
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 29
29
 4
4


本文主要介绍用于估算 transformer 类模型计算量需求和内存需求的相关数学方法.
其实,很多有关 transformer 语言模型的一些基本且重要的信息都可以用很简单的方法估算出来。不幸的是,这些公式在 NLP 社区中鲜为人知。本文的目的是总结这些公式,阐明它们是如何推导出来的及其作用.
注意: 本文主要关注训练成本,该成本主要由 GPU 的 VRAM 主导。如果你想知道有关推理成本 (通常由推理延迟主导) 的信息,可以读读 Kipply 写的 这篇精彩博文 .
下式可用于估算训练一个 transformer 模型所需的算力成本
这里
该式由 OpenAI 的缩放定律论文 和 DeepMind 的缩放定律论文 提出并经其实验验证。想要获取更多信息,可参阅这两篇论文.
下面,我们讨论一下 \(C\) 的单位。 \(C\) 是总计算量的度量,我们可以用许多单位来度量它,例如
FLOP - 秒 ,单位为 \({\text {每秒浮点运算数}} \times \text {秒}\) GPU - 时 ,单位为 \(\text {GPU 数}\times\text {小时}\) PetaFLOP - 天 为单位,即单位为 \(10^{15} \times 24 \times 3600\) 这里需要注意 \(\text {实际 FLOPs}\) 的概念。虽然 GPU 的规格书上通常只宣传其理论 FLOPs,但在实践中我们从未达到过这些理论值 (尤其在分布式训练时!)。我们将在计算成本这一小节列出分布式训练中常见的 \(\text {实际 FLOPs}\) 值.
请注意,上面的算力成本公式来自于 这篇关于 LLM 训练成本的精彩博文 .
严格来讲,你可以随心所欲地使用任意数量的词元来训练 transformer 模型,但由于参与训练的词元数会极大地影响计算成本和最终模型的性能,因此需要小心权衡.
