
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4


不仅要解决定位问题,还要解决目标分类问题,给定图像或者视频,找出目标的位置(box),并给出目标的类别; 。

给定输入图像或者视频,找出文本的区域,可以是单字符位置或者整个文本行位置; 。


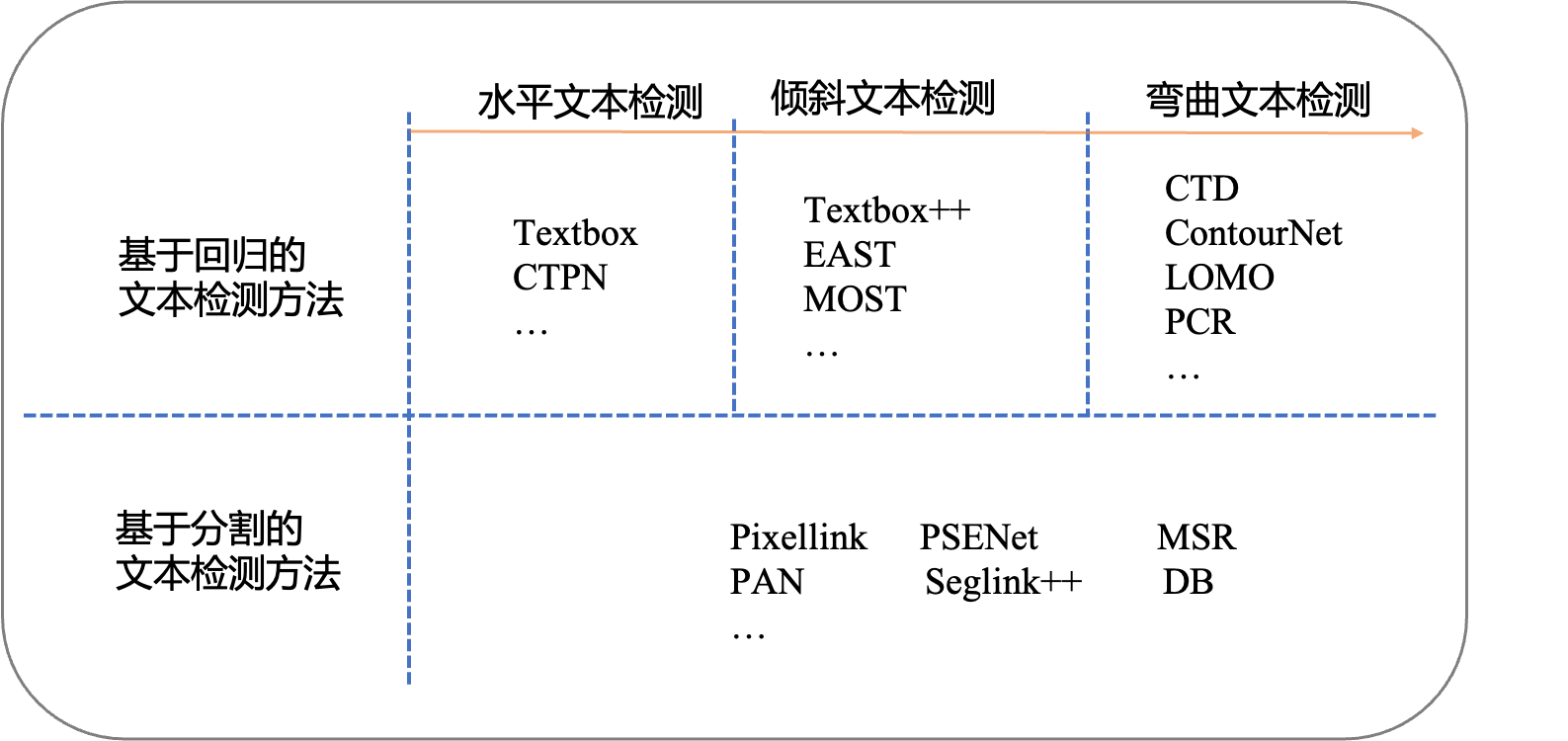
目前较为流行的文本检测算法可以大致分为 基于回归 和 基于分割 的两大类文本检测算法 。
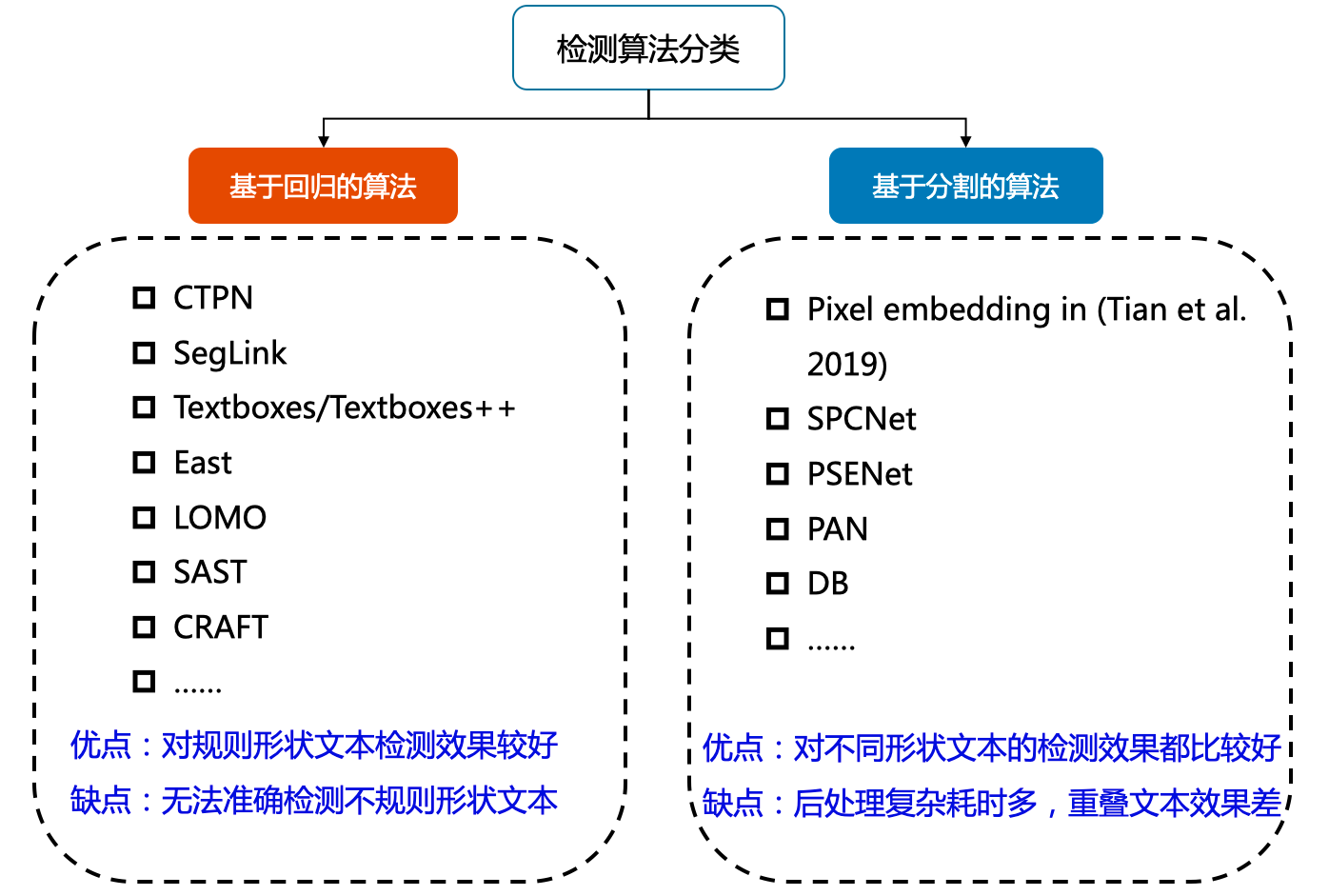
基于回归文本检测方法和目标检测算法的方法相似,文本检测方法只有两个类别,图像中的文本视为待检测的目标,其余部分视为背景.
