
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 27
27
 4
4


首发地址: https://mp.weixin.qq.com/s/Kc13g8OHK1h_f7eMlnl4Aw 。
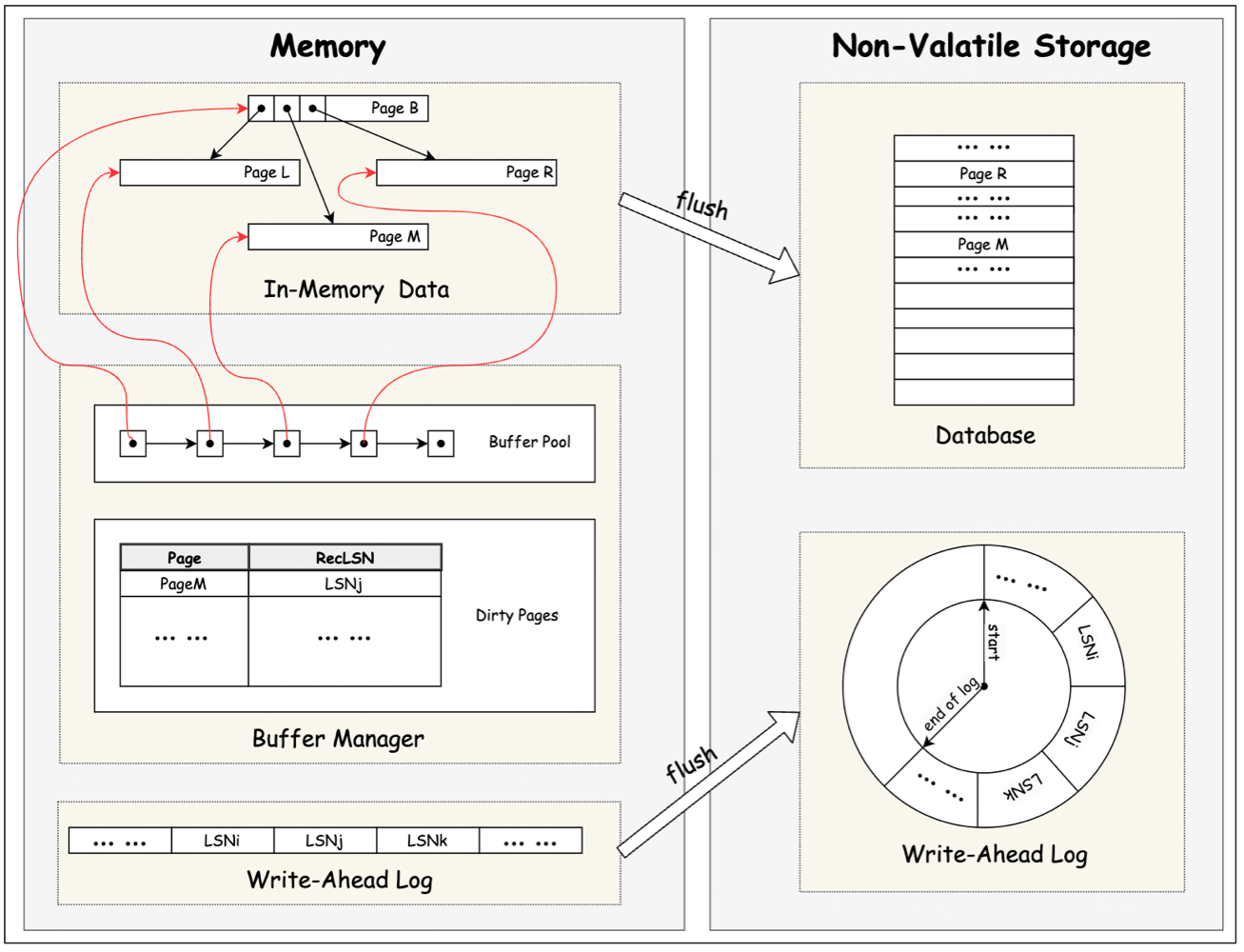
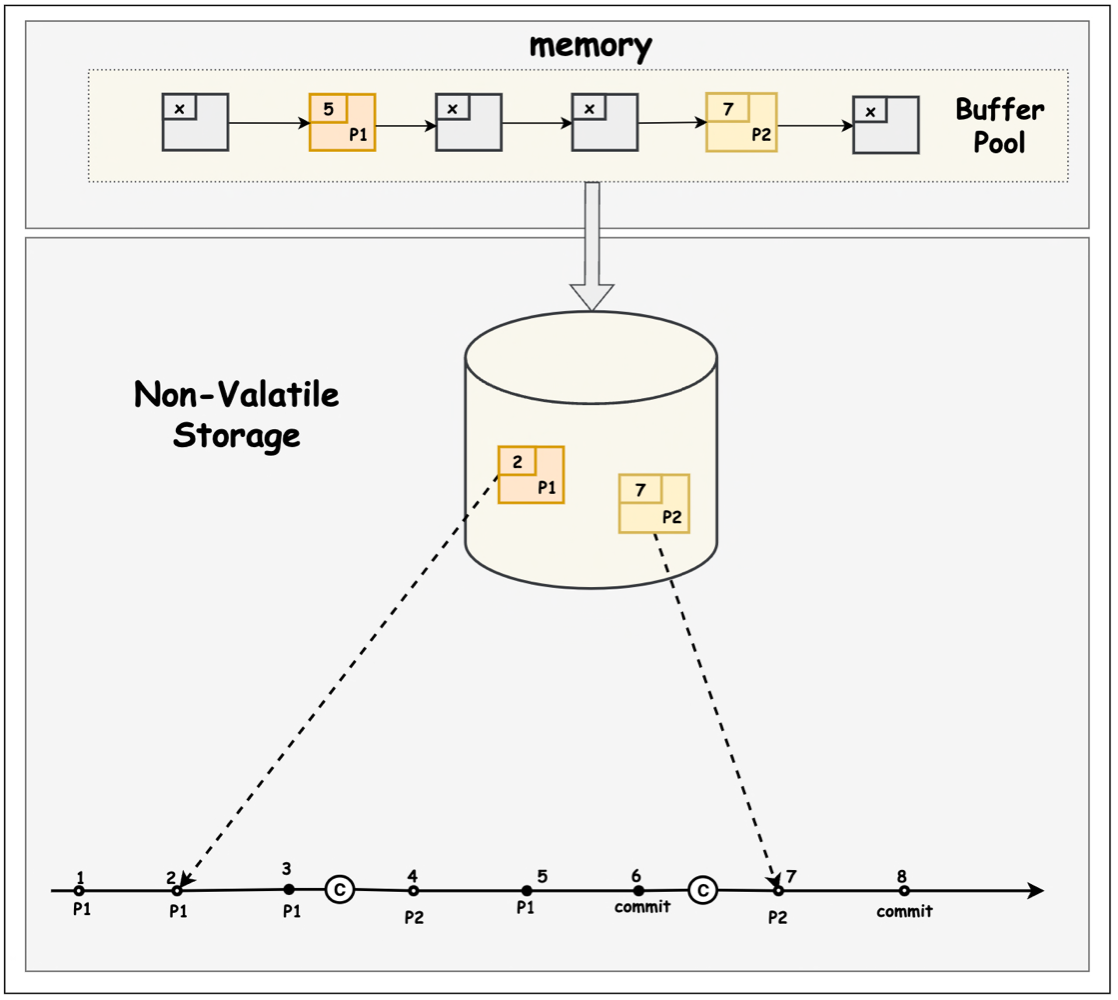
上图中为基于 WAL 的数据库的一种可能的架构情况。其中,In-Memory Data 为数据库数据在内存中的组织形式,可以是 B 树,也可以是 hash table 或者其他可能的数据结构。Non-Valatile Storage 中的 Database 为这些数据刷新(flush)到持久化存储之后的组织形式.
