
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 28
28
 4
4


实时光追(Real-time Ray Tracing)往往是综合了 sampling、ray casting、denoising 等各方面的方案,本文主要记录的是 ray casting 这部分,但是术语可能更多仍然称为 ray tracing.
ray tracing 最经典的实现莫过于 ray traversal:投射一条 ray 然后遍历所有 triangles 去做 ray-triangle 相交测试,并得到对应的 hit point。但是场景中的 triangles 数量往往数量庞大,ray traversal 也变得非常耗时,而后为了加速相交测试,便引入了加速结构(BVH,八叉树,k-d树等),来剪枝掉一些不可能发生相交的 triangles;但即便如此,软件实现 ray traversal 仍然是件耗时的事.
再后来,Nvidia 推出了 RTX 系列显卡,开始提供硬件单元来大大加速 ray traversal 这一过程,使得 real-time ray tracing 成为了可能。从此之后,GPU 厂商都逐渐开始普及硬件光追的支持.
硬件光追提供了两大层级的 AS,我们可以对这两大层级(BLAS 和 TLAS)进行配置,但不用关心 AS 具体采用哪种空间加速结构或者具体实现.
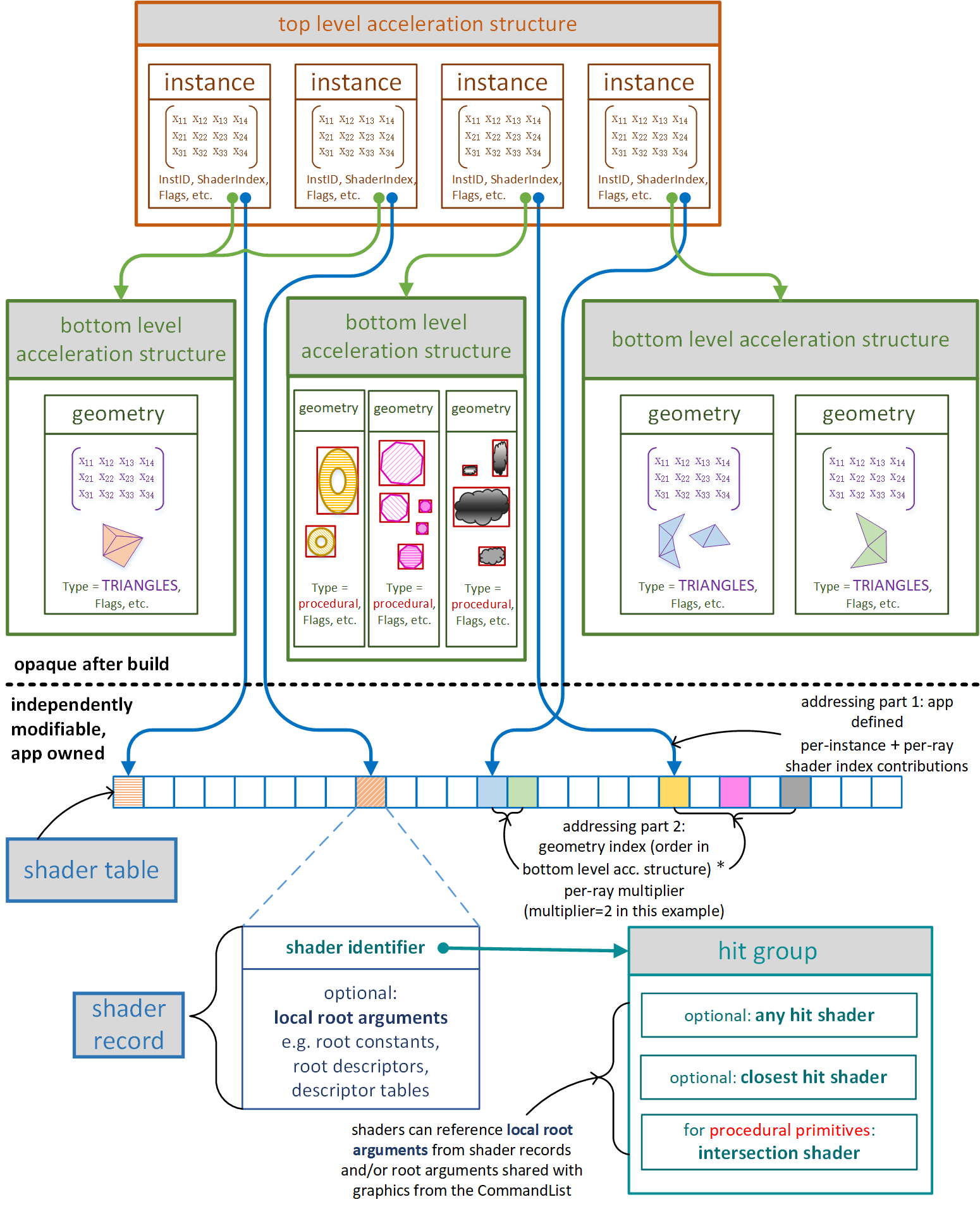
注:我们在 GPU 里通过 ray traversal 得到 hit point 后,要获取 hit point 的材质属性是非常困难的,因为材质函数和参数等都是在 CPU 端的,而粗暴的直接根据 geometry id 和 material id 去 CPU 拉取对应的 shader 和参数无疑是不可行的(通信时间过长).
为了解决这个问题,才有了 shader table 的机制:GPU 里的 shader table 预先存储着一堆 shader records,每个 record 包含一个或多个 shaders(其实就是 hit group)以及参数;再得到 hit point 后,根据 geometry id 和 material id 去索引到相对应的 shader record,并直接执行对应的 shader,无需通知 CPU.
| PREFER_ FAST_ TRACE | PREFER_ FAST_ BUILD | ALLOW_ UPDATE | Properties | Example | |
|---|---|---|---|---|---|
| 1 | no | yes | no | 尽可能快速的 build AS,trace 性能会低于 #3 和 #4。 | 完全动态的几何物体,如粒子、破坏物、移动剧烈的物体(爆炸)等,这种往往都需要每帧重建 AS。 |
| 2 | no | yes | yes | build AS 比 #1 稍微慢一些,但允许非常快速的 update。 | LOD level 低且不那么容易被 ray 命中的动态物体。 |
| 3 | yes | no | no | trace 性能最好,但 build AS 会比 #1 和 #2 都慢。 | 静态物体。 |
| 4 | yes | no | yes | trace 性能很好,只比 #3 慢一点点。AS 的 update 也只比 #2 慢一些。 | 重要的角色模型(如玩家主角);LOD level 高且比较容易被相当数量的 rays 命中的动态物体。 |
ray tracing pipeline 是与 graphics pipeline,compute pipeline 并列的一种新流水线,主要提供有 ray generation shader,intersection shader,和三种 hit shader 可编程.
