
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 27
27
 4
4


-系列目录- 。
大数据(一)背景和概念 。
大数据(二)大数据架构发展史 。
大数据(三)大数据技术栈发展史。
前两章,我们分析了大数据相关的概念和发展史,本节我们就讲一讲具体的大数据领域的 常见技术栈 发展史。对主流技术栈有一个初步的认知.
大数据技术栈非常多估计大大小小多达上百种。但发展史、技术体系仍有迹可循。我们从 数据采集、清洗、应用3大步骤来看 ,在每个步骤内部按照时序标识主流技术栈时间点。以此期望能给大家一个初步的映像。三大步骤如下:
分步骤整体技术栈如下图所示:

如上图,数据采集可以归纳为两大类:离线查询同步、实时变更同步。如下图所示:
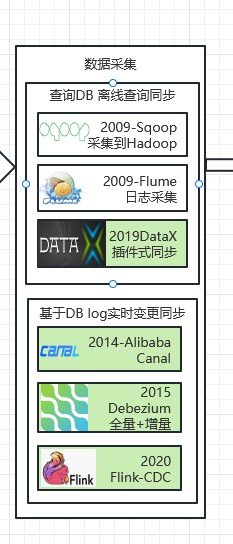
离线同步常见技术栈有:Sqoop、Flume、DataX.
1)介绍 。
Apache Flume 是一个分布式、高可靠、高可用的用来收集、聚合、转移不同来源的大量日志数据到中央数据仓库的工具。也是Apache顶级项目.
2)同步原理 。

flume采集流模式进行数据实时采集。 适用于日志文件实时采集,特定 文件传输 场景使用.
1)介绍 。
DataX是阿里开源的, 异构数据源离线同步工具 ,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能.
2)同步原理 。

为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步.
数据库日志同步。适用于在异构数据库/文件系统之间高速交换数据, 是主流的离线同步工具,推荐使用 .
1)介绍 。
canal [kə'næl] ,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。2014年,由Alibaba开源.
github:https://github.com/alibaba/canal,阿里巴巴 MySQL binlog 增量订阅&消费组件.
2)同步原理 。
1)介绍 。
RedHat(红帽公司) 开源的Debezium是一个将多种数据源实时变更数据捕获,形成数据流输出的开源工具。 它是一种CDC(Change Data Capture)工具,工作原理类似大家所熟知的 Canal, DataBus, Maxwell 等,是通过抽取数据库日志来获取变更的.
2)同步原理 。

Debezium的工作原理是 利用数据库日志来捕获数据库更改事件,深度结合Kafka实现 .
1)介绍 。
FlinkCDC是Apache Flink的一组源连接器,使用更改数据捕获(CDC)从不同的数据库摄取更改。项目诞生于2020年,底层也是封装的Debezium.
github: https://github.com/ververica/flink-cdc-connectors 。
2)同步原理 。
同Debezium.
常见开源CDC方案比较如下:

如上图,如果需要做全量+增量同步, FlinkCDC是一个不错的选择 。(支持的下游生态更丰富、操作更简单Flink SQL) 。
数据清洗阶段是大数据的核心能力阶段,主要包含 计算(离线计算、实时计算)+存储(分布式存储) ,下面我们就从这两个方面来看有哪些主流技术栈.

如上图所示,Google在2003-2006之间发布了3篇始祖级论文:2003分布式文件系统GFS、2004分布式计算框架MapReduce、2006NoSQL数据库系统BigTable。之后在2006年发布了大数据平台Hadoop,自此这只黄色的可爱小象,驰骋在大数据领域,所向披靡.

