
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 34
34
 4
4


ChatGPT是当前自然语言处理领域的重要进展之一,通过预训练和微调的方式,ChatGPT可以生成高质量的文本,可应用于多种场景,如智能客服、聊天机器人、语音助手等。本文将详细介绍ChatGPT的原理、实战演练和流程图,帮助读者更好地理解ChatGPT技术的应用和优势.
在当今快速发展的人工智能领域,自然语言处理(Natural Language Processing, NLP)技术是研究的重要方向之一。NLP技术的目标是帮助计算机更好地理解和处理人类语言,从而实现人机交互、自然语言搜索、文本摘要、语音识别等应用场景.
ChatGPT是当前自然语言处理领域的重要进展之一,可以生成高质量的文本,可应用于多种场景,如智能客服、聊天机器人、语音助手等。本文将详细介绍ChatGPT的原理、实战演练和流程图,帮助读者更好地理解ChatGPT技术的应用和优势.
ChatGPT是由OpenAI推出的一种基于Transformer的预训练语言模型。在自然语言处理中,预训练语言模型通常是指使用无标签文本数据训练的模型,目的是为了提高下游任务(如文本分类、命名实体识别、情感分析)的性能。ChatGPT是预训练语言模型的一种,它采用了单向的Transformer模型,通过大规模的文本数据预训练模型,再在具体任务上进行微调,从而实现高质量的文本生成和自然对话.
下面我们来详细介绍一下ChatGPT的原理.
ChatGPT模型采用了单向的Transformer模型,Transformer模型是一种基于注意力机制的编码-解码框架,由Google在2017年提出。它是目前自然语言处理中应用最广泛的模型之一,已经被证明在多种任务上取得了比较好的性能.
Transformer模型的核心是多头注意力机制,它允许模型在不同位置上对输入的信息进行不同的关注,从而提高模型的表达能力。同时,Transformer模型采用了残差连接和Layer Normalization等技术,使得模型训练更加稳定,减少了梯度消失和梯度爆炸等问题.
在Transformer模型中,输入的序列首先经过Embedding层,将每个词映射为一个向量表示。然后输入到多层Transformer Encoder中,每一层包括多头注意力机制和前向传播网络。在多头注意力机制中,模型会计算出每个位置与其他位置的关联程度,从而得到一个权重向量,将这个权重向量应用到输入上,就得到了每个位置的加权表示。接下来,模型会将每个位置的加权表示与原始输入进行残差连接和Layer Normalization,从而得到更好的表达.
在ChatGPT模型中,Encoder和Decoder是相同的,因为它是单向的模型,只能使用历史信息生成当前的文本。每次生成一个新的词时,模型会将历史文本作为输入,通过Decoder生成下一个词.
ChatGPT模型的预训练使用的是大规模的无标签文本数据,例如维基百科、网页文本等,这些数据可以包含数十亿甚至数百亿的单词。预训练的目的是让模型学习到文本的语言规律和语义信息,从而提高模型的泛化能力。预训练使用的是语言建模任务,即在给定部分文本的情况下,模型预测下一个词是什么。预测的损失函数采用交叉熵损失函数,通过反向传播和随机梯度下降算法更新模型参数.
ChatGPT模型的微调是指在特定的任务上,针对不同的数据集,对预训练模型进行微调。微调的目的是将模型应用到具体的场景中,例如聊天机器人、智能客服等。微调过程中,我们会为模型添加一些特定的输出层,根据具体的任务来调整模型的参数.