在该 shader 里可以调用 TraceRay() 接口来使用 ray tracing pipeline 硬件光追:对 AS 进行 ray-traversal,并根据 intersection 的情况来自动调用对应的 hit shader 来完成 hit point 的着色.
TraceRay() 一般不可以在别的 shader 中调用,只能在 ray tracing pipeline 的相关 shader(RGS,MS,CHS之类的)中被调用,但一般推荐只在 RGS 中调用,不推荐递归调用(如 RGS 调用 TraceRay() 触发 CHS,CHS 再调用 TraceRay()),因为递归调用往往不如改造成多轮 pass 迭代.
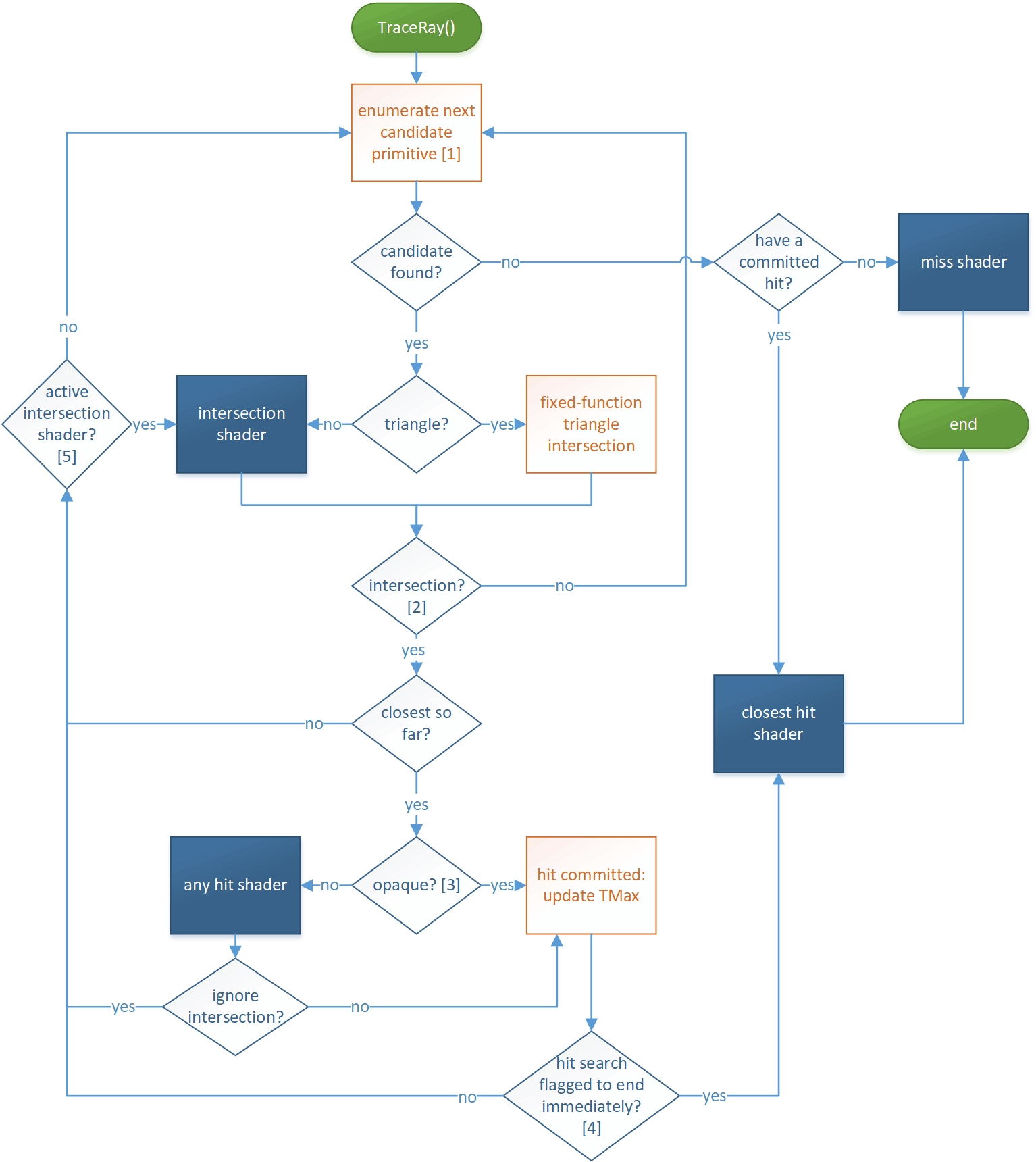
如果我们需要的不是默认的 ray-triangle intersection,而是 ray 与自定义的图元(例如可以是 sphere)做 intersection,那么就需要编写 intersection shader。不过注意的是,使用 ray-triangle intersection 是最高效的,因为它将使用硬件内置的 intersection 函数,因此除了特别需求之外,我们最好尽量使用 ray-triangle intersection.
ray query 则相当于一个各个 pipeline 都能调用的查询接口(在 CS,PS 乃至于各种 hit shader 等都能调用),而不是像 ray tracing pipeline 那样独立的一套管线.
通过调用 TraceRayInline() 接口来使用 ray query 硬件光追:同样对 AS 进行 ray traversal,但与 ray tracing pipeline 不同的是,ray query 只会提交 intersection 的信息(position,primitive id,instance id 等),并不会调用任何其它 shader.
