
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 27
27
 4
4


由于项目场景原因,需要将A库(MySQL)中的表a、表b、表c中的数据 定时T+1 增量 的同步到B库(MySQL)。这里说明一下,不是数据库的主从备份,就是普通的数据同步。经过技术调研,发现Kettle挺合适的,原因如下:
官网地址: https://sourceforge.net/projects/pentaho/files/Data%20Integration/ 。
出现以下图片表示正在启动, 如果一直没有反应,使用管理员身份运行 .

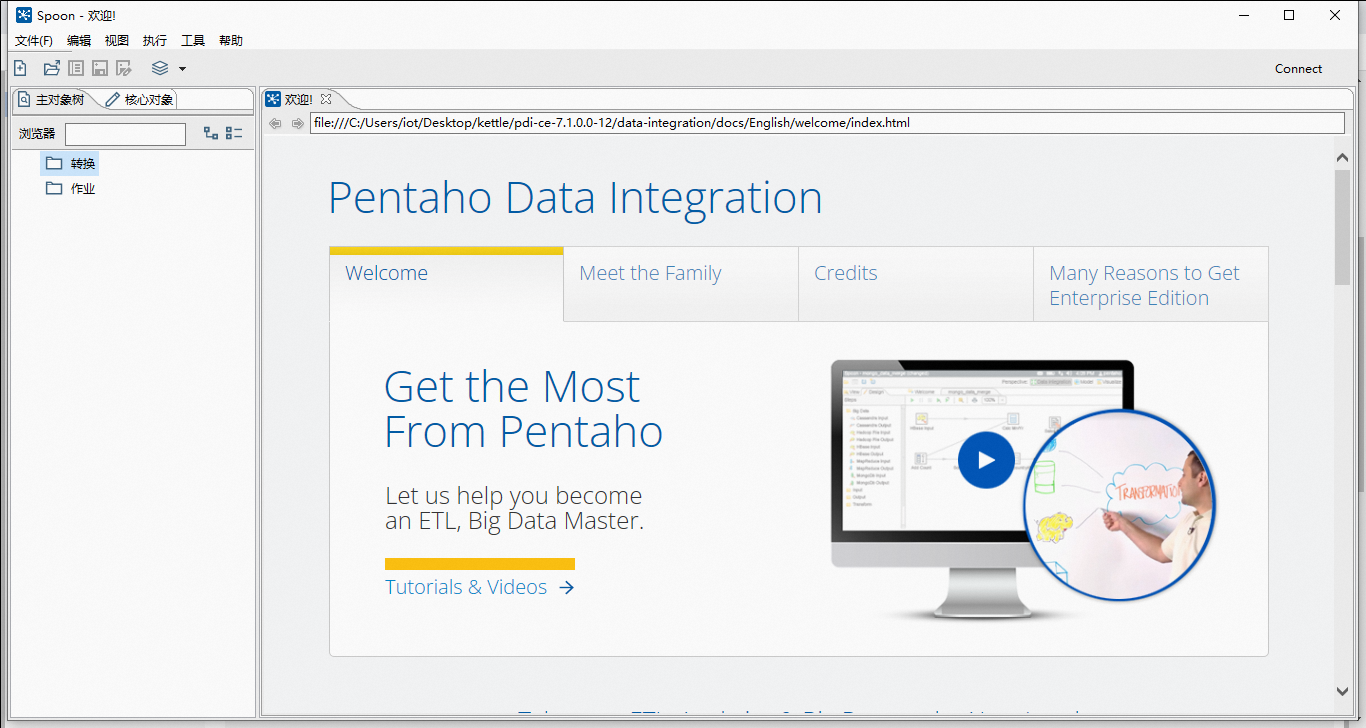
主界面如下:
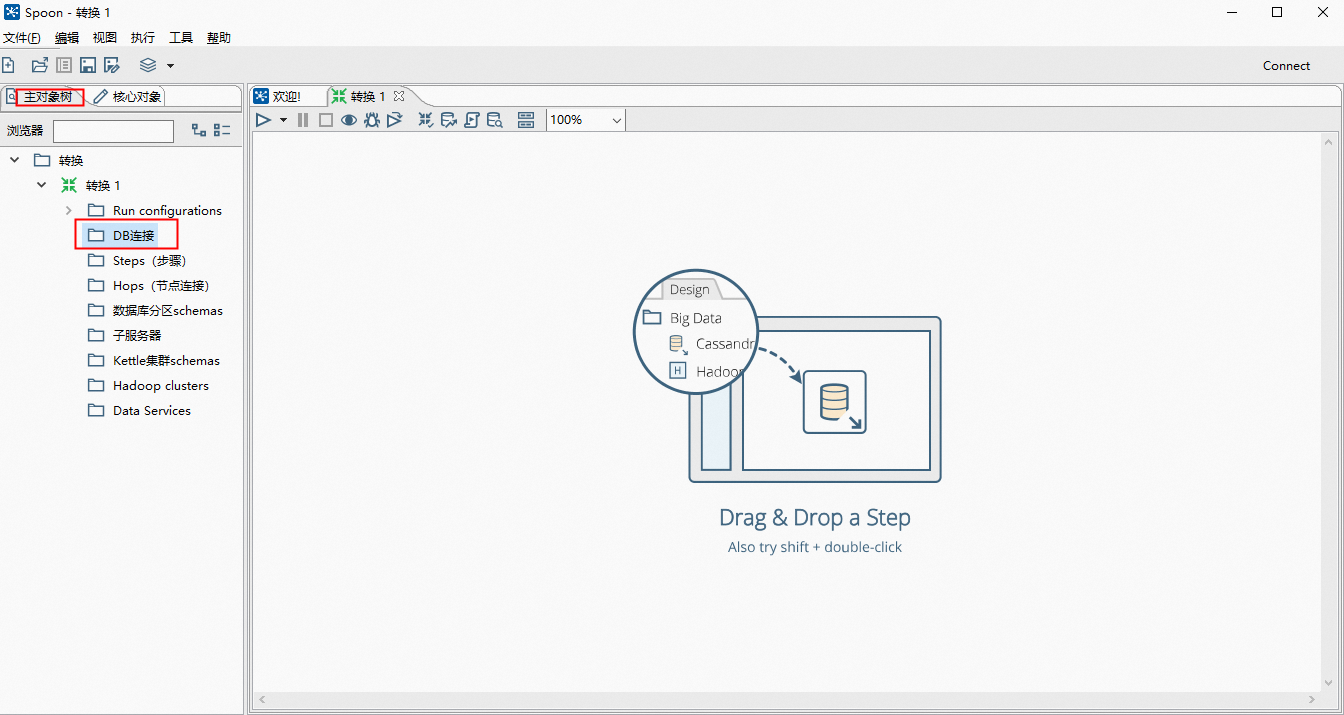
由于Kettle自身是不带任何数据库驱动包的,所以这里我们需要先自己准备好驱动包,版本最好选择5.1.49。下载好jar包后,拷贝到lib目录下(Windows和Linux同理)。如果已经启动了Kettle,则需要关掉重新启动,否则驱动包不会被加载.

