
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4



Photo by Merilin Kirsika Tedder from Pexels 。
MySQL作为一个流行的开源关系型数据库管理系统,它可以运行在多种平台上,支持多种存储引擎,提供了灵活的数据操作和管理功能。MySQL的逻辑架构可以分为三层: 连接层 、 服务层 和 引擎层 ,下方是网上流传度很广的一张架构图.
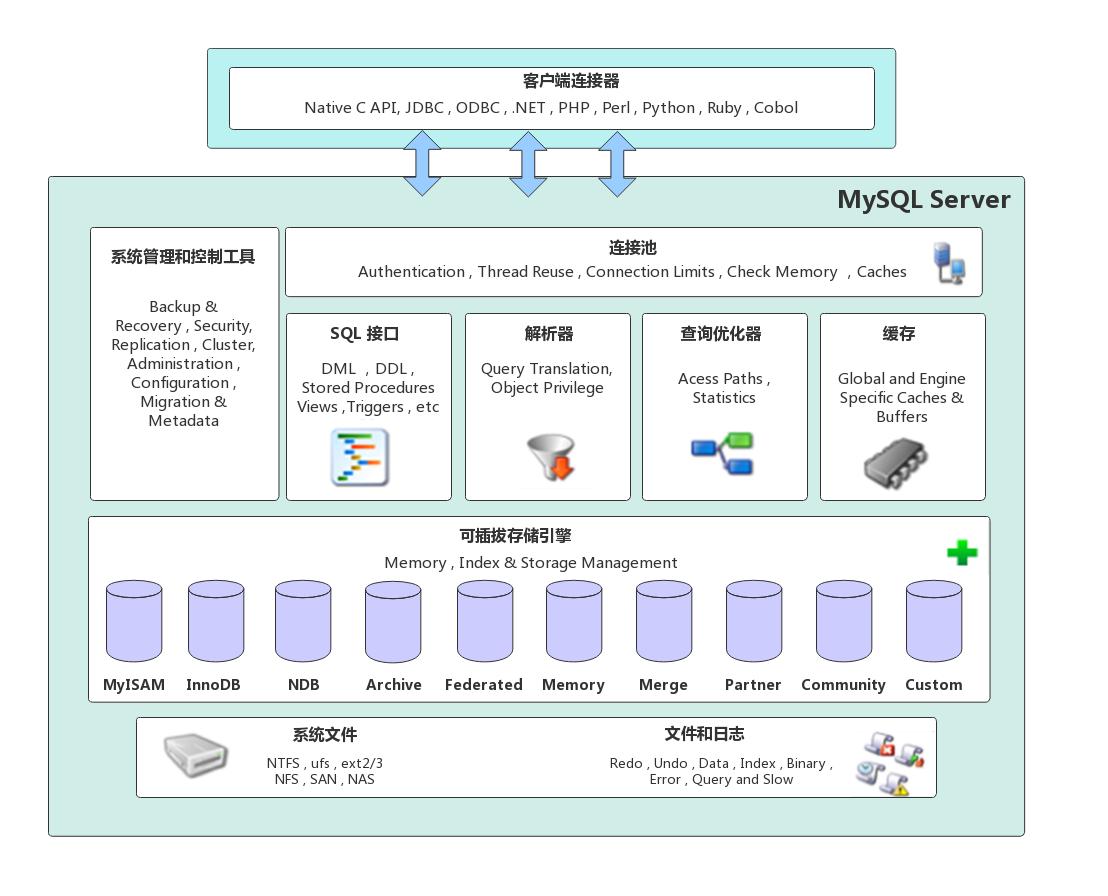
需要注意的是, 上图描述的是MySQL5.7及以前的逻辑架构,MySQL8.0中正式移除了查询缓存组件, 因为从收集的数据来看查询缓存的命中率很低,即使是在MySQL5.7中查询缓存这个选项也是默认关闭的,所以本篇文章就不对缓存这款内容做解析了。具体可以查看官方的一篇博客:
MySQL :: MySQL 8.0:停用对查询缓存的支持 。
事实上,如果不去关注其内部的细节,《高性能MySQL》一书中的这张简图也足够让我们对其逻辑架构有一个直观的认知:
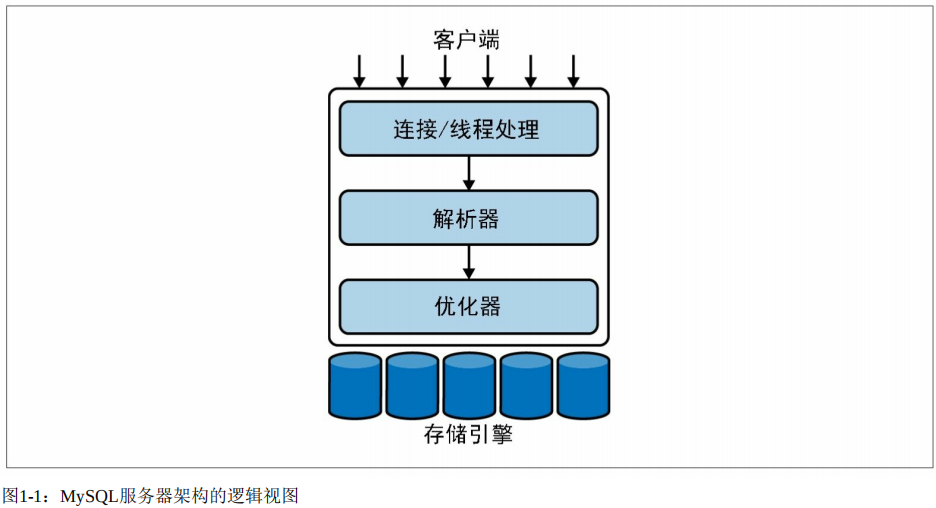
当客户端发送连接请求时,MySQL服务器会在连接层接收请求,分配一个线程来处理该连接,随后进行身份验证。具体的功能如下:
客户端连接的建立与处理:当客户端发起连接请求时,MySQL会创建一个专用的线程(以操作系统级别的线程实现)来为该客户端服务。这些服务线程使用线程池里的长连接服务多个用户请求,减少了线程切换的开销.
安全认证:安全认证是连接层的另一项重要任务。当客户端连接到MySQL服务器时,服务器首先需要验证客户端的身份。MySQL使用基于用户名、主机和密码的认证方式。在连接时,客户端需要提供有效的用户名、主机名和密码,服务器会根据在"mysql.user"表中的数据进行验证,若通过,则建立连接.
