
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4


新内容 (06/2023) : 这篇博文受到 “在多语言 ASR 上微调 XLS-R” 的强烈启发,可以看作是它的改进版本.
Wav2Vec2 是自动语音识别 (ASR) 的预训练模型,由 Alexei Baevski、Michael Auli 和 Alex Conneau 于 2020 年 9 月 发布。其在最流行的 ASR 英语数据集之一 LibriSpeech 上展示了 Wav2Vec2 的强大性能后不久, Facebook AI 就推出了 Wav2Vec2 的两个多语言版本,称为 XLSR 和 XLM-R ,能够识别多达 128 种语言的语音。XLSR 代表 跨语言语音表示 ,指的是模型学习跨多种语言有用的语音表示的能力.
Meta AI 的最新版本, 大规模多语言语音 (MMS) ,由 Vineel Pratap、Andros Tjandra、Bowen Shi 等人编写。将多语言语音表示提升到一个新的水平。通过发布的各种 语言识别、语音识别和文本转语音检查点 ,可以识别、转录和生成超过 1,100 多种口语.
在这篇博文中,我们展示了 MMS 的适配器训练如何在短短 10-20 分钟的微调后实现惊人的低单词错误率.
对于资源匮乏的语言,我们 强烈 建议使用 MMS 的适配器训练,而不是像 “在多语言 ASR 上微调 XLS-R” 中那样微调整个模型.
在我们的实验中,MMS 的适配器训练不仅内存效率更高、更稳健,而且对于低资源语言也能产生更好的性能。对于中到高资源语言,微调整个检查点而不是使用适配器层仍然是有利的.
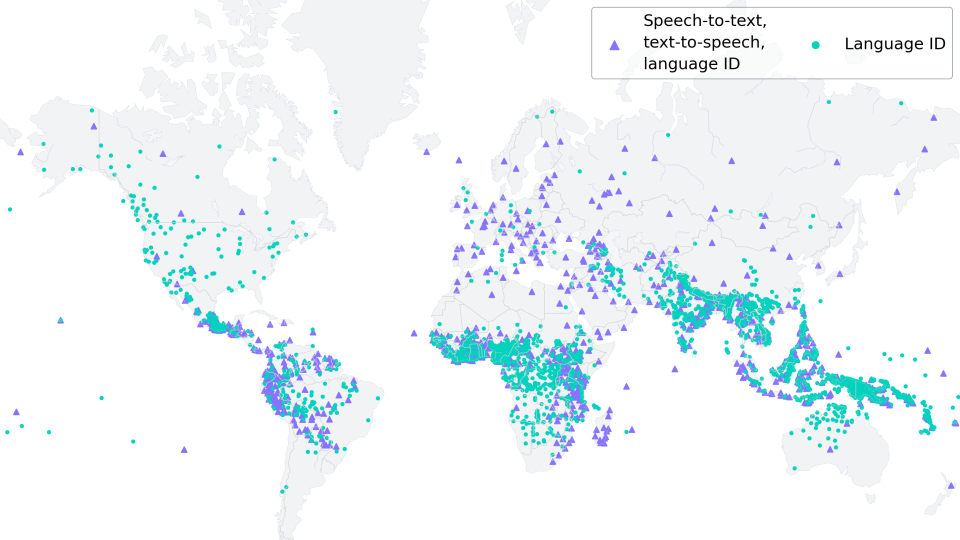
根据 https://www.ethnologue.com/ 的数据,大约 3000 种语言 (即所有“现存”语言的 40%) 由于母语人士越来越少而濒临灭绝。这种趋势只会在日益全球化的世界中持续下去.
MMS 能够转录许多濒临灭绝的语言,例如 Ari 或 Kaivi 。未来,MMS 可以通过帮助剩余的使用者创建书面记录并用母语进行交流,这在保持语言活力方面发挥至关重要的作用.
为了适应 1000 多个不同的词汇表, MMS 使用适配器 (Adapters) - 一种仅训练一小部分模型权重的训练方法.
适配器层就像语言桥梁一样,使模型能够在解读另一种语言时利用一种语言的知识.
MMS 无监督检查点使用 1,400 多种语言的超过 50 万 小时的音频进行了预训练,参数范围从 3 亿到 10 亿不等.
你可以在 🤗 Hub 上找到 3 亿个参数 (300M) 和 10 亿个参数 (1B) 模型大小的仅预训练检查点
mms-300m mms-1b 注意 : 如果你想微调基本模型,可以按照 “在多语言 ASR 上微调 XLS-R” 中所示的完全相同的方式进行操作.
与 BERT 的掩码语言建模目标 类似,MMS 通过随机遮蔽特征向量来学习上下文语音表示,然后在自监督预训练期间将其传递到 Transformer 网络.
对于 ASR,预训练 MMS-1B 检查点 通过联合词汇输出层以监督方式对 1000 多种语言进行了进一步微调。最后一步,联合词汇输出层被丢弃,并保留特定于语言的适配器层。每个适配器层 仅 包含约 2.5M 权重,由每个注意力块的小型线性投影层以及特定于语言的词汇输出层组成.
已发布针对语音识别 (ASR) 进行微调的三个 MMS 检查点。它们分别包括 102、1107 和 1162 个适配器权重 (每种语言一个)
mms-1b-fl102 mms-1b-l1107 mms-1b-all 你可以看到基本模型 (像往常一样) 保存为文件 model.safetensors ,但此外这些存储库还存储了许多适配器权重, 例如 针对法国的 adapter.fra.safetensors .
