
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4


Strassen 算法是一种用于矩阵乘法的分治算法,它将原始的矩阵分解为较小的子矩阵,然后使用子矩阵相乘的结果来计算原始矩阵的乘积.
对于一个 knn 矩阵和一个 nkn 矩阵相乘,如果使用 Strassen 算法进行分解,最坏情况下需要进行 7 次矩阵乘法运算和 6 次加法运算。因此,在最坏情况下,该算法的时间复杂度为 O(n^1.44).
对于两个输入矩阵规模互换的情况,如果使用 Strassen 算法进行分解,最坏情况下需要进行 7 次矩阵乘法运算和 6 次加法运算。因此,在最坏情况下,该算法的时间复杂度也为 O(n^1.44).
需要注意的是,在实际应用中,由于 Strassen 算法需要额外进行子矩阵的分解和合并操作,因此其实际运行时间可能会比理论时间复杂度略慢一些.

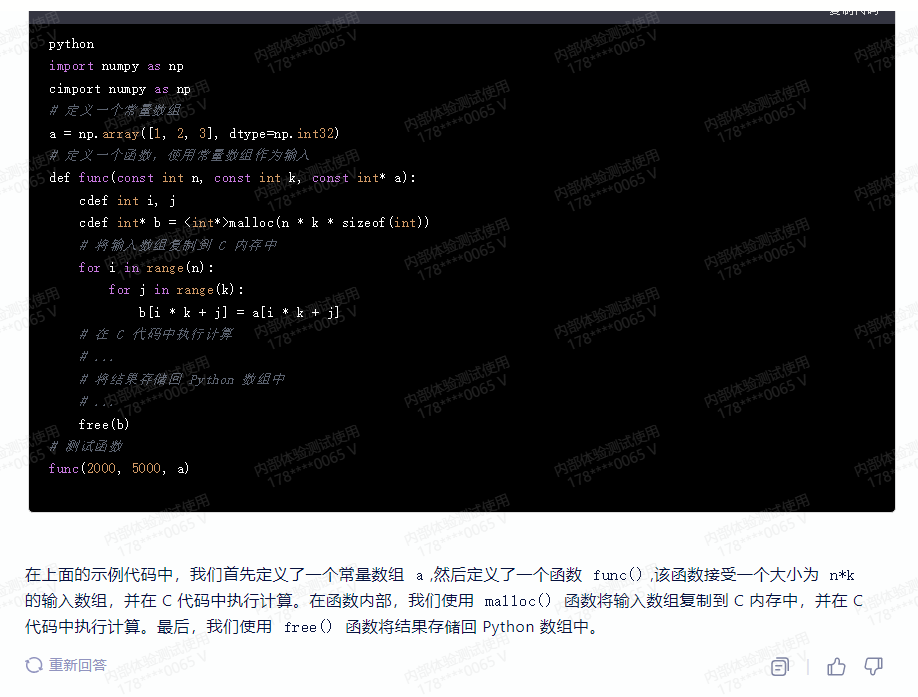
代码解决方案: Cython 是一个可以将 Python 代码转换为 C 代码的工具。通过使用 Cython,可以大大提高 Python 代码的执行速度。然而,如果在 Cython代码中使用了数组,可能会影响性能。这是因为数组是 Python 对象,而 Cython 需要将它们转换为 C 类型的数组。如果数组过大或过于复杂,可能会导致性能下降.
以下是一个可能的解决方案,可以帮助优化 Cython 代码中的数组性能:
1.避免在循环中过多使用数组。如果数组太大或过于复杂,可以考虑使用其他数据结构,例如列表或元组.
2.使用 Cython 提供的内存视图功能。内存视图是一种允许在 Cython 代码中访问 C 内存的方式。使用内存视图可以避免将大量数据复制到 Python 堆栈中,从而提高性能。但是,使用内存视图可能会导致代码更加复杂和难以理解,因此需要谨慎使用.
3.将数组声明为常量。如果数组的大小不会发生变化,可以将数组声明为常量。这样可以避免在运行时重复分配内存,从而提高性能.
下面是一个示例代码,演示了如何在 Cython 代码中优化数组性能:
python
import numpy as np
cimport numpy as np
# 定义一个常量数组
a = np.array([1, 2, 3], dtype=np.int32)
# 定义一个函数,使用常量数组作为输入
def func(const int n, const int k, const int* a):
cdef int i, j
cdef int* b = <int*>malloc(n * k * sizeof(int))
# 将输入数组复制到 C 内存中
for i in range(n):
for j in range(k):
b[i * k + j] = a[i * k + j]
# 在 C 代码中执行计算
# ...
# 将结果存储回 Python 数组中
# ...
free(b)
# 测试函数
func(2000, 5000, a)
在上面的示例代码中,我们首先定义了一个常量数组 a ,然后定义了一个函数 func() ,该函数接受一个大小为 n*k 的输入数组,并在 C 代码中执行计算。在函数内部,我们使用 malloc() 函数将输入数组复制到 C 内存中,并在 C 代码中执行计算。最后,我们使用 free() 函数将结果存储回 Python 数组中.