ChatGPT是一款通用的自然语言生成模型,即GPT翻译成中文就是生成型预训练变换模型。这个模型被互联网巨大的语料库训练之后,它就可以根据你输入的文字内容,来生成对应的文字回答。也就是常见的聊天问答模式,比如:
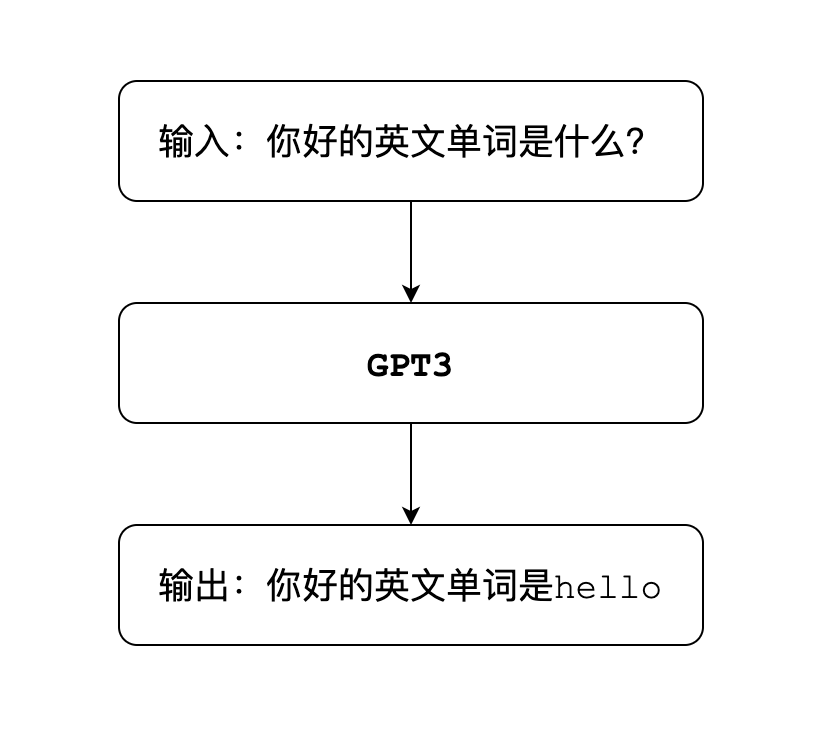
语言模型的工作方式,是对语言文本进行概率建模.

用来预测下一段输出内容的概率,形式上非常类似于我们小时候玩的文字接龙游戏。比如输入的内容是你好,模型就会在可能的结果中,选出概率最高的那一个,用来生成下一部分的内容 。
。
从体验的反馈来看,ChatGPT对比其他的聊天机器人,主要在这样几个方面上进步明显:
ChatGPT目前暂时还没有看到与之相关的论文,但是,官网有一篇Instruct GPT和ChatGPT是非常接近的。在官网上也指出了ChatGPT是InstructGPT的兄弟模型,它经过训练可以按照指示中的说明进行操作并提供详细的响应.

这里我们可以看到2个模型的训练过程非常的相似,文章地址:
https://openai.com/research/instruction-following 。
ChatGPT训练流程如下所示:
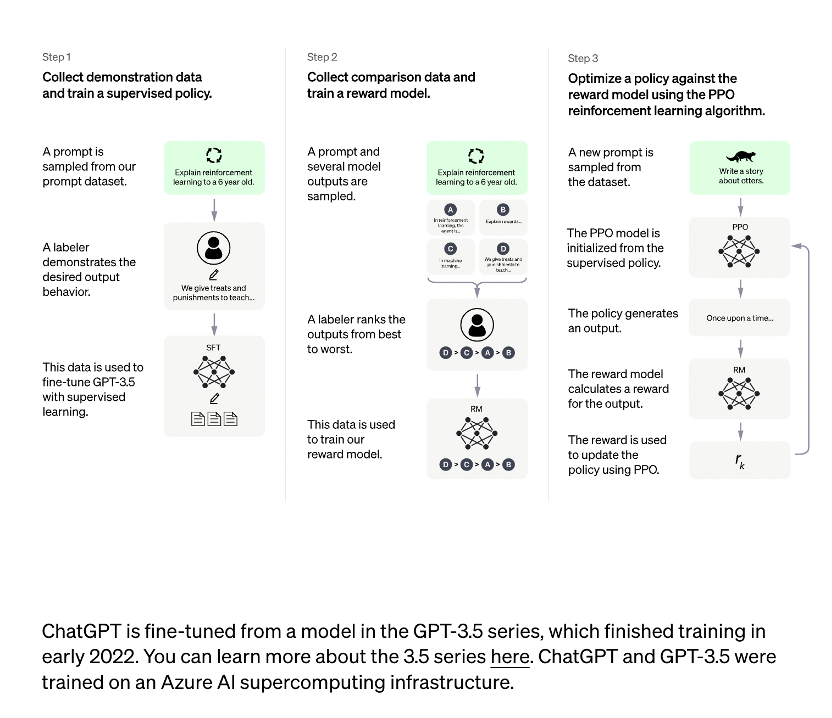
InstructGPT训练流程如下所示:

在OpenAI关于InstructiGPT中的论文中,有可以找到这些直观优势的量化分析.