早期基于深度学习的文本检测算法是从目标检测的方法改进而来,支持水平文本检测。比如Textbox算法基于SSD (Single Shot MultiBox Detector)算法改进而来,CTPN (connection text proposal network)根据二阶段目标检测Fast-RCNN算法改进而来.
TextBoxes 算法根据一阶段目标检测器SSD调整,将默认文本框更改为适应文本方向和宽高比的规格的四边形,提供了一种端对端训练的文字检测方法,并且无需复杂的后处理.
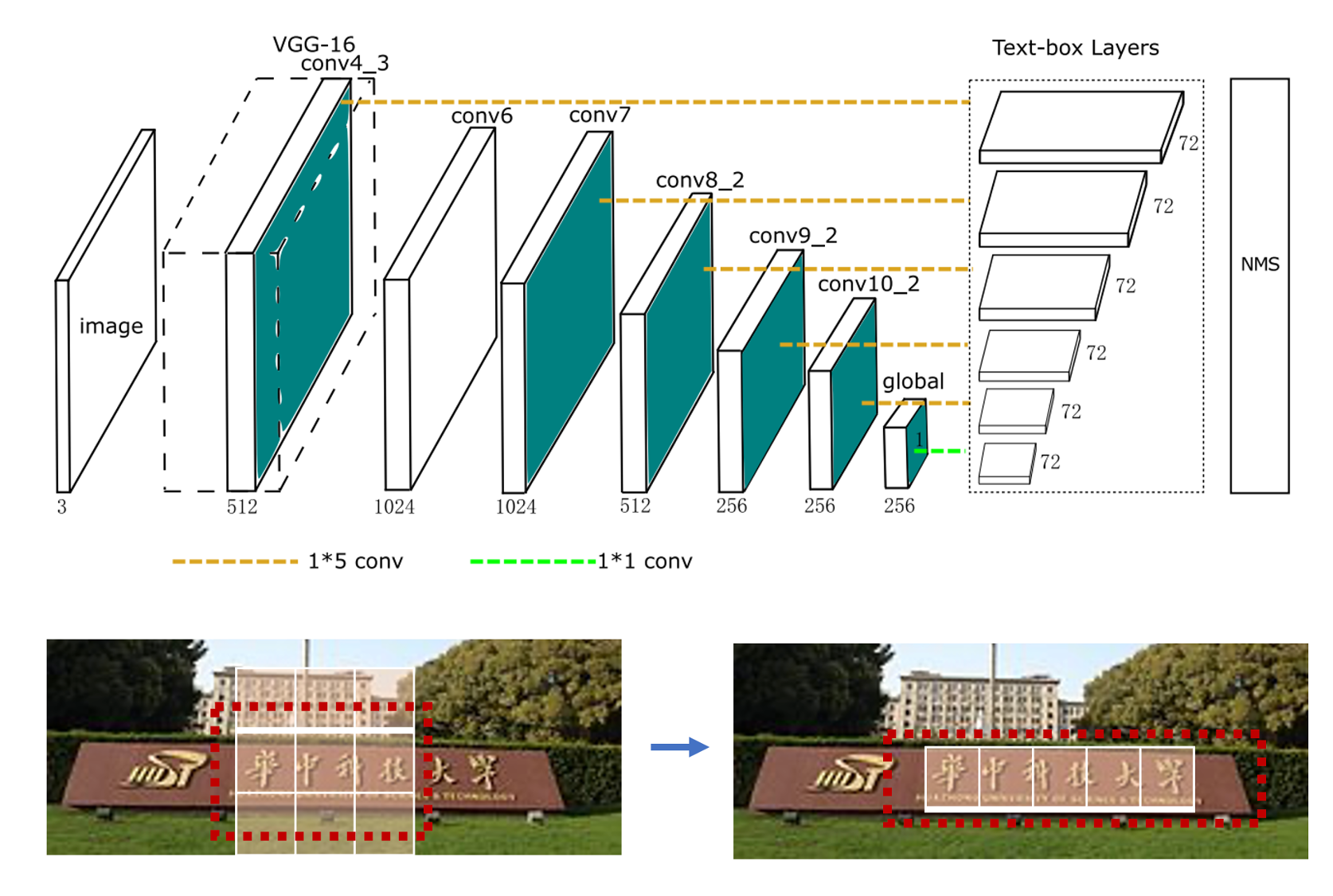
CTPN 基于Fast-RCNN 算法,扩展RPN模块并且设计了基于CRNN的模块让整个网络从卷积特征中检测到文本序列,二阶段的方法通过ROI Pooling获得了更准确的特征定位。 但是TextBoxes和CTPN只支持检测横向文本.