我们从最关键的部分开始谈起: “计算最优” 语言模型。 “Chinchilla 缩放定律”,得名于提出 “计算最优” 语言模型论文中所训练的模型名,指出计算最优语言模型的 参数量 和 数据集大小 的近似关系满足: \(D=20P\) 。该关系成立基于一个前提条件: 使用 1,000 个 GPU 1 小时和使用 1 个 GPU 1,000 小时成本相同。如果你的情况满足该条件,你应该使用上述公式去训练一个性能最优且 GPU - 时 成本最小的模型.
但 我们不建议在少于 200B 词元的数据集上训练 LLM。 虽然对于许多模型尺寸来说这是 “Chinchilla 最优” 的,但生成的模型通常比较差。对于几乎所有应用而言,我们建议确定你可接受的推理成本,并训练一个满足该推理成本要求的最大模型.
Transformer 模型的计算成本通常以 GPU - 时 或 FLOP - 秒 为单位.
实际 TFLOP/s 在正常注意力机制下达到 150 TFLOP/s/A100,在 Flash 注意力机制下达到 180 FLOP/s/A100。这与其他高度优化的大规模计算库一致,例如 Megatron-DS 的值是在 137 和 163 TFLOP/s/A100 之间。 实际 TFLOP/s 可至 120 TFLOP/s/A100 左右。如果你得到低于 115 TFLOP/s/A100 的值,可能是你的模型或硬件配置有问题。 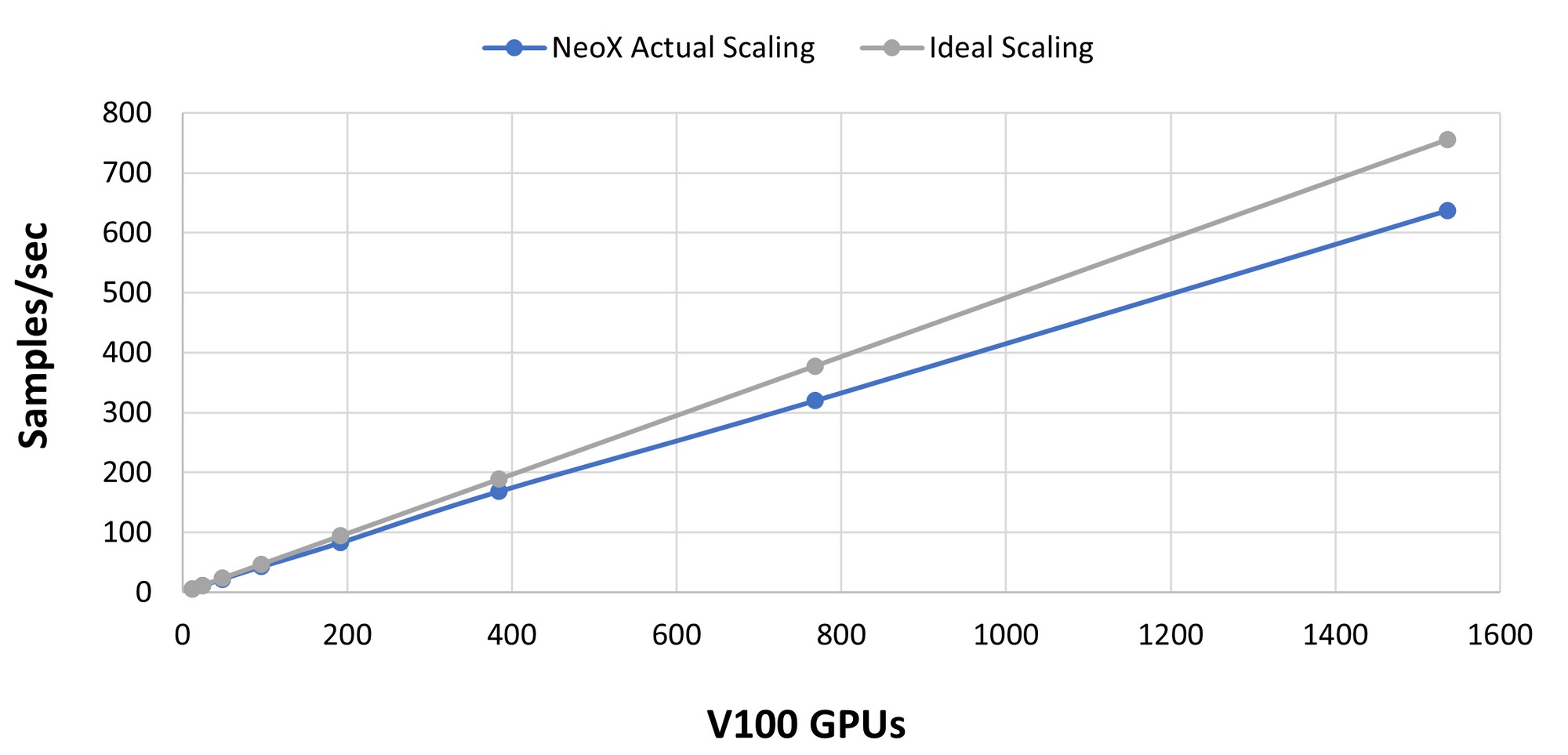
Transformer 模型通常由其 参数尺寸 来描述。但是,根据给定一组计算资源确定要训练哪些模型时,你需要知道 该模型将占用多少空间 (以字节为单位) 。这不仅需要考虑你的本地 GPU 可以推理多大的模型,还需要考虑给定训练集群中的总可用 GPU 内存可供训练多大的模型.
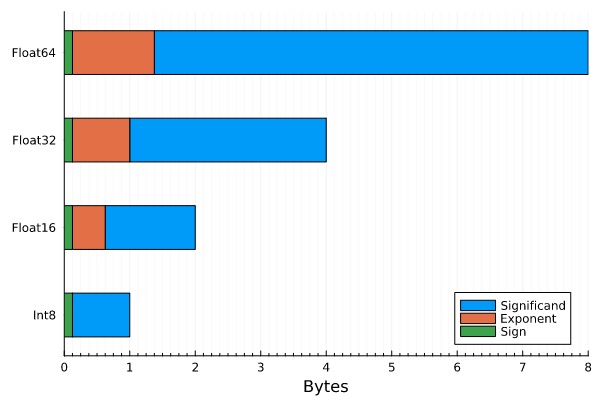
大多数 transformer 模型都使用 混合精度 进行训练,可以是 fp16 + fp32 或是 bf16 + fp32。混合精度降低了模型训练和推理所需的内存量。推理时,我们还可以将语言模型从 fp32 转换为 fp16 甚至 int8,而没有实质性的精度损失。下面我们看看在不同的数据类型下,模型所需内存有什么不同 (以字节为单位)
除了存储模型权重所需的内存外,实际中前向传播过程中还会有少量额外开销。根据我们的经验,此开销在 20% 以内,该比例通常与模型无关.