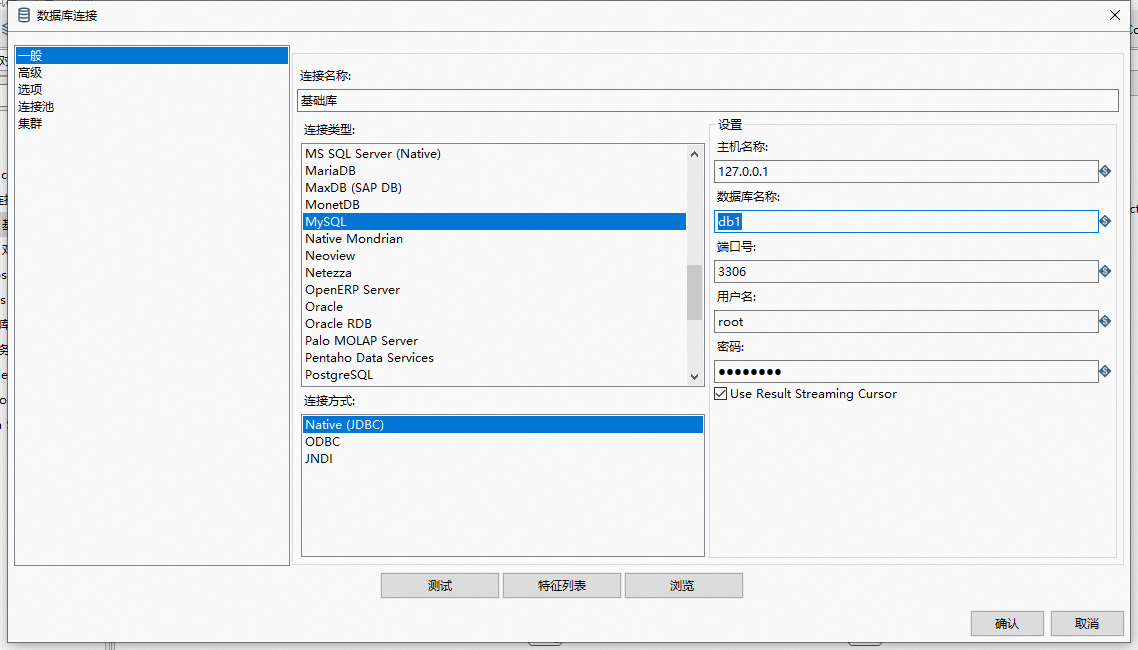
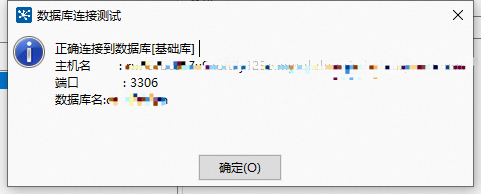
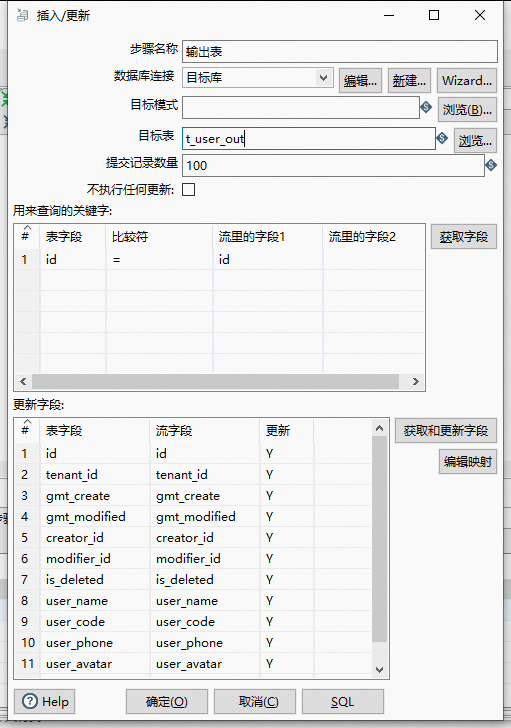
同上操作,创建好两个数据源:源数据库、目标库;目标就是将源数据库中的表数据同步到目标库中去 。

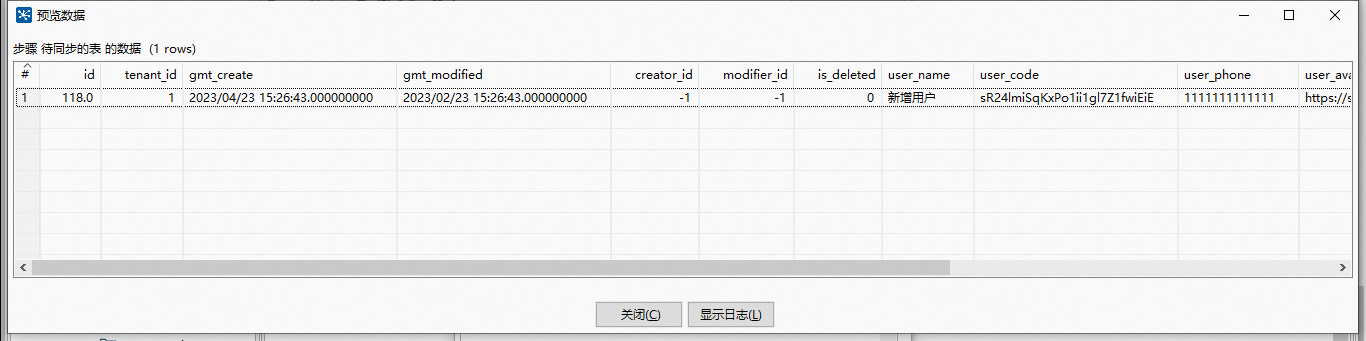
这里因为我是 定时T+1 增量 同步数据,所以我加了个同步条件 WHERE gmt_create >= CURDATE() 表示该数据创建时间大于当天才会进行查询.
点击预览,正好有一条数据 。
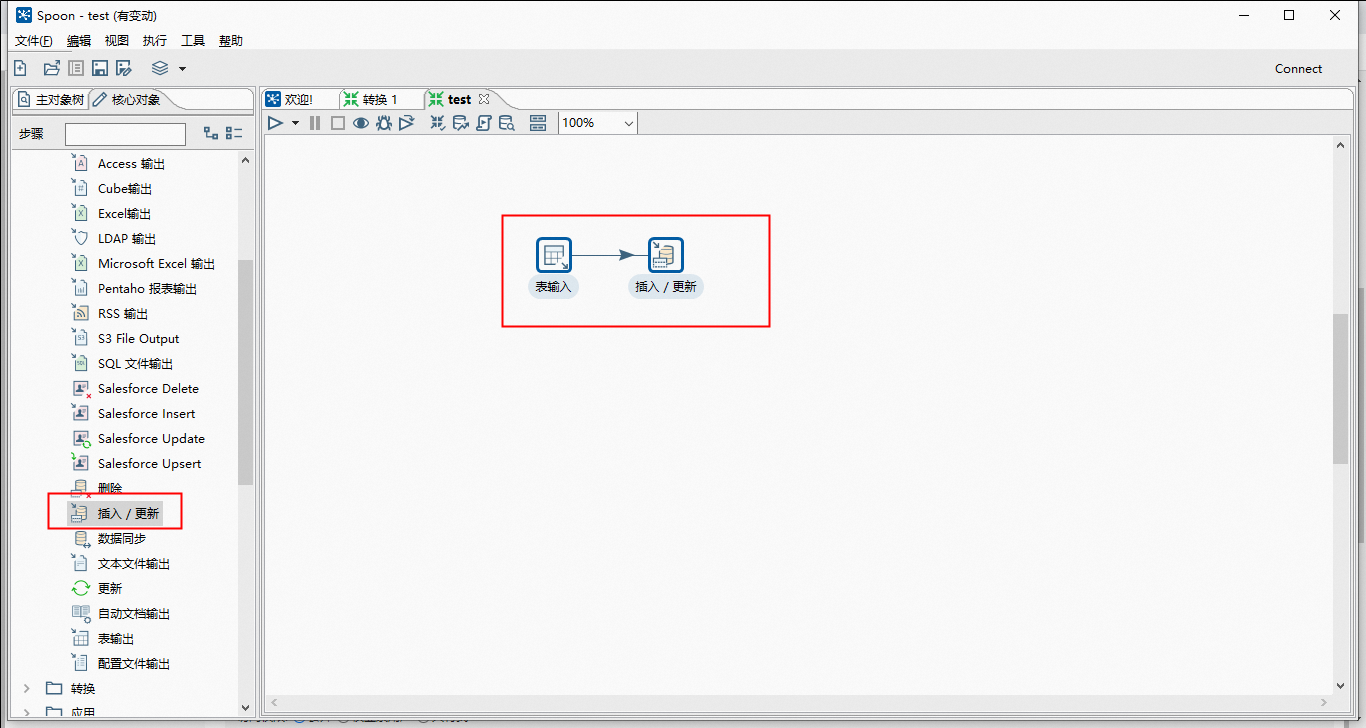
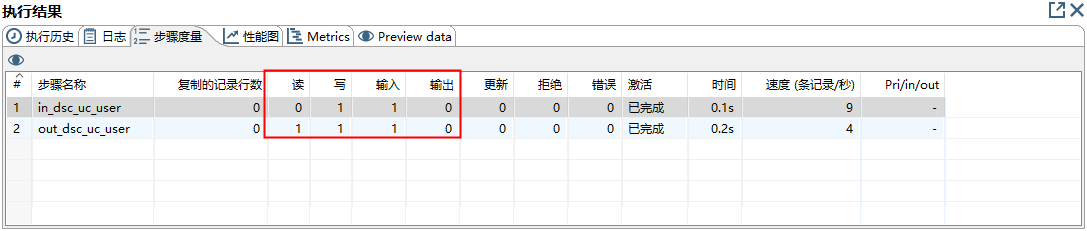