。
InstructGPT对比上一代GPT3
所以,汇总下来,InstructGPT比上一代模型能够提供更加真实可靠的回答,并且回答的内容也会远比上一代更加符合用户的意愿.
我们要看清楚ChatGPT,为什么可以做到如此出色的效果。就需要我们把视角稍微拉远一点,看一看这款模型,近几年的发展历史。 ChapGPT是OpenAI的另一款模型,它是InstructGPT的兄弟模型,也就是基于InstructGPT做了一些调整,而InstructGPT的上一代是GPT3,再往上一个版本是GPT2,再往上是GPT,那再往前就是Google的那一篇关于transformer的著名论文(https://arxiv.org/pdf/1706.03762.pdf),这里需要提一下的是,同样是基于transformer结构的,还有Google自家的BERT架构,以及对应的分支。 所以,我们能够得到这样一个分支图.
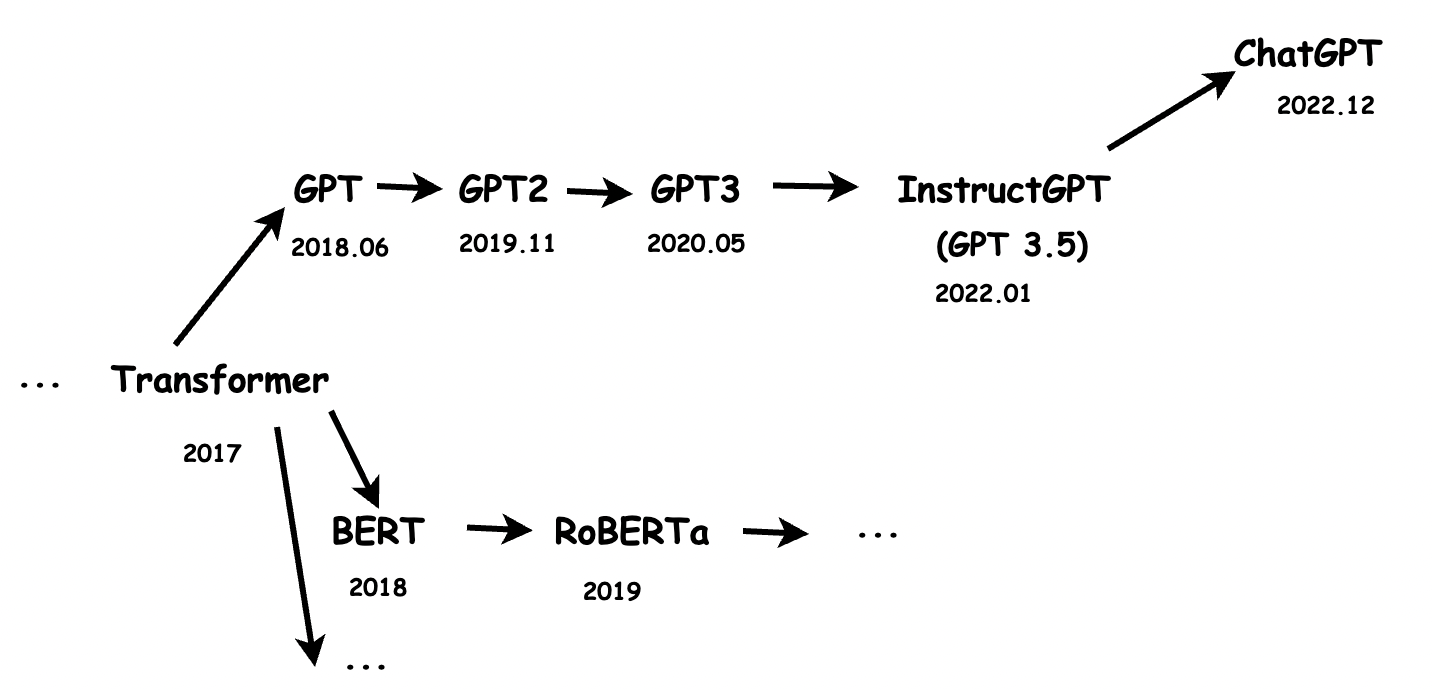
。
这里,本人能力有限,没法对每一篇论文分析总结。但是,想提到一些自己在学习的过程中感觉比较有趣的决定和突破。 首先,同样是transformer架构上分支出来的,BERT和GPT的一大不同,来自于他们transformer具体结构的区别,BERT使用的是transformer的encoder组件,而encoder的组件在计算某个位置时,会关注他左右两侧的信息,也就是文章的上下文。而GPT使用的是transformer decoder组件,decoder组件在计算某个位置时,只关注它左侧的信息,也就是文章的上文.
