
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


先来看看官网关于Paimon查询模式的说明 。
可以看到查询模式围绕snapshot展开, 而snapshot分了两种一种是Last compact snapshot和 last snapshot. 直接读last snapshot的话应该是需要merge on read. 而last compact snapshot 应该有点类似于hudi里面的 Read Optimized Queries 。
上表中流读都提到需要读取变更流的数据.因此,Paimon表要有产生变更流的数据的能力. 内置了几种不同的changelog producer. 。
Changelog producer的含义是这张Paimon表的change log producer. 也就是用户写入数据后,如果对于这张表产生正确的change log. 这样下游才可以基于这个变更流进行增量的处理. 。
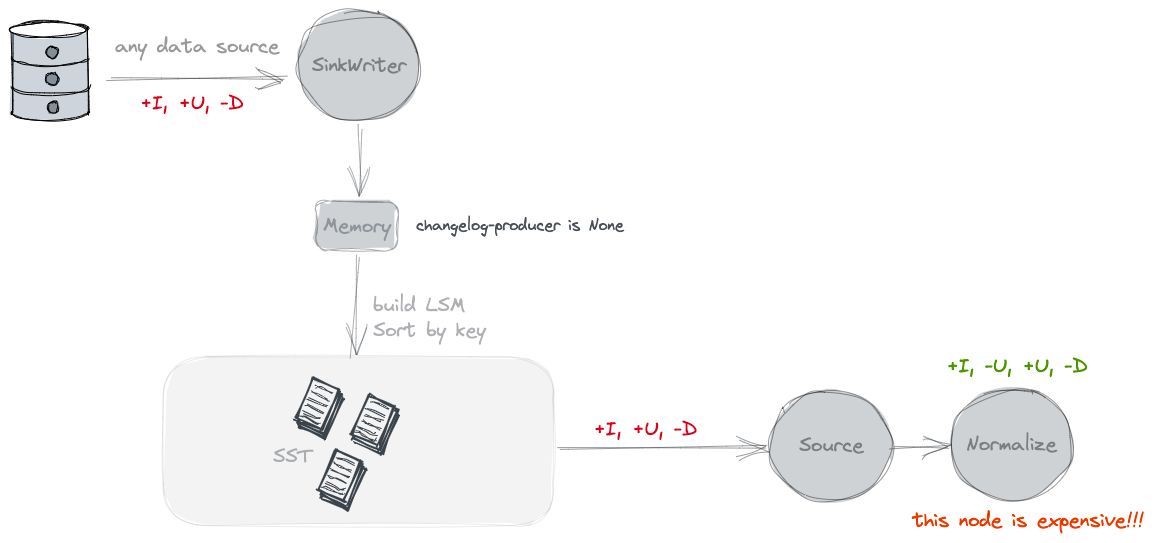
不单独产生Changelog文件. 按照官网的说法是只能看到snapshot之间的变化. 但是没有old value. 。
Paimon source can only see the merged changes across snapshots, like what keys are removed and what are the new values of some keys. 。
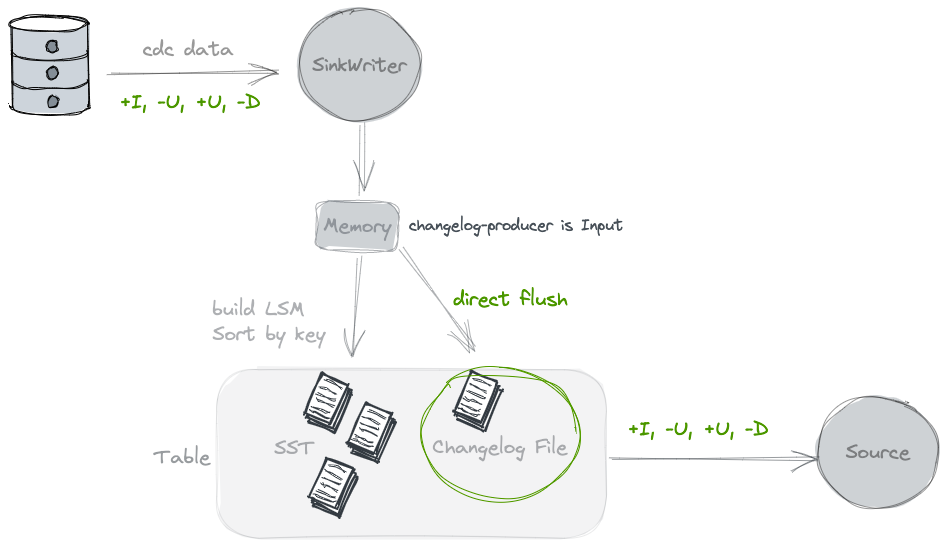
在刷写数据的时候,会同时写一份Changelog的文件,提供给下游消费. 相当于为了流式能消费到变更流的视图, 需要将上游的变更流数据另外保存一份. 使用这种类型的clp的前提是, 基于输入数据已经能完全反应这张表的Changelog, 例如由CDC同步进来的数据,是可以的. 但是对于partial update 是不行的 。
// 如果配置了ChangelogProducer.INPUT 那么再刷写WriteBuffer的时候会同时将原始数据写入到changelog里面
final RollingFileWriter<KeyValue, DataFileMeta> changelogWriter =
changelogProducer == ChangelogProducer.INPUT
? writerFactory.createRollingChangelogFileWriter(0)
: null;
final RollingFileWriter<KeyValue, DataFileMeta> dataWriter =
writerFactory.createRollingMergeTreeFileWriter(0);
try {
// forEach会对原始数据的基于key的有序遍历
writeBuffer.forEach(
keyComparator,
mergeFunction,
changelogWriter == null ? null : changelogWriter::write,
dataWriter::write); // 最终使用的Orc/Parquet Writer来将数据写出
} finally {
if (changelogWriter != null) {
changelogWriter.close();
}
dataWriter.close();
}
当input无法形成一个完整的changelog, 比如partial update的场景中, 每个单独的input是没法产生changelog流的, changelog的过程实际和Compaction的merge过程相关 。
// 针对lookup的changelog producer 需要
// 1. 使用LookupCompaction CompactionStrategy
// 2. 使用LookupMergeTreeCompactRewriter
// 3. 使用LookupMergeFunction
LOOKUP(
"lookup",
"Generate changelog files through 'lookup' before committing the data writing.");
KeyValue result = mergeFunction.getResult();
checkArgument(result != null);
KeyValue highLevel = mergeFunction.highLevel;