Buffer Manager(BM) 控制 In-Memory Data 及其持久化数据之间的读写逻辑。当用户访问的数据不在 In-Memory Data 中, BM 会去 Non-Valatile Storage 中读取磁盘中该数据对应的 Page,并将其交由 Buffer Pool 管理。如果 Memory 中的剩余空间不足以读取该 Page,BM 会根据指定的置换算法先将 Buffer Pool 中的部分 Page 逐出(evict)然后再读取.
当我们需要对某个 page 做操作时,需要先将这个 page fix 到 In-Memory Data 中。如果 page 不在内存中,fix 操作会将该 page 从磁盘中读取到内存。并且会让该 page 不会被置换算法逐出。当操作完成之后,对该 page 执行 unfix 操作,解除对该 page 的限制.
为了减少 I/O 对性能的影响,用户对 In-Memory Data 的变更,并不会立刻 flush 到 Non-Valatile Storage , 这会导致 它们中的数据可能会存在版本不一致的情况。BM 会 In-Memory Data 中比 Non-Valatile Storage 数据版本更新的数据由 Dirty Pages 统一维护起来,按照一定的规则统一 flush。(比如后台进程定期 flush;或是指定节点强制 flush) 。
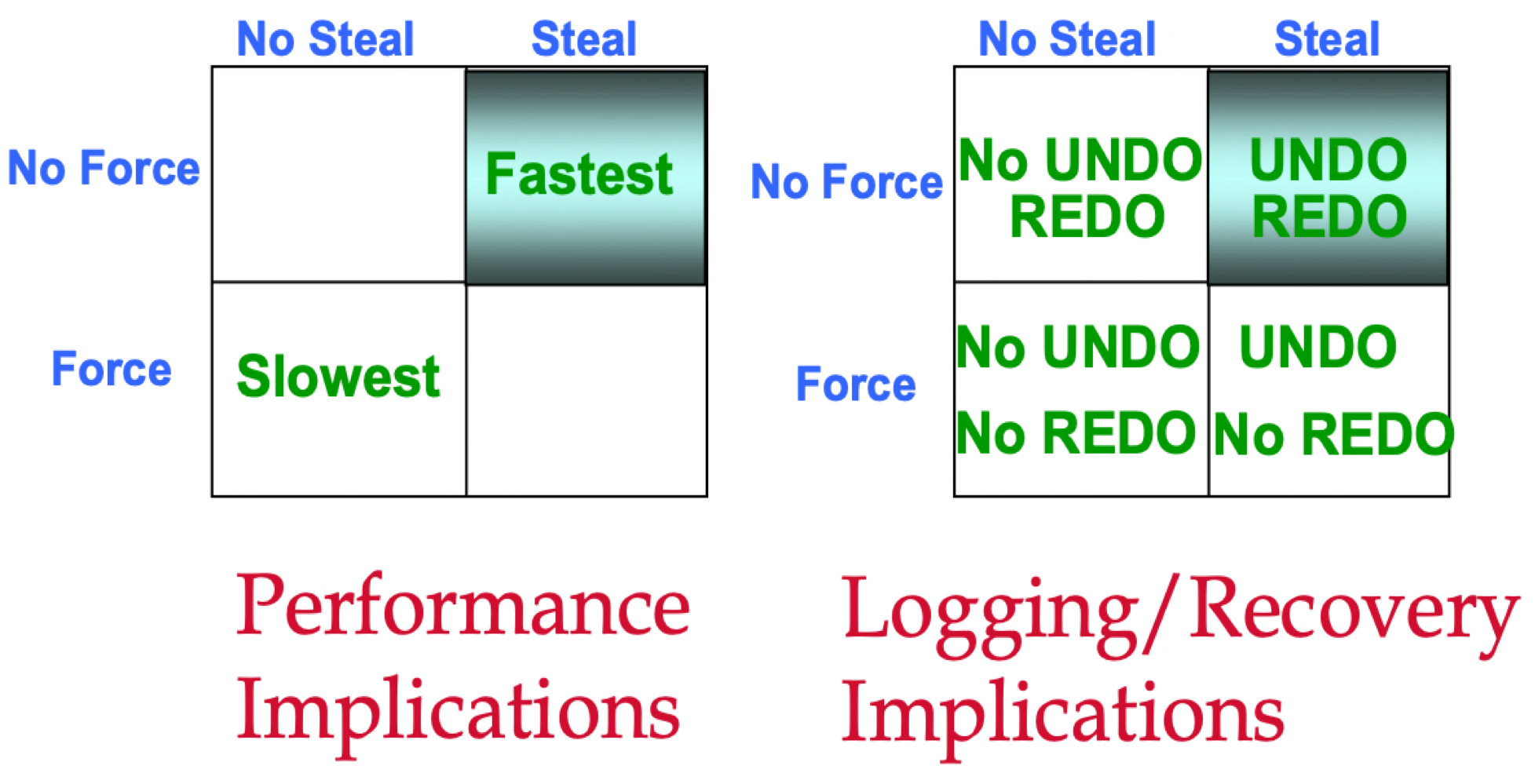
对 Buffer Pool 的管理有两组策略来控制 flush 逻辑,第一组是 Steal/No-Steal
另一组是 Force/No-Force:
一般来说 No-Force + Steal 因为不用强制刷屏,并且允许异步进程在任意时刻刷盘,所以性能最好。但是它的代价是需要同时维护 UNDO 和 REDO log 来保证数据的完整性和一致性。ARIES 就采用的是 No-Force + Steal 策略.
设想一下这个场景:某个请求对 In-Memory Data 的某个 Page X 做了变更。但在 Page X flush 进 Non-Valatile Storage 之前,整个系统因为某种原因重启了。此时,Page X 未 flush 的变更将会丢失。如果这部分变更之前已经 commit, 用户将会感知到数据丢失的发生.
为了解决上述问题, 我们需要使用 Write-Ahead Log(WAL),将 Dirty Pages 的变更提前写入 WAL 日志。这样在系统重启后,我们就可以通过 WAL 日志将 Dirty Pages 的变更恢复。 WAL 可以同步 flush,也可以较大频率的定期 flush。只有在某个事务 Txn 对应 WAL 日志已经全部 flush 成功的情况下,我们才认为事务 Txn commit 成功,可以向用户做出事务提交成功的响应.
一般来说 WAL log 有一下几类:
REDO LOG: 提供某个变更操作的重做信息.
UNDO LOG: 提供某个变更操作的回滚信息.
UNDO-REDO LOG: 既包含 REDO 信息又包含 UNDO 信息的日志.
