
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


系列文章目录和关于我 。
最近有很多想学的,像netty的使用、原理源码,但是苦于自己对于操作系统和nio了解不多,有点无从下手,遂学习之.
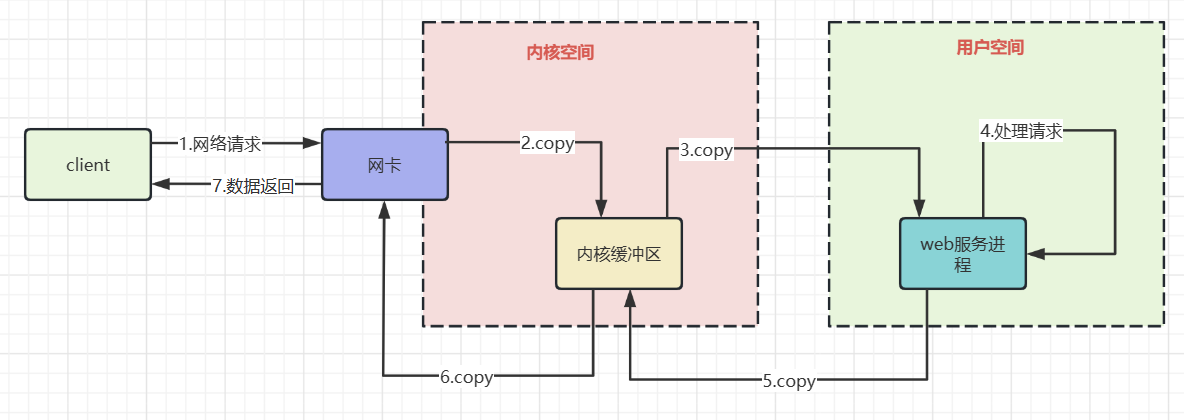
上图粗略描述了网络io的过程,了解其中的拷贝过程有利于我们理解非阻塞io,以及IO多路复用的必要性.
数据从网卡到内核缓冲区 网卡通过DMA的方式将网络帧copy到内核空间 。
并不是拷贝到内核空间就完事了,因为还需要根据协议对数据进行处理.
所以网卡使用硬中断通知cpu,cpu响应后会使用网卡注册函数进行收包,然后协议层处理网络帧.
数据从内核缓冲区到用户空间 。
根据协议处理好的数据,还需要拷贝到用户空间才能被运行在内核态的应用程序使用==>cpu进行数据拷贝。随后内核唤醒用户进程,相当于我们的java程序从阻塞io中被唤醒,继续执行下一行代码的执行.
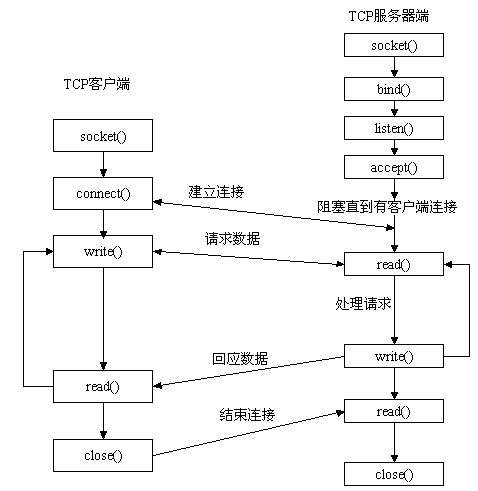
这其中有几个阻塞的过程 。
accept 系统调用:等待客户端建立tcp连接 。
这个问题不大,没有连接那么阻塞服务端线程,可以节约cpu资源.
read系统调用:等待请求数据来到用户空间 。
数据从网卡到用户空间的过程,线程时阻塞的 。
Servlet#service 处理请求是一个同步过程 。
tomcat根据http协议构造request,并和response作为参数,找到对应Servlet调用service方法,Servlet#service方法执行结束,返回内容才能通过write系统调用回应数据.
