
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


分布式机器学习中,参数服务器(Parameter Server)用于管理和共享模型参数,其基本思想是将模型参数存储在一个或多个中央服务器上,并通过网络将这些参数共享给参与训练的各个计算节点。每个计算节点可以从参数服务器中获取当前模型参数,并将计算结果返回给参数服务器进行更新.
为了保持模型一致性,通常采用下列两种方法:
在该架构中,包含两个角色:parameter server和worker 。
parameter server将被视为master节点在Master/Worker架构,而worker将充当计算节点负责模型训练 。
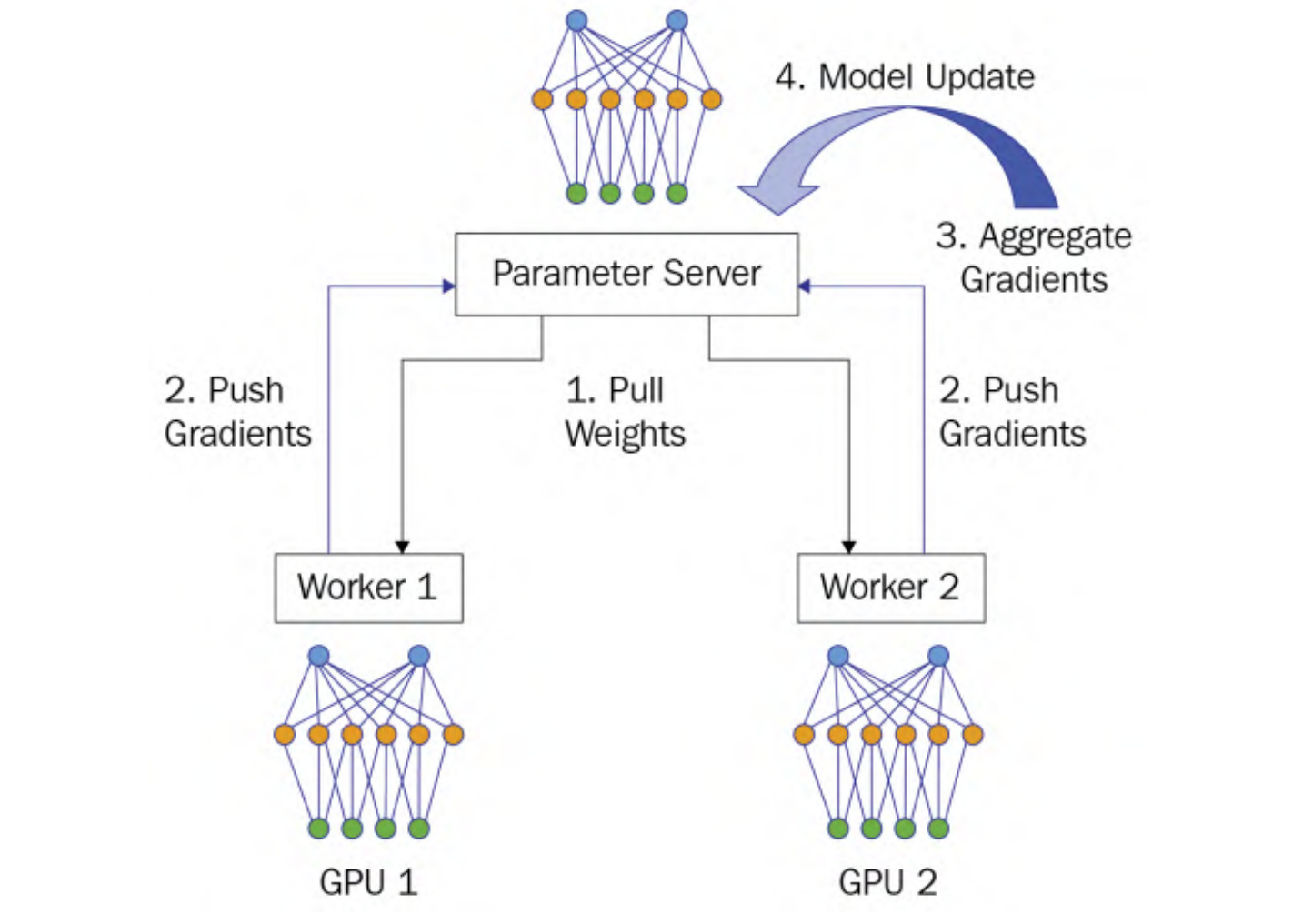
整个系统的工作流程分为4个阶段:
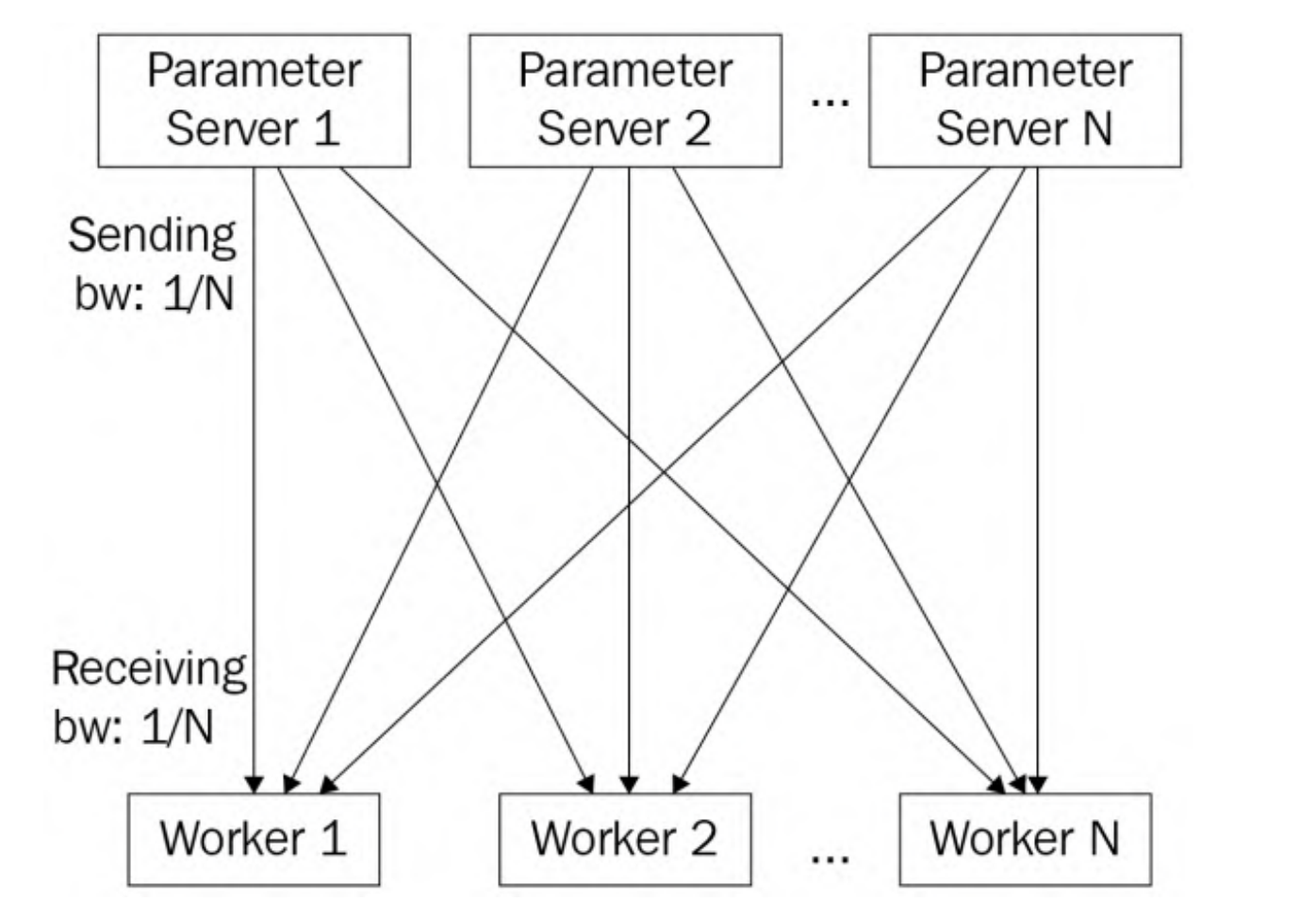
可见,上述的Pull Weights和Push Gradients涉及到通信,首先对于Pull Weights来说,参数服务器同时向worker发送权重,这是一对多的通信模式,称为fan-out通信模式。假设每个节点(参数服务器和工作节点)的通信带宽都为1。假设在这个数据并行训练作业中有N个工作节点,由于集中式参数服务器需要同时将模型发送给N个工作节点,因此每个工作节点的发送带宽(BW)仅为1/N。另一方面,每个工作节点的接收带宽为1,远大于参数服务器的发送带宽1/N。因此,在拉取权重阶段,参数服务器端存在通信瓶颈.