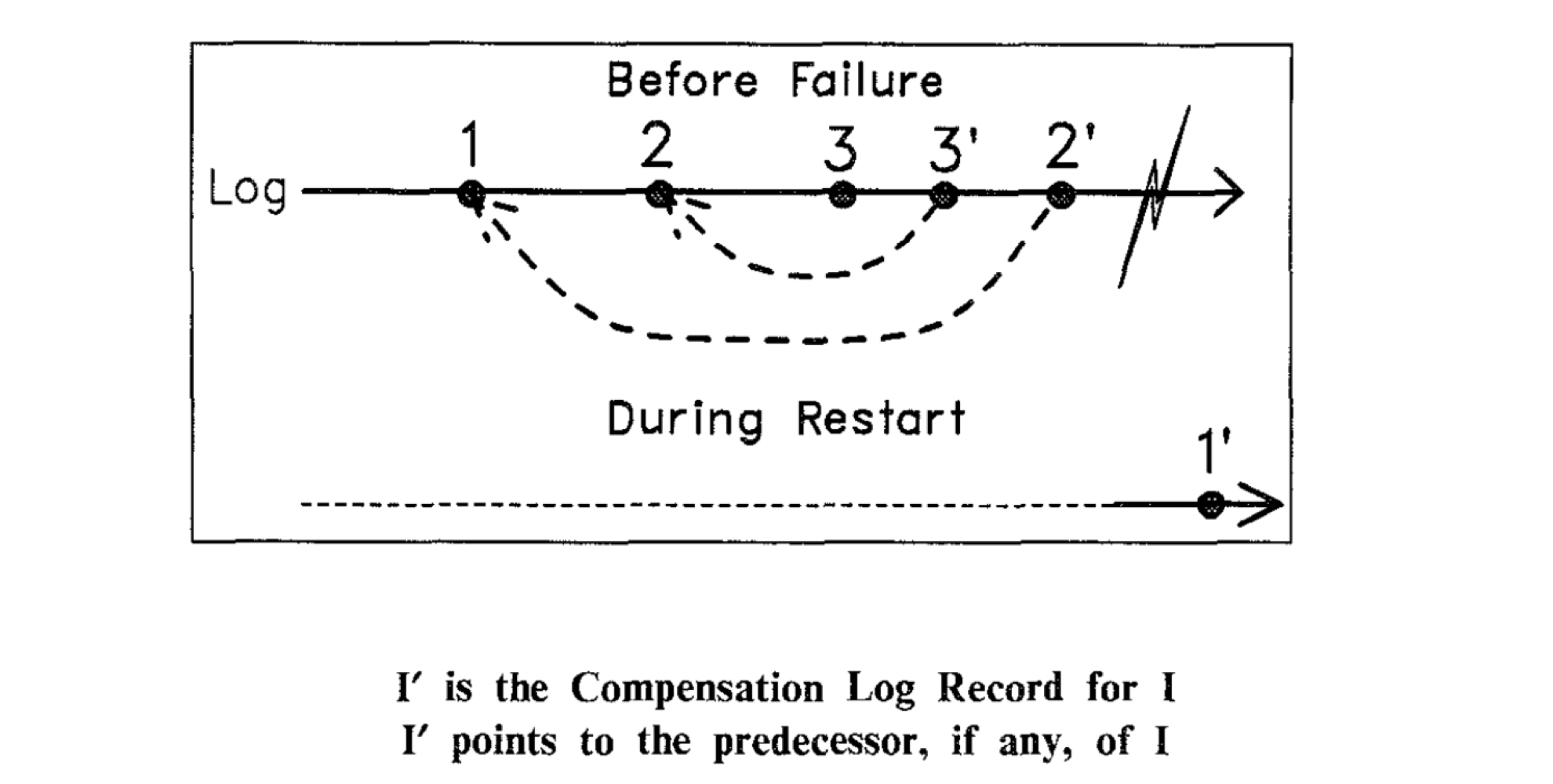
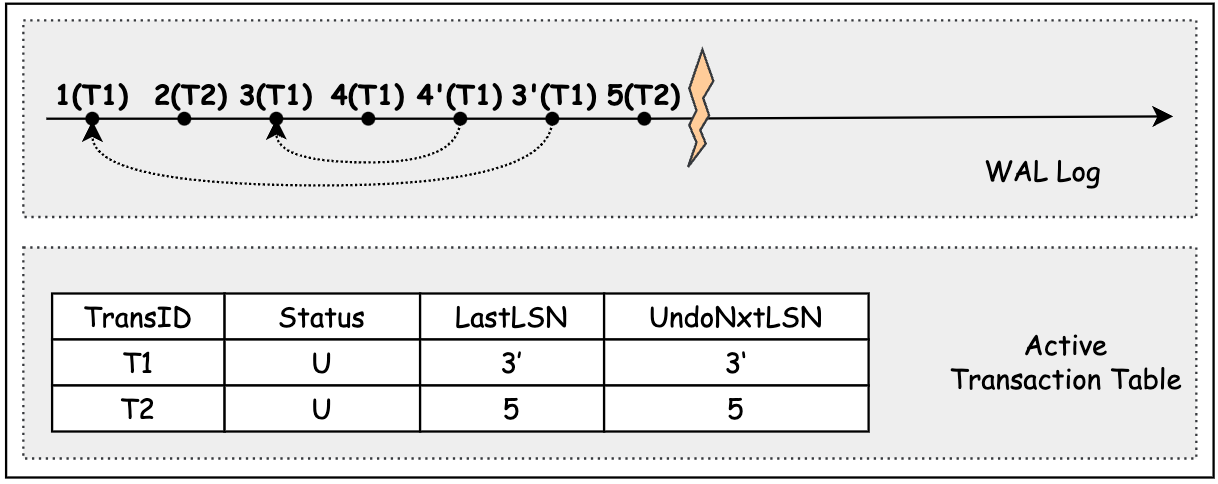
Compensation Log Record(CLR): Undo 操作的 Redo Log。在 ARIES 中, 它是 Redo-only 日志。由于 UNDO 操作的信息在之前的被 Undo 的原操作操作对应的 WAL log 已经包含,因此,当我们在记录这条 UNDO 操作的 WAL log(redo-only) 时,仅需补偿指出它要 UNDO 的原操作的前一条操作,以便在 restart 过程中,快速定位到下一个待 UNDO 的原操作.
在下图中,系统在 Recovery 过程中, 通过 CLR 日志 2’ 的信息发现当前应该对 1 进行回滚操作。因此,在 UNDO 阶段,对 1 进行回滚操作,并记录下它的 CLR 日志 1'.
WAL 协议保证在某个 page 的变更 flush 到持久化存储之前,它所对应的 WAL 日志已经写入持久化存储。也就是说,至少保证某个变更的 UNDO log 已经 flush,才允许对应的变更 flush,只有这样,我们才能保证未完成的事务可以顺利的 UNDO。同时每个持久化的 page 携带有当前 page 上次刷盘对应的变更日志的 LSN,以便后续 recovery 操作时,定位该 page 的起始 redo log.
ARIES(Algorithms for Recovery and Isolation Exploiting Semantics) 是一种能够恢复系统状态并处理系统崩溃带来的问题的重要技术。该算法为处理数据库中的恢复、并发控制和事务管理问题等提供了全面的解决方案。它将上述的架构系统的整合在一起,提供一种通用化的处理思路。当前市面上绝大多数数据库的 Recovery 逻辑都是基于 ARIES 优化改造实现的.
本文将详细介绍 ARIES paper 的细节,完整展现数据库系统是如何实现 Recovery 的.