连接资源管理:MySQL支持可配置的最大连接数。当到达最大连接数时,新的连接请求会被拒绝。符合条件的客户端可以设置连接超时时间、客户端闲置关闭时间等参数。同时,可以通过"mysql.user"表配置特定用户对于数据库的操作权限.
线程管理:MySQL会自动创建和管理连接线程,其中包括以线程数作为上限的线程池。线程池的目的是复用连接线程,避免了线程切换和创建的开销。此外,MySQL使用异步I/O机制和协程,尽可能提高了并发和吞吐量.
服务层是MySQL中的核心组件,负责提供各种数据库操作所需的基本功能,如SQL语法处理、事务管理、锁管理等.
服务层负责从客户端接收来自连接层的SQL查询请求,并进行初始分析、解析和预处理.
MySQL的服务层负责事务管理,确保在执行一系列操作时,满足原子性、一致性、隔离性和持久性这四个特性。事务管理涉及的主要功能包括:
MySQL优化器使用缓存来提高查询速度,包括:
引擎层负责存储数据和执行SQL语句。MySQL支持多种存储引擎,每种引擎各有特点,根据实际需求进行选用。当然,只要没有非常明确的特殊需求就不需要更改存储引擎,因为InnoDB在大部分场景下都比其他引擎更加适用。引擎层通过标准API与服务层交互,实现数据的存储和查询.
我们可以在SQL命令行中执行 show engines; 来查看当前支持的存储引擎:
mysql> show engines;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
9 rows in set (0.00 sec)
SQL语句的执行流程可以简单分为以下几个步骤:
另外请注意,本篇文章依旧是在为后续写MySQL优化流程做知识上的铺垫,所以一些细节会简单介绍,但实际的SQL优化思想会等到后面的文章再详细介绍.
下面我们来详细解释一下SQL语句的执行流程和细节.