这导致在业务处理上需要使用线程池来让服务端可以处理多个并发请求.
write系统调用:响应数据写回 。
write系统调用将servlet处理后的响应数据,写回到文件描述符中.
这就是常说的IO多路复用,那为什么需要IO多路复用?
尽量使用较少的系统资源处理更多的连接,如果当前单台服务器接收了1w个请求,服务端当如何处理?
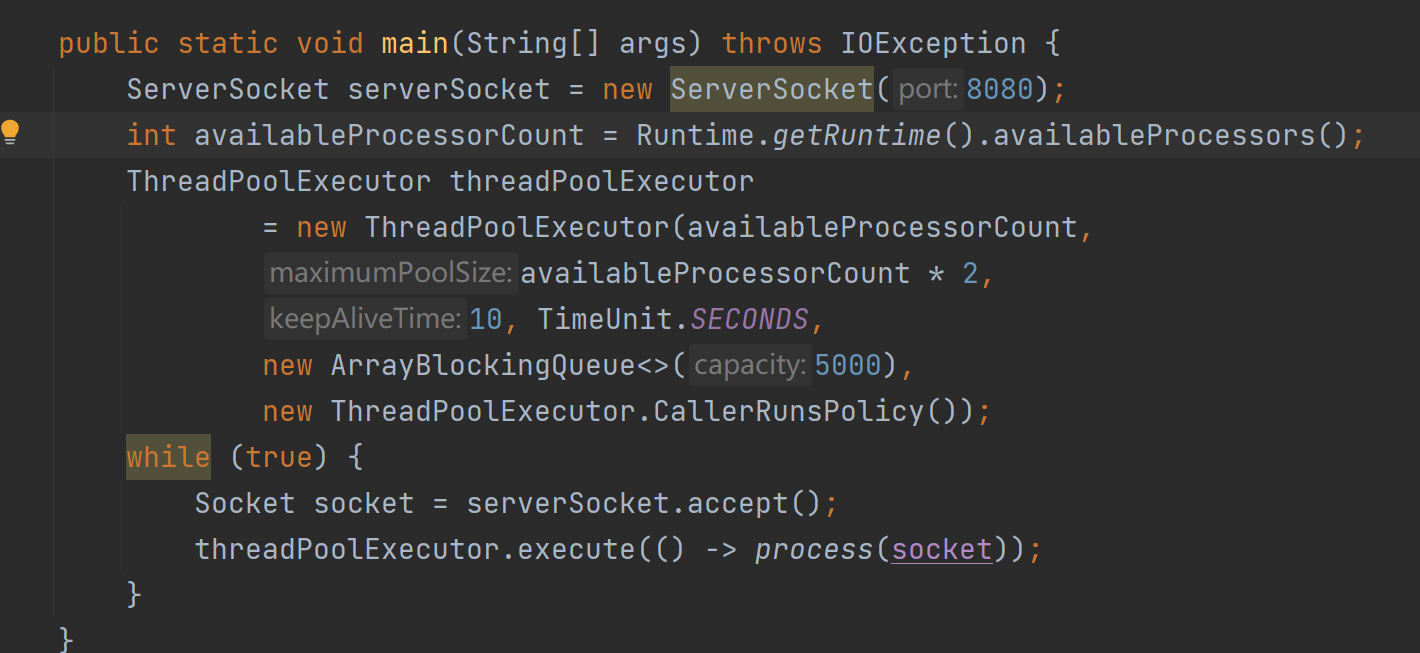
上面是一段java BIO模型并发处理多请求的实例代码,它有以下不足 。
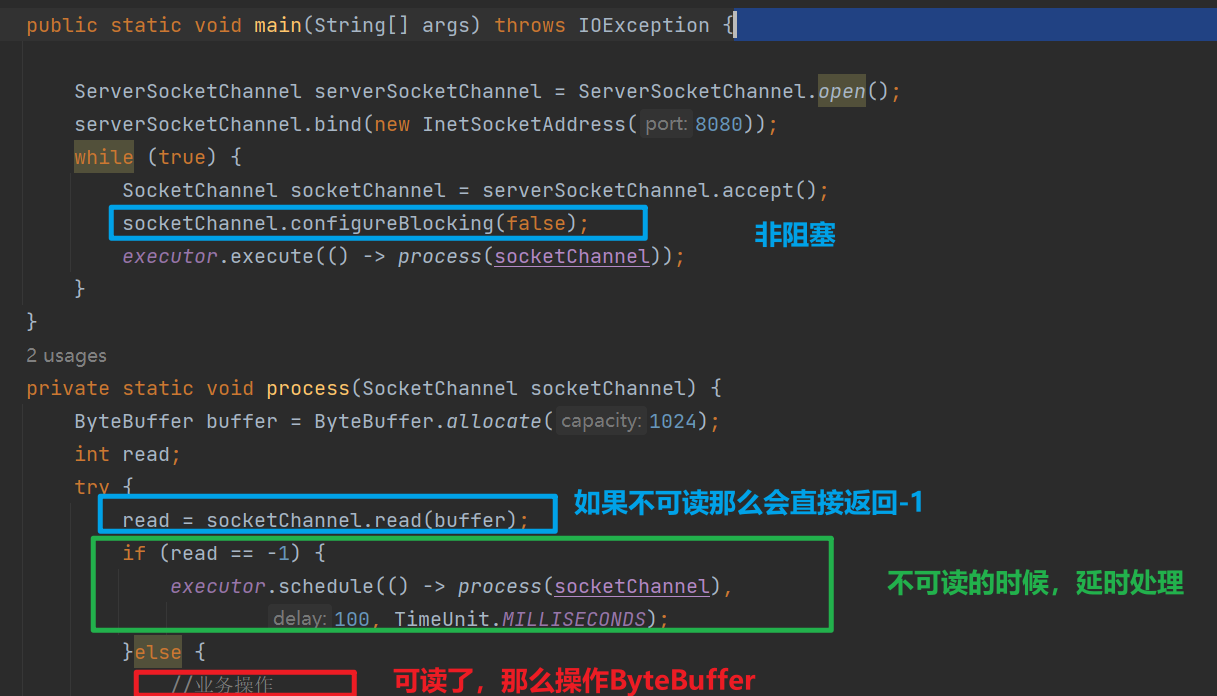
上面是非阻塞IO的一个实例 。
socketChannel.configureBlocking(false) 可以让后续的read在通道数据没有就绪的时候直接返回-1,而不是让线程阻塞。这个特性让调度线程池中的线程减少了阻塞,从而节省了线程资源.

但是这种方式也不是没有任何缺点,多次系统意味着多次系统调用,每次系统调用都需要,用户态<=>内核态的来回切换,需要cpu保存进程的上下文,调用结束还需要恢复进程的上下文.
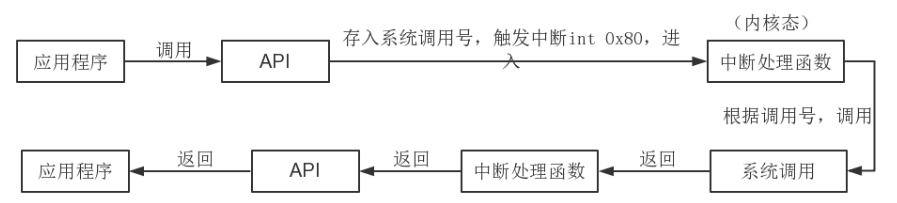

如上是Java IO多路复用的简陋例子。操作系统提供了多路复用的机制,将连接上来的客户端都进行注册,然后不断循环扫描各个客户端连接,监听客户端的请求。但是,多路复用轮询扫描各个客户端连接的过程 在操作系统内核中进行 , 极大的加快了多路复用的效率,减少了用户态和内核态的切换 .
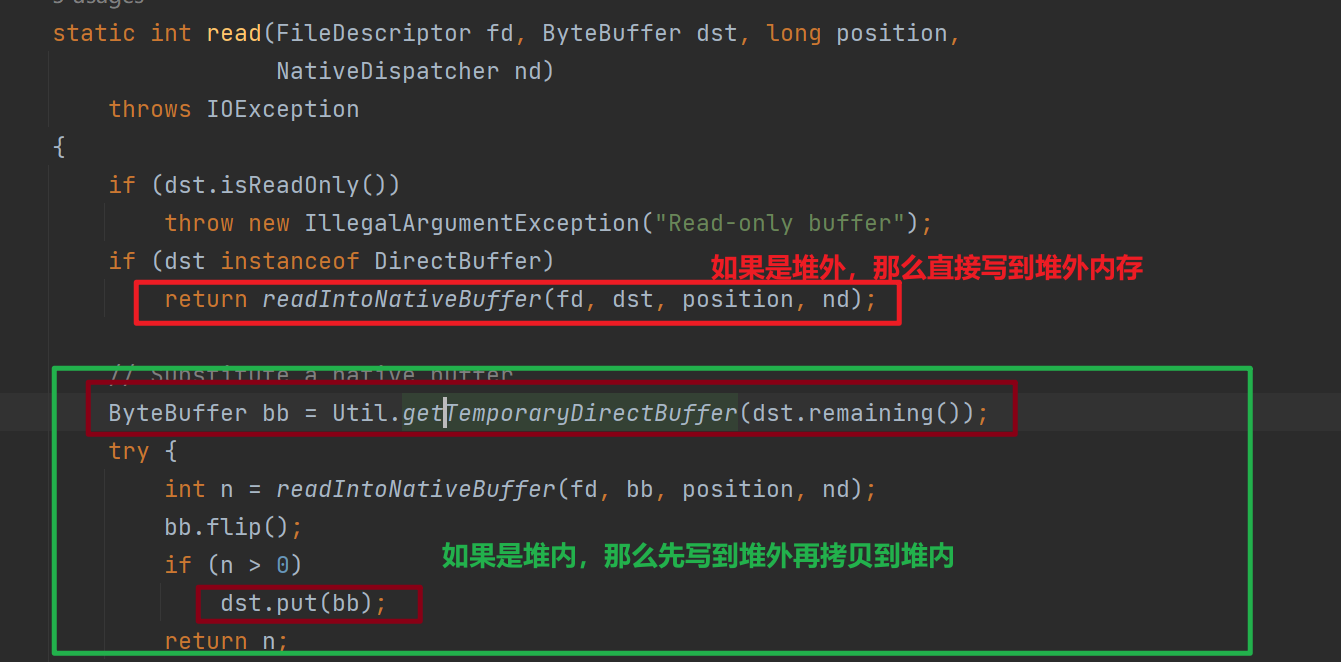
使用NIO Channel读写时需要需要先读到堆外内存,然后拷贝到堆内内存,如果直接使用堆外内存则可以减少堆外到堆内的拷贝过程.