总的来说,回答 “这个模型是否适合推理” 这一问题,可以用下述公式来获得不错的估计
\(\text {推理总内存} \approx 1.2 \times \text {模型内存}\) 。
本文不会深究该开销的来源,留待后面的文章来阐述。在本文的后续部分,我们将主要关注模型训练的内存。如果你有兴趣了解更多有关推理计算需求的信息,请查看 这篇深入介绍推理的精彩博文 。现在,我们要开始训练了! 。
除了模型权重之外,训练还需要在设备内存中存储优化器状态和梯度。这就是为什么当你问 “我需要多少内存来运行模型?”,别人会立即回答 “这取决于是训练还是推理”。训练总是比推理需要更多的内存,通常多得多! 。
首先,可以使用纯 fp32 或纯 fp16 训练模型
除了推理中讨论的常见模型权重数据类型外,训练还引入了 混合精度 训练,例如 AMP 。该技术寻求在保持收敛性的同时最大化 GPU 张量核的吞吐量。现代 DL 训练领域经常使用混合精度训练,因为: 1) fp32 训练稳定,但内存开销高且不能利用到 NVIDIA GPU 张量核、2) fp16 训练稳定但难以收敛。更多混合精度训练相关的内容,我们建议阅读 tunib-ai 的 notebook 。请注意,混合精度要求模型的 fp16/bf16 和 fp32 版本都存储在内存中,而模型需要的内存如下
正如上面所讲,这个仅仅是模型内存,还需要额外加上 \(4 \text { 字节 / 参数} \cdot \text {参数量}\) 的 用于优化器状态计算 的模型副本,我们会在下面的 优化器状态 一节中算进去.
Adam 有奇效,但内存效率非常低。除了要求你有模型权重和梯度外,你还需要额外保留三个梯度参数。因此, 。
对于纯 AdamW, \(\text {优化器内存}=12 \text { 字节}/\text {参数}\cdot \text {参数量}\) 。