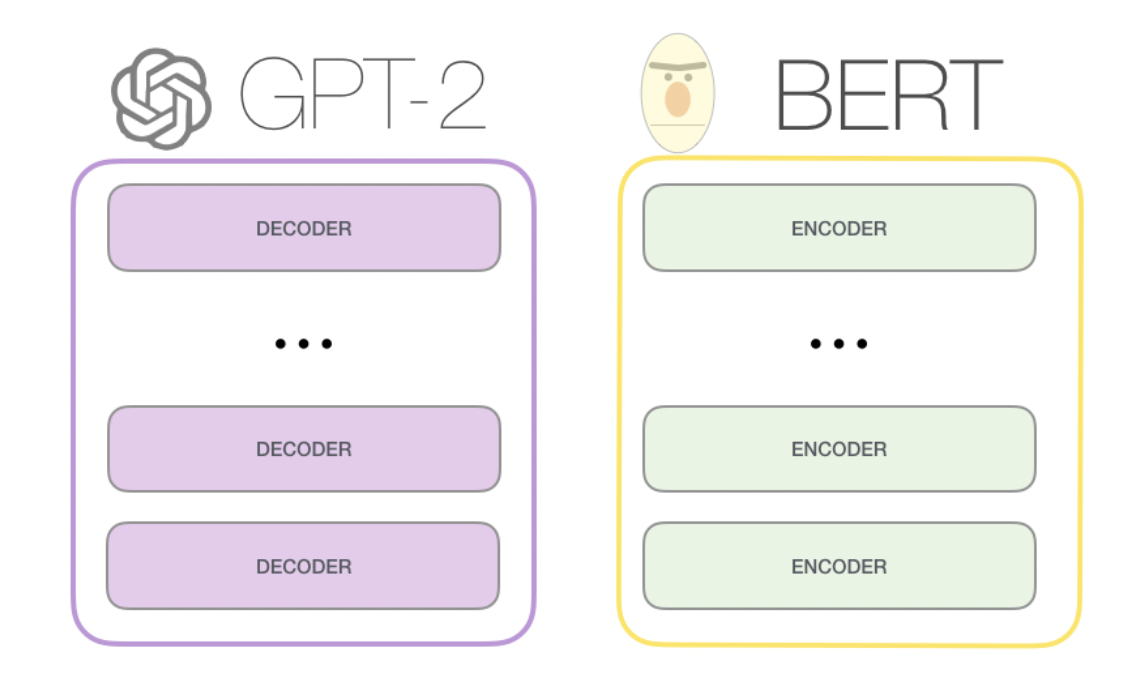
。
我们如果用一个通俗的比喻就是,BERT在结构上对上下文的理解会更强,更适合嵌入式的表达,也就是完型填空式的任务。而GPT在结构上更适合只有上文,完全不知道下文的任务,而聊天恰好就是这样的场景。 另一个有趣的突破,来自模型量级上的提升.
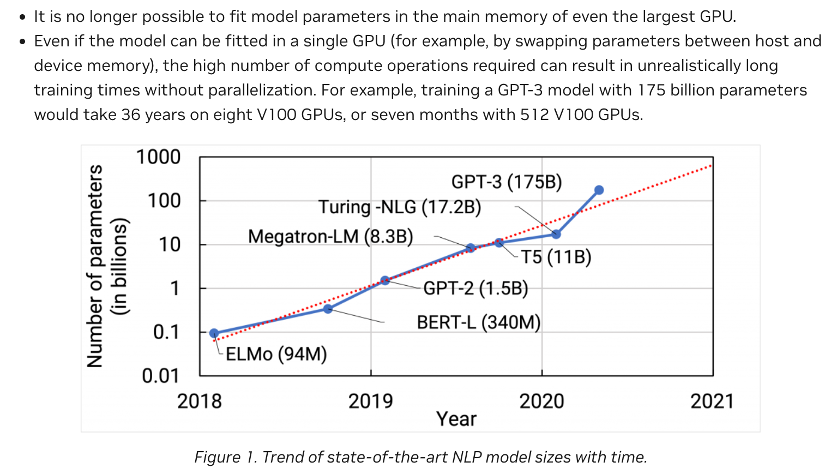
从GPT到GPT2,再到GPT3,OpenAI大力出奇迹,将模型参数从1.17亿,提升到15亿,然后进一步暴力提升到了1750亿个。以至于GPT3比以前同类型的语言模型,参数量增加了10倍以上.