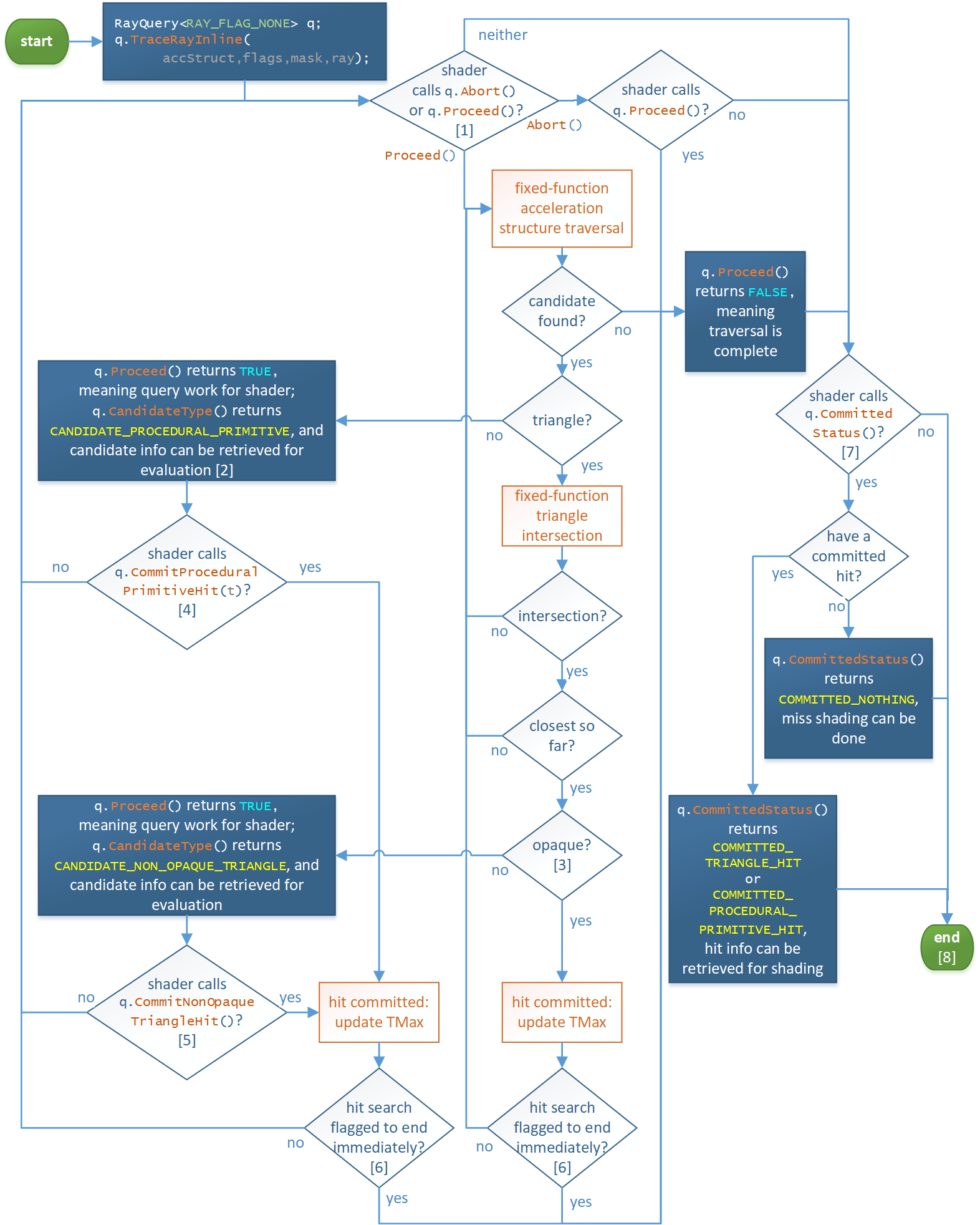
ray query 明显就是 ray tracing pipeline 的阉割版,或者也可以说是 ray tracing pipeline 的子部件,基本只负责了 ray-traversal 的操作。而 ray tracing pipeline 不仅做了 ray-traversal 的操作,还能自动调用合适的 shader 对 hit point 进行着色(一般是用于计算材质).
SSRT 可能是大家都比较熟悉的软件光追方式,它主要就是将屏幕所看到的表面几何信息当成一个场景,利用屏幕的 depth texture 来做 ray marching:每次 marching 一步后就可以检测当前点的 z 值与在 depth texture 中对应的 depth 哪个更小,如果 depth 更小则说明 marching 碰到了屏幕中的 pixel,就可以访问对应的屏幕信息作为 hit point 的属性.
而在实践中,还可以借助 hi-z(depth texture 的 mipmap)来优化 marching 性能,因为 mip 层级高的 depth texture 相当于为更高层级的 bounding volume 表示,这样就可以实现大步的 marching.
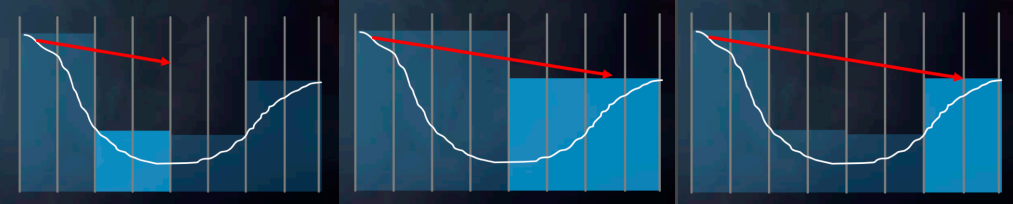
显而易见的问题是:如果 marching 最终走出了屏幕外,那么 SSRT 将无能为力去处理(因为只记录了屏幕上的信息)。并且 SSRT 的命中判断是保守的:即 SSRT 产生 hit 了则 ground truth ray tracing 必定会产生 hit,但 SSRT miss 了但 ground truth ray tracing 不一定会 miss.
以上内容均在我以前的博文( 基于屏幕空间的实时全局光照(Real-time Global Illumination Based On Screen Space) - KillerAery - 博客园 (cnblogs.com) )也有大概介绍.
此外,SSRT 还有一个效果问题:由于相交检测是简单的深度比较,这就相当于把摄像机所看到的 depth texture 都当成了完全实心的场景,但是这样在一些 case 下是不正确的(特别是一个小物体放进摄像机的近处,然后遮挡了大部分场景).