Hugging Face 文档很好地 解释了如何使用此类检查点进行推理 ,因此在这篇博文中,我们将重点学习如何基于任何已发布的 ASR 检查点有效地训练高性能适配器模型.
在机器学习中,适配器是一种用于微调预训练模型同时保持原始模型参数不变的方法。他们通过在模型的现有层之间插入小型可训练模块 (称为 适配器层 ) 来实现此目的,然后使模型适应特定任务,而无需进行大量的重新训练.
适配器在语音识别,尤其是 说话人识别 方面有着悠久的历史。在说话人识别中,适配器已被有效地用于调整预先存在的模型,以识别单个说话人的特质,正如 Gales 和 Woodland (1996) 以及 Miao 等人 (2014) 的工作中所强调的那样。与训练完整模型相比,这种方法不仅大大降低了计算要求,而且使得特定于说话者的调整更好、更灵活.
MMS 中完成的工作利用了跨不同语言的语音识别适配器的想法。对少量适配器权重进行了微调,以掌握每种目标语言独特的语音和语法特征。因此,MMS 使单个大型基础模型 ( 例如 mms-1b-all 模型检查点) 和 1000 多个小型适配器层 (每个 2.5M 权重 mms-1b-all ) 能够理解和转录多种语言。这极大地减少了为每种语言开发不同模型的计算需求.
棒极了!现在我们了解其动机和理论,下面让我们研究一下 mms-1b-all 🔥的适配器权重微调 。
正如之前在 “多语言 ASR 上微调 XLS-R” 博客文章中所做的那样,我们在 Common Voice 的低资源 ASR 数据集上微调模型,该数据集仅包含 ca. 4 小时经过验证的训练数据.
就像 Wav2Vec2 或 XLS-R 一样,MMS 使用连接时序分类 (CTC) 进行微调,CTC 是一种用于训练神经网络解决序列到序列问题 (例如 ASR 和手写识别) 的算法.
有关 CTC 算法的更多详细信息,我强烈建议阅读 Awni Hannun 的写得很好的一篇博客文章 Sequence Modeling with CTC (2017) .
在我们开始之前,让我们安装 datasets 和 transformers 。此外,我们需要 torchaudio 来加载音频文件,以及使用 字错误率 (WER) 指标 ( {}^1 ) 评估我们微调后的模型,因此也需要安装 jiwer .
%%capture
!pip install --upgrade pip
!pip install datasets[audio]
!pip install evaluate
!pip install git+https://github.com/huggingface/transformers.git
!pip install jiwer
!pip install accelerate
我们强烈建议你在训练时将训练检查点直接上传到 🤗 Hub 。Hub 存储库内置了版本控制,因此你可以确保在训练期间不会丢失任何模型检查点.
为此,你必须存储来自 Hugging Face 网站的身份验证令牌 (如果你还没有注册,请在 此处 注册!) 。
from huggingface_hub import notebook_login
notebook_login()
ASR 模型将语音转录为文本,这意味着我们需要一个将语音信号处理为模型输入格式 (例如特征向量) 的特征提取器,以及一个将模型输出格式处理为文本的分词器.
在🤗 Transformers 中,MMS 模型同时伴随着一个名为 Wav2Vec2FeatureExtractor 的特征提取器和一个名为 Wav2Vec2CTCTokenizer 的分词器.
我们首先创建标记生成器,将预测的输出类解码为输出转录.
Wav2Vec2CTCTokenizer 微调的 MMS 模型,例如 mms-1b-all 已经有一个伴随模型检查点的 分词器 。然而,由于我们想要在某种语言的特定低资源数据上微调模型,因此建议完全删除分词器和词汇输出层,并根据训练数据本身创建新的.
在 CTC 上微调的类似 Wav2Vec2 的模型通过一次前向传递来转录音频文件,首先将音频输入处理为一系列经过处理的上下文表示,然后使用最终的词汇输出层将每个上下文表示分类为表示该字符的字符转录.
该层的输出大小对应于词汇表中的标记数量,我们将从用于微调的标记数据集中提取该词汇表。因此,第一步,我们将查看所选的 Common Voice 数据集,并根据转录定义词汇表.
对于本 notebook,我们将使用 Common Voice 的 6.1 土耳其语数据集。土耳其语对应于语言代码 "tr" .
太好了,现在我们可以使用 🤗 Datasets 的简单 API 来下载数据了。数据集名称是 "mozilla-foundation/common_voice_6_1" ,配置名称对应于语言代码,在我们的例子中是 "tr" .
注意 : 在下载数据集之前,你必须登录你的 Hugging Face 帐户,进入 数据集存储库页 面并单击“同意并访问存储库”来访问它 。
Common Voice 有许多不同的分割,其中包括 invalidated ,它指的是未被评为“足够干净”而被认为有用的数据。在此 notebook 中,我们将仅使用拆分的 "train" , "validation" 和 "test" .
from datasets import load_dataset, load_metric, Audio
common_voice_train = load_dataset("mozilla-foundation/common_voice_6_1", "tr", split="train+validation", use_auth_token=True)
common_voice_test = load_dataset("mozilla-foundation/common_voice_6_1", "tr", split="test", use_auth_token=True)
许多 ASR 数据集仅提供每个音频数组 ( 'audio' ) 和文件 ( 'path' ) 的目标文本 ( 'sentence' )。实际上,Common Voice 提供了关于每个音频文件的更多信息,例如 'accent' 等。为了使 notebook 尽可能通用,我们仅考虑用于微调的转录文本.
common_voice_train = common_voice_train.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"])
common_voice_test = common_voice_test.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"])
让我们编写一个简短的函数来显示数据集的一些随机样本,并运行它几次以了解转录的感觉.