在Linux上,ktr文件使用Kettle的pan.sh脚本运行,命令大致如下:sh /home/admin/kettle/data-integration/pan.sh -file=/home/admin/kettle/ktr/table_transfer.ktr -norep。同时为了实现定时执行这个脚本,我打算用Linux自带的corntab功能设置定时.
首先我编写了一个shell脚本,命名为cornSql.sh,用于保存ktr的执行命令,内容如下:
#!/bin/bash
export KETTLE_HOME=/home/admin/kettle/data-integration
export JAVA_HOME=/usr/java/jdk1.8.0_131
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin:${KETTLE_HOME}
export JRE_HOME=${JAVA_HOME}/jre
TIME=$(date "+%Y%m%d")
sh /home/admin/kettle/data-integration/pan.sh -file=/home/admin/kettle/ktr/table_transfer.ktr -norep >>/home/admin/kettle/log/transfer-"$TIME".log
其次,将ktr脚本拷贝到指定目录下,也就是/home/admin/kettle/ktr目录下,输入 crontab -e ,再输入 0 1 * * * /home/admin/kettle/cornSql.sh ,这句话的意思是 每天凌晨1点定时执行cornSql.sh脚本 为了检查定时配置是否生效,这里可以使用 crontab -l -u root 命令,如果刚才的定时指令有打印出来,则证明配置生效.
最后,第二天检查一下执行日志文件有没有生成,在/home/admin/kettle/log目录下,这里我把每天执行的日期打印出来了,如下图:
作者: 不若为止 欢迎任何形式的转载,但请务必注明出处。 限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教.