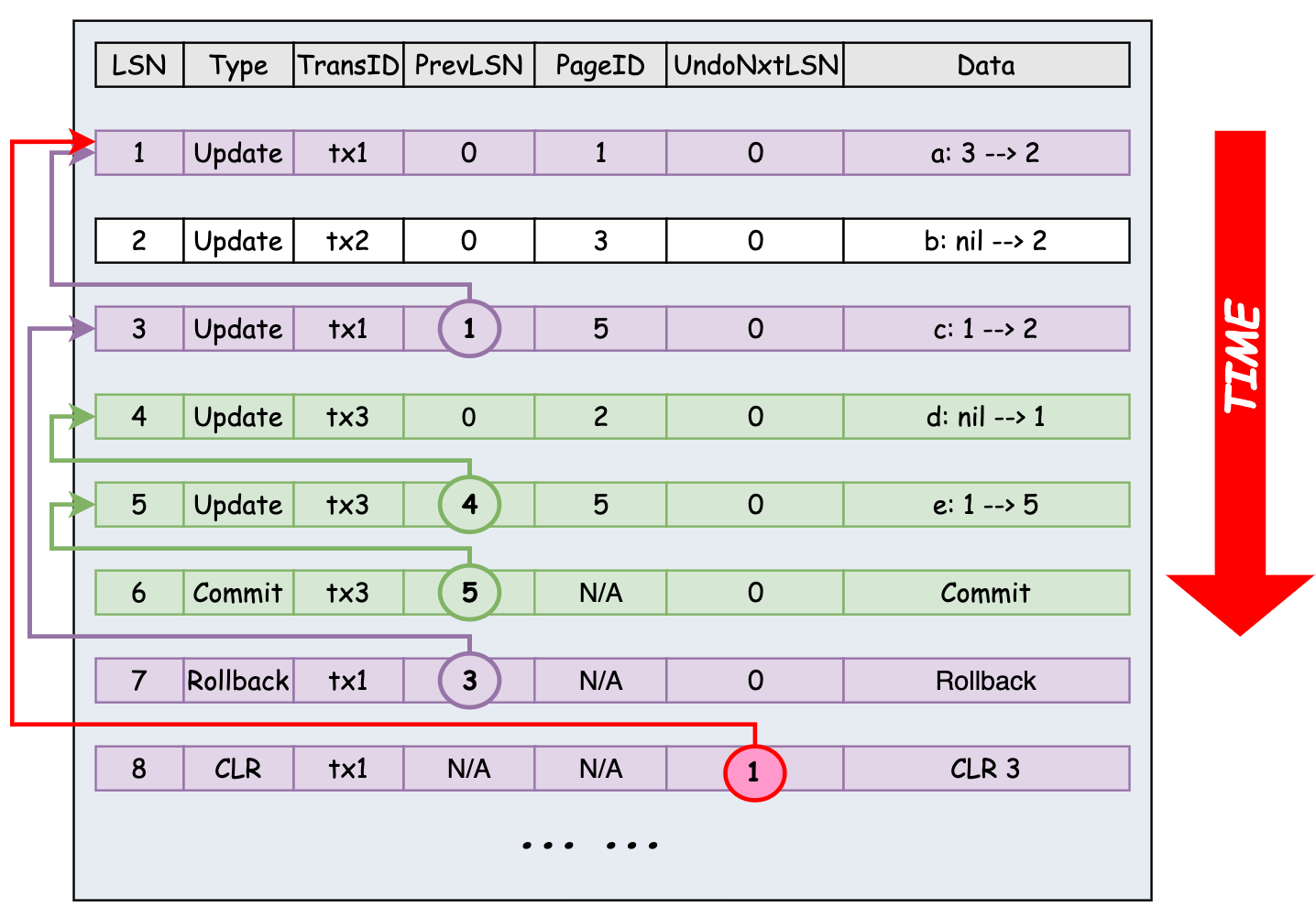
ARIES 的 WAL 日志记录结构如下:
在下图中,事务 tx1 在 LSN = 7 处回滚,开始执行回滚 LSN=3 的日志,并为其写下 LSN = 8 的 CLR log, 该日志指向下一个待 UNDO 的日志的 LSN, 即 LSN = 3 的日志对应的 PrevLSN(1).
在数据库 Page 的元信息中,维护了一个 PageLSN 字段。该字段记录应用到该 Page 的最新的更新操作对应的 WAL 日志记录的 LSN.
如在下图中,下面的数轴表示 WAL 日志,数轴上面的数字表示 WAL 日志的 LSN。下面的 P1/P2 标记表示当前 WAL 日志涉及到变更的 Page。虚线箭头表示 Page flush 的 LSN.
在该图中, P1 flush 到了 PageLSN=2 处的日志,但其 buffer pool 中的数据已经变更到 PageLSN=5 处的日志(如果在当前状态下 crash,则 P1 需要从 pageLSN = 2 之后开始 recovery).
ATT 是负责追踪活跃事务的执行状态的状态表,包括以下字段
DPT 用于记录数据库运行过程中 Buffer Pool 中已变更但还未来得及 flush 到持久化存储的 Page(即缓冲区中与持久化存储版本不一致的 Page)。包含以下字段:
在下图中,page L 和 Page M 持久化存储的数据版本早于内存中的数据版本,因此 Dirty Page 记录了它们对应的 RecLSN。page B 和 Page R flush 最新数据到持久化存储(内存数据和持久化存储数据版本一致),因此可以从 Dirty Page 中删除.
数据库正常运行状态下,后台任务定时刷新数据库运行状态 checkpoint 到 WAL 日志中,记录当前 DPT,ATT 的状态。同时在持久化存储的 Master Record 记录最新的 checkpoint 起始 LSN.
事务的 Rollback :
ARIES Normal Process 流程如下图,当服务接收到业务数据更新请求,会现在 BufferPool 中更新对应的 Page,如果它不在 Dirty Page 中,则将它加入 Dirty Page。然后在内存中的 WAL 日志增加本次变更的内容,最后将 WAL flush 到磁盘。当 WAL flush 到磁盘后,该数据更新请求完成,返回业务请求成功.
同时,异步 flush 进程,定时将 Buffer Pool 中的 Page flush 到磁盘,并将其从 Dirty Page 中移除.
为了支持部分回滚(partial rollback), 在事务执行过程中,会在特定时间节点建立 savepoint 记录当前事务最新写入的日志 LSN,记作 SaveLSN。如果当前事务还未写入日志,则 SaveLSN 设为 0.
同一个事务可以根据需要维护任意多个 savepoint。当事务需要回滚到某个 savepoint 时, 它会从最新的 WAL 日志开始执行 UNDO 操作,指定指定 savepoint 对应的 SaveLSN 为止.
事务回滚过程中, SaveLSN 之后申请的 lock 也会被释放(因为 ARIES 不会 UNDO CLR 日志, 因此在此场景下不再需要这些锁)。因此,当系统检测到出现死锁问题时,仅需要 partial rollback 到指定 savepoint 即可解决, 而不用 total rollback.
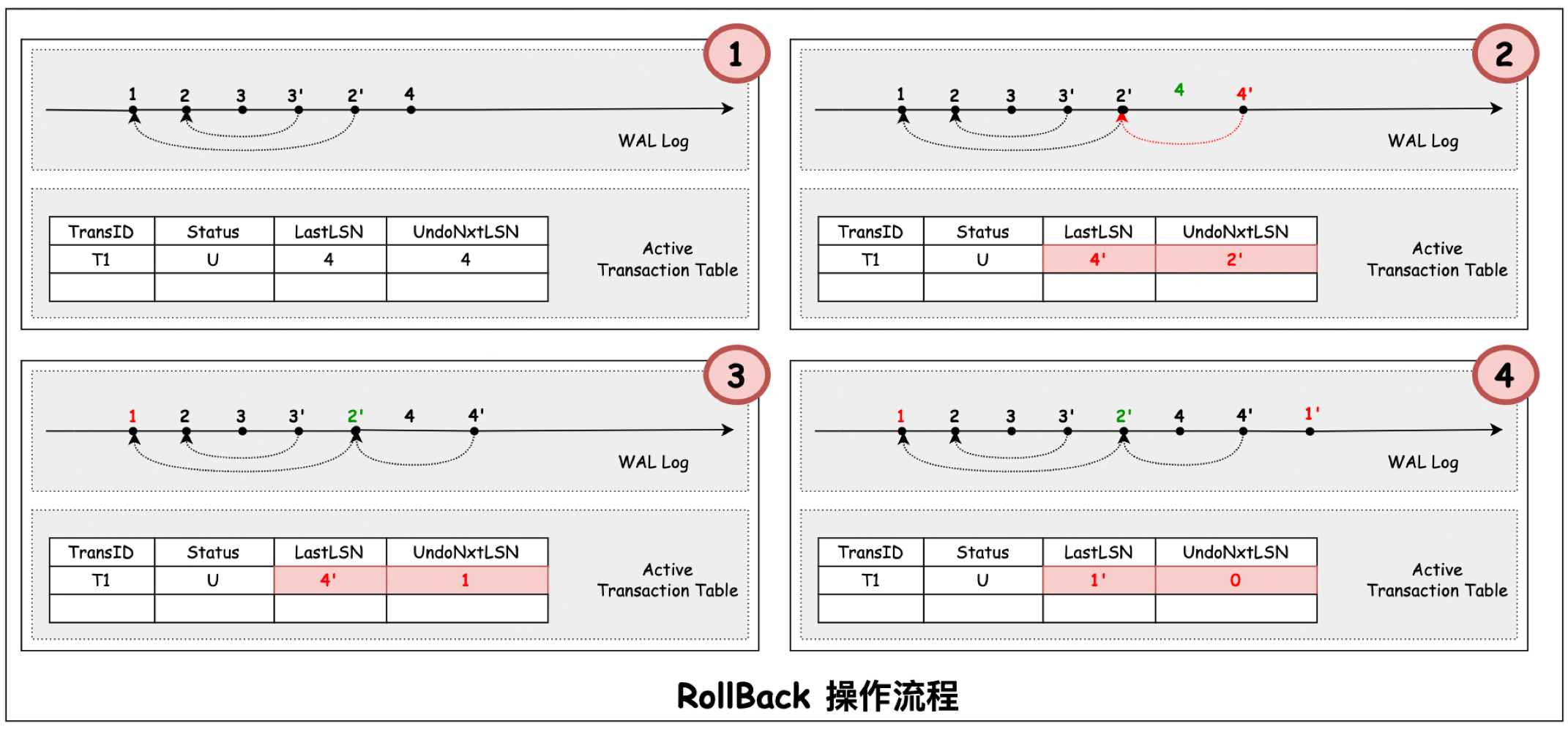
回滚过程中, 会从 ATT 中记录的 UndoNxtLSN 开始逆序 UNDO 所有可被 UNDO 的日志记录,并为其记录 REDO 日志(即 CLR 日志)。该 CLR 日志的 UndoNxtLSN 为原日志的 PrevLSN。因为 CLR 日志为 Redo-Only,因此,当 Rollback 过程中遇到 CLR 日志时,会直接跳过.