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
display(HTML(df.to_html()))
show_random_elements(common_voice_train.remove_columns(["path", "audio"]), num_examples=10)
Oylar teker teker elle sayılacak.
Son olaylar endişe seviyesini yükseltti.
Tek bir kart hepsinin kapılarını açıyor.
Blogcular da tam bundan bahsetmek istiyor.
Bu Aralık iki bin onda oldu.
Fiyatın altmış altı milyon avro olduğu bildirildi.
Ardından da silahlı çatışmalar çıktı.
"Romanya'da kurumlar gelir vergisi oranı yüzde on altı."
Bu konuda neden bu kadar az şey söylendiğini açıklayabilir misiniz?
好吧!转录看起来相当干净。翻译完转录的句子后,这种语言似乎更多地对应于书面文本,而不是嘈杂的对话。考虑到 Common Voice 是一个众包阅读语音语料库,这也解释的通.
我们可以看到,转录文本中包含一些特殊字符,如 ,.?!;: 。没有语言模型,要将语音块分类为这些特殊字符就更难了,因为它们并不真正对应于一个特征性的声音单元。例如,字母 "s" 有一个或多或少清晰的声音,而特殊字符 "." 则没有。此外,为了理解语音信号的含义,通常不需要在转录中包含特殊字符.
让我们简单地删除所有对单词的含义没有贡献并且不能真正用声音表示的字符,并对文本进行规范化.
import re
chars_to_remove_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\']'
def remove_special_characters(batch):
batch["sentence"] = re.sub(chars_to_remove_regex, '', batch["sentence"]).lower()
return batch
common_voice_train = common_voice_train.map(remove_special_characters)
common_voice_test = common_voice_test.map(remove_special_characters)
我们再看看处理后的文本标签.
show_random_elements(common_voice_train.remove_columns(["path","audio"]))
i̇kinci tur müzakereler eylül ayında başlayacak
jani ve babası bu düşüncelerinde yalnız değil
onurun gözlerindeki büyü
bandiç oyların yüzde kırk sekiz virgül elli dördünü topladı
bu imkansız
bu konu açık değildir
cinayet kamuoyunu şiddetle sarstı
kentin sokakları iki metre su altında kaldı
muhalefet partileri hükümete karşı ciddi bir mücadele ortaya koyabiliyorlar mı
festivale tüm dünyadan elli film katılıyor
好!这看起来更好了。我们已经从转录中删除了大多数特殊字符,并将它们规范化为仅小写.
在完成预处理之前,咨询目标语言的母语人士总是有益的,以查看文本是否可以进一步简化。 对于这篇博客文章, Merve 很友好地快速查看了一下,并指出带帽子的字符 (如 â ) 在土耳其语中已经不再使用,可以用它们的无帽子等效物 (例如 a ) 替换.
这意味着我们应该将像 "yargı sistemi hâlâ sağlıksız" 这样的句子替换为 "yargı sistemi hala sağlıksız" .
让我们再写一个简短的映射函数来进一步简化文本标签。记住 - 文本标签越简单,模型学习预测这些标签就越容易.
def replace_hatted_characters(batch):
batch["sentence"] = re.sub('[â]', 'a', batch["sentence"])
batch["sentence"] = re.sub('[î]', 'i', batch["sentence"])
batch["sentence"] = re.sub('[ô]', 'o', batch["sentence"])
batch["sentence"] = re.sub('[û]', 'u', batch["sentence"])
return batch
common_voice_train = common_voice_train.map(replace_hatted_characters)
common_voice_test = common_voice_test.map(replace_hatted_characters)
在 CTC 中,将语音块分类为字母是很常见的,所以我们在这里也做同样的事情。让我们提取训练和测试数据中所有不同的字母,并从这组字母中构建我们的词汇表.
我们编写一个映射函数,将所有转录连接成一个长转录,然后将字符串转换为一组字符。将参数传递 batched=True 给 map(...) 函数非常重要,以便映射函数可以立即访问所有转录.
def extract_all_chars(batch):
all_text = " ".join(batch["sentence"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
vocab_train = common_voice_train.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=common_voice_train.column_names)
vocab_test = common_voice_test.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=common_voice_test.column_names)
现在,我们创建训练数据集和测试数据集中所有不同字母的并集,并将结果列表转换为枚举字典.
vocab_list = list(set(vocab_train["vocab"][0]) | set(vocab_test["vocab"][0]))
vocab_dict = {v: k for k, v in enumerate(sorted(vocab_list))}
vocab_dict
{' ': 0,
'a': 1,
'b': 2,
'c': 3,
'd': 4,
'e': 5,
'f': 6,
'g': 7,
'h': 8,
'i': 9,
'j': 10,
'k': 11,
'l': 12,
'm': 13,
'n': 14,
'o': 15,
'p': 16,
'q': 17,
'r': 18,
's': 19,
't': 20,
'u': 21,
'v': 22,
'w': 23,
'x': 24,
'y': 25,
'z': 26,
'ç': 27,
'ë': 28,
'ö': 29,
'ü': 30,
'ğ': 31,
'ı': 32,
'ş': 33,
'̇': 34}
很酷,我们看到字母表中的所有字母都出现在数据集中 (这并不令人惊讶),我们还提取了特殊字符 "" 和 ' 。请注意,我们没有排除这些特殊字符,因为模型必须学会预测单词何时结束,否则预测将始终是一系列字母,这将使得不可能将单词彼此分开.