语法分析是MySQL执行SQL语句的第一步。语法分析器会对SQL语句进行分析,检查其是否符合语法规则。如果SQL语句不符合语法规则,MySQL将会返回一个错误消息。详细的来说又可分为以下几步:
MySQL使用的语法分析器是Bison。它是一种自动生成解析器的工具,可以根据语法规则自动生成语法分析器。下面是一个示例SQL语句:
SELECT name, age FROM student WHERE id = 1;
在语法分析阶段,MySQL会进行以下操作:
| token | type | value |
|---|---|---|
| SELECT | keyword | select |
| name | identifier | name |
| , | symbol | , |
| age | identifier | age |
| FROM | keyword | from |
| student | identifier | student |
| WHERE | keyword | where |
| id | identifier | id |
| = | operator | = |
| 1 | number | 1 |
select_statement: SELECT select_expression_list FROM table_reference_list [WHERE where_condition]
如果以上步骤都没有出现错误,那么MySQL就会认为这条SQL语句在语法分析阶段是正确的,并继续进行后续的处理。否则,MySQL就会报错,并停止执行这条SQL语句.
查询优化是MySQL执行SQL语句的第三步。SQL语句在查询优化阶段会经历以下步骤:
举例说明,下面是一个示例SQL语句:
SELECT name, age FROM student WHERE id IN (SELECT student_id FROM score WHERE score > 80);
则首先在查询重写时,MySQL会将这条SQL语句重写为:
SELECT name, age FROM student s JOIN score c ON s.id = c.student_id WHERE c.score > 80;
这样做的好处是:
接下来在查询分解阶段,MySQL会将这条SQL语句分解为两个子查询:
SELECT name, age, id FROM student;
SELECT student_id FROM score WHERE score > 80;
预处理时MySQL会对SQL语句进行一些基本的检查和处理,例如检查表名和字段名是否存在,解析参数等.
最后优化器会根据统计信息和成本模型,为SQL语句选择一个最佳的执行计划.
MySQL优化器是负责为SQL语句选择一个最佳的执行计划的模块。执行计划包括了连接顺序,访问方法,索引选择,排序策略等。MySQL优化器是基于成本的优化器(cost-based optimizer),也就是说它会根据统计信息和成本模型来估算不同执行计划的代价,并选择代价最小的那个.
MySQL优化器在选择执行计划时会考虑以下几个方面:
例如,上面能够重写后的SQL语句应该是:
SELECT name, age FROM student s JOIN score c ON s.id = c.student_id WHERE c.score > 80;
MySQL优化器在选择执行计划时会进行以下操作:
这么一通分析之后到底有点纸上谈兵,接下来我们在MySQL 8.0 里执行命令,毕竟实践出真知。进入MySQL命令行,利用explain来查看执行计划:
mysql> SELECT name, age FROM student WHERE id IN (SELECT student_id FROM score WHERE score > 80);
+----------+------+
| name | age |
+----------+------+
| zhangsan | 18 |
| wangwu | 20 |
+----------+------+
2 rows in set (0.00 sec)
mysql> explain SELECT name, age FROM student WHERE id IN (SELECT student_id FROM score WHERE score > 80);
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------------------------------------------+
| 1 | SIMPLE | student | NULL | ALL | PRIMARY | NULL | NULL | NULL | 4 | 100.00 | NULL |
| 1 | SIMPLE | score | NULL | ALL | student_id | NULL | NULL | NULL | 8 | 12.50 | Using where; FirstMatch(student); Using join buffer (hash join) |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------------------------------------------+
2 rows in set, 1 warning (0.01 sec)
我们可以在explain的结果中看到,两行的ID值都为1,而我们自己写的SQL语句里有两个Select,说明实际并没有按照我们的原SQL来执行 。
再使用 show warnings 来查看实际执行的sql内容:
mysql> show warnings;
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1003 | /* select#1 */ select `datasets`.`student`.`name` AS `name`,`datasets`.`student`.`age` AS `age` from `datasets`.`student` semi join (`datasets`.`score`) where ((`datasets`.`score`.`student_id` = `datasets`.`student`.`id`) and (`datasets`.`score`.`score` > 80)) |
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
可以发现,实际执行的时候用的是semi join,这是因为Semi Join返回的结果只包含主表(左表)中满足连接条件的行,而不包含从表(右表)的任何数据。它的主要目的是通过减少要比较的数据量来提高查询性能。通过使用Semi Join,可以避免将两个表的所有数据进行连接,并仅仅关注满足连接条件的部分数据.