下图是将Channel数据读取到Buffer,调用IOUtil#read的源码 。
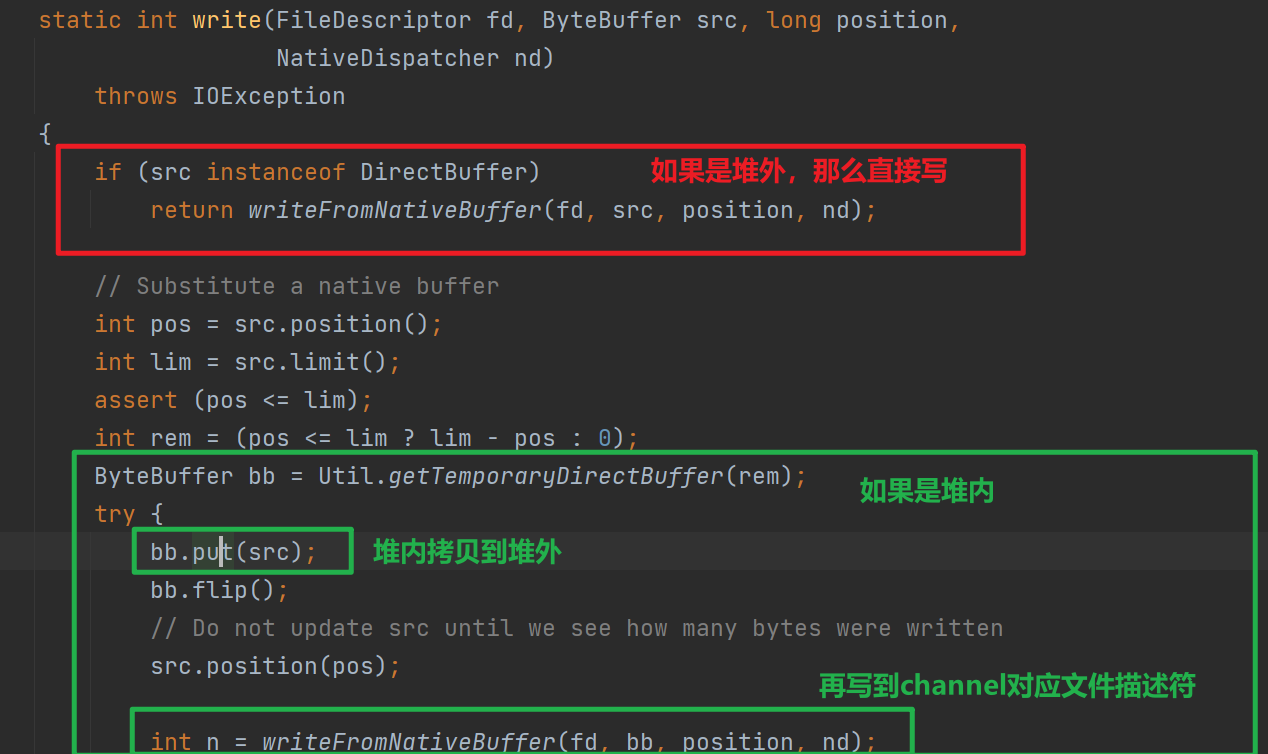
下图是将Buffer数据写入到Channel,调用IOUtil#write的源码 。
写入Buffer数据到文件描述符,or读取文件描述符数据到Buffer都是需要进行系统调用的,执行系统调用依赖于执行native方法,而执行native方法的线程被认为是处于SafePoint,处于SafePoint就有可能发生 GC 重排列对象内存的情况.
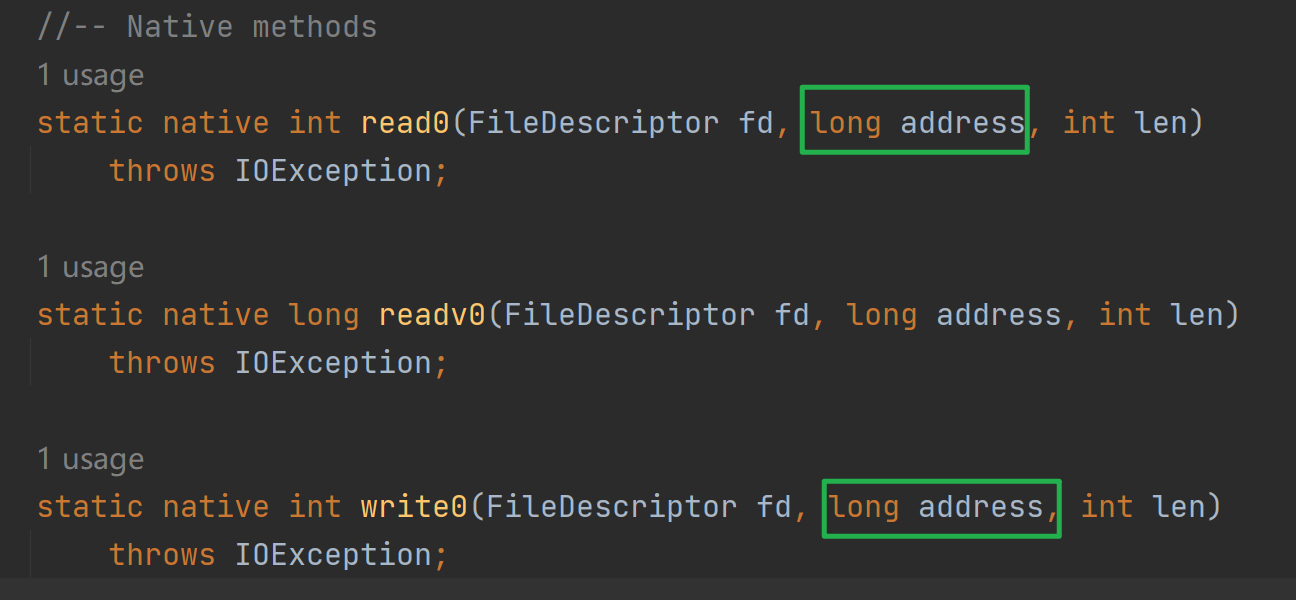
并且这个写入和读取是针对地址的(如下图,最终的native调用需要传入地址)如果写入或者读取buffer由于gc移动,那么地址会改变,但是native方法调用可不管这个,就导致读写出现错误。因此需要依赖于堆外内存.