如果当前 UNDO 的原日志为非 CLR 日志,则下一个待 UNDO 的日志为当前原日志的 PrevLSN。 如果当前 UNDO 的原日志为 CLR 日志,则下一个待 UNDO 的日志为当前日志的 UndoNxtLSN(这将跳过已经被 UNDO 的日志).
RollBack 伪代码如下:
下图展示了事务在回滚过程中的操作逻辑:
为了减少重启恢复过程中需要处理的 WAL 日志的数量,ARIES 定期在 WAL 日志中记录 Checkpoint 信息.
Checkpoint 日志以 begin_chkpt 为起点,以 end_chkpt 为结束,记录当前 ATT, DPT 的信息,以及当前正在使用的文件映射信息等。只有当 end_chkpt 完全写入的 Checkpoint 才是完整的,否则该 Checkpoint 信息将会被忽略.
Checkpoint 构建和写入过程中,并不阻塞其他的事务操作。比如下图中, Checkpoint 的 begin_chkpt 和 end_chkpt 之间还有其他事务的日志写入。既有 begin_chkpt 之前发起的事务 T1 的日志,也有 begin_chkpt 之后发起的事务 T2 的日志。它们既可以在 end_chkpt 之前结束(T2),也可以在 end_chkpt 之后结束(T1).

ARIES 在构建 Checkpoint 过程中,并不需要强制 Dirty Page flush 到可持久化存储。因为 flush 操作由 Buffer Manager 按照其策略自动执行,而 Checkpoint 只负责将当前时间节点下的 flush 状态和其他必要信息记录下来,以便后续快速恢复.
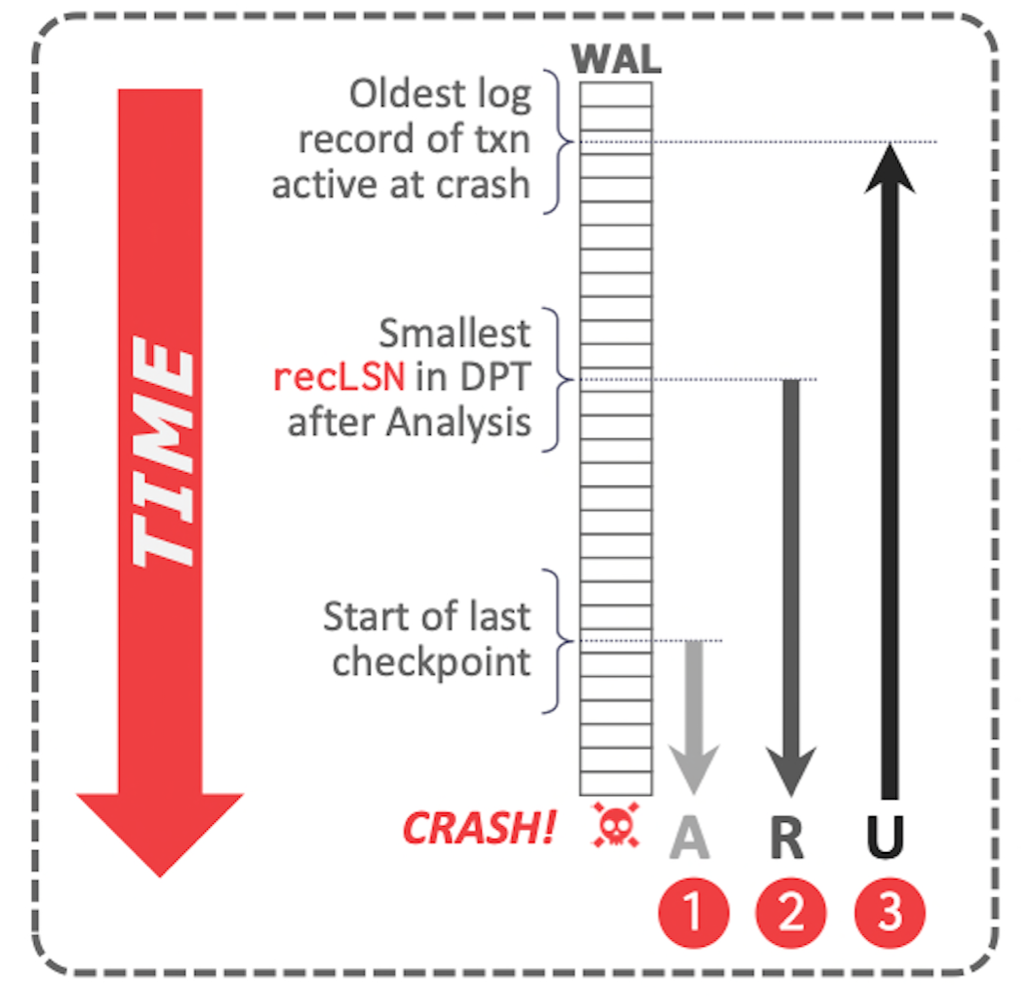
当系统重启,先从 MasterRecord 中读取到系统终止前最新的完整记录的 Checkpoint 的起始 LSN,然后依次执行重启 Analysis 和重启 Redo 并更新 DPT,接着执行重启 Undo,并为所有的 prepare 状态的事务重新获取 lock。最后记录新的 Checkpoint 记录重启流程的处理结果。伪代码如下图:

分析阶段会传入 MasterRecord 的 LSN,并返回恢复后的 DPT 和 ATT,以及 REDO 开始的位置 RedoLSN.
初始化阶段,通过 MasterRecord 的 LSN 读取到 MasterRecord,然后利用 MasterRecord 记录的最新 Checkpoint 的 begin_chkpt 的位置。然后,从 CheckPoint 的 begin_chkpt 开始分析 WAL 日志,直到 WAL 日志结束(end of log).