对于像 bitsandbytes 这样的 8 位优化器, \(\text {优化器内存} =6 \text { 字节} /\text {参数} \cdot \text {参数量}\) 。
对于含动量的类 SGD 优化器, \(\text {优化器内存} =8 \text { 字节} /\text {参数} \cdot \text {参数量}\) 。
梯度可以存储为 fp32 或 fp16 (请注意,梯度数据类型通常与模型数据类型匹配。因此,我们可以看到在 fp16 混合精度训练中,梯度数据类型为 fp16),因此它们对内存开销的贡献为
对于 LLM 训练而言,现代 GPU 通常受限于内存瓶颈,而不是算力。因此,激活重计算 (activation recomputation,或称为激活检查点 (activation checkpointing) ) 就成为一种非常流行的以计算换内存的方法。激活重计算 / 检查点主要的做法是重新计算某些层的激活而不把它们存在 GPU 内存中,从而减少内存的使用量。内存的减少量取决于我们选择清除哪些层的激活。举个例子,Megatron 的选择性重计算方案的效果如下图所示
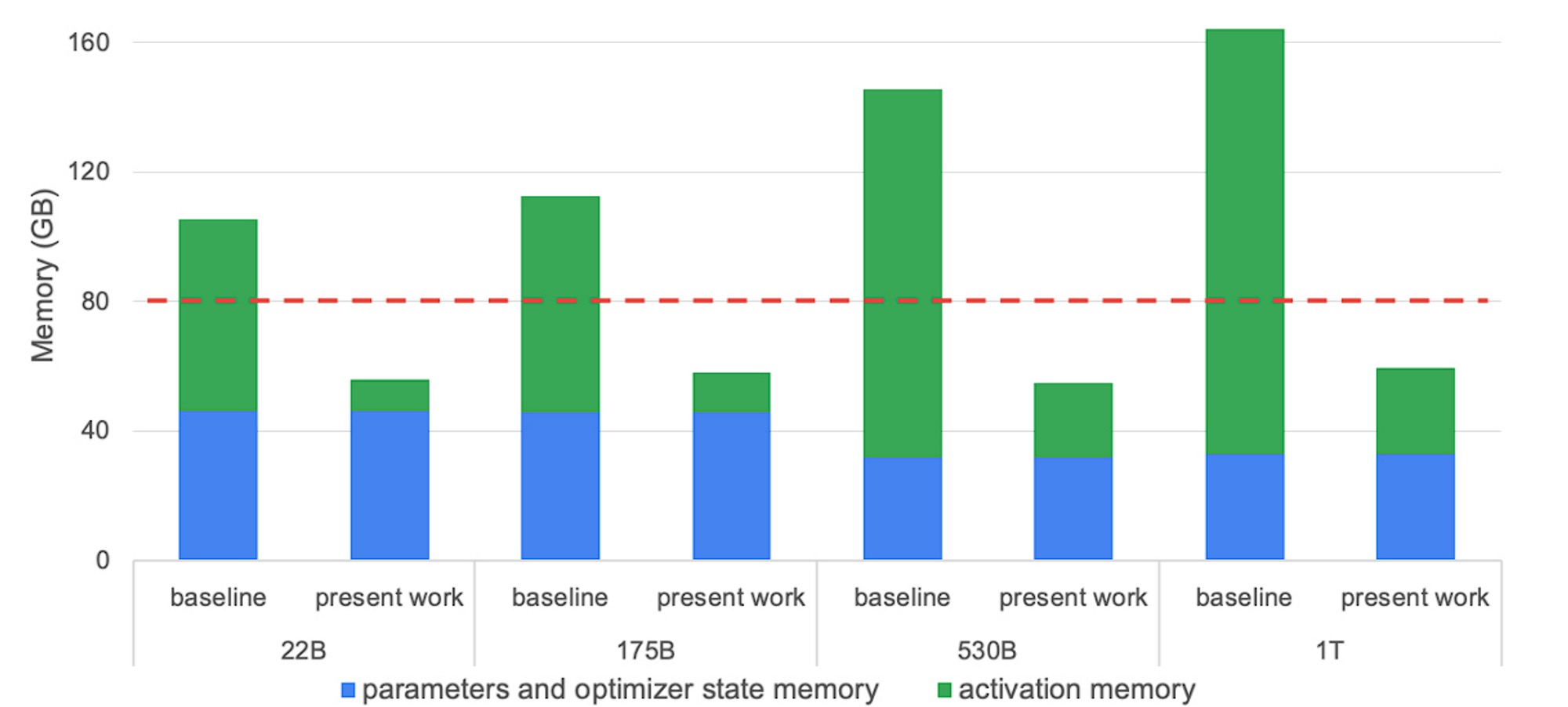
图中,红色虚线表示 A100-80GB GPU 的内存容量,“present work” 表示使用选择性激活重计算后的内存需求。请参阅 Reducing Activation Recomputation in Large Transformer Models 一文,了解更多详细信息以及下述公式的推导过程.
下面给出存储 transformer 模型激活所需内存的基本公式
其中
由于重计算的引入也会引起计算成本的增加,具体增加多少取决于选择了多少层进行重计算,但其上界为所有层都额外多了一次前向传播,因此,更新后的前向传播计算成本如下