以SokcetInputStream的读为例,读最终调用socktRead0这个native方法,入参fd是当前Socket对应的文件描述符,byte数组就是数据最终读入的目的地.
下图是native 方法socketRead0的实现 。

可以看到,其实是先将socket fd内容读取到c语言声明的数组,然后拷贝到Java byte[],这个c语言声明的数组其实作用类似于直接内存! 。
上面说了直接内存的作用:减少堆外堆内的拷贝开销。无论堆外堆内,都是用户空间的拷贝.
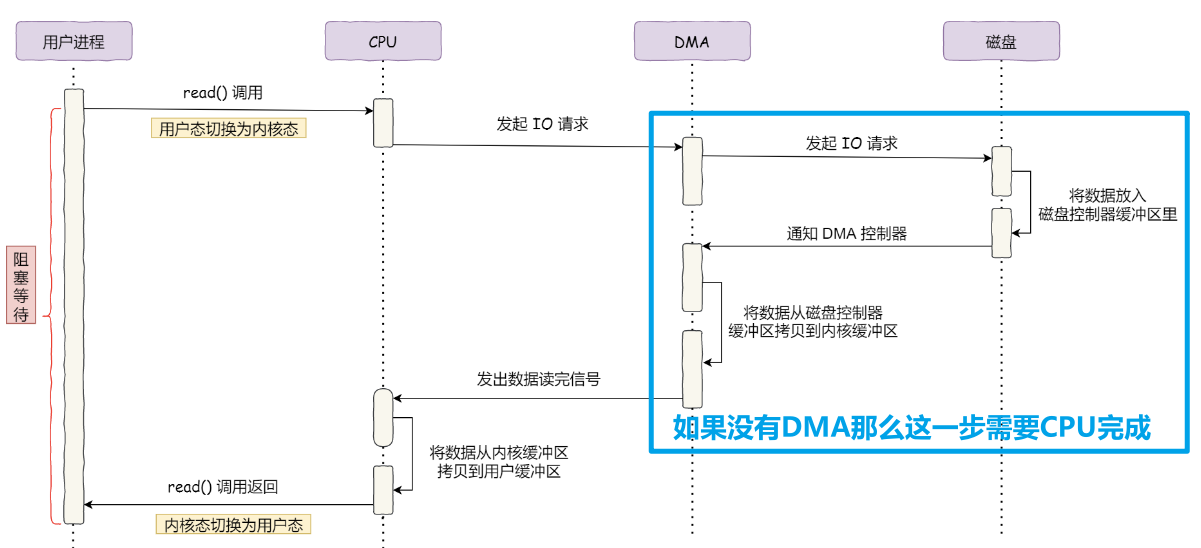
上图是读取磁盘文件的时序图,可以看到如果没有DMA技术,蓝色部分需要CPU来完成,将浪费宝贵的资源.
再DMA读取到足够数据后,会发送中断信号给CPU,让CPU将内核缓冲区数据,拷贝到用户缓冲区,随后CPU再来调度Java程序,Java程序才能操作到用户缓冲区的数据.
如下图是我们使用IO流,读取磁盘文件,通过Socket API 发送的流程,其中需要read,和 write 系统调用,每次系统调用都意味着 用户态与内核态的上下文切换 .
并且还有四次数据拷贝,其中两次由DMA负责打工,两次由CPU负责拷贝.