对于Push Gradients来说,所有的worker并发地发送梯度给参数服务器,称为fan-in通信模式,参数服务器同样存在通信瓶颈.
基于上述讨论,通信瓶颈总是发生在参数服务器端,将通过负载均衡解决这个问题 。
将模型划分为N个参数服务器,每个参数服务器负责更新1/N的模型参数。实际上是将模型参数分片(sharded model)并存储在多个参数服务器上,可以缓解参数服务器一侧的网络瓶颈问题,使得参数服务器之间的通信负载减少,提高整体的通信效率.
定义网络结构:
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
if torch.cuda.is_available():
device = torch.device("cuda:0")
else:
device = torch.device("cpu")
self.conv1 = nn.Conv2d(1,32,3,1).to(device)
self.dropout1 = nn.Dropout2d(0.5).to(device)
self.conv2 = nn.Conv2d(32,64,3,1).to(device)
self.dropout2 = nn.Dropout2d(0.75).to(device)
self.fc1 = nn.Linear(9216,128).to(device)
self.fc2 = nn.Linear(128,20).to(device)
self.fc3 = nn.Linear(20,10).to(device)
def forward(self,x):
x = self.conv1(x)
x = self.dropout1(x)
x = F.relu(x)
x = self.conv2(x)
x = self.dropout2(x)
x = F.max_pool2d(x,2)
x = torch.flatten(x,1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
x = self.fc3(x)
output = F.log_softmax(x,dim=1)
return output
如上定义了一个简单的CNN 。
实现参数服务器:
class ParamServer(nn.Module):
def __init__(self):
super().__init__()
self.model = Net()
if torch.cuda.is_available():
self.input_device = torch.device("cuda:0")
else:
self.input_device = torch.device("cpu")
self.optimizer = optim.SGD(self.model.parameters(),lr=0.5)
def get_weights(self):
return self.model.state_dict()
def update_model(self,grads):
for para,grad in zip(self.model.parameters(),grads):
para.grad = grad
self.optimizer.step()
self.optimizer.zero_grad()
get_weights获取权重参数,update_model更新模型,采用SGD优化器 。
实现worker
class Worker(nn.Module):
def __init__(self):
super().__init__()
self.model = Net()
if torch.cuda.is_available():
self.input_device = torch.device("cuda:0")
else:
self.input_device = torch.device("cpu")
def pull_weights(self,model_params):
self.model.load_state_dict(model_params)
def push_gradients(self,batch_idx,data,target):
data,target = data.to(self.input_device),target.to(self.input_device)
output = self.model(data)
data.requires_grad = True
loss = F.nll_loss(output,target)
loss.backward()
grads = []
for layer in self.parameters():
grad = layer.grad
grads.append(grad)
print(f"batch {batch_idx} training :: loss {loss.item()}")
return grads
Pull_weights获取模型参数,push_gradients上传梯度 。
训练数据集为MNIST 。
import torch
from torchvision import datasets,transforms
from network import Net
from worker import *
from server import *
train_loader = torch.utils.data.DataLoader(datasets.MNIST('./mnist_data', download=True, train=True,
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))])),