人们应该始终记住,在训练模型之前,预处理是一个非常重要的步骤。例如,我们不希望我们的模型仅仅因为我们忘记规范化数据而区分 a 和 A 。 a 和 A 之间的区别根本不取决于字母的“声音”,而更多地取决于语法规则 - 例如,在句子开头使用大写字母。因此,删除大写字母和非大写字母之间的差异是明智的,这样模型在学习转录语音时就更容易了.
为了更清楚地表明 " " 具有自己的标记类别,我们给它一个更明显的字符 | 。此外,我们还添加了一个“未知”标记,以便模型以后能够处理 Common Voice 训练集中未遇到的字符.
vocab_dict["|"] = vocab_dict[" "]
del vocab_dict[" "]
最后,我们还添加了一个对应于 CTC 的“空白标记”的填充标记。 “空白标记”是 CTC 算法的核心组成部分。欲了解更多信息,请查看 此处 的“对齐”部分.
vocab_dict["[UNK]"] = len(vocab_dict)
vocab_dict["[PAD]"] = len(vocab_dict)
len(vocab_dict)
37
很酷,现在我们的词汇表已经完成,包含 37 个标记,这意味着我们将作为适配器权重的一部分添加在预训练的 MMS 检查点顶部的线性层将具有 37 的输出维度.
由于单个 MMS 检查点可以为多种语言提供定制权重,因此分词器也可以包含多个词汇表。因此,我们需要嵌套我们的 vocab_dict ,以便将来可能向词汇表中添加更多语言。字典应该嵌套使用适配器权重的名称,并在分词器配置中以 target_lang 的名称保存.
让我们像原始的 mms-1b-all 检查点一样使用 ISO-639-3 语言代码.
target_lang = "tur"
让我们定义一个空字典,我们可以在其中添加刚刚创建的词汇表 。
new_vocab_dict = {target_lang: vocab_dict}
注意 : 如果你想使用此 notebook 将新的适配器层添加到 现有模型仓库 ,请确保 不要 创建一个空的新词汇表,而是重用已经存在的词汇表。为此,你应该取消注释以下单元格,并将 "patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab" 替换为你要添加适配器权重的模型仓库 ID.
# from transformers import Wav2Vec2CTCTokenizer
# mms_adapter_repo = "patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab" # make sure to replace this path with a repo to which you want to add your new adapter weights
# tokenizer = Wav2Vec2CTCTokenizer.from_pretrained(mms_adapter_repo)
# new_vocab = tokenizer.vocab
# new_vocab[target_lang] = vocab_dict
现在让我们将词汇表保存为 json 文件.
import json
with open('vocab.json', 'w') as vocab_file:
json.dump(new_vocab_dict, vocab_file)
最后一步,我们使用 json 文件将词汇表加载到类的实例中 Wav2Vec2CTCTokenizer .
from transformers import Wav2Vec2CTCTokenizer
tokenizer = Wav2Vec2CTCTokenizer.from_pretrained("./", unk_token="[UNK]", pad_token="[PAD]", word_delimiter_token="|", target_lang=target_lang)
如果想要在本 notebook 的微调模型中重用刚刚创建的分词器,强烈建议将 tokenizer 上传到 🤗 Hub 。让我们将上传文件的仓库命名为 "wav2vec2-large-mms-1b-turkish-colab"
repo_name = "wav2vec2-large-mms-1b-turkish-colab"
并将分词器上传到 🤗 Hub .
tokenizer.push_to_hub(repo_name)
CommitInfo(commit_url='https://huggingface.co/patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab/commit/48cccbfd6059aa6ce655e9d94b8358ba39536cb7', commit_message='Upload tokenizer', commit_description='', oid='48cccbfd6059aa6ce655e9d94b8358ba39536cb7', pr_url=None, pr_revision=None, pr_num=None)
太好了,你可以在下面看到刚刚创建的存储库 https://huggingface.co/<your-username>/wav2vec2-large-mms-1b-tr-colab 。
Wav2Vec2FeatureExtractor 语音是一个连续的信号,要被计算机处理,首先必须离散化,这通常被称为 采样 。采样率在这里起着重要的作用,它定义了每秒测量语音信号的数据点数。因此,采用更高的采样率采样会更好地近似 真实 语音信号,但也需要每秒更多的值.
预训练检查点期望其输入数据与其训练数据的分布大致相同。两个不同采样率采样的相同语音信号具有非常不同的分布,例如,将采样率加倍会导致数据点数量加倍。因此,在微调 ASR 模型的预训练检查点之前,必须验证用于预训练模型的数据的采样率与用于微调模型的数据集的采样率是否匹配。 Wav2Vec2FeatureExtractor 对象需要以下参数才能实例化
feature_size : 语音模型以特征向量序列作为输入。虽然这个序列的长度显然会变化,但特征大小不应该变化。在 Wav2Vec2 的情况下,特征大小为 1,因为该模型是在原始语音信号上训练的 ( {}^2 )。 sampling_rate : 模型训练时使用的采样率。 padding_value : 对于批量推理,较短的输入需要用特定值填充 do_normalize : 输入是否应该进行 零均值单位方差 归一化。通常,语音模型在归一化输入时表现更好 return_attention_mask : 模型是否应该使用 attention_mask 进行批量推理。通常情况下,XLS-R 模型检查点应该 始终 使用 attention_mask
from transformers import Wav2Vec2FeatureExtractor
feature_extractor = Wav2Vec2FeatureExtractor(feature_size=1, sampling_rate=16000, padding_value=0.0, do_normalize=True, return_attention_mask=True)
太好了,MMS 的特征提取管道已经完全定义! 。
为了提高用户友好性,特征提取器和分词器被 封装 到一个 Wav2Vec2Processor 类中,这样只需要一个 model 和 processor 对象.
from transformers import Wav2Vec2Processor
processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
接下来,我们可以准备数据集.