但是对于开发人员来说,我们并不需要关注优化器内部的所有决策,因为涉及的因素太多了,所以我们从整体上来看知道大致的优化方向即可.
这里也给出上面示例的建表语句,方便有心的读者自行尝试:
CREATE TABLE student
(
id INT PRIMARY KEY auto_increment,
name VARCHAR(20),
age INT
) charset = utf8mb4;
CREATE TABLE score
(
student_id INT,
course VARCHAR(20),
score INT,
FOREIGN KEY (student_id) REFERENCES student (id)
) charset = utf8mb4;
INSERT INTO student (id, name, age) VALUES (1, 'zhangsan', 18),(2, 'lisi', 19),(3, 'wangwu', 20),(4, 'zhaoliu', 21);
INSERT INTO score (student_id, course, score) VALUES (1, '数学', 85),(1, '语文', 90),(2, '数学', 75),(2, '语文', 80),(3, '数学', 95),(3, '语文', 100),(4, '数学', 65),(4, '语文', 70);
SELECT name, age FROM student WHERE id IN (SELECT student_id FROM score WHERE score > 80);
执行SQL语句是MySQL执行SQL语句的最后一步。简单来说,执行器会按照执行计划的步骤,逐步执行SQL语句。执行器会根据查询语句,从磁盘读取数据,并将其存储在内存中。然后,执行器会对数据进行排序、分组、聚合等操作,最终生成查询结果.
说的详细一点,一些重要的步骤如下:
实际上,依旧可以通过MySQL命令行来了解其执行过程:
mysql> set profiling = 'ON';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> SELECT name, age FROM student WHERE id IN (SELECT student_id FROM score WHERE score > 80);
+----------+------+
| name | age |
+----------+------+
| zhangsan | 18 |
| wangwu | 20 |
+----------+------+
2 rows in set (0.00 sec)
mysql> show profile for query 1;
+--------------------------------+----------+
| Status | Duration |
+--------------------------------+----------+
| starting | 0.000094 |
| Executing hook on transaction | 0.000005 |
| starting | 0.000008 |
| checking permissions | 0.000005 |
| checking permissions | 0.000004 |
| Opening tables | 0.000088 |
| init | 0.000009 |
| System lock | 0.000009 |
| optimizing | 0.000012 |
| statistics | 0.000035 |
| preparing | 0.000076 |
| executing | 0.000065 |
| end | 0.000004 |
| query end | 0.000005 |
| waiting for handler commit | 0.000009 |
| closing tables | 0.000008 |
| freeing items | 0.000021 |
| cleaning up | 0.000010 |
+--------------------------------+----------+
18 rows in set, 1 warning (0.00 sec)
可以看到,命令执行结果非常详细的列出了所有步骤,本文只是挑选了一部分来展开说.
具体结合到例子来说明,假设有一条SQL语句如下:
SELECT name, age FROM student s JOIN score c ON s.id = c.student_id WHERE c.score > 80 ORDER BY s.age LIMIT 10;
在执行阶段,MySQL会进行以下操作:
InnoDB是MySQL的默认存储引擎,它支持事务、行级锁、外键、MVCC等特性,提供了高性能和高可靠性的数据存储方案。InnoDB的底层结构主要由两部分组成:内存结构和磁盘结构.