boolean containLevel0 = mergeFunction.containLevel0;
// 1. No level 0, just return
// 没有level 0的数据, 意味着没有新数据产生
// 那么没有changelog文件产生, 只是高层文件的合并
if (!containLevel0) {
return reusedResult.setResult(result);
}
// 2. With level 0, with the latest high level, return changelog
// 先前的value也在此次的Compaction列表里面,直接就可以得出change log了
if (highLevel != null) {
setChangelog(highLevel, result);
return reusedResult.setResult(result);
}
// 3. Lookup to find the latest high level record
// 向更高level中查找这个key先前的数据, 为了产生变更流代价还是挺高的
// org.apache.paimon.mergetree.LookupLevels#lookup
highLevel = lookup.apply(result.key());
if (highLevel != null) {
mergeFunction2.reset();
mergeFunction2.add(highLevel);
mergeFunction2.add(result);
result = mergeFunction2.getResult();
setChangelog(highLevel, result);
} else {
setChangelog(null, result);
}
return reusedResult.setResult(result);
大致过程就是在Compaction的过程中会向高层的文件中查找该key的数据, 并根据查找结果来构建change log stream. 因为高层文件的key是有序的, 所以会通过二分法来过滤文件meta,快速定位到属于哪个文件. 但是因为这个文件是Parquet/Orc的列存文件, 无法直接根据key去高效查询的. 所以会先将原始数据读出,并重新成一个新的格式的文件,用于lookup探查, 主要是构建key的索引, 用于. HashLookupStoreWriter HashLookupStoreReader 主体逻辑可以参看 。
从上面的过程分析可以看出lookup的clp开销还是很大的,需要重读某个key的数据, 然后重新构建file cache, 再写出. 这里还提供了 full-compaction 的方式.同lookup一样,这个也是在compaction阶段来产生的, 不过是full Compaction阶段. 。
Full compaction changelog producer can produce complete changelog for any type of source. However it is not as efficient as the input changelog producer and the latency to produce changelog might be high. 。
他可以支持任意类型的input,但是时延会比较高. 10min 往上 实现类 FullChangelogMergeTreeCompactRewriter 和 FullChangelogMergeFunctionWrapper full compaction的时候不会产生delete的change log消息(大概是因为并不知道谁被delete了?) 在Full compaction阶段最后数据都会写到top level. 然后将最后合并后的数据和topLevel比较, 然后得出一个变更消息写到change log文件中. 。
对于离线场景的一般delete消息的需求 。
昨天新增今天删,昨天日增量分区有,今天增量分区没有 (也就是change log中并没有delete消息).昨天的日全量有,今天的日全量没有 今天新增今天删,今天的日增量分区没有,今天的日全量也没有 。
| 批模式 | 流模式 | |
|---|---|---|
| latest-full | 读取最新的snapshot. 获取的是最近一次的snapshot | 先读取最新的snapshot, 然后持续读取变更流 |
| compacted-full | 读取最近一次Compaction之后的snapshot. | |