到目前为止,我们还没有看过语音信号的实际值,只看过转录。除了 sentence ,我们的数据集还包括另外两个列名 path 和 audio 。 path 表示音频文件的绝对路径, audio 表示已经加载的音频数据。MMS 期望输入格式为 16kHz 的一维数组。这意味着音频文件必须加载并重新采样.
值得庆幸的是,当列名为 audio 时, datasets 会自动完成这一操作。让我们试试.
common_voice_train[0]["audio"]
{'path': '/root/.cache/huggingface/datasets/downloads/extracted/71ba9bd154da9d8c769b736301417178729d2b87b9e00cda59f6450f742ed778/cv-corpus-6.1-2020-12-11/tr/clips/common_voice_tr_17346025.mp3',
'array': array([ 0.00000000e+00, -2.98378618e-13, -1.59835903e-13, ...,
-2.01663317e-12, -1.87991593e-12, -1.17969588e-12]),
'sampling_rate': 48000}
在上面的示例中,我们可以看到音频数据以 48kHz 的采样率加载,而模型期望的是 16kHz,正如我们所见。我们可以通过使用 cast_column 将音频特征设置为正确的采样率
common_voice_train = common_voice_train.cast_column("audio", Audio(sampling_rate=16_000))
common_voice_test = common_voice_test.cast_column("audio", Audio(sampling_rate=16_000))
我们再来看一下 "audio" .
common_voice_train[0]["audio"]
{'path': '/root/.cache/huggingface/datasets/downloads/extracted/71ba9bd154da9d8c769b736301417178729d2b87b9e00cda59f6450f742ed778/cv-corpus-6.1-2020-12-11/tr/clips/common_voice_tr_17346025.mp3',
'array': array([ 9.09494702e-13, -6.13908924e-12, -1.09139364e-11, ...,
1.81898940e-12, 4.54747351e-13, 3.63797881e-12]),
'sampling_rate': 16000}
这似乎奏效了!让我们通过打印语音输入的形状、转录内容和相应的采样率来最后检查数据是否准备正确.
rand_int = random.randint(0, len(common_voice_train)-1)
print("Target text:", common_voice_train[rand_int]["sentence"])
print("Input array shape:", common_voice_train[rand_int]["audio"]["array"].shape)
print("Sampling rate:", common_voice_train[rand_int]["audio"]["sampling_rate"])
Target text: bağış anlaşması bir ağustosta imzalandı
Input array shape:(70656,)
Sampling rate: 16000
很好!一切看起来都很棒 - 数据是一维数组,采样率始终对应于 16kHz,并且目标文本已标准化.
最后,我们可以利用 Wav2Vec2Processor 将数据处理成 Wav2Vec2ForCTC 训练所需的格式。为此,让我们利用 Dataset 的 map(...) 函数.
首先,我们通过调用 batch["audio"] 来加载并重新采样音频数据。 其次,我们从加载的音频文件中提取 input_values 。在我们的情况下, Wav2Vec2Processor 只规范化数据。然而,对于其他语音模型,这一步可能包括更复杂的特征提取,例如 Log-Mel 特征提取 。 第三,我们将转录编码为标签 id.
注意 : 这个映射函数是一个很好的例子,说明了如何使用 Wav2Vec2Processor 类。在“正常”情况下,调用 processor(...) 会重定向到 Wav2Vec2FeatureExtractor 的调用方法。然而,当将处理器封装到 as_target_processor 上下文中时,同一个方法会重定向到 Wav2Vec2CTCTokenizer 的调用方法。 欲了解更多信息,请查看 文档 .
def prepare_dataset(batch):
audio = batch["audio"]
# batched output is "un-batched"
batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
batch["input_length"] = len(batch["input_values"])
batch["labels"] = processor(text=batch["sentence"]).input_ids
return batch
让我们将数据准备功能应用到所有示例中.
common_voice_train = common_voice_train.map(prepare_dataset, remove_columns=common_voice_train.column_names)
common_voice_test = common_voice_test.map(prepare_dataset, remove_columns=common_voice_test.column_names)
注意 : datasets 自动处理音频加载和重新采样。如果你希望实现自己的定制数据加载/采样,请随意使用该 "path" 列并忽略该 "audio" 列.
太棒了,现在我们准备开始训练了! 。
数据已经处理好,我们准备开始设置训练流程。我们将使用 🤗 的 Trainer ,为此我们基本上需要做以下几件事
compute_metrics 函数 在微调模型之后,我们将正确地在测试数据上评估它,并验证它是否确实学会了正确转录语音.
让我们从定义数据整理器开始。数据整理器的代码是从 这个示例 中复制的.
不详细讲述,与常见的数据整理器不同,这个数据整理器分别对待 input_values 和 labels ,因此对它们应用两个单独的填充函数 (再次利用 MMS 处理器的上下文管理器)。这是必要的,因为在语音识别中,输入和输出属于不同的模态,因此它们不应该被相同的填充函数处理。 与常见的数据整理器类似,标签中的填充标记用 -100 填充,以便在计算损失时 不 考虑这些标记.
import torch
from dataclasses import dataclass, field
from typing import Any, Dict, List, Optional, Union
@dataclass
class DataCollatorCTCWithPadding:
"""
Data collator that will dynamically pad the inputs received.