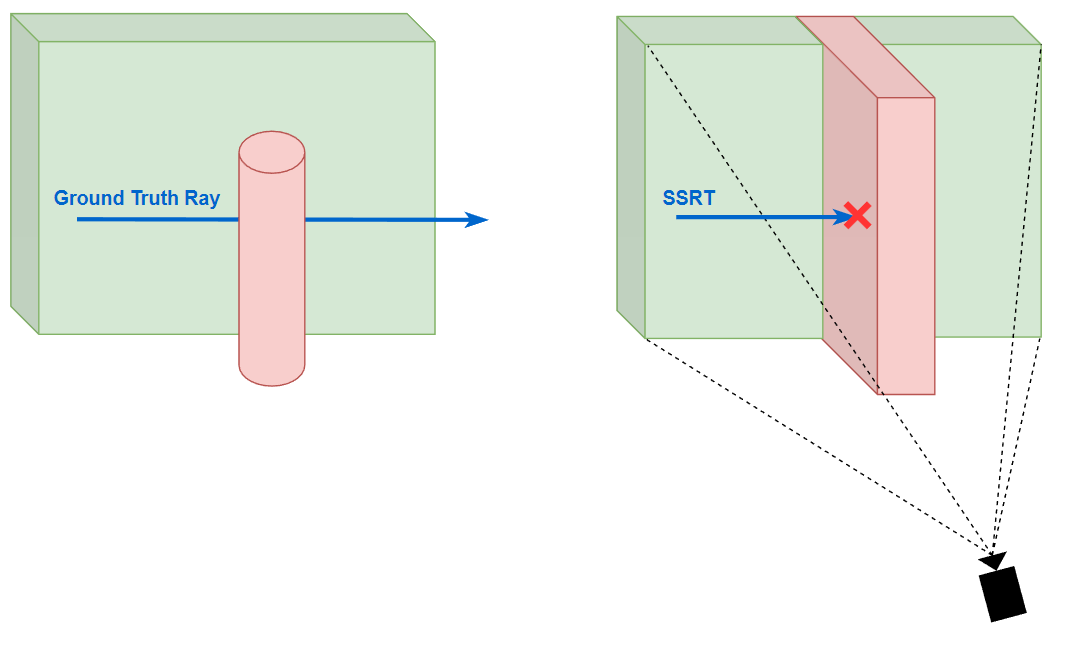
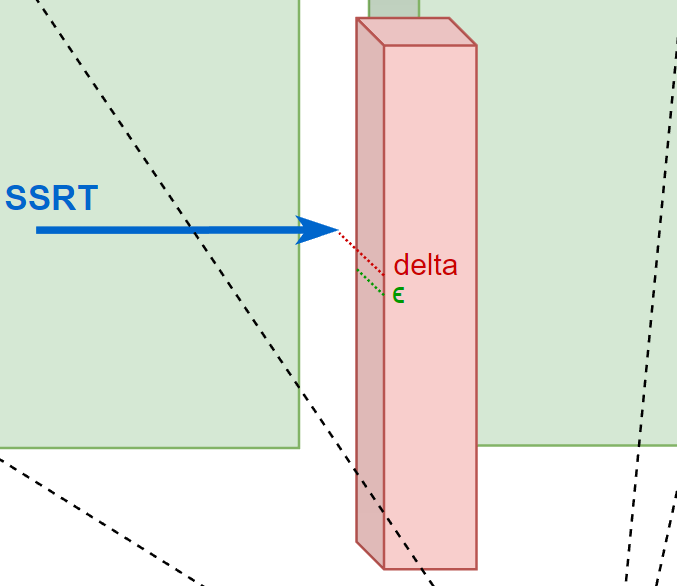
为了改进这一点,在 marching 的时候我们不能简单地认为 depth texture 的 depth 值小于 z 值就是发生碰撞了,而是同时还要额外检测 z 和 depth 的相差值 delta,如果大于一定阈值 \(\epsilon\) ( \(\epsilon\) 可以与 depth 相关),我们是无法断定是否发生碰撞的(因为不知道这个 pixel 的 “深度柱” 是实心的还是空心的),应当选择放弃本次 SSRT(视为 SSRT miss).
HFRT(height field ray tracing) 中的 height field 基本是用来描述大地地形的,而地形往往是表面平滑的且实心的,不会像 screen space depth texture 那样可能有镂空问题或者表面突变问题.
与 SSRT 相同的是,HFRT 的命中判断也是保守的:即 HFRT 产生 hit 了则 ground truth ray tracing 必定会产生 hit,但 HFRT miss 了但 ground truth ray tracing 不一定会 miss.
与 SSRT 不同的是:
HFRT 的 ray tracing 方式类似 relief map(浮雕贴图),即一般采用 ray marching + 二分找零点,效率往往更高:


depth texture 无法保证其表示的表面是连续的,从而也不能转换成找零点问题.
voxelization 涉及的内容太多(投影、孔洞问题等),存储的结构也由很多种(3d texture clipmap,sparse octree 等),由于本文主要涉及 ray tracing 本身,因此不多展开.
其实是懒得写了XD,以后再补.

最简单的方法便让 marching 步长固定为一个 voxel 的边长,每 marching 一步就采样当前位置所在的 voxel 并且累加 alpha 值(不透明物体占据 voxel 时alpha 值为 1,半透明物体占据 voxel 时 alpha 值为0到1间的某个值,不存在物体在 voxel 的位置时则 alpha 值为 0),如果累积的 alpha 值仍然小于一定阈值则继续 marching:
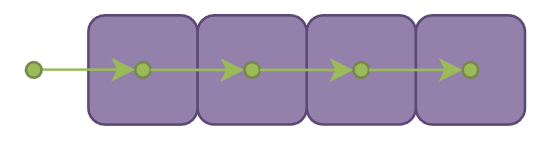
但是由于 voxel 并不像球那样中心点到表面都一样的距离,在斜方向的情况下很容易出现 marching 后仍然停留在同一个 voxel 从而产生重复采样.