对于Strassen算法,在处理规模为kn*n的矩阵相乘时,可以将其转换为两个Strassen子串的乘积,然后使用Strassen算法进行相乘。具体而言,我们可以将矩阵A[i][j] = [i, j],代入矩阵B[i][j] = [i, j],然后使用Strassen算法进行相乘.
对于输入矩阵规模互换的情况,我们可以使用以下算法
1.对角线法:对于规模为knn的矩阵,我们可以先找到两个对角线,然后将它们分别乘以矩阵A和矩阵B。这样得到的矩阵相乘的结果仍然是knn的.
2.快速幂法:快速幂法则是使用矩阵A的幂值来计算矩阵B的幂值,即A^(n+k)。假设矩阵A的幂值为a,矩阵B的幂值为b,那么可以使用快速幂法则计算
a^(n+k) = b^(n+k) 。
其中n为矩阵A的行数,k为矩阵B的列数。因此,当矩阵A的行数为k时,矩阵B的列数为k,并且k为正整数.
因此,对于输入矩阵规模互换的情况,我们可以使用快速幂法则来进行计算,最快需要花费的时间取决于矩阵A和矩阵B的规模.

Strassen 算法是一种高效的矩阵乘法算法,其时间复杂度为 O(n^(3/2))。在子进程中使用 Strassen 算法进行矩阵相乘,最坏情况下需要时间复杂度为 O(n^2) 的子进程数量,即需要 n 个子进程并行计算。因此,对于规模为 kn n 和 n kn 的矩阵相乘,最坏情况下最快需要花费 O(n^2) 的时间.
当输入矩阵规模互换时,需要对 Strassen 算法进行调整,以适应新的输入规模。具体来说,需要调整算法中的系数 k 和常数 C,以适应新的输入规模。调整后的 Strassen 算法的时间复杂度为 O(n^(3/2)),仍具有很高的效率.
因此,无论输入矩阵规模如何互换,使用 Strassen 算法进行矩阵相乘最快需要花费 O(n^(3/2)) 的时间.
使用 Strassen 算法进行 kn n 矩阵和 n kn 矩阵相乘,最好的情况下时间复杂度为 O(n^log2(7)).
假设 Strassen 算法作为子进程运行,那么最快需要花费的时间取决于两个因素:
1.子进程启动和初始化所需的开销 。
2.实际计算矩阵乘积所需的时间 。
对于第一个因素,我们可以假设子进程已经启动,并已经完成了必要的初始化工作。这个开销通常很小,可以忽略不计.
对于第二个因素,我们需要考虑实际计算矩阵乘积所需的时间。根据 Strassen 算法的时间复杂度,当 n 足够大时,运行时间将接近 O(n^2.81)。因此,当规模较大时,计算矩阵乘积的时间可能会非常长.
对于两个输入矩阵规模互换的情况,计算复杂度和上述情况是相同的。因此,最快需要的时间也相同.
总之,时间复杂度为 O(n^log2(7)) 的 Strassen 算法可以在较大规模的矩阵乘法中提供比传统算法更好的性能。但是,在实际使用时,仍需要考虑子进程启动和初始化时间、系统资源限制等因素,以确定最终的计算时间.
最后此篇关于文心一言VS讯飞星火VSchatgpt(24)--算法导论4.26题的文章就讲到这里了,如果你想了解更多关于文心一言VS讯飞星火VSchatgpt(24)--算法导论4.26题的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
滑动窗口限流 滑动窗口限流是一种常用的限流算法,通过维护一个固定大小的窗口,在单位时间内允许通过的请求次数不超过设定的阈值。具体来说,滑动窗口限流算法通常包括以下几个步骤: 初始化:设置窗口
表达式求值:一个只有+,-,*,/的表达式,没有括号 一种神奇的做法:使用数组存储数字和运算符,先把优先级别高的乘法和除法计算出来,再计算加法和减法 int GetVal(string s){
【算法】前缀和 题目 先来看一道题目:(前缀和模板题) 已知一个数组A[],现在想要求出其中一些数字的和。 输入格式: 先是整数N,M,表示一共有N个数字,有M组询问 接下来有N个数,表示A[1]..