Args:
processor (:class:`~transformers.Wav2Vec2Processor`)
The processor used for proccessing the data.
padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
*:obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
*:obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
maximum acceptable input length for the model if that argument is not provided.
*:obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
different lengths).
"""
processor: Wav2Vec2Processor
padding: Union[bool, str] = True
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lenghts and need
# different padding methods
input_features = [{"input_values": feature["input_values"]} for feature in features]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.pad(
input_features,
padding=self.padding,
return_tensors="pt",
)
labels_batch = self.processor.pad(
labels=label_features,
padding=self.padding,
return_tensors="pt",
)
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
batch["labels"] = labels
return batch
data_collator = DataCollatorCTCWithPadding(processor=processor, padding=True)
接下来,定义评估指标。如前所述,ASR 中的主要指标是单词错误率 (WER),因此我们也将在本 notebook 中使用它.
from evaluate import load
wer_metric = load("wer")
模型将返回一系列 logit 向量: ( \mathbf{y}_1, \ldots, \mathbf{y}_m ) 其中 ( \mathbf{y} 1 = f {\theta}(x_1, \ldots, x_n)[0] ) 且 ( n >> m ).
logit 向量 ( \mathbf{y}_1 ) 包含我们前面定义的词汇表中每个单词的对数几率,因此 ( \text{len}(\mathbf{y}_i) = ) config.vocab_size 。我们对模型最可能的预测感兴趣,因此取 logits 的 argmax(...) 。此外,我们通过将 -100 替换为 pad_token_id 并解码 id,同时确保连续标记 不 以 CTC 风格分组到同一标记 ( {}^1 ),将编码后的标签转换回原始字符串.
def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)
pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
pred_str = processor.batch_decode(pred_ids)
# we do not want to group tokens when computing the metrics
label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
wer = wer_metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
现在,我们可以加载预训练的 mms-1b-all 检查点。分词器的 pad_token_id 必须定义模型的 pad_token_id ,或者在 Wav2Vec2ForCTC 的情况下也是 CTC 的 空白标记 ( {}^2 ).
由于我们只训练一小部分权重,模型不容易过拟合。因此,我们确保禁用所有 dropout 层.
注意 : 当使用本笔记本在 Common Voice 的另一种语言上训练 MMS 时,这些超参数设置可能不会很好地工作。根据你的用例,随意调整这些设置.
from transformers import Wav2Vec2ForCTC
model = Wav2Vec2ForCTC.from_pretrained(
"facebook/mms-1b-all",
attention_dropout=0.0,
hidden_dropout=0.0,
feat_proj_dropout=0.0,
layerdrop=0.0,
ctc_loss_reduction="mean",
pad_token_id=processor.tokenizer.pad_token_id,
vocab_size=len(processor.tokenizer),
ignore_mismatched_sizes=True,
)
Some weights of Wav2Vec2ForCTC were not initialized from the model checkpoint at facebook/mms-1b-all and are newly initialized because the shapes did not match:
- lm_head.bias: found shape torch.Size([154]) in the checkpoint and torch.Size([39]) in the model instantiated
- lm_head.weight: found shape torch.Size([154, 1280]) in the checkpoint and torch.Size([39, 1280]) in the model instantiated
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
注意 : 预计一些权重将被重新初始化。这些权重对应于新初始化的词汇输出层.
我们现在希望确保只有适配器权重将被训练,而模型的其余部分保持冻结.
首先,我们重新初始化所有适配器权重,这可以通过方便的 init_adapter_layers 方法完成。也可以不重新初始化适配器权重并继续微调,但在这种情况下,在训练之前应该通过 load_adapter(...) 方法 加载合适的适配器权重。然而,词汇表通常仍然不会很好地匹配自定义训练数据,因此通常更容易重新初始化所有适配器层,以便它们可以轻松地进行微调.
model.init_adapter_layers()
接下来,我们冻结 除 适配器层之外的所有权重.
model.freeze_base_model()
adapter_weights = model._get_adapters()
for param in adapter_weights.values():
param.requires_grad = True
最后一步,我们定义与训练相关的所有参数。 对一些参数进行更多解释
group_by_length 通过将输入长度相似的训练样本分组到一个批次中,使训练更加高效。这可以通过大大减少通过模型传递的无用填充标记的总数,从而显著加快训练时间 learning_rate 被选择为 1e-3,这是使用 Adam 训练的常用默认值。其他学习率可能同样有效。 有关其他参数的更多解释,可以查看 文档 。为了节省 GPU 内存,我们启用 PyTorch 的 梯度检查点 ,并将损失减少设置为“ mean ”。MMS 适配器微调非常快地收敛到非常好的性能,因此即使对于像 4 小时这样小的数据集,我们也只会训练 4 个周期。在训练过程中,每 200 个训练步骤将异步上传一个检查点到 hub。它允许你在模型仍在训练时也可以使用演示小部件玩耍.
注意 : 如果不想将模型检查点上传到 hub,只需将 push_to_hub=False 即可.