TextBoxes++ 在TextBoxes基础上进行改进,支持检测任意角度的文本。从结构上来说,不同于TextBoxes,TextBoxes++针对多角度文本进行检测,首先修改预选框的宽高比,调整宽高比aspect ratio为1、2、3、5、1/2、1/3、1/5。其次是将 \(1∗5\) 的卷积核改为 \(3∗5\) ,更好的学习倾斜文本的特征;最后,TextBoxes++ 的输出旋转框的表示信息.
EAST 针对倾斜文本的定位问题,提出了two-stage的文本检测方法,包含 FCN特征提取和NMS部分。EAST提出了一种新的文本检测pipline结构,可以端对端训练并且支持检测任意朝向的文本,并且具有结构简单,性能高的特点。FCN支持输出倾斜的矩形框和水平框,可以自由选择输出格式.
考虑到FCN输出的文本框是比较冗余的,比如一个文本区域的邻近的像素生成的框重合度较高,但不是同一个文本生成的检测框,重合度都很小,因此EAST提出先按行合并预测框,最后再把剩下的四边形用原始的NMS筛选.
MOST 提出TFAM模块动态的调整粗粒度的检测结果的感受野,另外提出PA-NMS根据位置信息合并可靠的检测预测结果。此外,训练中还提出 Instance-wise IoU 损失函数,用于平衡训练,以处理不同尺度的文本实例。该方法可以和EAST方法结合,在检测极端长宽比和不同尺度的文本有更好的检测效果和性能.
利用回归的方法解决弯曲文本的检测问题,一个简单的思路是用多点坐标描述弯曲文本的边界多边形,然后直接预测多边形的顶点坐标 CTD 提出了直接预测弯曲文本14个顶点的边界多边形,网络中利用Bi-LSTM 层以细化顶点的预测坐标,实现了基于回归方法的弯曲文本检测.
LOMO 针对长文本和弯曲文本问题,提出迭代的优化文本定位特征获取更精细的文本定位,该方法包括三个部分,坐标回归模块DR,迭代优化模块IRM以及任意形状表达模块SEM。分别用于生成文本大致区域,迭代优化文本定位特征,预测文本区域、文本中心线以及文本边界。迭代的优化文本特征可以更好的解决长文本定位问题以及获得更精确的文本区域定位.
Contournet 基于提出对文本轮廓点建模获取弯曲文本检测框,该方法首先使用Adaptive-RPN获取文本区域的proposal特征,然后设计了局部正交纹理感知LOTM模块学习水平与竖直方向的纹理特征,并用轮廓点表示,最后,通过同时考虑两个正交方向上的特征响应,利用Point Re-Scoring算法可以有效地滤除强单向或弱正交激活的预测,最终文本轮廓可以用一组高质量的轮廓点表示出来.
PCR 提出渐进式的坐标回归处理弯曲文本检测问题,总体分为三个阶段,首先大致检测到文本区域,获得文本框,另外通过所设计的Contour Localization Mechanism预测文本最小包围框的角点坐标,然后通过叠加多个CLM模块和RCLM模块预测得到弯曲文本。该方法利用文本轮廓信息聚合得到丰富的文本轮廓特征表示,不仅能抑制冗余的噪声点对坐标回归的影响,还能更精确的定位文本区域.
基于回归的方法虽然在文本检测上取得了很好的效果,但是对解决弯曲文本往往难以得到平滑的文本包围曲线,并且模型较为复杂不具备性能优势。于是研究者们提出了基于图像分割的文本分割方法,先从像素层面做分类,判别每一个像素点是否属于一个文本目标,得到文本区域的概率图,通过后处理方式得到文本分割区域的包围曲线。 此类方法通常是基于分割的方法实现文本检测,基于分割的方法对不规则形状的文本检测有着天然的优势。基于分割的文本检测方法主体思想为,通过分割方法得到图像中文本区域,再利用opencv,polygon等后处理得到文本区域的最小包围曲线.