| 获取的snapshot是最近一次compaction的. 理论上这样读取阶段就不需要Merge On Read了 | 先读取最近一次Compaction之后的snapshot, 然后持续读取变更流 | |
| latest | 和latest-full一样 | 只读取最新变化的数据, 没有读取snapshot |
| from-timestamp | 读取一个早于或等于 scan.timestamp-millis 指定时间戳的snapshot |
读取某个时间之后的数据, 不读取snapshot |
| from-snapshot | 读取 scan.snapshot-id 指定的某个snapshot id |
读取某个snapshot之后的数据, 不读取snapshot |
| from-snapshot-full | 读取 scan.snapshot-id 指定的某个snapshot id |
先读取某个snapshot, 然后持续读取其后的变化数据 |
StaticFileStoreSource org.apache.paimon.table.source.AbstractInnerTableScan#createStartingScanner InnerTable#newScan#plan (返回的Splits列表) org.apache.paimon.table.AbstractFileStoreTable#newScan org.apache.paimon.KeyValueFileStore#newScan() org.apache.paimon.table.source.snapshot.SnapshotSplitReaderImpl#splits org.apache.paimon.operation.AbstractFileStoreScan#plan 通过snapshot, 读取到相应的ManifestEntry 过滤出所有要读的文件 org.apache.paimon.table.source.snapshot.SnapshotSplitReaderImpl#generateSplits 对文件列表创建splits org.apache.paimon.table.source.MergeTreeSplitGenerator#split 每个bucket内部进行splits切分, 提高读取的并行度 org.apache.paimon.flink.source.FileStoreSourceSplitReader org.apache.paimon.table.source.KeyValueTableRead#createReader org.apache.paimon.operation.KeyValueFileStoreRead#createReaderWithoutOuterProjection Merge On Read 。
大体上和上面一样. 除了切分split的时候和创建reader的时候 org.apache.paimon.table.source.AppendOnlySplitGenerator#split org.apache.paimon.operation.AppendOnlyFileStoreRead#createReader 。
org.apache.paimon.table.AbstractFileStoreTable#newStreamScan org.apache.paimon.table.source.AbstractInnerTableScan#createStartingScanner 创建一个初始的scan 这个和批模式很类似. 但是大部分流读都不会去读取Snapshot, 这个部分只是生成一个next Snapshot的id org.apache.paimon.table.source.InnerStreamTableScanImpl#createFollowUpScanner 创建一个变更流的scan 变更流就和上面的Changelog producer息息相关, 每一种clp都有一个对应的变更流的planner. 用于根据Snapshot返回splits 。
并且也可以看到变更流的消费是跟着Snapshot走的, 在Stream 的 Source中会定期去获取splits, 就会触发定期Plan的获取, Plan的获取依赖于Snapshot. 所以读取的时延实际上Snapshot息息相关, 而Snapshot的产生又和上游的Checkpoint频率息息相关. 。
对于Append表 changelog 应该是delta 的数据, 是不是Append表应该只有DeltaFollowUpScanner 呢?