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir=repo_name,
group_by_length=True,
per_device_train_batch_size=32,
evaluation_strategy="steps",
num_train_epochs=4,
gradient_checkpointing=True,
fp16=True,
save_steps=200,
eval_steps=100,
logging_steps=100,
learning_rate=1e-3,
warmup_steps=100,
save_total_limit=2,
push_to_hub=True,
)
现在,所有实例都可以传递给 Trainer,我们准备开始训练! 。
from transformers import Trainer
trainer = Trainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=common_voice_train,
eval_dataset=common_voice_test,
tokenizer=processor.feature_extractor,
)
( {}^1 ) 为了使模型独立于说话人速率,在 CTC 中,相同的连续标记简单地分组为单个标记。然而,在解码时不应该对编码的标签进行分组,因为它们不对应于模型的预测标记,这就是为什么必须传递 group_tokens=False 参数。如果我们不传递这个参数,像 "hello" 这样的单词会被错误地编码,并解码为 "helo" .
( {}^2 ) 空白标记允许模型通过强制在两个 l 之间插入空白标记来预测一个词,例如 "hello" 。我们模型的 CTC 符合预测 "hello" 将是 [PAD] [PAD]"h" "e" "e" "l" "l" [PAD]"l" "o" "o" [PAD] .
训练时间应该少于 30 分钟,具体取决于所使用的 GPU.
trainer.train()
| 训练损失 | 训练步数 | 验证损失 | Wer |
|---|---|---|---|
| 4.905 | 100 | 0.215 | 0.280 |
| 0.290 | 200 | 0.167 | 0.232 |
| 0.2659 | 300 | 0.161 | 0.229 |
| 0.2398 | 400 | 0.156 | 0.223 |
训练损失和验证 WER 都很好地下降.
我们看到,仅微调 mms-1b-all 的适配器层 100 步就大大超过了 这里 显示的微调整个 xls-r-300m 检查点.
从 官方论文 和这个快速比较中可以清楚地看出, mms-1b-all 具有更高的将知识转移到低资源语言的能力,应该优先于 xls-r-300m 。此外,训练也更节省内存,因为只训练了一小部分层.
适配器权重将作为模型检查点的一部分上传,但我们也希望确保单独保存它们,以便它们可以轻松地上下线.
让我们将所有适配器层保存到训练输出目录中,以便它能够正确上传到 Hub.
from safetensors.torch import save_file as safe_save_file
from transformers.models.wav2vec2.modeling_wav2vec2 import WAV2VEC2_ADAPTER_SAFE_FILE
import os
adapter_file = WAV2VEC2_ADAPTER_SAFE_FILE.format(target_lang)
adapter_file = os.path.join(training_args.output_dir, adapter_file)
safe_save_file(model._get_adapters(), adapter_file, metadata={"format": "pt"})
最后,你可以将训练结果上传到🤗 Hub.
trainer.push_to_hub()
适配器权重训练的主要优点之一是“基础”模型 (约占模型权重的 99%) 保持不变,只需共享一个小的 2.5M 适配器检查点 即可使用训练好的检查点.
这使得训练额外的适配器层并将它们添加到你的仓库变得非常简单.
你可以通过简单地重新运行此脚本并将你想要训练的语言更改为另一种语言来轻松实现,例如 swe 表示瑞典语。此外,你应该确保词汇表不会被完全覆盖,而是新语言词汇表应该像上面注释掉的单元格中所述那样 附加 到现有词汇表中.
为了演示如何加载不同的适配器层,我还训练并上传了一个瑞典语适配器层,其 iso 语言代码为 swe ,如 此处 所示 。
你可以像往常一样使用 from_pretrained(...) 加载微调后的检查点,但应确保在方法中添加 target_lang="<your-lang-code>" ,以便加载正确的适配器。你还应该为分词器正确设置目标语言.
让我们看看如何首先加载土耳其检查点.
model_id = "patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab"
model = Wav2Vec2ForCTC.from_pretrained(model_id, target_lang="tur").to("cuda")
processor = Wav2Vec2Processor.from_pretrained(model_id)
processor.tokenizer.set_target_lang("tur")
让我们检查模型是否可以正确转录土耳其语 。
from datasets import Audio
common_voice_test_tr = load_dataset("mozilla-foundation/common_voice_6_1", "tr", data_dir="./cv-corpus-6.1-2020-12-11", split="test", use_auth_token=True)
common_voice_test_tr = common_voice_test_tr.cast_column("audio", Audio(sampling_rate=16_000))
让我们处理音频,运行前向传递并预测 ids 。
input_dict = processor(common_voice_test_tr[0]["audio"]["array"], sampling_rate=16_000, return_tensors="pt", padding=True)
logits = model(input_dict.input_values.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)[0]
最后,我们可以解码该示例.
print("Prediction:")
print(processor.decode(pred_ids))
print("\nReference:")
print(common_voice_test_tr[0]["sentence"].lower())
输出
Prediction:
pekçoğuda roman toplumundan geliyor
Reference:
pek çoğu da roman toplumundan geliyor.
这看起来几乎完全正确,只是第一个单词中应该添加两个空格。 现在,通过调用 model.load_adapter(...) 并将分词器更改为瑞典语,可以非常简单地将适配器更改为瑞典语.
model.load_adapter("swe")
processor.tokenizer.set_target_lang("swe")
我们再次从普通语音加载瑞典语测试集 。
common_voice_test_swe = load_dataset("mozilla-foundation/common_voice_6_1", "sv-SE", data_dir="./cv-corpus-6.1-2020-12-11", split="test", use_auth_token=True)
common_voice_test_swe = common_voice_test_swe.cast_column("audio", Audio(sampling_rate=16_000))
并转录一个样本
input_dict = processor(common_voice_test_swe[0]["audio"]["array"], sampling_rate=16_000, return_tensors="pt", padding=True)
logits = model(input_dict.input_values.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)[0]
print("Prediction:")
print(processor.decode(pred_ids))
print("\nReference:")
print(common_voice_test_swe[0]["sentence"].lower())
输出
Prediction:
jag lämnade grovjobbet åt honom
Reference:
jag lämnade grovjobbet åt honom.