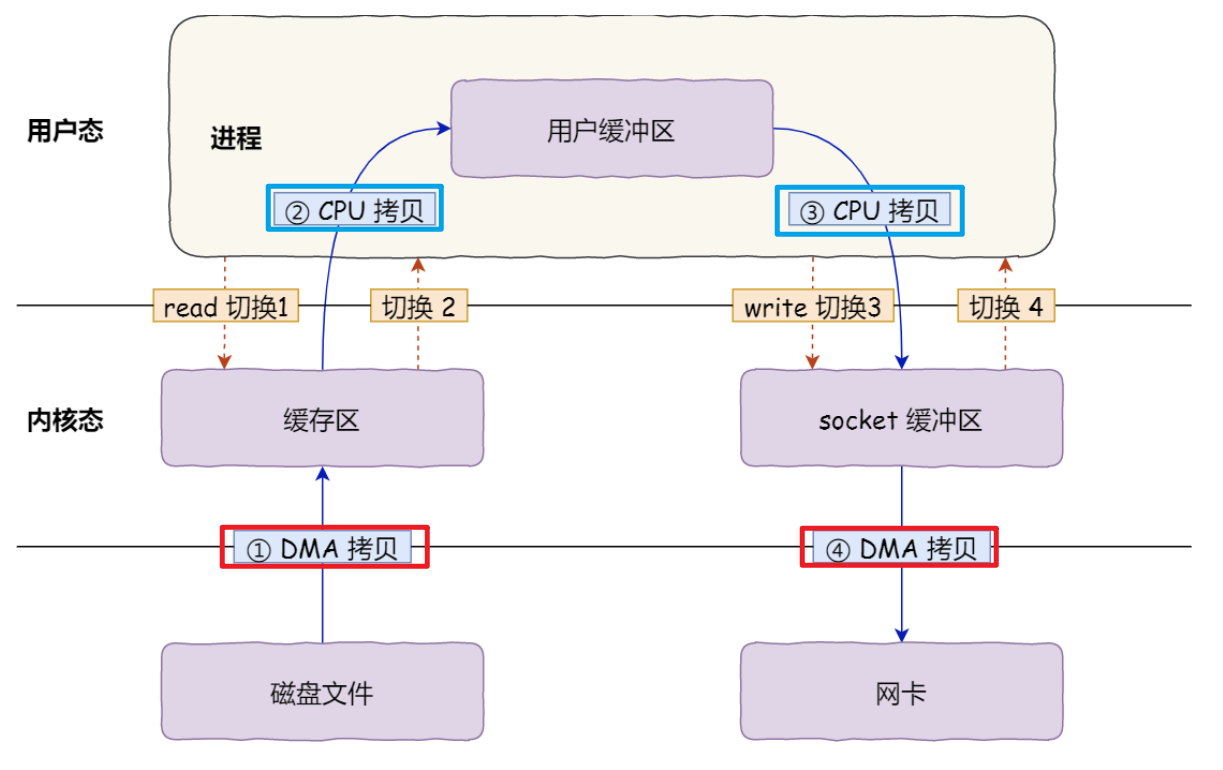
如何优化:
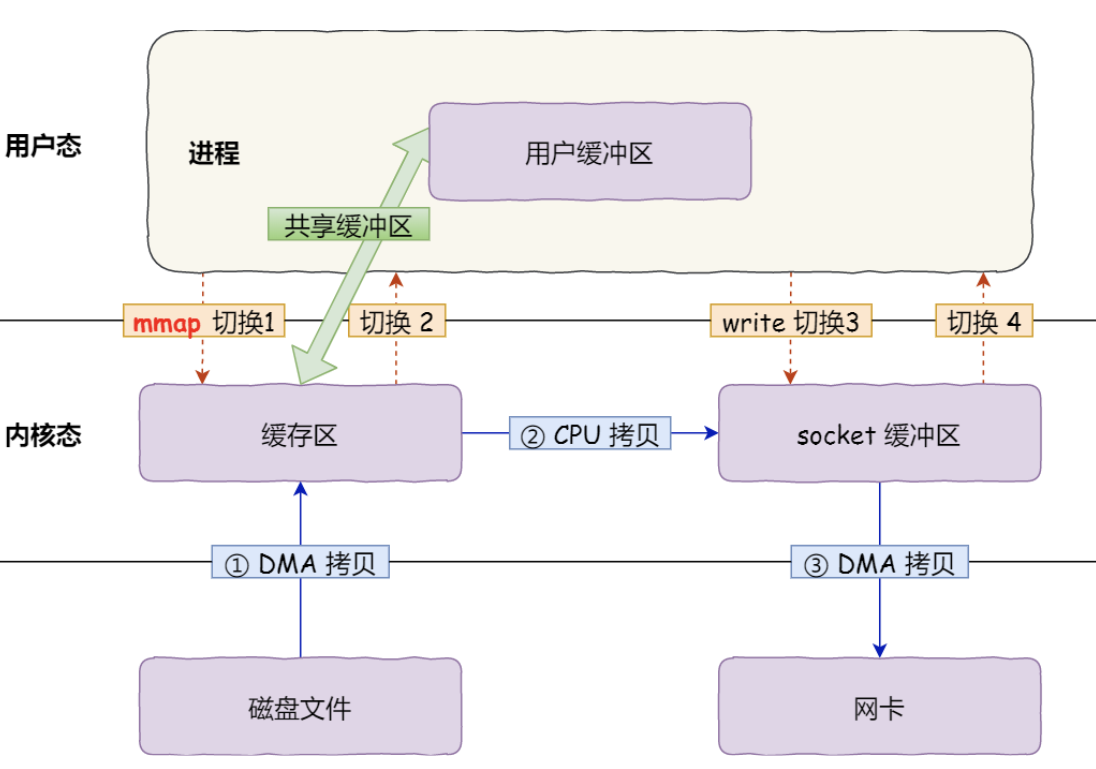
mmap() 后,DMA 会把磁盘的数据拷贝到内核的缓冲区里。接着,应用进程跟操作系统内核 共享 这个缓冲区; write() ,操作系统直接将内核缓冲区的数据拷贝到 socket 缓冲区中,这一切都发生在内核态,由 CPU 来搬运数据; 所以mmap优化了什么?
mmap并没有减少系统调用带来的内核态用户态切换开销,只是应用程序和内核共享缓冲区,从而让cpu可以直接将内核缓冲区的数据,拷贝到socket缓冲区,不需要拷贝到用户缓冲区,再从用户缓冲区拷贝到socket缓冲区.
linux 提供sendfile系统调用,只需这一个系统调用就可以从一个文件描述符拷贝数据到另外一个文件描述符 。
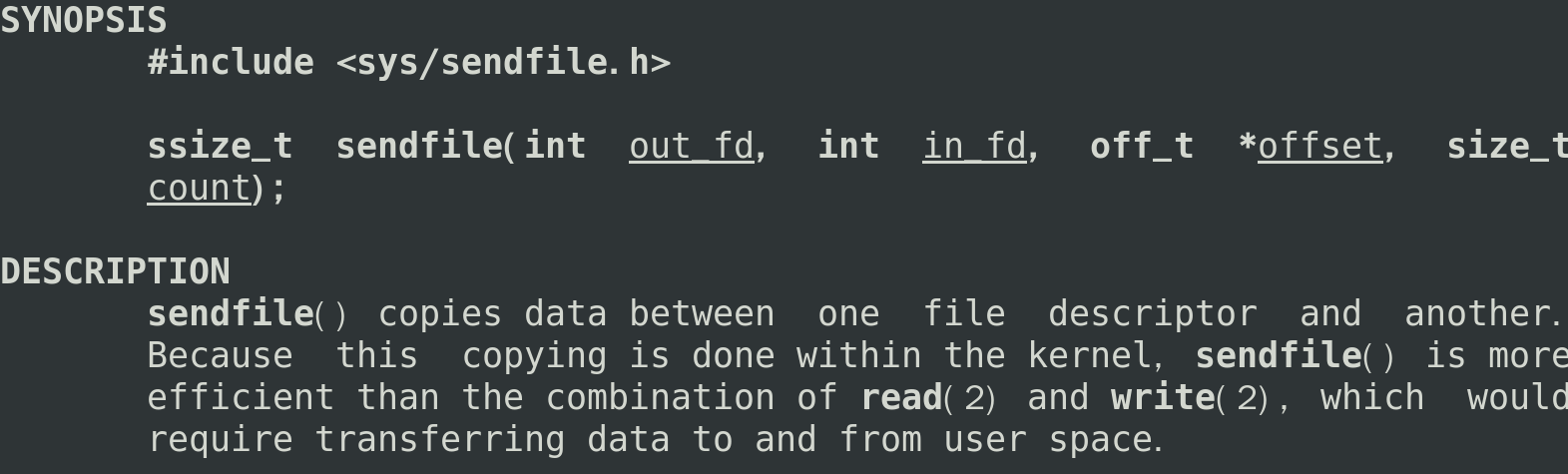
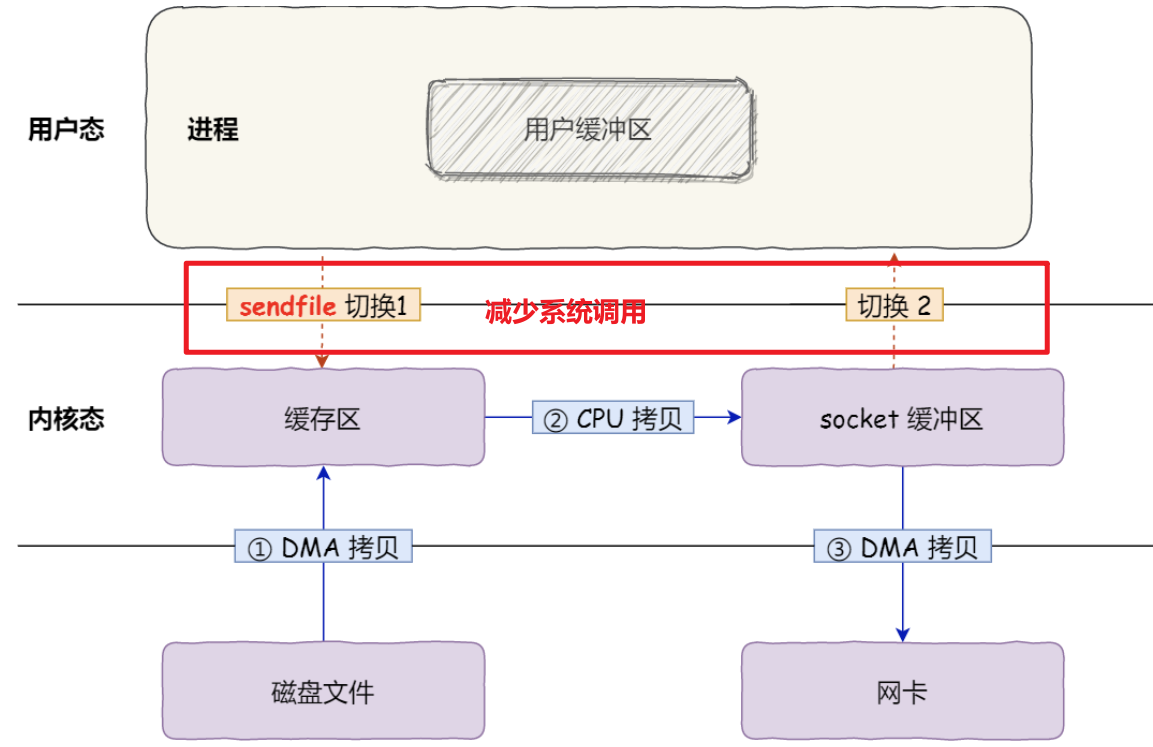
sendfile可以减少write,read导致的系统调用,从而优化效率.