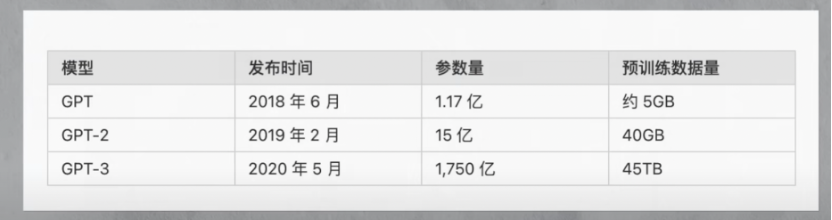
同时,训练数据量也从GPT的5GB,增加到GPT2的40GB,再到GPT3的45TB,与此相关的是在方向上(https://arxiv.org/pdf/2005.14165.pdf) 。
OpenAI没有追求模型在特定类型任务上的表现,而是不断的增加模型的泛化能力。同时,GPT3的训练费用,也到达了惊人的1200万美元.

那下一个有趣的节点,就达到了今天的主角ChatGPT的兄弟,InstructGPT。从GPT3到InstructGPT的一个有趣改进。来自于引入了人类的反馈。用OpenAI论文的说法是,在InstructGPT之前,大部分大规模语言模型的目标,都是基于上一个输入片段token,来推测下一个输入片段.
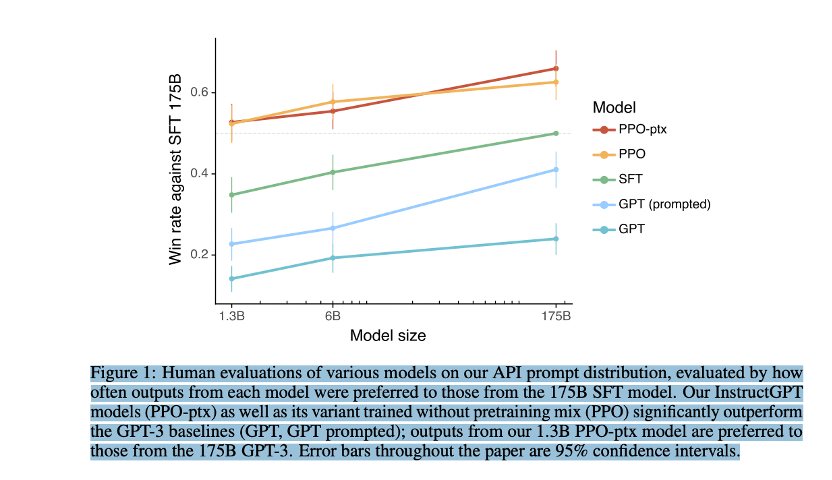
然而这个目标和用户的意图是不一致的,用户的意图是让语言模型,能够有用并且安全的遵循用户的指令,那这里的指令instruction,也就是InstructGPT名字的来源,当然,也就呼应的今天ChatGPT的最大优势,对用户意图的理解。为了达到这个目的,他们引入了人类老师,也就是标记人员,通过标记人员的人工标记,来训练出一个反馈模型,那这个反馈模型,实际上就是一个模仿喜好,用来给GPT3的结果来打分的模型,然后这个反馈模型再去训练GPT3,之所以没有让标记人员,直接训练GPT3,可能是因为数据量太大的原因吧.