离线计算领域Hadoop的MapReduce是始祖,有2个衍生技术栈:Pig和Hive。最后一个Spark相对Hadoop MapReduce性能上有极大提升.
1)介绍 。
Hadoop MapReduce是一个 软件框架 ,可以轻松地编写应用程序,以可靠,容错的方式 并行处理 大型硬件集群(数千个节点)上的大量数据(多TB数据集).
2)原理 。
MapReduce 作业通常将输入数据集拆分为独立的块,这些任务由地图任务以完全并行的方式进行处理。框架对地图的输出进行排序,然后将其输入到reduce任务。1)介绍 。
为了简化MapReduce开发的流程,Yahoo工程师发明了Pig,后捐给了Apache。只需编写Pig Latin脚本语言,系统自动转化成mapreduce执行。 pig 不是主流技术栈,不建议使用.
2)原理 。

Apache PIG提供一套高级语言平台,用于对结构化与非结构化数据集进行操作与分析。这种语言被称为Pig Latin,其属于一种脚本形式,可直接立足于PIG shell执行或者通过Pig Server进行触发。用户所创建的脚本会在初始阶段由Pig Latin处理引擎进行语义有效性解析,而后被转换为包含整体执行初始逻辑的定向非循环图(简称DAG).
1)介绍 。
Hive起源于FaceBook,是基于Hadoop的一个 数据仓库工具 ,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能 将SQL语句转变成MapReduce任务来执行 .
2)原理 。

如上图所示,Hive基本原理就是 转换HQL语言为MapReduce任务来执行 。hive 并非为联机事务处理而设计,hive 并不提供实时的查询和基于行级的数据更新操作。hive的最佳使用场合是 大数据集的批处理作业 ,例如,网络日志分析.
1)介绍 。
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出 结果可以保存在内存中,从而不再需要读写HDFS ,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。简单来说,Spark是一个 快速,通用,可扩展 的 分布式计算引擎 。这里把Spark划归离线计算,是把Spark Streaming排除在外的。 Spark是离线计算(批处理)领域的主流技术栈.
2)原理 。

如上图所示,Spark有三个主要特性: RDD的编程模型更简单 , DAG切分的多阶段计算过程更快速 , 使用内存存储中间计算结果更高效 。这三个特性使得Spark相对Hadoop MapReduce可以有更快的执行速度,以及更简单的编程实现。这里具体的细节原理就不展开细讲.
。
流式计算领域,有3个典型技术栈: Storm、Spark Streaming、Flink ,其中 Spark Streaming是“微批拟流” ,不能算是真流。两种流式处理说明如下:
1)Native Streaming原生流 :指每个传入的记录一到达就会被处理,而不必等待其他记录.

。
2)Micro-batching微批拟流: 这意味着每隔几秒就会将传入记录一起批处理,然后在一个小批量中处理,延迟几秒钟.

。
1)介绍 。
Storm是一个免费开源、分布式、高容错的实时计算系统。Storm最早于2011年诞生于Twitter,2013年进入Apache社区进行孵化, 2014年9月,晋级成为Apache顶级项目。早期Storm用于实时计算,Hadoop用于离线计算。 现阶段已不推荐使用 .
2)原理 。
在Storm中,先要设计一个用于实时计算的图状结构,我们称之为 拓扑(topology) ,它的结构和Mapreduce任务类似,通过自定定义Spout(数据输入处理模块)和Bolt(输出处理模块)逻辑,以及自定义Bolt之间的拓扑依赖关系,完成整个实时事件流的处理逻辑搭建。 Topology(拓扑) 是一个是由 Spouts 和 Bolts 通过 Stream 连接起来的有向无环图。Topology将会被提交给集群,由集群中的主控节点(master node)分发代码,将任务分配给工作节点(worker node)执行。 T opology拓扑 结构如下图所示:

Storm采用 主从架构 。nimbus是集群的Master,负责集群管理、任务分配等。supervisor是Slave,是真正完成计算的地方,每个supervisor启动多个worker进程,每个worker上运行多个task,而task就是spout或者bolt。supervisor和nimbus通过ZooKeeper完成任务分配、心跳检测等操作。如下图所示:

1)介绍 。
Spark是Hadoop的批处理(MapReduce)实际继承者。为了应对流式处理场景,2013年Spark 2.0推出了Spark Streaming。但由于不是原生流处理技术栈,存在时延,加之高级功能不如Flink, 已不是主流技术栈 .
2)原理 。
Spark Streaming是在 Spark Core API基础上扩展出来的,以 微批模式实现的近实时计算框架 ,它认为 流是批的特例 ,将输入数据切分成一个个小的切片,利用Spark引擎作为一个个小的batch数据来处理,最终输出切片流,以此实现近似实时计算。如下图所示:

。
1)介绍 。
Apache Flink是一个框架和分布式处理引擎,用于 无界和有界数据流的有状态计算 。Flink创造性地统一了流处理和批处理,作为 流处理 看待时 输入数据流是无界的 ,而 批处理 被作为一种特殊的流处理,只是它的 输入数据流被定义为有界 的。2015年发布了第一个版本, 目前Flink已成为流处理领域的实际标准 ,且大有一统某些场景的批流一体方案的计算引擎.