在日志分析过程中,如果遇到 WAL 日志对应的事务不在 ATT 中,则将其加入 ATT。当分析的日志为 end_chkpt, 则通过 Checkpoint 日志记录的信息,恢复 ATT 和 DPT 的数据。如下图伪代码所示:
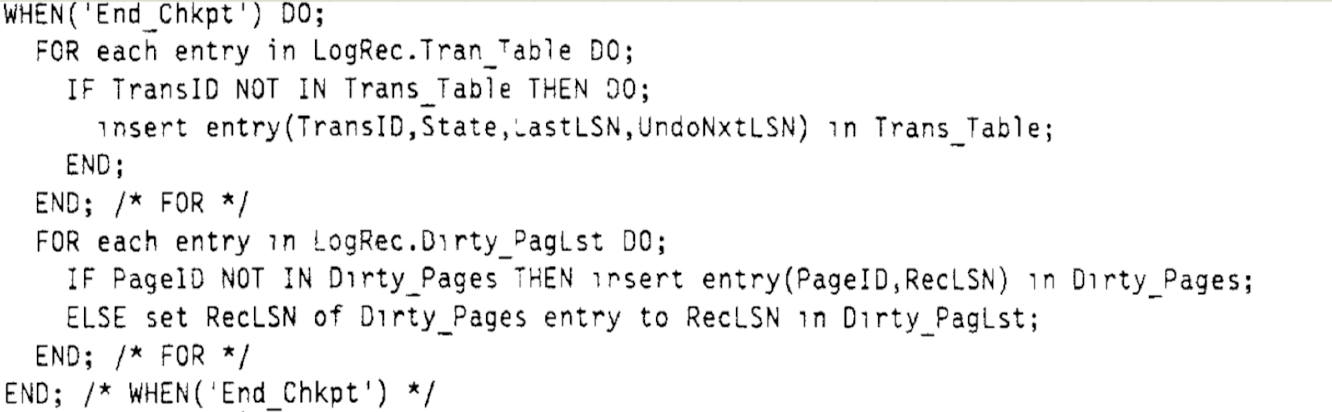
如 Normal Processing 所介绍那样, Checkpoint 日志写入期间,可能会并发存在其他并发写入事务的日志。因此,在恢复 DPT 时,如果发现某个 Dirty Page 已经写入被其他日志恢复到 DPT, 则只需要更新 DPT 中 该 Dirty Page 的 RecLSN 为 Checkpoint 记录的 Dirty Page 的 RecLSN.
当分析的日志为 Update 或 CLR 日志,则在 Restart Redo 阶段需要对它进行 REDO。因此在 DPT 中,如果不存在该日志对应的 Page,则需要将该日志对应的 Page 插入 DPT 中(该 Page 将在 Redo 阶段变更).
同时,在 ATT 中更新当前日志对应事务的 LastLSN 为当前日志的 LSN(事务最新日志的 LSN)。如果当前日志为 Update 且是可 Undo 的,则记录将 ATT中该事务的 UndoNxtLSN 更新为当前日志的 LSN。如果当前日志为 CLR 日志,则该事务的 UndoNxtLSN 为当前日志的 UndoNxtLSN.
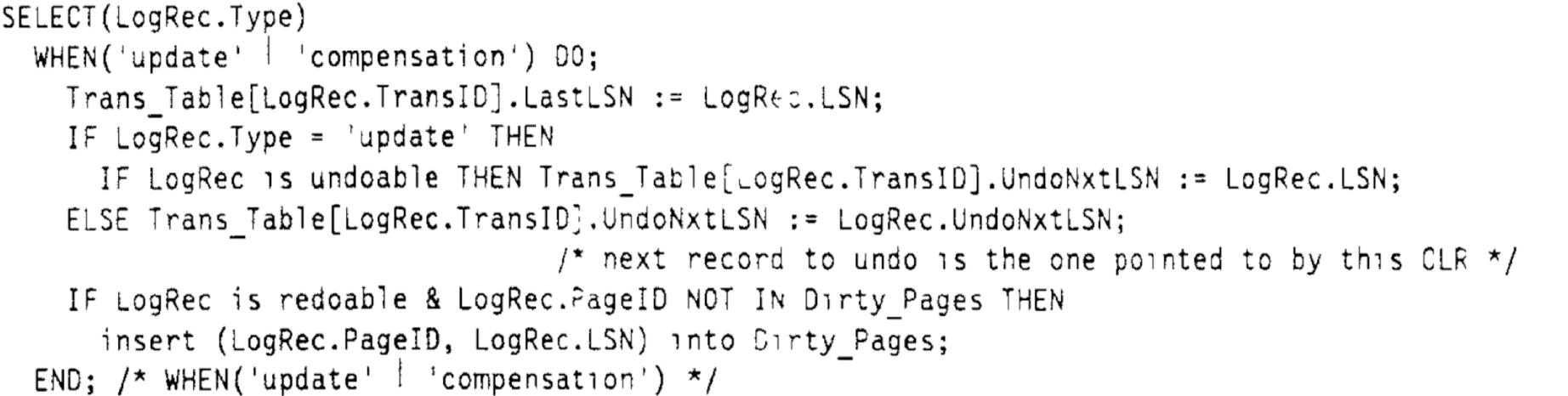
当分析到事务的 Prepare/Rollback 操作日志时,会将 ATT 表中当前日志对应事务的 LastLSN 设为当前日志的 LSN。同时,如果当前日志为 Prepare,将 ATT 中对应的 State 设为 “P(Prepared)”。 如果当前日志为 Rollback,则将 ATT 中对应 State 设为 “U(Unprepared)”。在 Undo 阶段, 所有处于 “U” 状态的事务,都将被回滚.
事务的 end 日志,表示事务已经成功的提交,因此不需要再 ATT 中维护这个事务。因此当分析到 end 日志时,直接在 ATT 中删除对应事务.

在分析阶段的最后,将 Redo 日志的起始位置 RedoLSN 设为 DPT 中所有 Dirty Page 的 RecLSN 的最小值。(如果 DPT 为空,则表示没有需要 Redo 的日志,可以跳过 Redo 阶段).
完整伪代码如下:

Redo 阶段以分析阶段生成的 RedoLSN 和 DPT 为输入,从 RedoLSN 开始扫描处理日志,直到最后一条日志.
当遇到Redo 的日志记录时,会检查对应的 Page 是否在 DPT 中存在。如果存在,并且当前日志的 LSN 大于或等于表中该页的 RecLSN,那么该日志可能需要被 Redo。继续读取该页的 PageLSN, 如果 PageLSN 小于当前日志的 LSN,则该日志需要重做。否则忽略该日志, 。
为什么某个 Page 的 PageLSN 可能会不小于它在 DPT 的 RecLSN ?
因为 PageLSN 记录的事实际 flush 到 Page 的 LSN, 而 RecLSN 记录的是 Checkpoint 恢复的 Dirty Page 信息。由于 Page Flush 和 Checkpoint 的 Flush 完全并行,互不影响, 因此可能存在 Checkpoint Flush 之后,再次执行了 Page Flush ,导致恢复的 Checkpoint Dirty Page 信息延迟与实际 Page Flush 的信息。因此 DPT 的 RecLSN 小于实际的 PageLSN.