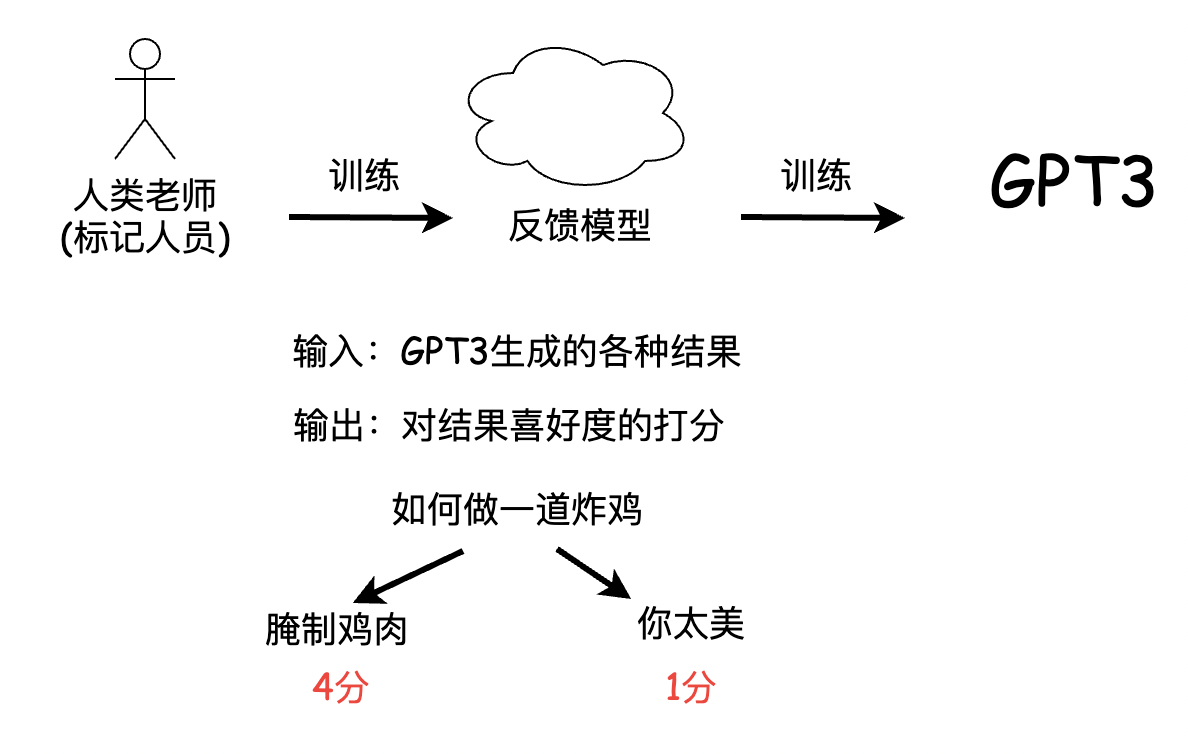
。
所以,这个反馈模型,就像是被抽象出来的人类意志。可以用来激励GPT3的训练,那整个训练方法,就被叫做基于人类反馈的强化学习。至此简易版的InstructGPT的前世今生就介绍完了。我们来回顾一下OpenAI一直在追求的几个特点:
既然说到了原理,还有一个方面是前面没有提及到的,就是连续对话的能力。所以,ChatGPT是如何做到能够记住对话的上下文的呢? 这一能力,其实在GPT3时代就已经具备了,具体做法是这样的,语言模型生成回答的方式,其实是基于一个个的token,这里的token,可以粗略的理解为一个个单词。所以ChatGPT给你生成一句话的回答,其实是从第一个词开始,重复把你的问题以及当前生成的所有内容,再作为下一次的输入,再生成下一个token,直到生成完整的回答.
为了更好地理解ChatGPT模型的实际应用,我们可以尝试使用Hugging Face提供的Transformers库来构建一个聊天机器人模型.
我们可以使用Cornell电影对话数据集来作为ChatGPT模型的训练数据集。Cornell电影对话数据集包含了超过220,579条对话记录,每条记录都有一个问题和一个回答。我们可以将问题和回答组合在一起,形成聊天机器人的训练样本.
在训练ChatGPT模型之前,我们需要对数据进行预处理,将文本转换为数字表示。我们可以使用tokenizer将文本转换为tokens,并将tokens转换为模型输入的数字表示。在使用Hugging Face的Transformers库中,我们可以使用AutoTokenizer自动选择适合的tokenizer,根据模型的类型和配置来进行初始化.