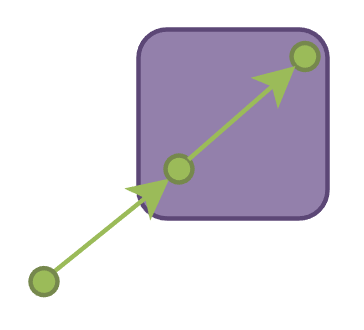
当然,可以通过判断当前 voxel 是否和上一个 voxel 一样来决定是否放弃本次采样并继续 marching;但更好的 marching 方式应当是使用直线绘制算法中的 DDA (Digital Differential Analyzer) 算法来决定步长:将 ray 方向分别映射到 x,y,z 三个轴,取最大值的轴作为主步进轴;每次 marching 必须要满足在这个主步进轴走 1 个单位距离(即 1 个 voxel 边长),而另外两个轴对应的步进距离也能通过比例算出:
// 仅伪代码,不做边界检查
vector3 voxelMarchingStep_DDA (vector3 origin, vector3 end)
{
vector3 offset = end - origin;
vector3 dir = normalize(offset);
float
maxScalar = max(max(
abs
(dir.x),
abs
(dir.y)),
abs
(dir.z));
vector3 step = dir / maxScalar * voxelSize;
return
step;
}
如果有层次结构的 voxel(如含 mipmap 的 3d texture),还可以采用 HDDA(Hierarchical Digital Differential Analyzer)算法:大概思想就是先在高层级的 voxels 上进行 marching 和采样,如果发现存在非空 voxel,再降级到底层级的 voxel 进行 marching 和 采样.
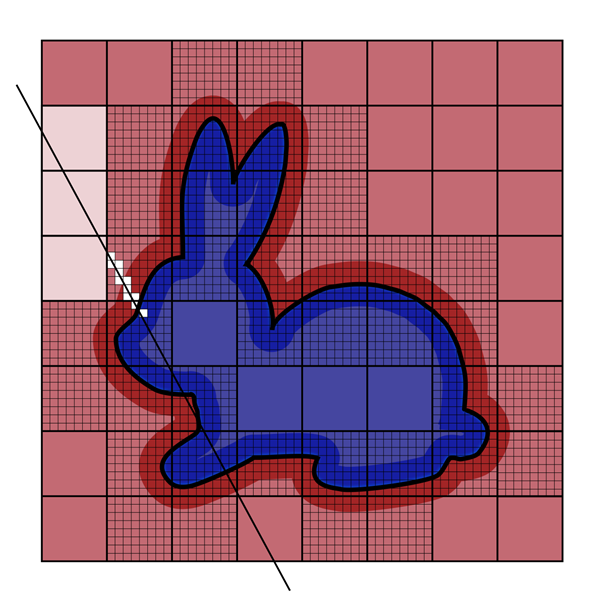
将一堆从相同 origin 点出发的 rays 近似成一个 cone 的形式.
类似 voxel ray tracing,voxel cone tracing 累积的 alpha 值小于一定阈值则继续 marching;不同的是随着 marching 越来越远离 origin 点,cone 的直径也越来越大。而 voxel cone tracing 聪明地对 voxels 的 3d texture 生成预过滤的 mipmap:在 cone 半径小的时候在 mipmap level 低的 voxel texture 去采样,在 cone 半径大时候在 mipmap level 高的 voxel texture 去采样.
当然,本身 voxels 便是不准确的场景表达,而预过滤的 texture 更进一步会导致高频信息的丢失,尤其是 mipmap level 高时。因此 voxel cone tracing 往往仅适用于搜集不那么准确的光照.
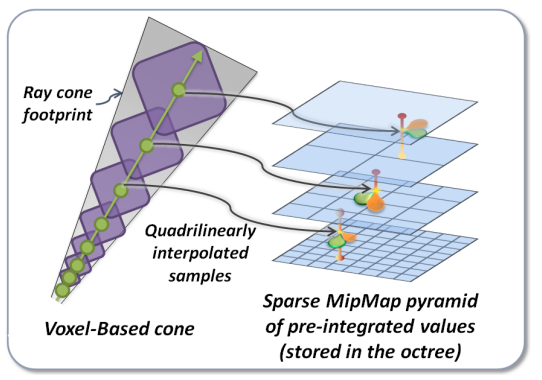
以下是一些 voxel cone tracing 的数学关系.
一次 marching 步长 \(step\) 取决于 cone 的直径 \(d\) :
\[step = max(d, voxelSize(level)) \]
当前应该去哪个 mipmap level 采样 voxel 也需要取决于直径 \(d\) :
\[level = \log_2(\frac{d}{voxelSize(maxLevel)}) \]
而直径 \(d\) 又取决于 marching 总共走过的距离 \(t\) 和 cone 的张角 \(ψ\) :
\[d = 2 * t * tan\frac{ψ}{2} \]
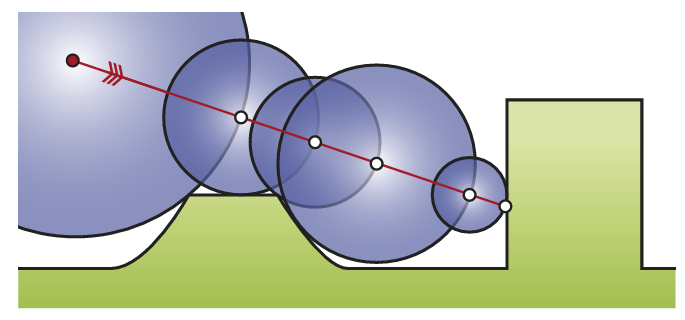
所谓的 SDF tracing(或者更正式的叫法为 sphere tracing),其实就是基于 SDF 的 ray marching。其基本原理非常简洁,也非常聪明:从点 \(x_{0}\) 开始投射一条 ray,然后进行若干次 marching,每次 marching 的起点为上一次 marching 的终点,而 marching 的步长取为起点 \(x_{n}\) 的 SDF 值 \(f(x_n)\) .
SDF 代表着离该点最近的几何表面有多远,也就是说在 SDF 值范围内,这个 ray 绝对不会与任何几何表面相交.
当然 \(f(x_n)\) 在有限步数下无法收敛到刚好为 0,实现中往往用一个小的阈值 $\epsilon $ 来做命中判断.
在实践中,最常用 3D texture 来存储 SDF,也就是说 SDF 是以均匀网格的形式存储的,每个 cell 存储一个 SDF 值。容易想到,对整个场景构建高精度的 SDF 将会耗费巨量带宽和存储空间,并且在实时渲染领域往往是不可以承担的.
UE5 Lumen 为了解决场景的 SDF 表示问题,为每个 mesh 单独预生成了一个高精度的 sdf(称之为 mesh sdf),然后将场景中每个 mesh sdf 实时合成一个低精度的场景 sdf(称之为 global sdf).