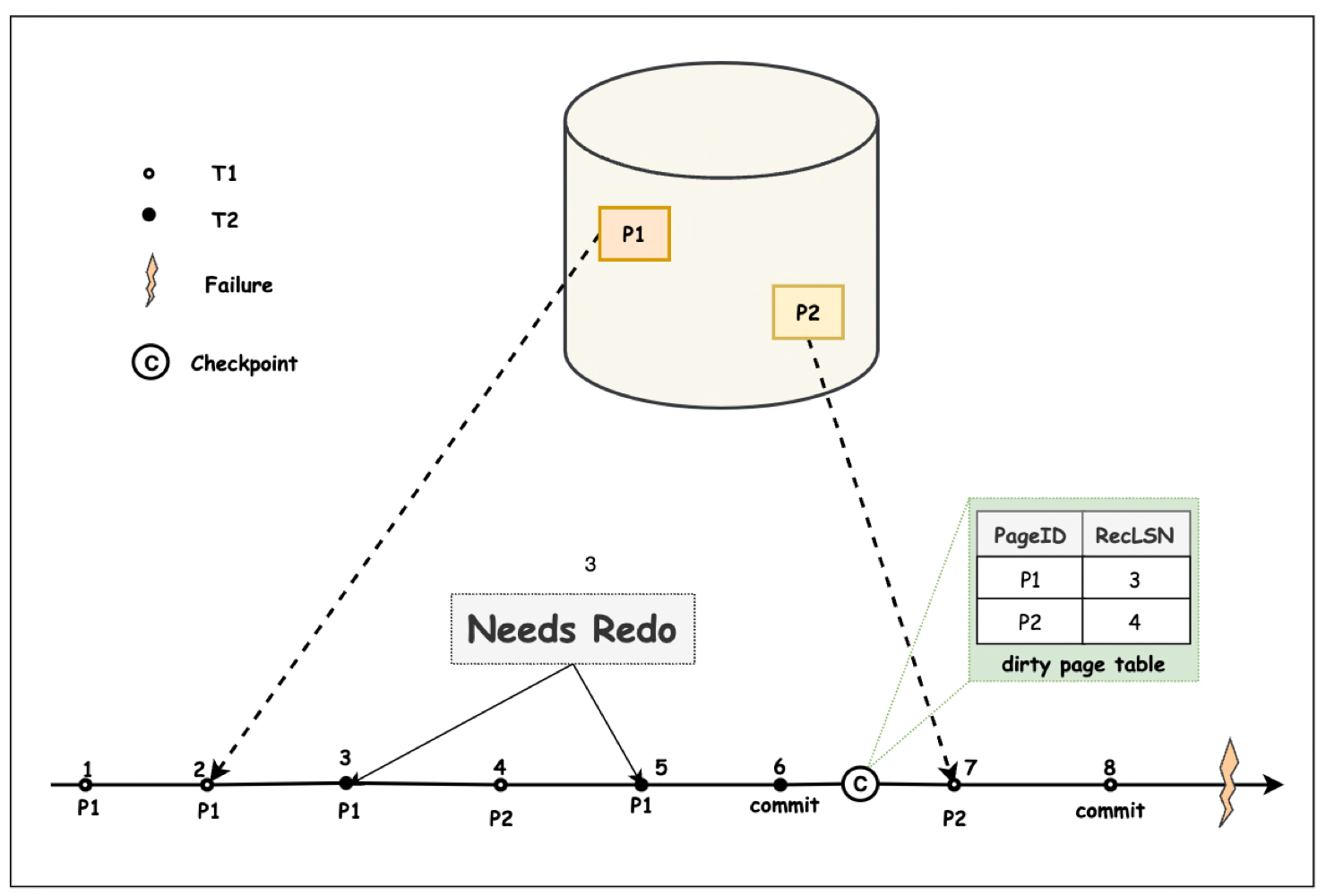
如上图,空心点表示事务 T1 的 WAL 日志, 实心点表示 T2 的日志。虚线箭头表示持久化存储中的 P1, P2 当前 flush 的数据对应的最新的 LSN(即,PageLSN)。 可以看到在系统 Failure 时, 持久化存储中的 P1 的 PageLSN 为 2, P2 的 PageLSN 为 7.
根据分析阶段的结果, 在 Redo 时,会从 DPT 中最小的 RecLSN 作为 Redo 操作的起始日志 RedoLSN。在本例中 RedoLSN=3.
Redo 阶段,从 Failure 前最新的 Checkpoint 记录恢复的 DPT 中,P2 的 RecLSN 为 4(这个 Checkpoint 不知道在 LSN=7 处的日志已经 flush)。而P2 对应的 PageLSN 实际上为 7。此时的 P2 的 RecLSN <= PageLSN,因此 LSN 为 4 的操作已经被 flush 到持久化存储,不需要 Redo。同理,也不需要 Redo LSN=7 的日志.
而 Checkpoint 记录的 P1 的 RecLSN=3,大于 P1 flush 到 Page 的 LSN(PageLSN = 2)。因此,LSN 为 3, 5 的 WAL 日志对 P1 的变更还未被 flush 到持久化存储,需要被 Redo.
在 Redo 阶段执行的操作都不会记录在 WAL log 中,因为它本身就是在 Redo 之前的 Redo Log(即执行的操作已经记录).
Redo 的完整伪代码如下:

Undo 阶段,以 ATT 作为参数,每次从 ATT 中读取失败事务(待回滚)最大的 UndoNxtLSN 处理,直到所有的回滚事务已经处理完成。伪代码如下:

Undo 阶段对待回滚事务的处理和 Normal Processing 的回滚操作一样。如果当前 UNDO 的原日志为非 CLR 日志,则下一个待 UNDO 的日志为当前原日志的 PrevLSN。如果当前日志为可 Undo 日志,则为其执行 Undo 操作,并记录该操作的 CLR 日志。 如果当前 UNDO 的原日志为 CLR 日志,则下一个待 UNDO 的日志为当前日志的 UndoNxtLSN(这将跳过已经被 UNDO 的日志).
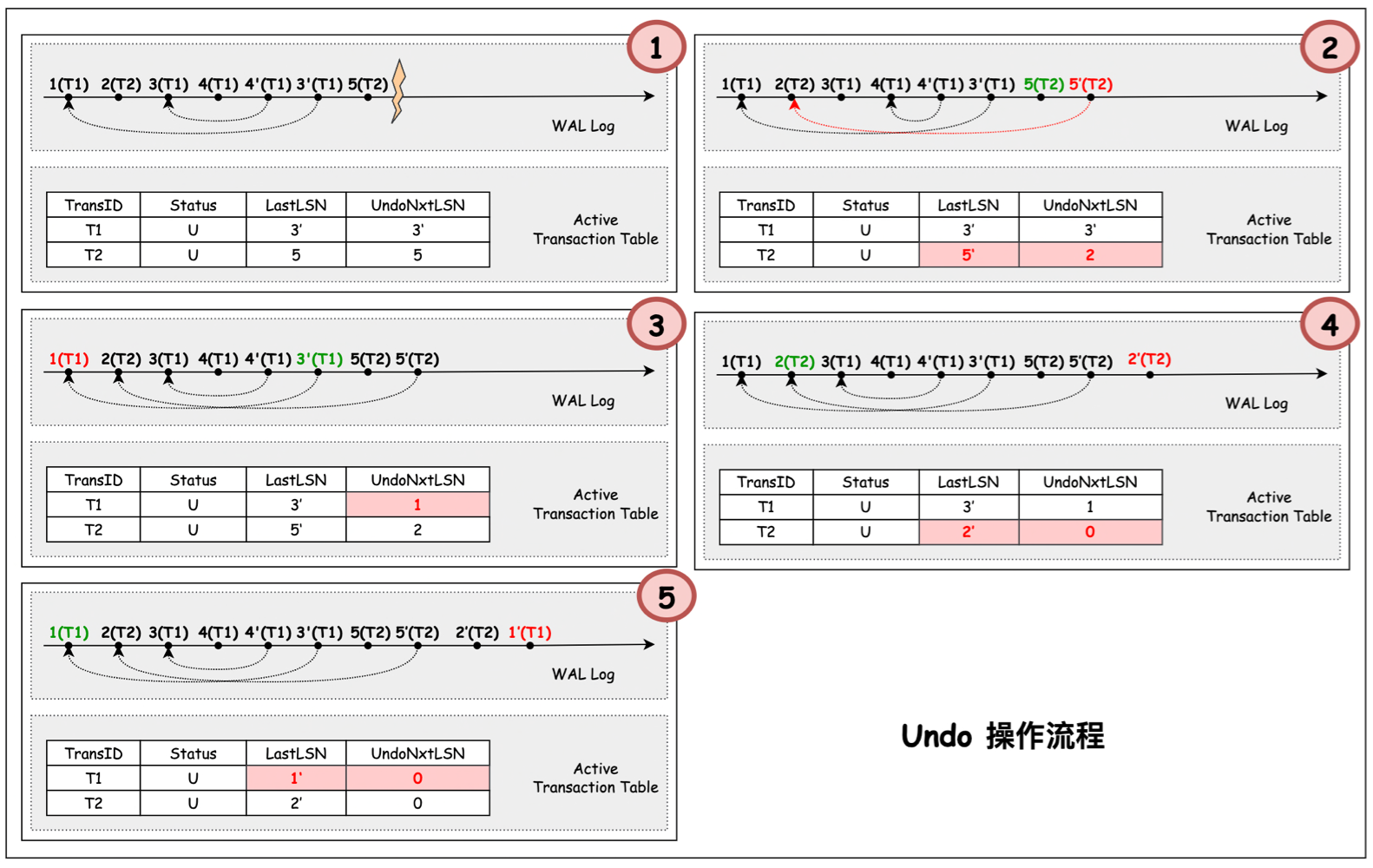
下图 demo 中,描述了 ARIES 重启恢复中的单个事务的回滚流程.