如果网卡支持 SG-DMA( The Scatter-Gather Direct Memory Access )技术,那么还可以进一步优化.
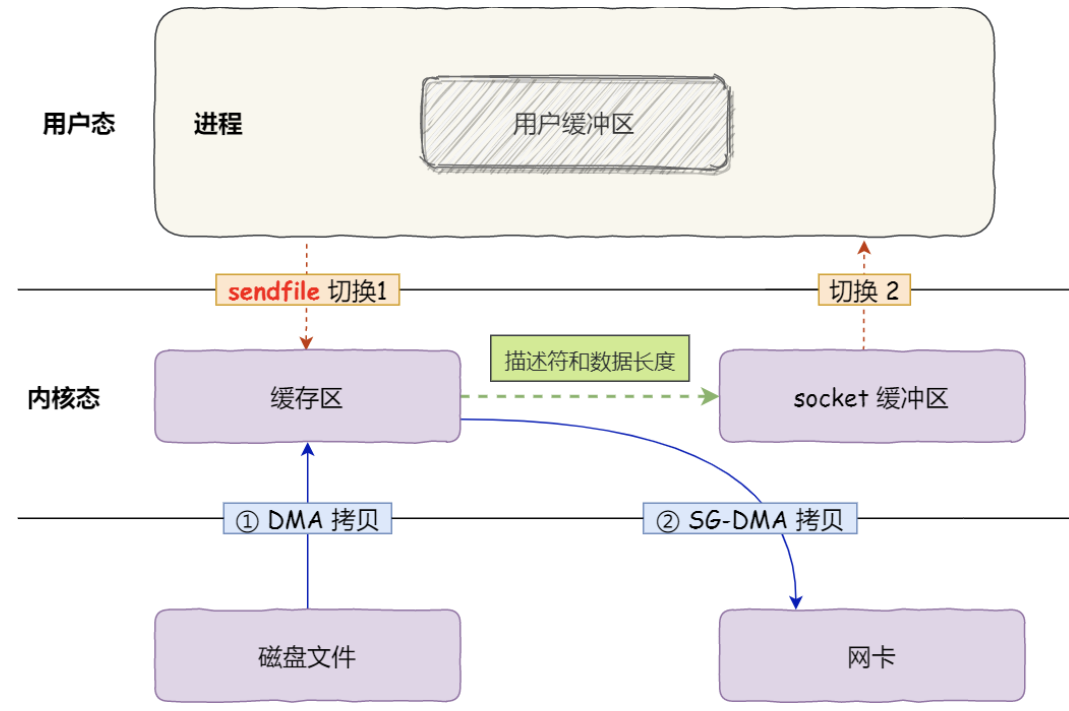
不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中 ,这样就减少了一次数据拷贝。 这便是所谓的零拷贝,减少内存层面拷贝数据的次数,以及系统调用内核态用户态的切换,从而优化性能.
NIO中的FileChannel.map()方法使用了mmap系统调用实现内存映射方式 。
将内核缓冲区的内存和用户缓冲区的内存做了一个地址映射。这种方式适合读取大文件,同时也能对文件内容进行更改,但是如果其后要通过SocketChannel发送,还是需要CPU进行数据的拷贝.
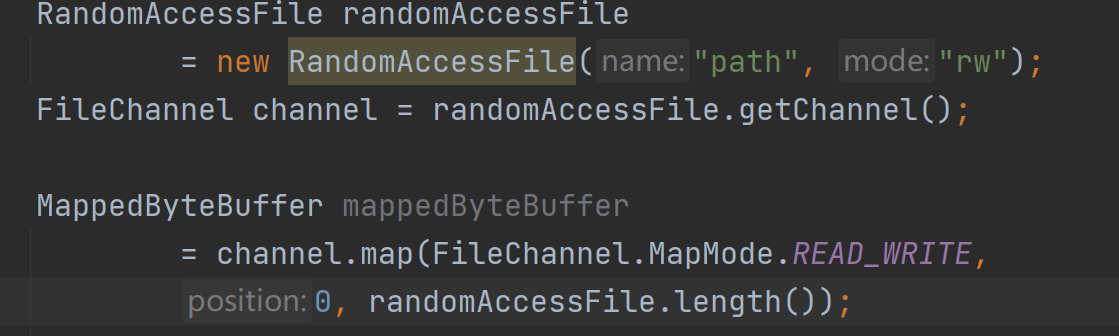
如上是MappedByteBuffer的获取方式,其实底层是通过反射调用DirectByteBuffer的构造方法实现的,其中的cleaner是直接内存的回收器,传入的unmapper会被回调,从而调用native方法实现资源释放.