这样就可以先在 global sdf 进行低精度的 sdf tracing,当 marching 到存在 mesh sdf 的区域时,就可以访问对应的 mesh sdf 进行高精度的 sdf tracing.
global sdf 可视化:

mesh sdf 可视化:

源于 AMD 的方案(Real-time Sparse Distance Fields for Games | GDC2023)。由于篇幅有限,这里只讲个大概,实际上还有更多细节和优化策略,感兴趣的建议看引用的原文.
为每个 mesh 预生成 mesh sdf 会限制 mesh 的动态性(不允许动态拉伸或者顶点偏移等),而 AMD 给出的方案则是实时根据局部区域的 triangles 去生成 local DF,并将这些 local DF 以 3-level AABB Tree 的形式组织起来(一个 local DF 就是一个叶结点).
其具体流程如下:
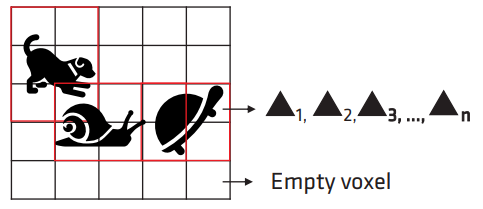
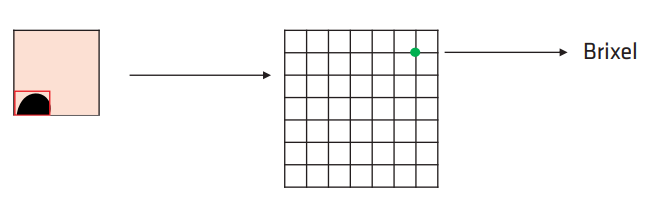
对每个 brick,遍历对应 voxel 的 triangle list:
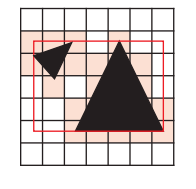
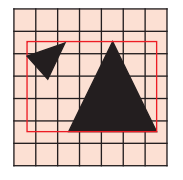
对于边界的 brixels,则参与所有邻接 bricks 的计算.
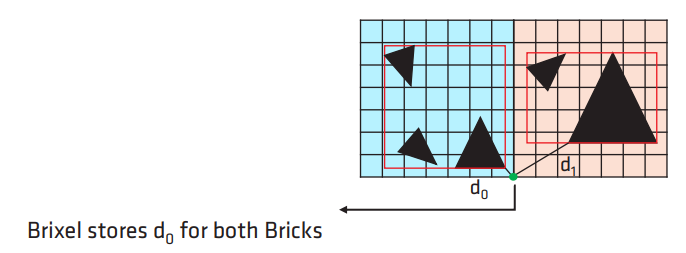
对计算出来的 AABB boxes 构建出一棵 3-level AABB tree,以供后续 sdf tracing 查询使用.

传统 sphere tracing 算法中,在点 \(x_n\) 的 ray marching 步长应取为 SDF 值 \(f(x_{n})\) ,而这种 marching 其实是保守的.
实际上我们可以采用更激进的步长倍数 \(\alpha\) ,只要 \(x_n\) 的SDF 值加激进 marching 后到达 \(x_{n+1}\) 后的 SDF 值 \(f(x_{n+1})\) 大于本次激进 marching 的步长 \(\alpha f(x_n)\) (即 \(f(x_n) + f(x_{n+1}) > \alpha f(x_{n})\) ,在几何上实际就是表现为两个 sphere 相交),那么就说明 ray 可以安全通过本次激进 marching,否则应当退回到点 \(x_n\) 的位置重新进行保守的 marching.
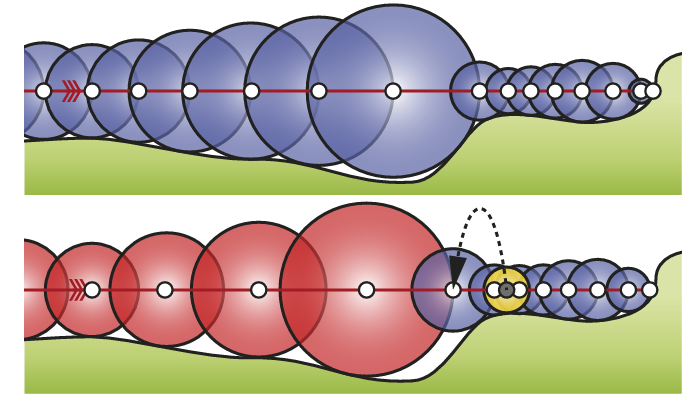
当然,过于激进的步长倍数会导致过多的回退,而过保守的步长倍数则不会带来效率的提升,因此应该针对自己的场景调整 \(\alpha\) 参数(引入一些动态调整 \(\alpha\) 的方法,如下面的 accelerating sphere tracing),而原 paper 的作者推荐大约 \(\alpha = 1.2\) 倍步长为性能最佳.
更进一步的激进策略是:永远假设前两次 marching 所形成的 sphere 都相切于同一平面,那么下一次可以尝试 marching 这样一个 sphere:与该平面相切,也刚好与上一次的 marching sphere 相切;如果尝试失败则回退至保守 marching.
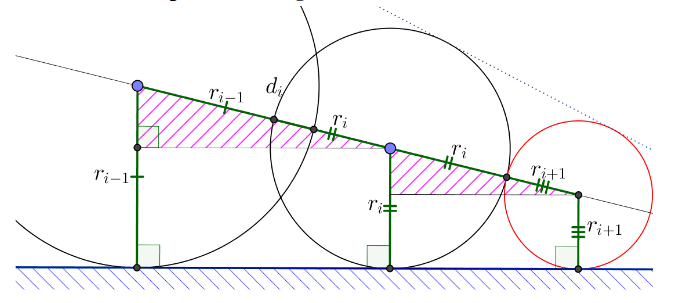
那这个尝试 marching 的具体步长应该是多少呢?
由相似三角形易得 \(\frac{d_i}{r_i+r_{i+1}}=\frac{r_{i-1}-r_i}{r_i-r_{i+1}}\) 。
那么尝试的步长应为:
这种策略比 enhanced sphere tracing 回退次数减少了许多,有更好的加速效果.
一堆数学定义(如 Lipschitz),还要假设场景是 \(C^2\) 连续(如果有棱角基本就容易出问题),并且不一定有优化(甚至可能是负优化,因为需额外多次采样 SDF 来求导),不推荐用.