同时支持有界、无界:

。
2)原理 。
Flink 架构也遵循Master-Slave架构设计原则,JobManager为Master节点,TaskManager为Slave节点。架构图如下:

相比于计算领域的百花齐放,分布式存储技术栈就显得独树一帜了。最早的Hadoop HDFS分布式文件系统,以及基于HDFS衍生出来的Hbase.
。
1)介绍 。
HBase是一个分布式的、面向列的开源数据库。建立在 HDFS 之上。Hbase的名字的来源是 Hadoop database。HBase 的计算和存储能力取决于 Hadoop 集群。它介于NoSql和RDBMS之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过Hive支持来实现多表join等复杂操作).
HBase中表的特点:
2)原理 。
hbase的系统架构如下:

HBase由三种类型的服务器以主从模式构成:
HBase 表数据模型如下:
。
与nosql数据库一样,row key是用来检索记录的主键。访问hbase table中的行,只有三种方式:
。
本节聚焦大数据OLAP,讲解主流技术栈 。OLAP技术发展至今,已经是”百花齐放“之势,可简单分三类:

Rolap(Relational OLAP),即 关系型OLAP 。Rolap基于关系型数据库,它的OLAP引擎就是将用户的OLAP操作,如上钻下钻过滤合并等,转换成SQL语句提交到数据库中执行,并且提供聚集导航功能,根据用户操作的维度和度量将SQL查询定位到最粗粒度的事实表上去。分为两大类:1、MPP数据库 2、SQL on Hadoop.

MPPDB即基于 MPP架构 (Massive Parallel Processing,海量并行处理)的数据库。典型技术栈有:Doris/StarRocks、ClickHouse、GreenPlum.
Doris-2018 。
Apache Doris 是由百度开源的一款MPP数据库,支持标准的SQL语言, 兼容MYSQL协议 ,可直接对接主流BI系统。2018年捐给apache,后在2022年成为Apache 顶级项目。 使用简单、 生态完善、运维方便、稳定可靠、国产之光----一站式开箱即用,无脑推荐使用。 Doris定位如下图:

ClickHouse-2016 。
ClickHouse 是俄罗斯的Yandex于2016年开源的一个 用于联机分析(OLAP)的 列式数据库管理系统。 性能极高,运维难度较大,全球风靡 --- 推荐使用 。看官网介绍的定位支持任何数据源的快速查询,如下图:

。
GreenPlum 。
为了提高SQL on Hadoop的性能,第一个重要技术流派的就是 MPP (Massively Parallel Processing),即大规模并行处理。简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与Hadoop相似)。 其中的代表就是 Presto & Impala .
1)Presto 。
Presto 是 Facebook 推出分布式SQL交互式查询引擎,完全基于 内存的并行计算,这也是为啥Presto比Hive快的原因 。Presto架构图如下:

2)Impala 。
Impala 是 Cloudera 在受到 Google 的 Dremel 启发下开发的 实时交互SQL大数据查询工具 ,其也是基于内存的并行计算框架 ,缺点是仅适用于 HDFS/Hive 系统的查询.

3)其它 。
Blink 诞生于2015年,在Alibaba内部使用,2019年开源并于Flink1.9.0版本。 Flink SQL 可以做到 API 层的流与批统一,这是一个极大的进步,让用户关注核心API即可而不用关注底层细节 .