至此,我们得到了回答 “这个模型是否适合训练” 这一问题的一个很好的估算公式
巨大的优化器内存开销促使大家设计和实现了分片优化器,目前常用的分片优化器实现有 ZeRO 和 FSDP 。该分片策略可以使单 GPU 的优化器内存开销随 \(\text {GPU 个数}\) 线性下降,这就是为什么你会发现某个模型及其训练配置可能在大规模集群上能跑,但到小规模集群时就 OOM (Out Of Memory,内存耗尽) 了。下图来自于 ZeRO 论文,它形象地说明了不同的 ZeRO 阶段及它们之间的区别 (注意 \(P_{os}\) 、 \(P_{os+g }\) 和 \(P_{os+g+p}\) 通常分别表示为 ZeRO-1、ZeRO-2、ZeRO-3。ZeRO-0 通常表示 “禁用 ZeRO”)
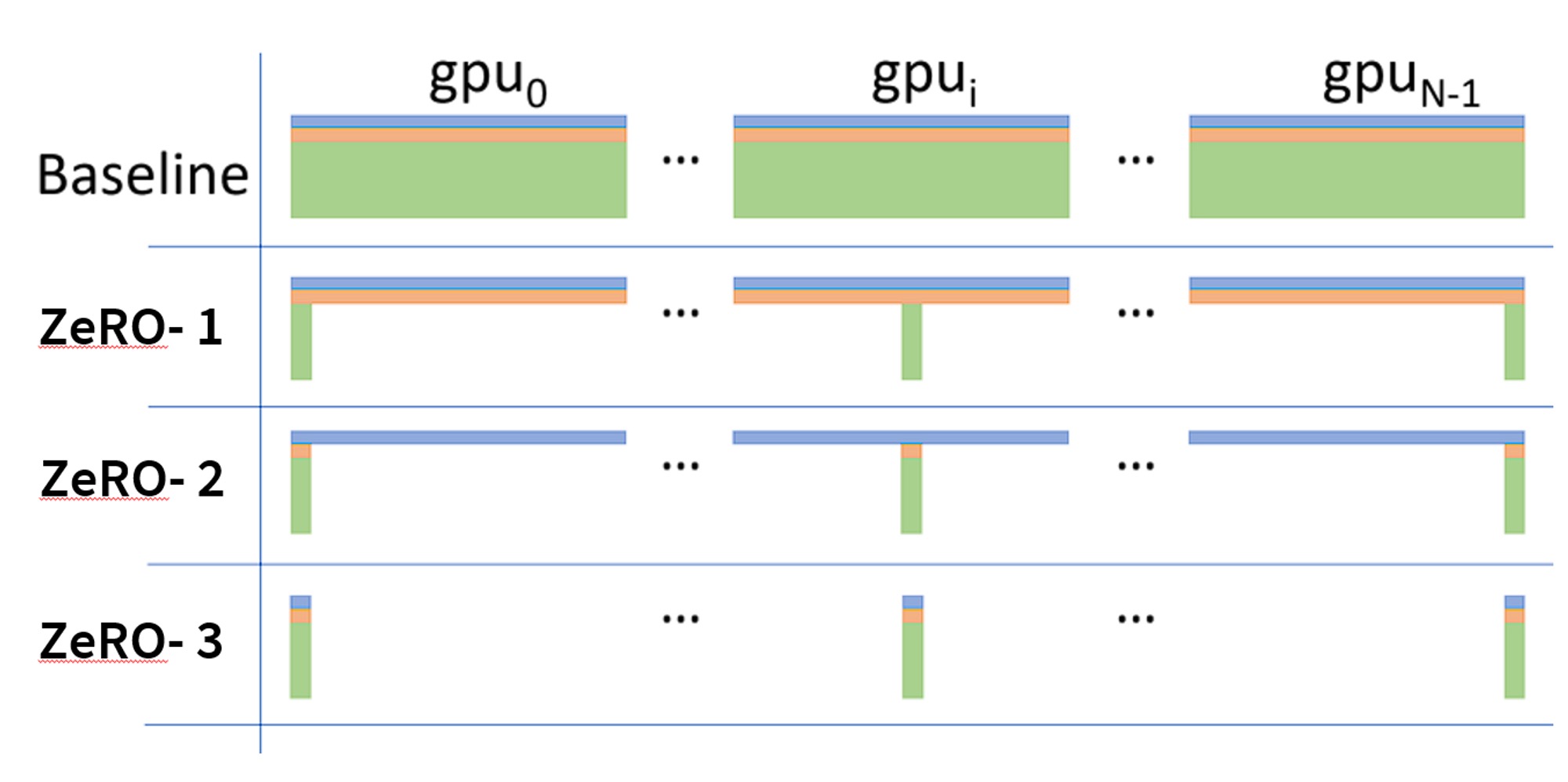

下面,我们总结一下 ZeRO 各阶段的内存开销公式 (假定我们使用混合精度及 Adam 优化器)
其中,在训练过程没有使用流水线并行或张量并行的条件下, \(\text {GPU 数}\) 即为 \(\text {DP 并行度}\) 。更多详细信息,请参阅 Sharded Optimizers + 3D Parallelism 一文.
请注意,ZeRO-3 引入了一组实时参数。这是因为 ZeRO-3 引入了一组配置项 ( stage3_max_live_parameters, stage3_max_reuse_distance, stage3_prefetch_bucket_size, stage3_param_persistence_threshold ) 来控制同一时刻 GPU 内存中可以放多少参数 (较大的值占内存更多但需要的通信更少)。这些参数会对总的 GPU 内存使用量产生重大影响.