以下是对电影对话数据集进行预处理的代码:
from
transformers
import
AutoTokenizer
tokenizer
= AutoTokenizer.from_pretrained(
'
distilgpt2
'
)
pad_token_id
=
tokenizer.pad_token_id
max_length
= 512
def
preprocess_data(filename):
with open(filename,
'
r
'
, encoding=
'
iso-8859-1
'
) as f:
lines
=
f.readlines()
conversations
=
[]
conversation
=
[]
for
line
in
lines:
line
=
line.strip()
if
line.startswith(
'
M
'
):
conversation.append(line[
2
:])
elif
line.startswith(
'
E
'
):
conversation.append(line[
2
:])
if
len(conversation) > 1
:
conversations.append(conversation)
conversation
=
[]
questions
=
[]
answers
=
[]
for
conversation
in
conversations:
for
i
in
range(len(conversation) - 1
):
questions.append(conversation[i])
answers.append(conversation[i
+1
])
inputs
= tokenizer(questions, answers, truncation=True, padding=True, max_length=
max_length)
return
inputs, pad_token_id
inputs, pad_token_id
= preprocess_data(
'
movie_conversations.txt
'
)
在上述代码中,我们使用了AutoTokenizer来初始化tokenizer,并指定了最大的序列长度为512。同时,我们也定义了padding token的id,并使用preprocess_data函数来对Cornell电影对话数据集进行预处理。在预处理过程中,我们将每个问题和回答组合在一起,使用tokenizer将文本转换为tokens,并将tokens转换为数字表示。我们还设置了padding和truncation等参数,以使得所有输入序列长度相同.
在对数据集进行预处理后,我们可以使用Hugging Face的Transformers库中提供的GPT2LMHeadModel类来构建ChatGPT模型。GPT2LMHeadModel是一个带有语言模型头的GPT-2模型,用于生成与前面输入的文本相关的下一个词.
以下是使用GPT2LMHeadModel训练ChatGPT模型的代码:
from
transformers
import
GPT2LMHeadModel, Trainer, TrainingArguments
model
= GPT2LMHeadModel.from_pretrained(
'
distilgpt2
'
)
model.resize_token_embeddings(len(tokenizer))
training_args
=
TrainingArguments(
output_dir
=
'
./results
'
,
num_train_epochs
=3
,
per_device_train_batch_size
=4
,
save_total_limit
=2
,
save_steps
=1000
,
logging_steps
=500
,
evaluation_strategy
=
'
steps
'
,
eval_steps
=1000
,
load_best_model_at_end
=
True,
)
trainer
=
Trainer(
model
=
model,
args
=
training_args,
train_dataset
=inputs[
'
input_ids
'
],
data_collator
=
lambda
data: {
'
input_ids
'
: torch.stack(data)},
)
trainer.train()
在上述代码中,我们首先使用GPT2LMHeadModel来初始化ChatGPT模型,并调整Embedding层的大小以适应我们的tokenizer。接下来,我们定义了TrainingArguments来配置训练参数。其中包括了训练的轮数、每批次的大小、模型保存路径等信息。最后,我们使用Trainer类来训练模型。在这里,我们将输入数据传递给train_dataset参数,并使用一个data_collator函数将输入数据打包成一个批次.
在训练完成后,我们可以使用ChatGPT模型来生成文本。在Hugging Face的Transformers库中,我们可以使用pipeline来实现文本生成.
以下是使用ChatGPT模型生成文本的代码:
from
transformers
import
pipeline
generator
= pipeline(
'
text-generation
'
, model=model, tokenizer=
tokenizer)
def
generate_text(prompt):
outputs
= generator(prompt, max_length=1024, do_sample=True, temperature=0.7
)
generated_text
= outputs[0][
'
generated_text
'
]
return
generated_text
generated_text
= generate_text(
'
Hello, how are you?
'
)
print
(generated_text)
在上述代码中,我们首先使用pipeline函数来初始化一个文本生成器,其中指定了ChatGPT模型和tokenizer。接下来,我们定义了generate_text函数来使用生成器生成文本。在这里,我们传入一个prompt字符串作为生成的起始点,并使用max_length参数来指定生成文本的最大长度,使用do_sample和temperature参数来控制文本的随机性和流畅度.
ChatGPT是一个强大的自然语言生成模型,可以用于生成对话、推荐、文本摘要等多种任务。在本文中,我们介绍了ChatGPT的原理、实现流程和应用场景,并提供了Cornell电影对话数据集的预处理和ChatGPT模型的训练代码。通过使用Hugging Face的Transformers库,我们可以轻松地构建和训练ChatGPT模型,并使用pipeline来生成文本。希望本文能够帮助读者更好地理解ChatGPT,以及如何应用自然语言生成技术来解决实际问题.
因为,GPT3 API里面单次交互最多支持4000多个token(https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them) 。

因此,我猜测ChatGPT的上下文大概也是4000个token左右.