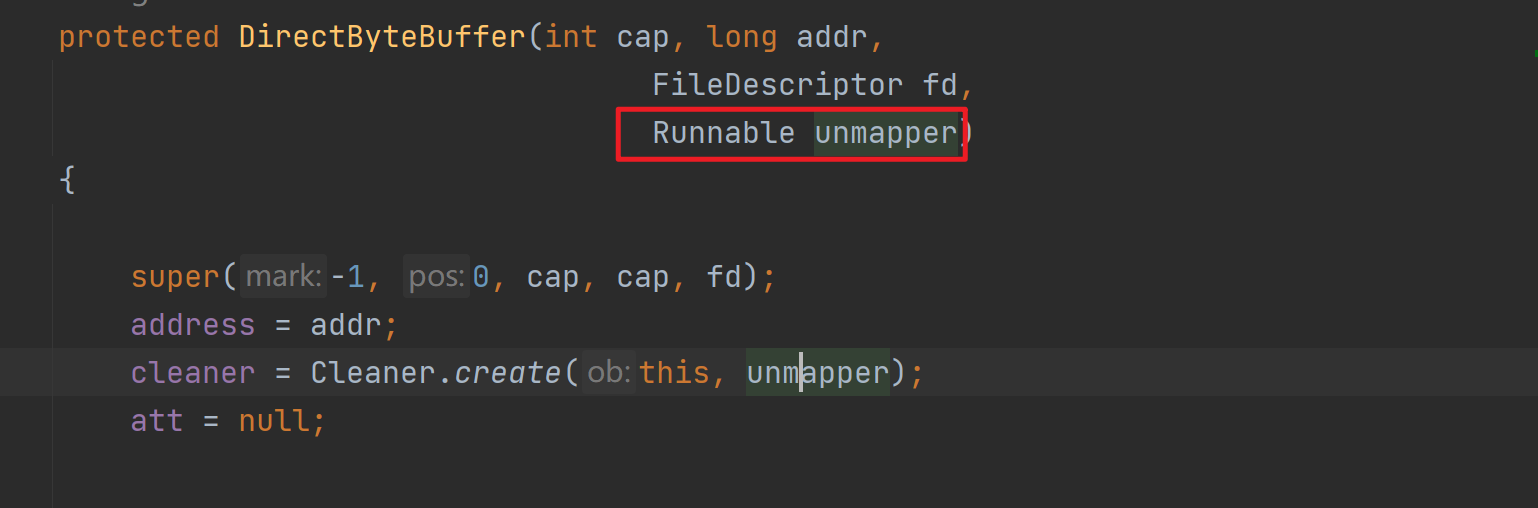
这种方式适合读取大文件,同时也能对文件内容进行更改.
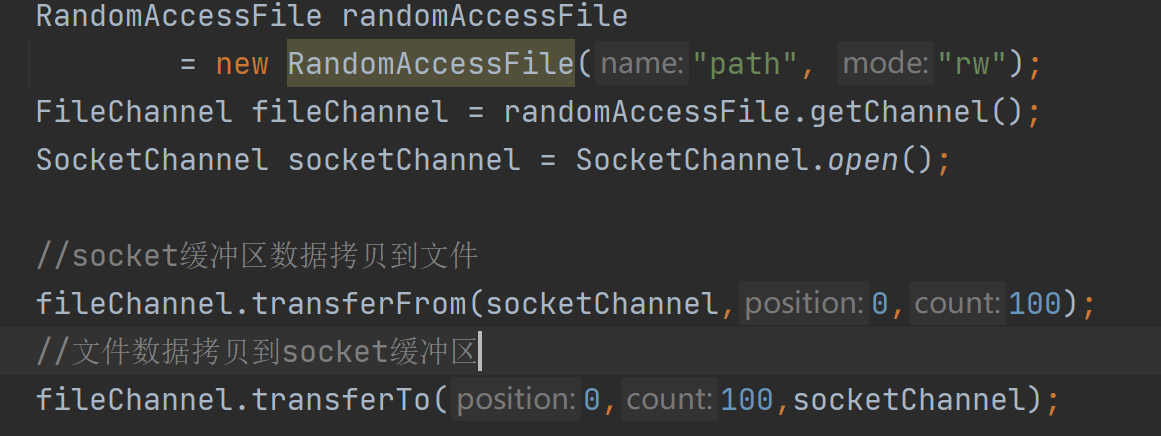
在操作系统层面是调用的一个sendFile系统调用。通过这个系统调用,可以在内核层直接完成文件内容的拷贝.
由于CPU的运行速度非常快,所以CPU在执行指令时,通常只能与缓存进行交互,而不适合直接操作像磁盘、网卡这样的硬件。也因此,在进行文件写入时,操作系统也是先写入到page cache中,缓存起来,然后再往硬件写入.
缓存有利也有弊,使用page cache页缓存,应用程序将数据都写入到了page cache中,但是却没有真正写入磁盘。如果这个时候出现断电,那么将出现缓存数据丢失.
FileChannel#force会进行fsync系统调用 。

fsync可以实现将page cache缓存内容进行落盘,从而保证不丢失(redis aof可以设置持久化机制,通常设置每秒落盘一次,这里落盘也是fsync系统调用)。为了性能考虑,应用程序不可能每写入一点数据就调用fsync,fsync也是有性能损耗的.
上面我们聊到了IO多路复用解决了什么问题,以及NIO Selector的基本使用,但是没有探究在操作系统层面是如何实现的,下面来学习一下.
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout)
select 其实就是把 NIO中用户态要遍历的fd数组拷贝到了内核态,让内核态来遍历 ,因为用户态判断socket是否有数据依旧需要通过系统调用,切换到内核态进行.
可以看到select依赖了很多位图参数,系统调用完后需要用户程序遍历一次位图才能直到哪一个fd具备了io事件,并且这个位图大小最大为1024,导致select用起来需要很多位操作并且最多只能支持1024路IO.
int poll(struct pollfd *fds, nfds_t nfds/*最大监听的文件描述符个数*/, int timeout/*最大监听的文件描述符个数*/);
其中pollfd为:
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};
poll可以看作升级版select,它突破了 1024 个文件描述符的限制,并且 poll 函数的监听和返回是分开的,简化了代码实现.
虽然 poll 不需要遍历所有的文件描述符了,只需要遍历加入数组中的描述符,范围缩小了很多,但缺点仍然是需要遍历,当加入数组描述符很多,但是存在事件的fd很少,这个遍历操作还是有点不划算的.
在linux环境下,java nio中的selector就是基于epoll实现的.
int epoll_create(int size)
//返回一个fd
//传入大小作为参考值
epoll_create返回一个特殊的文件描述符,它代表红黑树的根节点。 size 则是树的大小,它代表你将监听多少个文件描述符。 epoll_create 将按照传入的大小,构造出一棵大小为 size 的红黑树.