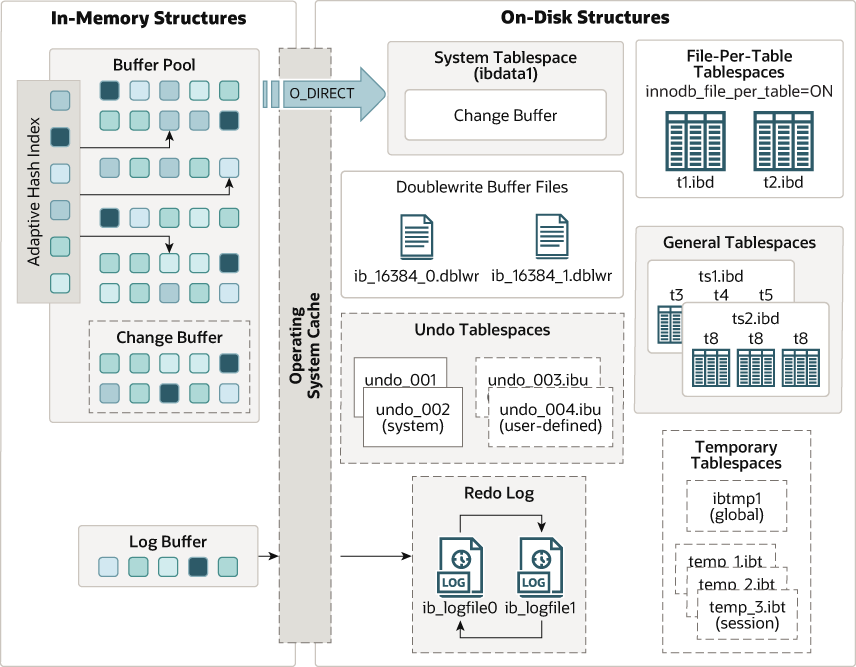
图片来源: https://dev.mysql.com/doc/refman/8.0/en/innodb-architecture.html 。
InnoDB的内存结构主要包括以下几个部分:
如果对这部分内容感兴趣可以看官方文档,这里只做一个简单的介绍.
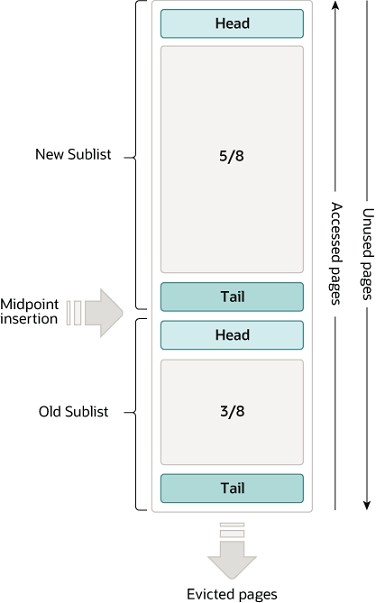
主要用于缓存表数据和索引数据,加快访问速度。缓冲池是InnoDB内存结构中最重要的部分,通常占用宿主机80%的内存。缓冲池被分成多个页,每页默认大小为16KB,每页可以存放多条记录。缓冲池中的页按照LRU(最近最少使用)算法进行淘汰,同时也被分成两个子链表:New Sublist和Old Sublist,分别存放访问频繁和不频繁的页.
主要用于缓存对非聚集索引的修改操作,减少磁盘I/O。写缓冲是缓冲池的一部分,当对非聚集索引进行插入、删除或更新时,不会立即修改磁盘上的索引页,而是先记录在写缓冲中。当缓冲池中的数据页被刷新到磁盘时,会将写缓冲中的修改操作合并到相应的索引页中.
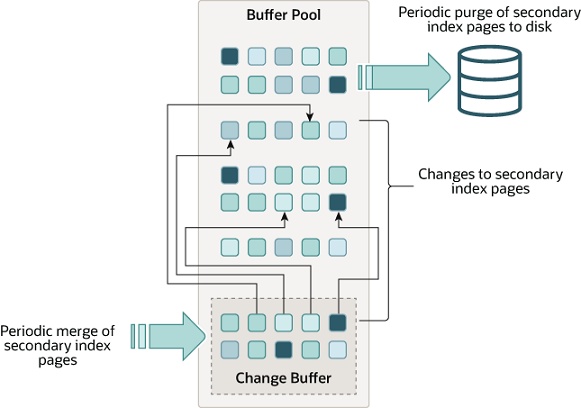
主要用于缓存重做日志(Redo Log),保证事务的持久性。日志缓冲是一个循环使用的内存区域,默认大小为16MB,可以通过参数innodb_log_buffer_size来调整。当事务提交时,会将日志缓冲中的重做日志刷新到磁盘上的重做日志文件中。日志缓冲中的重做日志也会在以下情况下被刷新:日志缓冲已满、每秒钟一次、每个事务检查点一次.
主要用于加速等值查询,提高查询效率。自适应哈希索引是InnoDB根据查询频率和模式自动建立的一种哈希索引,可以将某些B+树索引转换为哈希索引,从而减少树的搜索次数。自适应哈希索引是可选的,可以通过参数innodb_adaptive来开启或关闭.