请注意,ZeRO 还可以通过 ZeRO-R 在数据并行 rank 间划分激活,这样 \(\text {激活内存}\) 还可以再除以张量并行度 \(t\) 。更详细的信息,请参阅相关的 ZeRO 论文 及其 配置选项 (注意,在 GPT-NeoX 中,相应的配置标志为 partition_activations )。如果你正在训练一个大模型,激活放不下内存而成为一个瓶颈,你可以使用这个方法用通信换内存。把 ZeRO-R 与 ZeRO-1 结合使用时,内存消耗如下
LLM 主要有 3 种并行方式
数据并行: 在多个模型副本间拆分数据 。
流水线或张量 / 模型并行: 在各 GPU 之间拆分模型参数,因此需要大量的通信开销。它们的内存开销大约是
请注意,这是个近似公式,因为 (1) 流水线并行对降低激活的内存需求没有帮助、(2) 流水线并行要求所有 GPU 存储所有正在进行的 micro batch 的激活,这对大模型很重要、(3) GPU 需要临时存储并行方案所需的额外通信缓冲区.
当 ZeRO 与张量并行、流水线并行结合时,由此产生的 GPU 间的并行策略如下
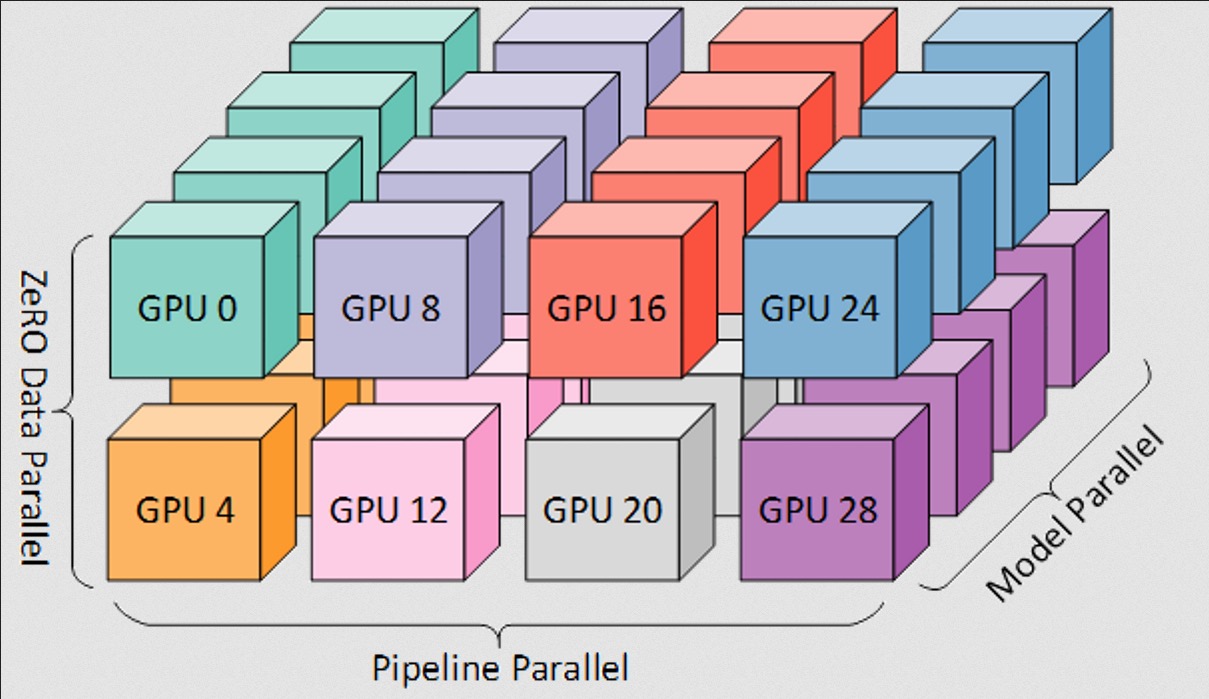
值得一提的是,数据并行度对于计算训练的全局 batch size 至关重要。数据并行度取决于你想在训练集群中保持几份完整模型副本
虽然流水线并行和张量并行与所有 ZeRO 阶段都兼容 (例如,张量并行叠加上 ZeRO-3 后,我们会首先对张量进行切片,然后在每个张量并行单元中应用 ZeRO-3),但只有 ZeRO-1 与张量和 / 或流水线并行相结合时会效果才会好。这是由于梯度划分在不同并行策略间会有冲突 (如流水线并行和 ZeRO-2 都会对梯度进行划分),这会显著增加通信开销.