最后此篇关于使用Kettle定时从数据库A刷新数据到数据库B的文章就讲到这里了,如果你想了解更多关于使用Kettle定时从数据库A刷新数据到数据库B的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
27
4
 0
0
我使用 java 编写了一些自定义代码。我想在代码片段部分将代码添加到 Kettle 中用户定义的 java 类。有没有办法在 UDJC 的类和代码片段中添加自定义代码片段,以便它可以重用。谢谢。 最
我是 Kettle 的新手,需要一些帮助来正确设置它。我试图将 Kettle 指向 SVN 存储库。目前,我只有以下文件夹。 D:\ETL\data-integration\ D:\ETL\.kett
在 Spoon 中创建新对象时,有两种可能性:作业和转换。他们有一组不同的可能组件(尽管有一定程度的重叠),并且生成的 XML 看起来非常相似。这两者有什么区别? 最佳答案 这也是我在开始使用 Pen
我正在使用kettle转换将CSV文件数据存储到数据库中。我的客户要求是将相同的CSV文件动态存储到不同的数据库(例如:Oracle和postgres)中。如何实现这一点?我尝试过kettle Job
我正在使用 Kettle 读取 Excel 工作表,该工作表包含三个字段:代码、描述和日期。 示例: 1 - description A - 01/JAN/2013 2 - description A
我需要找到多个开始结束日期行之间的间隔(每个 PK 最多可以有 4 行)。我输入了组合 PK - 开始日期 - 结束日期,我需要以某种方式检查这些日期之间是否有任何间隔。例如: PK
我想从 table1 映射具有以下结构的字符串: Table1 id
我在哪里可以找到 Pentaho Kettle 架构?我正在寻找一个简短的 wiki、设计文档、博客文章,任何可以很好地概述事物如何工作的东西。这个问题不是针对特定的“如何”入门指南,而是对技术和 的
我们有一个 Pentaho 作业,它在本地环境中运行良好,但在部署它并使用 Kettle 运行该作业后,我们在写入日志文件时遇到错误。该错误发生在具有“针对每个输入行执行?”设置的作业中。检查过。以下
是否可以从Java应用程序运行Kettle作业/转换,然后在同一个Java应用程序中获取结果(例如变量)? 最佳答案 尽管从 Java 执行命令行可能并不理想,但下面的方法可以工作。只需将 cmd 行
每当我从命令行而不是在 Spoon UI 中运行提取时,我都会收到此错误。 Missing plugins found while loading a transformation Step : Mo
Pentaho Data Integration 又名 Kettle 适合基于流的编程 FBP 吗? Kettle 是一个 ETL(提取、转换和加载)工具,基于 FBP concepts 有User
我正在寻找一个在 Pentaho Data Integration 中执行 SSIS 查找的解决方案。我将尝试用一个例子来解释:我有两张表A和B。这里,表A中的数据:12345这里,表B中的数据:34
我有一个奇怪的问题,我在java上做了一个小软件,它执行我在kettle中做的一些工作。现在,转换进展顺利,一切正常,但是当我执行转换时,我想在转换过程中显示一条消息 public Wait(){
我在 pentaho 中遇到了一些问题,我不完全确定 pentaho 是否能够处理这个问题。我会尽力解释。 因此,我的事实销售中有一个名为引用号的列,我必须使用它从维度表中查找 ID 并返回 ID。但
当我将 mysql 数据库转换为 postgres 时遇到问题。 mysql 表名和列都是大写的,但是当我运行这个作业时,kettle 创建的 postgres 表都是小写的。 tableoutput
我有一个 postgres 数据库,我使用 Pentaho Data Integration (Kettle) 进行 ETL。 使用具有以下配置的插入/更新框配置数据加载。 但是,我从数据库中收到此错
我是 Pentaho 的 GeoKettle (Spoon) 新手,目前正在将 Excel 文件中的行写入数据库。现在我想避免数据库表中出现重复项。这就是为什么我只想将那些尚不存在的行插入到我的数据库
我有很多数据库 (+100),每个数据库都具有相同的结构和不同的连接。我正在使用 Kettle 在不同的数据库中运行转换以创建数据仓库。 如何使用不同的连接自动运行相同的转换? 我已经证明了这一点Pa
我有一个使用名为 Geometry 的自定义数据类型的 Kettle 步骤。我有以下代码行从第一行获取元信息: geometryInterface = data.prevRowMeta.getValu

我是一名优秀的程序员,十分优秀!