。
技术争鸣——关于OLAP引擎你所需要知道的一切 。
HBase 底层原理详解(深度好文,建议收藏) 。
最后此篇关于大数据(三)大数据技术栈发展史的文章就讲到这里了,如果你想了解更多关于大数据(三)大数据技术栈发展史的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
27
4
 0
0
初学者 android 问题。好的,我已经成功写入文件。例如。 //获取文件名 String filename = getResources().getString(R.string.filename
我已经将相同的图像保存到/data/data/mypackage/img/中,现在我想显示这个全屏,我曾尝试使用 ACTION_VIEW 来显示 android 标准程序,但它不是从/data/dat
我正在使用Xcode 9,Swift 4。 我正在尝试使用以下代码从URL在ImageView中显示图像: func getImageFromUrl(sourceUrl: String) -> UII
我的 Ubuntu 安装 genymotion 有问题。主要是我无法调试我的数据库,因为通过 eclipse 中的 DBMS 和 shell 中的 adb 我无法查看/data/文件夹的内容。没有显示
我正在尝试用 PHP 发布一些 JSON 数据。但是出了点问题。 这是我的 html -- {% for x in sets %}
我观察到两种方法的结果不同。为什么是这样?我知道 lm 上发生了什么,但无法弄清楚 tslm 上发生了什么。 > library(forecast) > set.seed(2) > tts lm(t
我不确定为什么会这样!我有一个由 spring data elasticsearch 和 spring data jpa 使用的类,但是当我尝试运行我的应用程序时出现错误。 Error creatin
在 this vega 图表,如果我下载并转换 flare-dependencies.json使用以下 jq 到 csv命令, jq -r '(map(keys) | add | unique) as
我正在提交一个项目,我必须在其中创建一个带有表的 mysql 数据库。一切都在我这边进行,所以我只想检查如何将我所有的压缩文件发送给使用不同计算机的人。基本上,我如何为另一台计算机创建我的数据库文件,
我有一个应用程序可以将文本文件写入内部存储。我想仔细看看我的电脑。 我运行了 Toast.makeText 来显示路径,它说:/数据/数据/我的包 但是当我转到 Android Studio 的 An
我喜欢使用 Genymotion 模拟器以如此出色的速度加载 Android。它有非常好的速度,但仍然有一些不稳定的性能。 如何从 Eclipse 中的文件资源管理器访问 Genymotion 模拟器
我需要更改 Silverlight 中文本框的格式。数据通过 MVVM 绑定(bind)。 例如,有一个 int 属性,我将 1 添加到 setter 中的值并调用 OnPropertyChanged
我想向 Youtube Data API 提出请求,但我不需要访问任何用户信息。我只想浏览公共(public)视频并根据搜索词显示视频。 我可以在未经授权的情况下这样做吗? 最佳答案 YouTube
我已经设置了一个 Twilio 应用程序,我想向人们发送更新,但我不想回复单个文本。我只是想让他们在有问题时打电话。我一切正常,但我想在发送文本时显示传入文本,以确保我不会错过任何问题。我正在使用 p
我有一个带有表单的网站(目前它是纯 HTML,但我们正在切换到 JQuery)。流程是这样的: 接受用户的输入 --- 5 个整数 通过 REST 调用网络服务 在服务器端运行一些计算...并生成一个
假设我们有一个名为 configuration.js 的文件,当我们查看内部时,我们会看到: 'use strict'; var profile = { "project": "%Projec
这部分是对 Previous Question 的扩展我的: 我现在可以从我的 CI Controller 成功返回 JSON 数据,它返回: {"results":[{"id":"1","Sourc
有什么有效的方法可以删除 ios 中 CBL 的所有文档存储?我对此有疑问,或者,如果有人知道如何从本质上使该应用程序像刚刚安装一样,那也会非常有帮助。我们正在努力确保我们的注销实际上将应用程序设置为
我有一个 Rails 应用程序,它与其他 Rails 应用程序通信以进行数据插入。我使用 jQuery $.post 方法进行数据插入。对于插入,我的其他 Rails 应用程序显示 200 OK。但在
我正在为服务于发布请求的 API 调用运行单元测试。我正在传递请求正文,并且必须将响应作为帐户数据返回。但我只收到断言错误 注意:数据是从 Azure 中获取的 spec.js const accou

我是一名优秀的程序员,十分优秀!