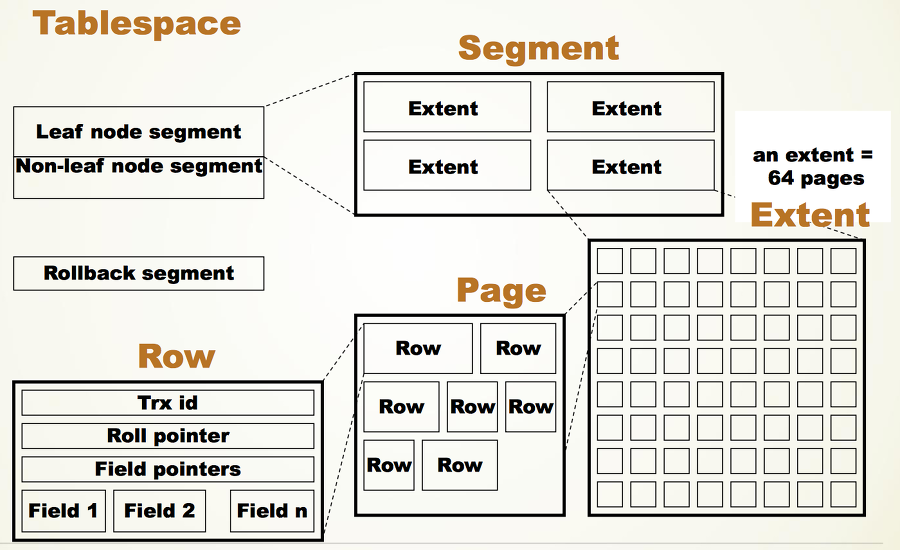
表空间是InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空间中。表空间可以分为以下五种类型¹²³⁴⁵:
数据字典包含用于跟踪对象,如表,索引,和列等元数据的内部系统表²⁴。元数据实际上位于InnoDB系统表空间中。InnoDB使用数据字典来管理和访问数据库对象,并检查用户对对象的权限。数据字典在数据库启动时加载到内存中,并在数据库关闭时刷新到磁盘上.
双写缓冲区位于系统表空间中的存储区域,用于保证数据页在写入磁盘时不会损坏²⁴⁵。InnoDB在Buffer Pool中刷新页面时,会将数据页写入doublewrite缓冲区后才会写入磁盘。如果在写入OS Cache或者磁盘mysql进程奔溃后, InnoDB启动崩溃恢复能从doublewrite找到完整的副本用来恢复.
重做日志是基于磁盘的数据结构,在崩溃恢复期间用于纠正不完整事务写入的数据 。MySQL以循环方式写入重做日志文件,默认会产生ib_logfile0 和 ib_logfile1两个文件。InnoDB在提交事务之前刷新事务的redo log,InnoDB使用组提交(group commit)技术来提高性能。重做日志记录了数据页的物理修改,而不是逻辑修改,这样可以减少日志的大小和恢复的时间。重做日志可以通过innodb_log_file_size和innodb_log_files_in_group参数来调整大小和数量.
更改缓冲区是Buffer Pool中的一部分,用于缓存对辅助索引页的修改 。当InnoDB需要修改一个辅助索引页时,如果该页在Buffer Pool中,则直接修改;如果该页不在Buffer Pool中,则将修改记录在Change Buffer中,而不是从磁盘读取该页。这样可以减少磁盘I/O操作,提高性能。Change Buffer中的修改会在后台或者检查点时合并到辅助索引页中。Change Buffer的大小可以通过innodb_change_buffer_max_size参数来调整.
这部分简单介绍即可,参考官方文档: MySQL :: MySQL 8.0 参考手册 :: 15.11.2 文件空间管理 。
InnoDB的磁盘结构主要包括以下几个部分:
参考资料
最后此篇关于深入浅出MySQL-架构与执行的文章就讲到这里了,如果你想了解更多关于深入浅出MySQL-架构与执行的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
本文分享自华为云社区《 Spring高手之路14——深入浅出:SPI机制在JDK与Spring Boot中的应用 》,作者:砖业洋__ 。 Spring Boot不仅是简化Spring

我是一名优秀的程序员,十分优秀!