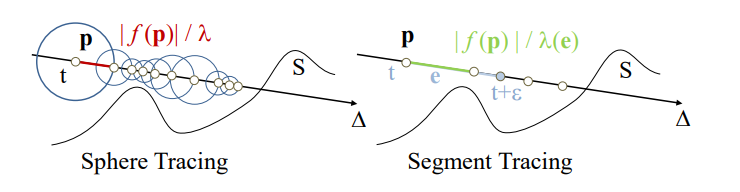
实在好奇,也可以这样感性地理解:segment tracing 实际上就是在 ray 的方向分成一段段线段(segment),然后算 segment 的顶点和末尾点的 SDF 一阶导,并由此推算出这段 segment 附近的大概安全区域(SDF 一阶导相当于往最近表面的反方向,由两个导数信息就可以推算出大概的表面信息),并算出 ray 如果要经过这块区域,其最远的安全步长是多少.
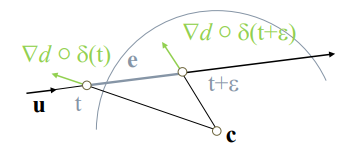
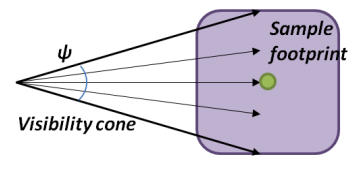
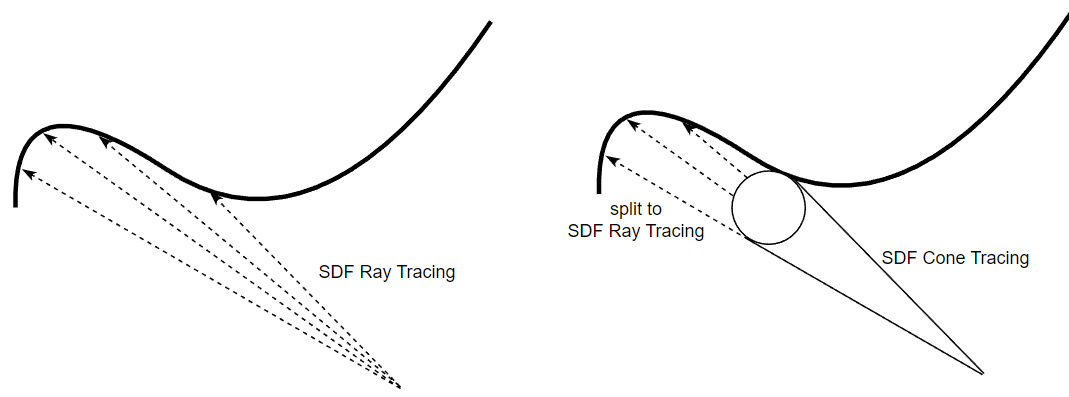
如果有多条从相同起点出发且出射方向相近的 rays,可以将它们合并成一个 cone,先进行 SDF cone tracing,hit 到物体时再分裂成原始的多条 rays 并分别进行 SDF ray tracing.
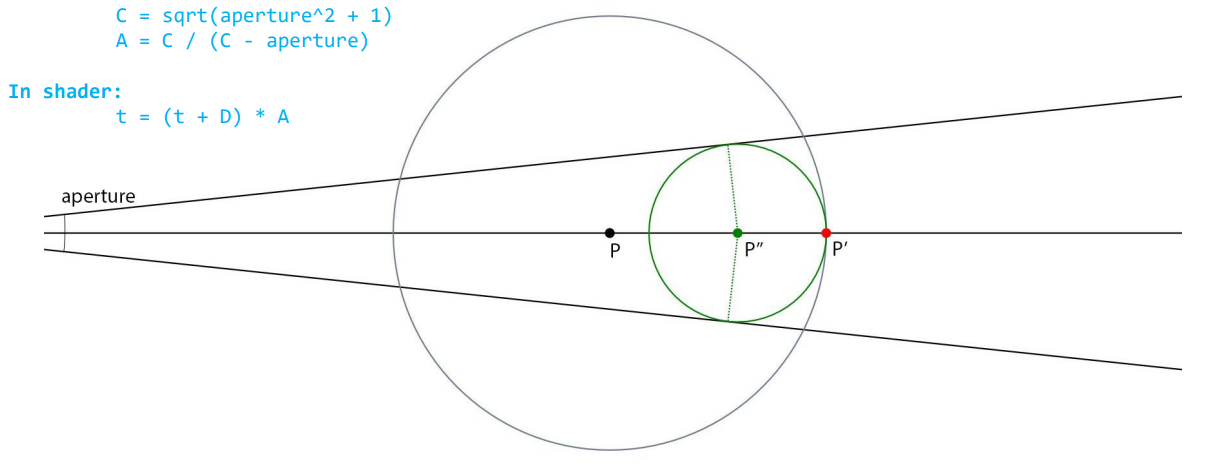
SDF cone tracing 的过程基本和 sphere tracing 差不多,只是步长不一样:第 n 次 marching 不是走到 \(x_{n} + f(x_{n})\) 的位置(对应下图 \(P'\) 的位置),而是走到 \((x_n+f(x_n))* A\) 的位置(对应下图 \(P''\) 的位置).
这是因为 ray tracing 本质上是一个点在 marching 而 cone tracing 是一个半径逐渐变大的球在 marching, \(P''\) 是能保证这个球绝对安全的最远位置.
可以看到 SDF cone tracing 的 marching 往往是比 SDF ray tracing(sphere tracing)要短的,会导致更多步长。但如果 rays 共享 cone tracing 从而减少的总步长次数大于 cone tracing 带来的额外步长次数,那么这个策略便能有很大用处(尤其对于一堆集中方向的 glossy/specular rays).
ray tracing pipeline 算是最理想的 ray casting 方法,它能获得 hit point 的材质,并且得益于硬件加速,其性能也并不亚于软件光追,因此基于 ray tracing pipeline 往往就可以设计出一套相当理想的实时光追算法。然而在硬件不支持或部分支持(仅支持 ray query)的大部分平台,如移动端,nintendo switch等,无论是 ray query 还是软件光追都不能直接获得 hit point 材质,因此往往还需要设计一套低精度的 material cache.
下面的实践主要是围绕 ray query 和软件光追来介绍,基本不介绍 ray tracing pipeline(因为它可以直接简单粗暴的做好).