batch_size=128, shuffle=True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST('./mnist_data', download=True, train=False,
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))])),
batch_size=128, shuffle=True)
def main():
server = ParamServer()
worker = Worker()
for batch_idx, (data,target) in enumerate(train_loader):
params = server.get_weights()
worker.pull_weights(params)
grads = worker.push_gradients(batch_idx,data,target)
server.update_model(grads)
print("Done Training")
if __name__ == "__main__":
main()
最后此篇关于分布式机器学习(ParameterServer)的文章就讲到这里了,如果你想了解更多关于分布式机器学习(ParameterServer)的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
PyCaret是一个开源、低代码Python机器学习库,能够自动化机器学习工作流程。它是一个端到端的机器学习和模型管理工具,极大地加快了实验周期,提高了工作效率。PyCaret本质上是围绕几个机器学习
在我的研究进展中,我现在已经将寄生虫从图像中分离出来。寄生虫看起来像蠕虫。我希望 MATLAB 读取所有输入图像,查找类似深紫色图像的蠕虫,如果检测到,则给出检测到的答复。我尝试使用直方图比较,但我认
目前我正在尝试了解机器学习算法的工作方式,但我没有真正了解的一件事是预测标签的计算准确度与视觉混淆矩阵之间的明显差异。我会尽量解释清楚。 这是数据集的片段(这里你可以看到 9 个样本(在真实数据集中大
第一章 绪论 机器学习 : 致力于研究如何通过计算的手段,利用经验来改善系统自身的性能。在计算机系统中, “经验” 通常以“数据“形式存在,因此,机器学习所研究的主要内容,是关于在计算
1. 算法原理(K-Nearest Neighbor) 本质是通过距离判断两个样本是否相似,如果距离够近就认为他们足够相似属于同一类别 找到离其最近的 k 个样本,并将这些样本称
前言 K-means是一种经典的无监督学习算法,用于对数据进行聚类。K-means算法将数据集视为具有n个特征的n维空间,并尝试通过最小化簇内平方误差的总和来将数据点划分为簇。本文将介绍K-m
目录 前言 介绍LightGBM LightGBM的背景和起源 L
前言 可以说掌握了机器学习,你就具备了与机器对话,充分利用机器为人类服务的能力。在人工智能时代,这将成为一项必备技能,就好比十年前你是编程大牛,二十年前你英语超好一样。因此,无论你是什么专业的
几个贯穿始终的概念 当我们把人类学习简单事物的过程抽象为几个阶段,再将这些阶段通过不同的方法具体化为代码,依靠通过计算机的基础能力-- 计算 。我们就可以让机器能够“学会”一些简单的事物。
1、选题背景 人脸识别技术是模式识别和计算机视觉领域最富挑战性的研究课题之一,也是近年来的研究热点,人脸性别识别作为人脸识别技术
每当我们在公有云或者私有云发布训练好的大数据模型,为了方便大家辨识、理解和运用,参照huggingface所制定的标准制作一个Model Card展示页,是种非常好的模型展示和组织形式。 下面就是一
2. 支持向量机 对偶优化 拉格朗日乘数法可用于解决带条件优化问题,其基本形式为: \[\begin{gather} \min_w f(w),\\ \mathrm{s.t.} \quad
我正在尝试运行以下代码: https://github.com/opencv/opencv/blob/master/samples/dnn/classification.cpp 我在这里找到所有经过预
我是机器学习新手。当我使用 scikit-learn 模块中的波士顿数据集练习具有默认参数的决策树回归模型时。 在此链接解决方案( How to Build a Decision tree Regre
我有用于训练的数据。当我将其输入神经网络时,该数据出现 3% 的错误。 我知道这些数据有一定的过度代表性 - 例如,第 5 类的示例大约是其他类的十分之一。 我的作业指出,我可以通过偏置训练数据(即删
我在 Python 的多类分类中使用 SVM 时遇到问题。事实上,问题在于性别分类(来自图像),其中训练数据集仅包含“y=1”或“ y=-1”作为类标签(二进制)。但是,在预测中,如果是男性,我必须预
以防万一你们不知道,对抗性图像是属于某个类别的图像,但随后被扭曲,而人眼没有任何视觉感知差异,但网络错误地将其识别为完全不同的类别。 有关此内容的更多信息,请参见此处: http://karpathy
我正在进行一个 ML 语言识别项目 (Python),该项目需要具有高维特征输入的多类分类模型。 目前,我所能做的就是通过反复试验来提高准确性。无意识地结合可用的特征提取算法和可用的机器学习模型,看看
import numpy as np def sigmoid(x): return 1.0/(1+np.asmatrix(np.exp(-x))) def graD(X,y,alpha,s0,
所以我有多个列表: ['disney','england','france'] ['disney','japan'] ['england', 'london'] ['disney', 'france'

我是一名优秀的程序员,十分优秀!