Pixellink采用分割的方法解决文本检测问题,分割对象为文本区域,将同属于一个文本行(单词)中的像素链接在一起来分割文本,直接从分割结果中提取文本边界框,无需位置回归就能达到基于回归的文本检测的效果。但是基于分割的方法存在一个问题,对于位置相近的文本,文本分割区域容易出现“粘连“问题。Wu, Yue等人提出分割文本的同时,学习文本的边界位置,用于更好的区分文本区域。另外Tian等人提出将同一文本的像素映射到映射空间,在映射空间中令统一文本的映射向量距离相近,不同文本的映射向量距离变远.
MSR 针对文本检测的多尺度问题,提出提取相同图像的多个scale的特征,然后将这些特征融合并上采样到原图尺寸,网络最后预测文本中心区域、文本中心区域每个点到最近的边界点的x坐标偏移和y坐标偏移,最终可以得到文本区域的轮廓坐标集合.
针对基于分割的文本算法难以区分相邻文本的问题,PSENet 提出渐进式的尺度扩张网络学习文本分割区域,预测不同收缩比例的文本区域,并逐个扩大检测到的文本区域,该方法本质上是边界学习方法的变体,可以有效解决任意形状相邻文本的检测问题。 假设用了PSENet后处理用了3个不同尺度的kernel,如上图s1,s2,s3所示。首先,从最小kernel s1开始,计算文本分割区域的连通域,得到(b),然后,对连通域沿着上下左右做尺度扩张,对于扩张区域属于s2但不属于s1的像素,进行归类,遇到冲突点时,采用“先到先得”原则,重复尺度扩张的操作,最终可以得到不同文本行的独立的分割区域.
Seglink++ 针对弯曲文本和密集文本问题,提出了一种文本块单元之间的吸引关系和排斥关系的表征,然后设计了一种最小生成树算法进行单元组合得到最终的文本检测框,并提出instance-aware 损失函数使Seglink++方法可以端对端训练.
虽然分割方法解决了弯曲文本的检测问题,但是复杂的后处理逻辑以及预测速度也是需要优化的目标。 PAN 针对文本检测预测速度慢的问题,从网络设计和后处理方面进行改进,提升算法性能。首先,PAN使用了轻量级的ResNet18作为Backbone,另外设计了轻量级的特征增强模块FPEM和特征融合模块FFM增强Backbone提取的特征。在后处理方面,采用像素聚类方法,沿着预测的文本中心(kernel)四周合并与kernel的距离小于阈值d的像素。PAN保证高精度的同时具有更快的预测速度.
DBNet 针对基于分割的方法需要使用阈值进行 二值化 处理而导致后处理耗时的问题,提出了可学习阈值并巧妙地设计了一个近似于阶跃函数的二值化函数,使得分割网络在训练的时候能端对端的学习文本分割的阈值。自动调节阈值不仅带来精度的提升,同时简化了后处理,提高了文本检测的性能.
FCENet 提出将文本包围曲线用傅立叶变换的参数表示,由于傅里叶系数表示在理论上可以拟合任意的封闭曲线,通过设计合适的模型预测基于傅里叶变换的任意形状文本包围框表示,从而实现了自然场景文本检测中对于高度弯曲文本实例的检测精度的提升.