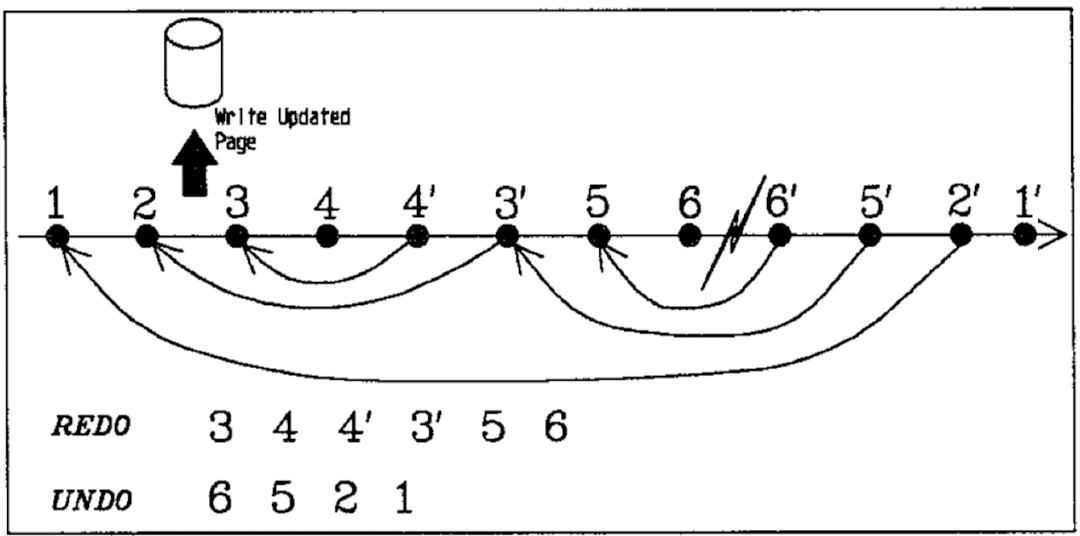
在正常运行状态下, 事务 partial rollback 对 WAL 日志 3, 4 执行了 UNDO 操作,产生了 CLR 日志 4’ 3’。接着继续推进事务写入 WAL 日志 5,6。在 6 写入持久化存储之后,系统由于某些原因导致了重启。此时, 最新记录的 Checkpoint 的 DPT 中最小 RecLSN 为 2.
ARIES 在 Restart Recovery 时, 会从 3 开始 REDO, 直到日志的结尾。即,3,4,4’, 3’,5,6.
然后再 Undo 阶段, 从 6 开始 undo,产生 CLR 6’。然后是对 5 undo 产生 CLR 5’。 接着在处理 3’ 时,发现它为 CLR 日志,因此直接跳转到它的 UndoNxtLSN(2) 继续处理。依次对 2,1 undo 并产生 CLR 日志 2’,1’ ,完成 Recovery Restart 流程.
上图所示, 。
最后此篇关于万字长文解析最常见的数据库恢复算法:ARIES的文章就讲到这里了,如果你想了解更多关于万字长文解析最常见的数据库恢复算法:ARIES的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
27
4
 0
0
a = [ "a", "b", "c", "d", "e" ] 这两种说法有什么区别? a[1,3] #=> [ "b", "c", "d" ] 对比 a[1..3]
我按照此处的教程 (https://github.com/apache/aries-jpa/tree/master/examples) 运行 aries-jpa 示例,但没有成功。 README.md
万字长文解析最常见的数据库恢复算法: ARIES 首发地址: https://mp.weixin.qq.com/s/Kc13g8OHK1h_f7eMlnl4Aw Intro
我想知道是否有人有录制 ARI 桥来分离文件、未混合的经验(或至少分离立体声文件的 L 和 R channel )。似乎这可以通过记录单独的 channel 来实现,但这些 channel 无法桥接。
我正在尝试使用 ARI API 发起调用,我遵循的过程是 POST/ari/channels 创建 channel 1 到本地扩展 POST/ari/bridges 创建网桥 POST/ari/bri
我正在尝试使用 Asterisk ARI 来监视与桥相关的事件。我正在使用 Asterisk 13.6.0。 具体来说,我想知道桥何时创建或销毁,以及用户( channel )何时加入或离开桥。在我的
为什么在聚类方法中使用调整兰德指数 (ARI) 和归一化互信息 (NMI) 比简单的测试分数(例如 MSE)能获得更好的测量结果?我明白哪个点属于哪个簇在聚类算法中很重要,并且标记是任意的。 最佳答案
给定一棵 n 元整数树,任务是找到一个子序列的最大和,其约束条件是序列中的任何 2 个数字都不应共享树中的公共(public)边。例子: 1个 /\ 2 5 /\ 3 4最大非相邻和 = 3 + 4
我无法通过控制台浏览器(lynx、elinks)在 ARI 中进行身份验证 cat/etc/asterisk/ari.conf : [general] enabled = yes pret
如果 Aries 算法已经知道在分析阶段后要撤消哪些事务,为什么要在撤消之前应用重做? 我知道(认为)它与 Lsn 编号和保持一致性有关,因为鉴于磁盘上刷新的数据可能与崩溃时撤消事务不同,撤消事务(由
在ARIES algorithm ,为什么它需要在重做通行证中重复崩溃前的所有历史记录?我可以在分析过程中获取提交的事务编号,然后重做提交的事务日志记录吗?这种方法将减少需要重做和撤消的记录数。 最佳
我目前正在为 asterisk 开发静音功能,我可以使用 asterisk ARI 从我的 Web 前端运行它。 但每次我尝试运行/调用静音函数时,都会出现以下错误: Error: { "mess
我想接受一个返回元组的函数。有没有办法描述函数的返回元组长度? 最佳答案 似乎不是。可能是因为它在形式逻辑中不是必需的,因为使用了 2 个函数而不是一个具有两个输出的函数。 如果 arity 或 ad
我用Java编写了一个K-ary树结构的程序,所以我试图找到树的叶子数.. import java.util.List; import java.util.ArrayList; /** A tree
我正在遵循位于:Camel MyBatis Integration Guide 的设置指南。我正在使用服务混合 5.0.1。我使用了 features-install spring-mybatis 来
计算ARI时与 scikit's implementation ,我注意到一个奇怪的情况。对于某些看起来标签上高度一致的列表,ARI 仍然是 0.0 甚至更糟。 我尝试了几种标签,以下是观察到的最奇怪
我想找出一个函数 f(x) 来计算 k 叉树中的叶子数。例如,假设我们创建了一棵树,它以根 4 开始,有 3 个 child ,每个 child 分别为 -1、-2、-3。我们的叶子只会是 0 值,而
我正在尝试用 C++ 设计一个树类,但我遇到了节点销毁的问题。 如果我销毁一个节点,我不想销毁它的整个子树,因为可能有其他东西指向它。所以显而易见的解决方案是使用引用计数。我会有一个指向父节点的弱指针
我在销毁树时遇到删除节点的问题。每个节点都是在我的 Tree 类中定义的结构: struct node { Skill skill; node** child; node
我正在尝试编写一个程序,将家谱表示为 n 叉树。该程序必须从 CSV 文件中读取名称并构建树。树由以下结构表示: typedef struct NTree_S { char * na

我是一名优秀的程序员,十分优秀!