Paimon还支持维表关联. 维表关联只支持all的模式. 会将数据全部load到本地(会有一些过滤下推), 并存储到Rocksdb中. 不会在关联的过程中直接去查询文件, 从上面的lookup changelog producer实现中也可以看出 kv的查询开销还是很大的. 。
changelog-producer: https://paimon.apache.org/docs/master/concepts/primary-key-table/#changelog-producers 。
最后此篇关于Paimon读取流程的文章就讲到这里了,如果你想了解更多关于Paimon读取流程的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
已关闭。此问题不符合Stack Overflow guidelines 。目前不接受答案。 要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于 Stack Overflow 来说是偏离主题的,因为
首先是一些背景;我们正在开发一个数据仓库,并对我们的 ETL 过程使用哪些工具进行一些研究。该团队非常以开发人员为中心,每个人都熟悉 C#。到目前为止,我已经看过 RhinoETL、Pentaho (
我需要具有管理员权限的进程。从this问题和答案来看,似乎没有比启动单独进程更好的方法了。因为我宁愿有一个专用于该过程的过程,而不是仅为此方法在第二个过程中启动我的原始应用程序–我以为我会在VS201
我有这个函数来压平对象 export function flattenObject(object: Object, prefix: string = "") { return Object.key
我正在开发一个基于java的Web应用程序,它要求我使用来自SIP( session 启动协议(protocol))消息的输入生成序列图。我必须表示不同电话和相应服务器之间的调用流程。我可以利用任何工
这是我的代码: Process p=Runtime.getRuntime().exec("something command"); String s; JFrame frame = new JFram
我对 istio 的 mTLS 流程有点困惑。在bookinginfo 示例中,我看到服务通过http 而不是https 进行调用。如果服务之间有 mTLS 那么服务会进行 http 调用吗? 是否可
很难说出这里问的是什么。这个问题是含糊的、模糊的、不完整的、过于宽泛的或修辞性的,无法以目前的形式得到合理的回答。如需帮助澄清此问题以便重新打开它,visit the help center 。 已关
之前做过一个简单的纸牌游戏,对程序的整体流程有自己的想法。我最关心的是卡片触发器。 假设我们有一张名为“Guy”的牌,其效果为“每当你打出另一张牌时,获得 2 点生命”。我将如何将其合并到我的代码中?
我有 4 个 Activity 。 A、B、C 和 D。 用户可以从每个 Activity 开始任何 Activity 。 即 Activity A 有 3 个按钮来启动 B、C 和 D。以同样的方式
我做了一个简单的路由器类,简化后看起来像这样 // @flow import { Container } from 'unstated' type State = { history: Objec
我有两个 Activity ,比如 A1 和 A2。顺序为 A1->A2我从 A1 开始 A2 而没有在 A1 中调用 finish() 。在 A2 中按下后退按钮后,我想在 A1 中触发一个功能。但
我正在考虑在我的下一个项目中使用 BPEL。我试用了 Netbeans BPEL 设计器,我对它很满意。但在我决定使用 BPEL 之前,我想知道它对测试驱动开发的适用程度。不幸的是,我对那个话题知之甚
我需要将两个表格堆叠在一起,前后都有内容。我无法让后面的内容正常流动。堆叠的 table 高度可变。 HTML 结构: ... other content ...
我是 Hibernate 的新手。我无法理解 Hibernate 的流程。请澄清我的疑问。 我有“HibernateUtil.java ”和以下语句 sessionFactory = new Anno
早上好 我开始使用 Ruby,想创建一个小工具来获取我的公共(public) IP 并通过电子邮件发送。我遇到了字符串比较和无法处理的 if/else block 的基本问题。 代码非常简单(见下文)
我目前正尝试在我的团队中建立一个开发流程并阅读有关 GitFlow 的信息。它看起来很有趣,但我可以发现一些问题。 让我们假设以下场景: 我们完成了 F1、F2 和 F3 功能,并将它们 merge
我已经使用 git flow 有一段时间了。我很想了解一个特定的用例。 对于我的一个项目,我有一张新网站功能的门票。此工单取决于许多子任务。我想为主工单创建一个功能分支,然后为每个子任务创建一个脱离父
简介 "终结"一般被分为确定性终结(显示清除)与非确定性终结(隐式清除) 确定性终结主要 提供给开发人员一个显式清理的方法,比如try-finally,using。
你怎么知道在一个程序中已经发现并解决了尽可能多的错误? 几年前我读过一篇关于调试的文档(我认为这是某种 HOWTO)。其中,该文档描述了一种技术,其中编程团队故意将错误添加到代码中并将其传递给 QA

我是一名优秀的程序员,十分优秀!