最后此篇关于基于ChatGPT用AI实现自然对话的文章就讲到这里了,如果你想了解更多关于基于ChatGPT用AI实现自然对话的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
34
4
 0
0
更新:下面提到的stackoverflow给出了另一种解决方案,即导入json并用正确格式的数据替换文本。我现在试图看看如何适应给定的格式,它看起来像这样: { "text" : "use
有谁知道三者之间的具体区别和功能,或者作为开发人员是否有更多功能/更灵活地使用? 最佳答案 wit.ai 与 Dialogflow 与 luis.ai ╔═══════════════════════
我知道 Wit.ai 引擎可以通过手动验证案例来训练,但是有没有办法用一组定义的输入和输出来训练它? 最佳答案 您可能可以查看其中一个应用程序的导出格式并对其进行调整以导入新应用程序。 https:/
来自 wit.ai 团队的一些人请回答这个 我们计划将 wit.ai 用于商业目的。有使用政策吗?请提供一些注意事项指南。此外,这项服务将来是否也是免费的,还是您计划推出企业版? 主要是 API 命中
我需要添加一个确认实体,以便在对话框流 (api.ai) 中的某个操作的参数中得到"is"或“取消”。假设用户正在购买咖啡,我会询问有关咖啡和数量的详细信息,最后我需要确认,我应该向哪个实体申请?任何
谁能帮我解决上面的问题。我们必须在数组 (a1,a2),(a1,a3),(a1,a4).... 等中找到元素的组合,然后选择满足条件 (ai*aj) <= max 的组合(A) 其中 A 是数组并返回
我正在尝试训练我的 Wit.ai 机器人以识别某人的名字。我不太确定我是否完全理解 NLP 的工作原理,所以我会给你一个例子。 我定义了很多表达,比如“我的名字是XXXX”、“大家都叫我XXXX” 在
我想知道是否存在一个网站,人们可以上传他们的 AI 在不同的棋盘游戏中相互竞争:国际象棋、五子棋等。 该站点将接受程序的源代码(以某种通用语言编写)、对其进行编译并相互运行程序。所有程序都必须使用一些
大家好,我是程序员幽鬼。 你想为后代开发一个令人难以置信的应用程序,你想到的第一件事——人工智能!还有什么比模仿人类智能的机器更令人着迷的呢?如果你期待打破刻板印象并准备推出出色的 AI 应用
我在 Application Insights Analytics 中创建了几个查询来获取我想要的图表。 示例: customEvents | where timestamp >= ago(31d)
我似乎无法让这个请求生效: https://wit.ai/docs/http/20160526#delete--entities-:entity-id-values-link 我已经设置了一个值为“C
我正在尝试在 wit.ai 中编写示例应用程序。我使用在 https://wit.ai/docs/quickstart 中显示的 node.js 客户端跟随快速启动应用程序。 .那里显示的示例只有一个
在 api.i(dialogflow) 中,我想获取用户的输入,如姓名、年龄、邮件等,并使用 PHP 将它们存储在我的 MYSQL 数据库中。 如何在对话流中生成我的代理的公共(public) API
我目前正在与 Wit.ai 合作 webpage in CodePen.io .我想知道是否可以使用 HTTP API 检索 Wit.ai 机器人的文本响应(“Bot says”)。 例如:如果用户要
我接到了一项任务,要编写一个由人类玩家和 AI 玩家组成的 NIM 游戏。游戏是“Misere”(最后一个必须拿起一根棍子的人输了)。 AI 应该使用 Minimax 算法,但它正在采取使其输得更快的
为了通过 shell 从端点取消部署模型,我必须指定 deployed-model-id如 gcloud ai endpoints undeploy-model 中所述 我如何获得这个已部署的模型 I
我在谷歌的 Vertex AI 中运行自定义训练作业。执行自定义作业的简单 gcloud 命令将使用类似于以下语法的内容(可以查看命令的完整文档 here ): gcloud beta ai cust
Wit AI project 在他们的 Converse 功能中添加了一个名为 Story 的新概念。有没有办法通过 HTTP API 管理(创建/编辑/验证)这些 Wit AI 故事? 最佳答案 W
我想为 Google 智能助理部署一个应用。但是,我想使用不同的 AI 后端而不是 api.ai。 有人知道这是否可能吗?如何? 或者如果我想使用 Google 智能助理,我会被 api.ai 困住吗
我的项目有一个依赖项,需要 python v3.6+。因此,它会在通过 pip 在 python 3 内核中安装时抛出错误,因为 AI Platform Notebooks 默认附带 v3.5。如何使

我是一名优秀的程序员,十分优秀!