把所有东西打包到一起,我们可以得到一个典型的 3D 并行 + ZeRO-1 + 激活分区 方案
EleutherAI 的工程师经常使用上述估算方法来高效规划、调试分布式模型训练。我们希望澄清这些经常被忽视的但很有用的实现细节,如果你想与我们讨论或认为我们错过了一些好的方法,欢迎你通过 contact@eleuther.ai 联系我们! 。
请使用如下格式引用本文
@misc {transformer-math-eleutherai,
title = {Transformer Math 101},
author = {Anthony, Quentin and Biderman, Stella and Schoelkopf, Hailey},
howpublished = \url {blog.eleuther.ai/},
year = {2023}
}
英文原文: https://blog.eleuther.ai/transformer-math/ 。
原文作者: Quentin Anthony,Stella Biderman,Hailey Schoelkopf,作者均来自 EleutherAI 。
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理.
审校/排版: zhongdongy (阿东) 。
最后此篇关于Transformer估算101的文章就讲到这里了,如果你想了解更多关于Transformer估算101的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
29
4
 0
0
我有一段这样的代码。我发现 myResults = writer.getBuffer().toString(); 对某些用例返回 EMPTY STRING,但对其他用例则不返回。 我查看了服务器,但在
如何使用 javascript 通过 id 更改元素中的 -webkit-transform 、-moz-transform 、-o-transform 和 -ms-transform css? 这段
我正在使用 javax.xml.transform.Transformer.transform() 通过 xsl 样式表将一个 xml 转换为另一个 xml。我想以编程方式设置第一级 child 的排
为了使 seaborn.pairplot() 正常工作,在 jupyter notebook 中执行了以下步骤。 /usr/local/lib/python2.7/site-packages/matp
假设这个输入 XML 编写这些代码行: StreamSource source = new StreamSource(new StringReader(/* the above XML*/));
如何在 spring 框架中配置 java.xml.transform.Transformer ?我需要转换器的实例来通过 xslt 将 xml 转换为文本。因此,配置的转换器应该了解 xslt 样式
我一直在核心数据中使用可转换属性,将图像和颜色等复杂对象转换为原始数据。我拿了this ... The idea behind transformable attributes is that you
我正在尝试打开 XML 文件,添加一些更改,然后保存到其他 XML 文件结果。我正在使用标准 javax.xml.parsers.* 和 javax.xml.transform* 类。 但在保存的文档
Transformer(变换方法)对输入源的大小有限制吗? 我正在尝试转换一个相当长的 (18M) XML,但收到一个奇怪的错误 "The element type "HR" must be term
我正在尝试解析一个非常简单的示例: 100 我使用的样式表如下: 这在 libxs
来自文档 for from_pretrained ,我知道我不必每次都下载预训练的向量,我可以使用以下语法保存它们并从磁盘加载: - a path to a `directory` contain
默认缓存目录磁盘容量不足,我需要更改默认缓存目录的配置。 最佳答案 您可以在每次加载模型时指定缓存目录 .from_pretrained通过设置参数cache_dir .您可以通过导出环境变量 TRA
有一个函数,例如: CATransform3DGetAffineTransform Returns the affine transform represented by 't'. If 't' ca
我有一个包含 WCF 设置的配置文件: “add”元素只有一个 baseAddress 属性,所以我不能使用 Match 定位器。一种方法如何像我的示例中那样转换多个元素? 最
在收到下面链接中描述的错误后,我已将实体属性的 Transfomer 设置为 NSSecureUnarchiveFromData(之前为 nil)。 CoreData crash error Xcod
当我写Document时使用 Transformer 的 transform() 方法转换为 XML,生成的 XML 文档的格式很好 - 所有元素都写在单独的行上并缩进。除了第一个元素与定义写在同一行
我不明白 StreamResult 实例会发生什么。我看到 Transformer 对象接收 source 和 streamResult: transformer.transform(sour
从下面的代码片段我应该得出结论,std::transform 比 boost::transform 更受欢迎,因为前者使用更少的初始化和析构函数可能更有效比后者? #include #include
transform() 可以将函数应用到序列的元素上,并将这个函数返回的值保存到另一个序列中,它返回的迭代器指向输出序列所保存的最后一个元素的下一个位置。 这个算法有一个版本和 for_each()
我是 react-native 的新手。在项目上将 react-native 从 0.48.3 升级到 0.62.2 后,运行“react-native run-ios”命令时出现错误:“index.

我是一名优秀的程序员,十分优秀!