1.前序遍历 根-左-右的顺序遍历,可以使用递归 void preOrder(Node *u){ if(u==NULL)return; printf("%d ",u->val);
先看题目 物品不能分隔,必须全部取走或者留下,因此称为01背包 (只有不取和取两种状态) 看第一个样例 我们需要把4个物品装入一个容量为10的背包 我们可以简化问题,从小到大入手分析 weightva
我最近在一次采访中遇到了这个问题: 给出以下矩阵: [[ R R R R R R], [ R B B B R R], [ B R R R B B], [ R B R R R R]] 找出是否有任
我正在尝试通过 C++ 算法从我的 outlook 帐户发送一封电子邮件,该帐户已经打开并记录,但真的不知道从哪里开始(对于 outlook-c++ 集成),谷歌也没有帮我这么多。任何提示将不胜感激。
我发现自己像这样编写了一个手工制作的 while 循环: std::list foo; // In my case, map, but list is simpler auto currentPoin
我有用于检测正方形的 opencv 代码。现在我想在检测正方形后,代码运行另一个命令。 代码如下: #include "cv.h" #include "cxcore.h" #include "high
我正在尝试模拟一个 matlab 函数“imfill”来填充二进制图像(1 和 0 的二维矩阵)。 我想在矩阵中指定一个起点,并像 imfill 的 4 连接版本那样进行洪水填充。 这是否已经存在于
我正在阅读 Robert Sedgewick 的《C++ 算法》。 Basic recurrences section it was mentioned as 这种循环出现在循环输入以消除一个项目的递
我正在思考如何在我的日历中生成代表任务的数据结构(仅供我个人使用)。我有来自 DBMS 的按日期排序的任务记录,如下所示: 买牛奶(18.1.2013) 任务日期 (2013-01-15) 任务标签(
输入一个未排序的整数数组A[1..n]只有 O(d) :(d int) 计算每个元素在单次迭代中出现在列表中的次数。 map 是balanced Binary Search Tree基于确保 O(nl
我遇到了一个问题,但我仍然不知道如何解决。我想出了如何用蛮力的方式来做到这一点,但是当有成千上万的元素时它就不起作用了。 Problem: Say you are given the followin
我有一个列表列表。 L1= [[...][...][.......].......]如果我在展平列表后获取所有元素并从中提取唯一值,那么我会得到一个列表 L2。我有另一个列表 L3,它是 L2 的某个
我们得到二维矩阵数组(假设长度为 i 和宽度为 j)和整数 k我们必须找到包含这个或更大总和的最小矩形的大小F.e k=7 4 1 1 1 1 1 4 4 Anwser是2,因为4+4=8 >= 7,
我实行 3 类倒制,每周换类。顺序为早类 (m)、晚类 (n) 和下午类 (a)。我固定的订单,即它永远不会改变,即使那个星期不工作也是如此。 我创建了一个函数来获取 ISO 周数。当我给它一个日期时
假设我们有一个输入,它是一个元素列表: {a, b, c, d, e, f} 还有不同的集合,可能包含这些元素的任意组合,也可能包含不在输入列表中的其他元素: A:{e,f} B:{d,f,a} C:
我有一个子集算法,可以找到给定集合的所有子集。原始集合的问题在于它是一个不断增长的集合,如果向其中添加元素,我需要再次重新计算它的子集。 有没有一种方法可以优化子集算法,该算法可以从最后一个计算点重新
我有一个包含 100 万个符号及其预期频率的表格。 我想通过为每个符号分配一个唯一(且前缀唯一)的可变长度位串来压缩这些符号的序列,然后将它们连接在一起以表示序列。 我想分配这些位串,以使编码序列的预

我是一名优秀的程序员,十分优秀!