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// epfd 是epoll_create的返回值,也就说红黑树的根节点
// op 表示操作,比如增加,修改,删除
//fd 是需要增加,修改,删除的文件描述符
// struct epoll_event *event 是一个结构体,如下
struct epoll_event {
uint32_t events; /* Epoll events 读事件or写事件,or 异常事件*/
epoll_data_t data; /* User data variable */
};
typedef union epoll_data {
void *ptr;
int fd;//代表一个文件描述符,初始化的时候传入需要监听的文件描述符,当监听返回时,此处会传出一个有事件发生的文件描述符,因此,无需我们遍历得到结果了
uint32_t u32;
uint64_t u64;
} epoll_data_t;
用来操作 epoll 句柄,可以使用该函数往红黑树里增加文件描述符,修改文件描述符,和删除文件描述符.
int epoll_wait(int epfd, struct epoll_event *events,
int maxevents, int timeout);
//epfd 是epoll_create的返回值,也就说红黑树的根节点
// struct epoll_event *events 是一个数组,返回的所有触发了事件的文件描述符集合
//maxevents代表这个数组的大小
//timeout 0代表立即返回,-1代表永久阻塞,如果大于0,则代表超时等待毫秒数
epoll 有两种触发方式,分别为 水平触发 和 边沿触发 .
水平触发 。
只要有数据处于就绪状态,那么可读事件就会一直触发.
举个例子,假设客户端一次性发来了 4K 数据 ,但是服务器 recv 函数定义的 buffer 大小仅为 1024 字节,那么一次肯定是不能将所有数据都读取完的,这时候就会继续触发可读事件,直到所有数据都处理完成.
epoll 默认的触发方式就是水平触发.
边缘触发 。
只有数据发送过来的时候会触发一次,即使数据没有读取完,也不会继续触发.
触发方式的设置:
水平触发和边沿触发在内核里 使用两个 bit mask 区分,分别为:
需要在注册事件的时候将其与需要注册的事件做一个位或运算即可:
ev.events = EPOLLIN; //LT
ev.events = EPOLLIN | EPOLLET; //ET
select函数需要一次性传入所有需要监控的连接(在内核中是FD),并在内核中对这些FD进行持续的扫描。当发现其中有FD不老实时,就会通知应用程序有客户端事件发生了, 上层应用接到通知后,就只能自己再去遍历所有的FD,寻找有事件发生的连接,然后进行业务处理。 但是select受限于操作系统,扫描的FD个数是受限的.
于是出现了Poll函数,解决了slelect文件描述符受限的问题。但是,上层应用程序依然要自己去遍历所有客户端,寻找哪个客户端上有事件发 生。高并发场景下,性能依然严重受限。 于是又出现了epoll机制.
epoll机制会直接返回有事件发生的FD。这样就省掉了上层应用频繁扫描所有客户端的消耗,进一步解决多路复用的高并发问题.
最后此篇关于JavaNIO原理(Selector、Channel、Buffer、零拷贝、IO多路复用)的文章就讲到这里了,如果你想了解更多关于JavaNIO原理(Selector、Channel、Buffer、零拷贝、IO多路复用)的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
我有一个基类和两个派生类,我需要将一个指向派生类对象的指针复制到另一个类中,就像示例一样。 class Base { public: Base(const Base& other); } cl
考虑 Container 类,它主要存储 Box 对象的 unique_ptr vector ,并可以对它们执行一些计算。 class Container { private: std::
引用是指保存的值为对象的地址。在 Python 语言中,一个变量保存的值除了基本类型保存的是值外,其它都是引用,因此对于它们的使用就需要小心一些。下面举个例子: 问题描述:已知一个列表,求生成一个
我正在尝试实现 Bron-Kerbosch 算法,这是一种用于查找派系的递归算法。我设法达到了一个点,它返回了正确数量的派系,但是当我打印它们时,它们不正确 - 添加了额外的节点。我在这里遗漏了什么明
在评估中,我选择了选项LINE I 上的运行时错误。没有未定义行为这样的选项,尽管我认为这是正确的选择。 我不确定,但我认为评估有误。我编译并运行了该程序,它确实打印了 3, 9, 0, 2, 1,
在函数签名中通过 const 值传递参数是否有任何好处(或相反,成本)? 所以: void foo( size_t nValue ) { // ... 对比 void foo( const s
我为 answer to another question 写了一个 OutputIterator .在这里: #include using namespace std; template clas
我有一个由第三方生成的 dll,它具有某种内部数据结构,将其大小限制为 X 个元素。 所以基本上,它有一个以 X 为限制的队列。 据我所知,DLL 是每个进程的,但是是否可以多次加载 DLL?也许每个
假设我有以下两个数据结构: std::vector all_items; std::set bad_items; all_items vector 包含所有已知项和 bad_items vector
如何在不渲染 CGImage 的情况下从另一个 CIImage 复制一个 CIImage 最佳答案 CIImage *copiedImage = [originalImage copy]; 正如您在
我有一个名为 UINode 的 GUI,我想创建一个拷贝并只更改一些内容。该项目由 3 个基本线程组成。 PingThread、RosThread 和 GuiThread。我试图复制粘贴项目文件夹并将
Qt 新手。如果这个问题太幼稚,请多多包涵。在 Windows 操作系统环境中,我有 Qt 对话框框架应用程序,它具有“重复”- 按钮。在同一目录中,有 Qt 应用程序 - (一个带有关闭按钮的对话框
我正在尝试创建一个函数来复制我的卡片结构。我只需复制 cvalue 即可轻松开始。然而,我的 cvalue 没有复制,当应该读取 1000 时它仍然读取 5。 #include #include
string str1("someString"); string str2 = string(str1);//how many copies are made here //copy2 =
我希望了解 boost::bind 执行何种函数对象的内部拷贝。由于这些对象的构造函数似乎没有被调用,我推测这是一种“非常浅的复制”,所以我引入了动态内存分配来产生一些错误。但是,下面代码的运行时输出
我正在查看 http://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#c22-make-default-operations-consis
下面的类方法Augmented3dPoint::getWorldPoint()返回对其成员的引用 cv::Point3f world_point; class Augmented3dPoint { p
我需要通过 MyClass2 将用户定义的 lambda 传递给 MyClass1。我想确保只有一步,没有拷贝。下面的代码实现了吗?有没有更好的方法来做到这一点(比如使用编译器完成的隐式移动)? 注意
在我的数据库访问代码中,我想写一个方法: variant_t GetQueryRows (...) 我想这样调用它: const variant_t result = GetQueryRows (..
我有一个包含引用的类,例如: class A { A(B &b) : b(b) {} // constructor B &b; } 有时b必须是只读的,有时是可写的。当我创建一个 const A

我是一名优秀的程序员,十分优秀!