` BIGINT METADATA VIRTUAL -- from Kafka connector
, ts TIMESTAMP(3) METADATA FROM 'timestamp' -- from Kafka connector
, `timestamp-type` STRING METADATA VIRTUAL -- from Kafka connector
, partition_id BIGINT METADATA FROM 'partition' VIRTUAL -- from Kafka connector
, WATERMARK FOR datethree AS datethree - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka-x'
,'topic' = 'my_test3'
,'properties.bootstrap.servers' = 'kafka1:9092'
,'properties.group.id' = 'test1'
,'scan.startup.mode' = 'earliest-offset'
,'format' = 'json'
,'json.timestamp-format.standard' = 'SQL'
,'scan.parallelism' = '2'
);
CREATE TABLE sink_test
(
id INT
, name STRING
, money decimal
, datethree timestamp
, `partition` BIGINT
, `topic` STRING
, `leader-epoch` int
, `offset` BIGINT
, ts TIMESTAMP(3)
, `timestamp-type` STRING
, partition_id BIGINT
) WITH (
'connector' = 'kafka-x'
,'topic' = 'my_test4'
,'properties.bootstrap.servers' = 'kafka1:9092'
,'format' = 'json'
,'sink.parallelism' = '2'
,'json.timestamp-format.standard' = 'SQL'
);
INSERT INTO sink_test
SELECT *
from source_test;
往kafka的my_test3这个topic写入数据 。
kafka-console-producer.sh --broker-list cdh1:9092 --topic my_test3
{"id":100,"name":"guocai","money":243.18,"datethree":"2023-07-03 22:00:00.000"}
{"id":101,"name":"hanmeimei","money":137.32,"datethree":"2023-07-03 22:00:01.000"}
启动同步任务 。
bash ./bin/chunjun-standalone.sh -job chunjun-examples/sql/kafka/kafka_kafka_my.sql
查看kafka的my_test4的数据,已经收到相应数据并打上kafka元数据信息 。
kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic my_test4 --from-beginning

最后此篇关于国产开源流批统一的数据同步工具Chunjun入门实战的文章就讲到这里了,如果你想了解更多关于国产开源流批统一的数据同步工具Chunjun入门实战的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
28
4
 0
0
我正在为期末考试学习,但我无法理解这个 FC 算法: 我理解你标准化每条规则的部分。然后我认为下一行是说对于满足广义 Modus Ponens (p'_iTheta = p_iTheta) 的每个 t
我有一个 3d 世界,它有一个 simpel 平台和一个代表玩家的立方体。当我旋转平台时,立方体会滑动并按照您预期的方式执行,增加和减少物理 Material 中的摩擦力。 我希望立方体在输入例如 f
所以我的 Unity 项目有一个大问题。我昨天工作,我没有做备份今天,在我打开项目后,我的笔记本电脑因电池电量不足而关机。之后,当我进入项目时,我得到了这个:加载“Assets/MyScene.uni
好的,我正在尝试创建一个函数来确定元组列表是否是可传递的,即如果 (x,y) 和 (y,z) 在列表中,那么 (x,z) 也在列表中。 例如,[(1,2), (2,3), (1,3)]是传递的。 现在
这个问题在这里已经有了答案: How to pass data between scenes in Unity (5 个回答) 9 个月前关闭。 我有一个游戏,我有一个队列匹配系统。 我想向玩家展示他
我现在正在为我的游戏创建一个 keystore (统一)但是当我按下添加键按钮时,会弹出一个错误 Java Development Kit (JDK) directory is not set or
我想将YouTube流视频放入Cardboard(适用于Android和iOS)应用中。我知道这些插件可以执行类似的操作,例如“Easy Movie Texture”,但它们不支持YouTube流媒体
我需要限制 ConfigurableJoint 的目标旋转以避免关节变形或破坏。 为了了解角度限制的工作原理,我做了一个实验。 在场景中放置一个人形模型。 为骨骼添加ConfigurableJoint
尝试实现一种有限形式的匹配统一。 尝试匹配两个公式匹配如果我们能找到替代出现在公式中的变量使得两者在句法上是等价。 我需要写一个函数来判断一个对应于基本项的常数,例如 Brother(George)
我正在使用 Unity 和 C#我想在运行时将输出日志文件发送到我的电子邮件,我使用了来自 this question 的 ByteSheep 答案和来自 this question 的 Arkane
关闭。这个问题需要debugging details .它目前不接受答案。 编辑问题以包含 desired behavior, a specific problem or error, and th
我希望能够将鼠标悬停在游戏对象(代理)上并在右键或左键单击时创建一个类似于 Windows 右键单击菜单的 float 菜单。我试过结合使用 OnGUI() 和 OnMouseOver() 但我要
我正在为 oculus Gear VR 开发游戏(考虑内存管理),我需要在特定时间(以秒为单位)后加载另一个屏幕 void Start () { StartCoroutine (loadSce
我设法生成了敌人,但它们一直在生成。如何设置限制,避免不断生成? 我已经尝试添加 spawnLimit 和 spawnCounter 但无法让它工作。 var playerHealth = 100;
我正在参加使用 Unity 进行游戏开发的在线类(class),讲师有时会含糊不清。我的印象是使用游戏对象与使用游戏对象名称(在本例中为 MusicPlayer)相同,但是当我尝试将 MusicPla
关闭。这个问题需要更多focused .它目前不接受答案。 想改进这个问题吗? 更新问题,使其只关注一个问题 editing this post . 关闭 6 年前。 Improve this qu
为了好玩,我正在(用 Java)开发一个使用统一算法的应用程序。 我选择了我的统一算法返回所有可能的统一。例如,如果我尝试解决 添加(X,Y)=成功(成功(0)) 返回 {X = succ(succ(
如何让对象在一段时间后不可见(或只是删除)?使用 NGUI。 我的示例(更改): public class scriptFlashingPressStart : MonoBehaviour {
我有下一个错误: The type or namespace name 'NUnit' could not be found (are you missing a using directive or
这是可以做到的 但是属性 autoSizeTextType 只能用于 API LEVEL >= 26,并且 Android Studio 会显示有关该问题的烦人警告。 为了摆脱这个问题,我想以编程方

我是一名优秀的程序员,十分优秀!