太好了,这看起来像是一个完美的转录! 。
我们在这篇博客文章中展示了 MMS 适配器权重微调不仅在低资源语言上提供了最先进的性能,而且还显著缩短了训练时间,并允许轻松构建定制的适配器权重集合.
相关帖子和附加链接列在这里
英文链接: https://hf.co/blog/mms_adapters 。
作者: Patrick von Platen 。
译者: innovation64 。
审校/排版: zhongdongy (阿东) 。
最后此篇关于微调用于多语言ASR的MMS适配器模型的文章就讲到这里了,如果你想了解更多关于微调用于多语言ASR的MMS适配器模型的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
我有一个应用程序,它实际上没有对 mongo 副本集进行大量写入,但该副本集成员之间的网络流量恒定为 500Kb/s,即使在应用程序上绝对没有流量的夜晚也是如此。这确定不是心跳?什么可能会占用这么多带
我为 CentOS 安装了 MMS 代理,当我将它作为服务启动时,我在日志文件中看到以下错误,我已经搜索了此错误,但找不到任何引用,有人可以告诉我问题是什么。 /usr/bin/mongodb-mms
我正在考虑设置 MMS 自动化代理,但发现 Windows 没有下载。它不适用于windows吗? 谢谢! 最佳答案 正确,彩信自动化代理在 Windows 上尚不可用。 Windows 版本在 fu
在彩信进入收件箱之前,是否有任何方法可以通过使用彩信/短信监听器来区分彩信和短信? 最佳答案 MMS 消息的第一个指示符是具有 MIME 类型“application/vnd.wap.mms-mess
本文实例讲述了Android非调用系统界面实现发送彩信的方法。分享给大家供大家参考,具体如下: 1、问题: 最近有个需求,不去调用系统界面发送彩信功能。做过发送短信功能的同学可能第一反应是这样
是否可以在 MMS 中放置内部超文本链接(或 anchor )。我不想让 MMS 服务的用户在多个链接之间进行选择,然后进入 MMS。知道这怎么可能吗? 最佳答案 您是如何编写彩信的?您在使用某种 A
我有这段代码可以发送一个带有来自原始文件夹的音频附件的电子邮件: Intent i = new Intent(Intent.ACTION_SEND); i.setFlags(Intent.FLAG_A
我正在尝试修改 android 手机中的默认短信。 我已经从以下链接下载了源代码 https://github.com/android/platform_packages_apps_mms 链接包含(
我想建立一个工单接受系统 a) 将工单的 pdf 格式转换为图像(可能使用 iText) b) 将这些内容作为附件发送到彩信,请求收件人批准 c) 接收者回答"is"或“否”以表示批准工作订单 我确信
我正在访问 Android MMS 数据库以获取 MMS 消息的日期: Uri mmsUri = Uri.parse("content://mms/"); ContentResolver conten
我确实得到了关于如何检索从这个链接发送的彩信的文本和图像的信息:How to Read MMS Data in Android? . 但我不确定如何检索发送的彩信的日期。 我知道我必须查看 conte
是否有办法更新 MMS/SMS 数据库以将消息从已读标记为未读,反之亦然?我试过使用 URI,但它们对我不起作用。 最佳答案 下面的代码可以让我更新彩信是否被标记为已查看。 要将其用于 SMS 消息,
我正在尝试创建一个 Intent ,它将为我启动 MMS 应用程序,并附加一个图像文件和消息正文中存在的一些预定义文本。 到目前为止,我已经能够完成其中之一,但不能同时完成。 我尝试过的事情(及其结果
我正在编写一个通过 MMS 发送 PNG 的 Android 应用程序。我遇到的一个问题是较大的图像被压缩成 JPG。因为图像格式必须是无损的,所以我需要知道用户的 MMS 字节限制(显然没有跨运营商
How to open Email program via Intents (but only an Email program) 的答案展示了如何通过调用 intent.setType("messa
所以我试图调用一个 Intent ,将图片附加到短信中。以下代码在模拟器上正确显示带有图像的文本消息窗口,但在我的手机 (Droid X) 上崩溃了。 String name
这是我在这里的第一篇文章,所以如果我违反了一些规则,我真的很抱歉。哪里不对请指正。 现在回答这个问题,我在 stackoverflow 和其他网站/互联网上来回搜索,但似乎找不到正确的答案。 我正在尝
当查询 Android 的 MMS-SMS Content Provider 时,日期列对于 MMS 和 SMS 具有不同的纪元时间值。 ContentResolver contentResolver
我正在尝试在我的 Android 应用程序中播放来自 mms 和 m3u8 的一些视频流。似乎 MediaPlayer 对此没有支持,从我在 FFMPEG 上阅读的内容来看,似乎也没有任何简单的方法。
我们使用 SMS 向我们的客户群发送文本消息,但最近有人请求也发送 HTML 内容。 我知道 SMS 仅支持文本消息,而且我知道通过 SMS 发送任何类型的 html 内容的唯一方法是在消息中提供返回

我是一名优秀的程序员,十分优秀!