# 1. 从paddleocr中import PaddleOCR类
from paddleocr import PaddleOCR
import numpy as np
import cv2
import matplotlib.pyplot as plt
# 2. 声明PaddleOCR类
ocr = PaddleOCR()
img_path = './PaddleOCR/doc/imgs/12.jpg'
# 3. 执行预测
result = ocr.ocr(img_path, rec=False)
print(f"The predicted text box of {img_path} are follows.")
print(result)
# 4. 可视化检测结果
image = cv2.imread(img_path)
boxes = [line[0] for line in result]
for box in result:
box = np.reshape(np.array(box), [-1, 1, 2]).astype(np.int64)
image = cv2.polylines(np.array(image), [box], True, (255, 0, 0), 2)
# 画出读取的图片
plt.figure(figsize=(10, 10))
plt.imshow(image)
DB文本检测模型可以分为三个部分:
# 首次运行需要打开下一行的注释,下载PaddleOCR代码
#!git clone https://gitee.com/paddlepaddle/PaddleOCR
# 安装PaddleOCR第三方依赖
!pip install --upgrade pip
!pip install -r requirements.txt
DB文本检测网络的Backbone部分采用的是图像分类网络,论文中使用了ResNet50 。
import os
# 加快训练速度,采用MobileNetV3 large结构作为backbone。
from ppocr.modeling.backbones.det_mobilenet_v3 import MobileNetV3
import paddle
fake_inputs = paddle.randn([1, 3, 640, 640], dtype="float32")
# 1. 声明Backbone
model_backbone = MobileNetV3()
model_backbone.eval()
# 2. 执行预测
outs = model_backbone(fake_inputs)
# 3. 打印网络结构
print(model_backbone)
# 4. 打印输出特征形状
for idx, out in enumerate(outs):
print("The index is ", idx, "and the shape of output is ", out.shape)
特征金字塔结构FPN是一种卷积网络来高效提取图片中各维度特征的常用方法。 FPN网络的输入为Backbone部分的输出,输出特征图的高度和宽度为原图的四分之一,假设输入图像的形状为[1, 3, 640, 640],FPN输出特征的高度和宽度为[160, 160] 。
import paddle
# 1. 从PaddleOCR中import DBFPN
from ppocr.modeling.necks.db_fpn import DBFPN
# 2. 获得Backbone网络输出结果
fake_inputs = paddle.randn([1, 3, 640, 640], dtype="float32")
model_backbone = MobileNetV3()
in_channles = model_backbone.out_channels
# 3. 声明FPN网络
model_fpn = DBFPN(in_channels=in_channles, out_channels=256)
# 4. 打印FPN网络
print(model_fpn)
# 5. 计算得到FPN结果输出
outs = model_backbone(fake_inputs)
fpn_outs = model_fpn(outs)
# 6. 打印FPN输出特征形状
print(f"The shape of fpn outs {fpn_outs.shape}")
计算文本区域概率图,文本区域阈值图以及文本区域二值图。 DB Head网络会在FPN特征的基础上作上采样,将FPN特征由原图的四分之一大小映射到原图大小.
# 1. 从PaddleOCR中imort DBHead
from ppocr.modeling.heads.det_db_head import DBHead
import paddle
# 2. 计算DBFPN网络输出结果
fake_inputs = paddle.randn([1, 3, 640, 640], dtype="float32")
model_backbone = MobileNetV3()
in_channles = model_backbone.out_channels
model_fpn = DBFPN(in_channels=in_channles, out_channels=256)
outs = model_backbone(fake_inputs)
fpn_outs = model_fpn(outs)
# 3. 声明Head网络
model_db_head = DBHead(in_channels=256)