可以通过传统的光栅化流程去做,而不是真的往屏幕投射 primary ray.
我们在常常需要计算某些着色点受到的直接光照,就往往需要从该点往光源投射 shadow ray 来检测是否被遮挡,我们可以通过一套类似流水线的流程去处理 shadow ray:
当阴影需要考虑半透明物体(例如树叶)时,意味着我们的 shadow ray tracing 不能只考虑是否被遮挡,还得考虑遮挡物体的 opacity,并且这一次 ray tracing 还可能将发生多次 intersection.
当我们通过 ray query 去做半透明阴影时(需要设置 RayFlags 为 NoOpaque),每当产生 intersection 时,需要中断返回到我们自定义的程序,该程序需要计算出交点 uv 坐标采样 alpha mask texture,并累积 alpha 值,若低于 opacity 阈值就继续进行 ray tracing.
一个优化方式是:我们可以进行多次非透明的 ray query(需要设置 RayFlags 为 Opaque):每次 ray query 产生 intersection 就 commit,然后做 alpha 相关测试(和上面一样),如果还需要继续 ray tracing,那就更新发射点位置为 intersection 的位置并进行新一次的 ray query.
这个优化方式的性能往往能提升2倍甚至更多的性能,一方面是 RayFlags 设置成 Opaque 后 ray query 的流程会简化很多,另一方面是因为 ray query 是特定的硬件流程,中断返回会导致额外的 latency,因此尽量让 ray query always commit.
而除了计算直接光照以外,我们还往往需要计算着色点受到的间接光照,这时候往往需要投射 material ray,获取 hit point 的材质信息以计算 radiance:
对于硬件光追 ray tracing pipeline 来说,material ray 是容易实现的:直接通过 closest hit shader 来计算出 hit point 的材质信息,并之后通过 payload 来获取材质信息即可.
注:几何信息有部分还是可以强行获得的,如通过 SDF 梯度算 normal ,或者 triangle id 获取 3 个 vertex 从而算出 face normal 等.
最后此篇关于实时光线追踪(3)RayCasting的文章就讲到这里了,如果你想了解更多关于实时光线追踪(3)RayCasting的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
28
4
 0
0
Closed. This question is opinion-based。它当前不接受答案。 想改善这个问题吗?更新问题,以便editing this post用事实和引用来回答。 2年前关闭。
我想显示我的网站上所有用户都在线(实时;就像任何聊天模块一样)。我正在使用下面提到的脚本来执行此操作。 HTML: Javascript: var doClose = false; documen
有什么方法可以知道 Algolia 何时成功处理了排队作业,或者与上次重新索引相比,Algolia 是否索引了新文档? 我们希望建立一个系统,每当新文档被索引时,浏览网站的用户都会收到实时更新警告,并
构建将在“桌面”而不是浏览器中运行的 Java 应用程序的推荐策略是什么。该应用程序的特点是: 1. Multiple application instances would be running o
这是场景: 我正在编写一个医疗相关程序,可以在没有连接的情况下使用。当采取某些措施时,程序会将时间写入CoreData记录。 这就是问题所在,如果他们的设备将时间设置为比实际时间早的时间。那将是一个大
我有: $(document).ready(function () { $(".div1, .div2, .div3, .div4, .div5").draggable();
我有以下 jquery 代码: $("a[id*='Add_']").live('click', function() { //Get parentID to add to. var
我有一个 jsp 文件,其中包含一个表单。提交表单会调用处理发送的数据的 servlet。我希望当我点击提交按钮时,一个文本区域被跨越并且应该实时显示我的应用程序的日志。我正在使用 Tomcat 7。
我编辑了我的问题,我在 Default.aspx 页面中有一个提交按钮和文本框。我打开两个窗口Default.aspx。我想在这个窗口中向文本框输入文本并按提交,其他窗口将实时更新文本框。 请帮助我!
我用 php 创建了一个小型 CMS,如果其他用户在线或离线,我想显示已登录的用户。 目前,我只创建一个查询请求,但这不会一直更新。我希望用户在发生某些事情时立即看到更改。我正在寻找一个类似于 fac
我有以下问题需要解决。我必须构建一个图形查看器来查看海量数据集。 我们有一些特定格式的文件,其中包含数百万条代表实验结果的记录。每条记录代表大图上的一个样本点。我见过的最大的文件有 4370 万条记录
我最近完成了申请,但遇到了一个大问题。我一次只需要允许 1 个用户访问它。每个用户每次都可以访问一个索引页面和“开始”按钮。当用户点击开始时,应用程序锁定,其他人需要等到用户完成。当用户关闭选项卡/浏
我是 Android 开发新手。我正在寻找任何将音高变换应用到输出声音(实时)的方法。但我找不到任何起点。 我找到了这个 topic但我仍然不知道如何应用它。 有什么建议吗? 最佳答案 一般来说,该算
背景 用户计算机上的桌面应用程序从调制解调器获取电话号码,并在接到电话后将其发送到 PHP 脚本。目前,我可以通过 PHP 在指定端口上接收数据/数据包。然后我有一个连接到 411 数据库并返回指定电
很抱歉提出抽象问题,但我正在寻找一些关于在循环中执行一些等效操作的应用程序类型的示例/建议/文章,并且循环的每次迭代都应该在特定时间部分公开其结果(例如, 10 秒)。 我的应用程序在外部 WCF 服
这个问题在这里已经有了答案: 关闭 10 年前。 Possible Duplicate: What specifically are wall-clock-time, user-cpu-time,
我最近遇到了一个叫做 LiveChart 的工具,决定试用一下。 不幸的是,我在弄清楚如何实时更新图表值时遇到了一些问题。我很确定有一种干净正确的方法可以做到这一点,但我找不到它。 我希望能够通过 p
我正在实现实时 flutter 库 https://pub.dartlang.org/packages/true_time 遇到错误 W/DiskCacheClient(26153): Cannot
我一直在使用 instagram 的实时推送 api ( http://instagram.com/developer/realtime/ ) 来获取特定位置的更新。我使用“半径”的最大可能值,即 5
关闭。这个问题不满足Stack Overflow guidelines .它目前不接受答案。 想改善这个问题吗?更新问题,使其成为 on-topic对于堆栈溢出。 7年前关闭。 Improve thi

我是一名优秀的程序员,十分优秀!