# 4. 打印DBhead网络
print(model_db_head)
# 5. 计算Head网络的输出
db_head_outs = model_db_head(fpn_outs)
print(f"The shape of fpn outs {fpn_outs.shape}")
print(f"The shape of DB head outs {db_head_outs['maps'].shape}")
引用: https://aistudio.baidu.com/aistudio/projectdetail/6232311 。
最后此篇关于OCR--文本检测的文章就讲到这里了,如果你想了解更多关于OCR--文本检测的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
根据 Wikipedia 的说法,“拉丁文打字文本的准确识别现在被认为在很大程度上解决了可以提供清晰成像的应用程序(例如扫描打印文档)的问题。”但是,它没有给出引用。 我的问题是:这是真的吗?当前最先
我在将包含文本图像的 JPG 文件转换为文本文件时遇到问题。我尝试了 ABBYY 的 OCR SDK 和其他一些 OCR 来源,但没有一个包含格鲁吉亚语。 你能告诉我是否有任何可用于格鲁吉亚语的 OC
有人给了我一大堆惊人的信息。它是 200MB 的 .tiff 扫描公告图像,可以追溯到 40 年代。我想将其数字化,但我对 OCR 一无所知。一些早期的 Material 几乎无法被人类阅读,更不用说
我正在尝试通过 python-tesseract 使用 tesseract-OCR 来读取看起来像这样的低分辨率字体: 不幸的是,该图像返回 ZIJZHZI 我认为分辨率太低,这会导致问题。我试过放大
OCR 软件是否能够可靠地将如下图像转换为值列表? 更新: 更详细的任务如下: 我们有一个客户端应用程序,用户可以在其中打开报告。此报告包含一个值表。 但并不是每个报告看起来都一样——不同的字体、不同
我正在尝试使用 Tesseract-OCR检测其中包含纯文本的图像文本,但这些文本具有名为Journal 的手写字体。 例子: 结果不是最好的: Maxima! size` W (35) 有没有可能改
我已经开始了一个简单的项目,它必须获得一个包含带有上标的文本的图像,然后通过使用 OCR(目前我正在使用 tesseract)它必须识别上标字符 + 正常字符。 例如,我们有一个化学方程式,例如 Cl
关闭。这个问题是off-topic .它目前不接受答案。 想改善这个问题吗? Update the question所以它是 on-topic对于堆栈溢出。 8年前关闭。 Improve this q
我目前正在研究 OCR(波斯语), 尽管“fas.traineddata”在tessdata中可用,但是当我使用以下命令时,什么也没发生: import pytesseract from PIL im
我对文本片段中下标和上标的一般识别有疑问。 示例图片: 我使用 Tesseract 4.1.1 和 https://github.com/tesseract-ocr/tessdata_best 下可用
在过去的 3 个月里,我一直在尝试训练 Tesseract 通过识别我拥有的图像集合,由于真正的缺乏 正确的文档,以及非常高的复杂性,我开始 放弃将 Tesseract 作为解决方案。 我正在寻找一种
关闭。这个问题不符合Stack Overflow guidelines .它目前不接受答案。 想改进这个问题?将问题更新为 on-topic对于堆栈溢出。 12 个月前关闭。 Improve this
已结束。此问题正在寻求书籍、工具、软件库等的推荐。它不满足Stack Overflow guidelines 。目前不接受答案。 我们不允许提出寻求书籍、工具、软件库等推荐的问题。您可以编辑问题,以便
下面是我的电表读数 52425.5(粗略)的图片: 什么程序/技术可以帮助我自动抄表?备注: 这是较为清晰的图像之一。许多图像都有静态。我可以忽略(让程序说“错误”)带有太多静态的图片。 相机有一个固
大写字母OCR(光学字符识别)的常见错误有哪些? 例如FOR -> FOB 最佳答案 要获得最准确的答案,最好使用针对您的问题的特定数据样本自行测试。不同字符/单词组合的错误率可能有很大差异,具体取决
对于我想教 Tesseract 将复选框识别为单词的客户。当 Tesseract 应该识别一个空的复选框时,它工作得很好。 此命令与 this 结合使用教程就像一个魅力,Tesseract 能够找到空
我正在使用 Tesseract OCR将扫描的 PDF 转换为纯文本。总体而言,它非常有效,但我对扫描文本的顺序有疑问。带有表格数据的文档似乎是逐列向下扫描,而更自然的方式是逐行扫描。一个非常小的例子
在哪里可以找到 cube 的 tesseract ocr 土耳其语扩展模式? 文件: tr.cube.fold tr.cube.lm tr.cube.nn tr.cube.params tr.cube
我正在编写一个用于训练 Tesseract OCR 图像的生成器。 在为 Tesseract OCR 的新字体生成训练图像时,最佳值是什么: 新闻部 以磅为单位的字体大小 字体是否应该抗锯齿 边界框是
我的文本带有一些不那么复杂的数学符号,如下所示。 Tesseract OCR 默认无法识别此类数学符号(+-、角度)。我如何通过 tesseract 识别这些数学符号? 最佳答案 只需使用以下语句:

我是一名优秀的程序员,十分优秀!