
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 31
31
 4
4


书接上文《 GPT接入企微应用 - 让工作快乐起来 》,我把GPT接入了企微应用,不少同事都开始尝试起来了。有的浅尝辄止,有的刨根问底,五花八门,无所不有。这里摘抄几份:
“帮我写一份表白信,我们是大学同学,暗恋十年” 。
”顺产后多久可以用收腹带?生完宝宝用收腹带好还是不用好“ (背景:公司主营月子中心, 护理相关的领域知识是公司对于护士培训的重点内容 ) 。
”我的工资是多少“ (这个有点强机器人所难了,不过如果机器人有了公司的人事语料数据,应该是可以回答的) 。
...... 。
总的来说,除了一些尝鲜,猎奇之外,有相当一部分还是咨询公司的内部的相关信息,比如HR方面的育儿假等,再就是母婴护理方面的问题了(公司有近60%的是护理人员,日常工作就是与宝宝,宝妈一起,这就不奇怪了).
看到这些问题后,我就开始尝试通过Fine-tune训练公司内部的护理机器人,希望他可以为护士们的工作带来一些便利。诸多尝试失败后,索性就放了一些时间.
恰逢五一假,回了媳妇娘家,掐指一算,已经3年6个月没有回来过了,二娃子都快3岁了,还没见过外婆。想不到娃子亲舅舅,我到清闲了,又捡起护理机器人捣鼓起来了。于是有了这篇文章.
刚看到Fine-tune的介绍时就想,如果通过fine-tune构建个性化的模型,导入公司的母婴护理知识,并且在未来了问答中进化,变成企业内部专家。所以一开始就是向这样的路子摸索着。毕竟介绍里也说了通过少量样本即可完成训练,分类这样的任务可能只需要200个左右的样本即可。(其实问答模型的样本要求至少要有几千个可能会有点效果) 。

。
当然,文档中也有一些关于Fine-tune的一些指南和准则。一来是全是英文文档,理解不太深入;二来就是无知无畏,不尝试下就是不死心。这是文档原文,大概的意思Fine-tune可以用来解决一些类似分类(判断对错,情绪判断(乐观,悲观),邮件分类),以及扩写总结之类的场景。 文档也有提到案例”Customer support chatbot“,这可能也是大家这样尝试的原因之一吧。 在其demo推荐使用 emebedding 来实现,也是本文的重点内容。这是后 。
虽然通过Fine-tune的方式最终也没有好的效果,一来可能是样本太少,或者样本质量不好;也或者过程中有疏漏的地方。在这里也和大家一起探讨下。毕竟fine-tune的方式还是让人非常神往的。实现代码基本是参考了 openai-cookbook 中的 fine-tuned_qa Demo。大致流程如入:
1, 文本分段 - 因为拿到的资料是word,并且有标题,就直接根据标题他分段了,超过2048的再分一次,代码如下( 现学现用, 比较粗漏) 。
import docx import pandas as pd 。
def getText(fileName): doc = docx.Document(fileName) TextList = [] 。
data = {"title":"","content":""} for paragraph in doc.paragraphs: if paragraph.style.name == 'Heading 1': print("title %s " % paragraph.text) if (len(data['content']) > 0): datax = {} datax['title'] = data['title'] datax['content'] = data['content'] 。
TextList.append(datax) data['title'] = paragraph.text data['content'] = '' else: data['content'] += paragraph.text+"\n" TextList.append(data) return TextList 。
## 根据doc 转 csv if __name__ == '__main__': fileName = '/Users/jijunjian/openai/test2.docx' 。
articList = getText(fileName) count = 0 for article in articList: if len(article['content']) > 800: print("%s,%s,\n%s" % (article['title'], len(article['content']),article['content'])) count += 1 。
header = ['title', 'content'] print("总共 %s 篇文章" % count) pd.DataFrame(articList, columns=header).to_csv('data_oring.csv', index=False, encoding='utf-8') 。
。
2,生成问题与答案 - 这样生成的质量可能不是太高,可能实际使用时还是要对生成的问题和答案,让领域专家进行修正比较好.
据官方文档介绍,建议生成的数据集中,prompt与completion都要有固定的结尾,且尽量保证其他地方不会出现这个,所以我们这里使用了”\n\n###\n\n“作为结束标志.
1
import pandas
as
pd
2
import openai
3
import sys
4
sys.path.append(
"
..
"
)
5
from
tools.OpenaiInit import openai_config
6
from
transformers import GPT2TokenizerFast
7
8
9
tokenizer = GPT2TokenizerFast.from_pretrained(
"
gpt2
"
)
10
11
def count_tokens(text: str) ->
int
:
12
"""
count the number of tokens in a string
"""
13
return
len(tokenizer.encode(text))
14
15
16
COMPLETION_MODEL =
"
text-davinci-003
"
17
FILE_TUNE_FILE =
"
search_data.jsonl
"
18
19
20
# 获取训练数据
21
def get_training_data():
22
file_name =
"
data_oring.csv
"
23
df =
pd.read_csv(file_name)
24
df[
'
context
'
] = df.title +
"
\n\n
"
+
df.content
25
print(f
"
{len(df)} rows in the data.
"
)
26
return
df
27
28
29
# 根据内容,生成问题
30
def get_questions(context):
31
print(
"
正在生成问题
"
)
32
try
:
33
response =
openai.Completion.create(
34
engine=
COMPLETION_MODEL,
35
prompt=f
"
基于下面的文本生成问题\n\n文本: {context}\n\n问题集:\n1.
"
,
36
temperature=
0
,
37
max_tokens=
500
,
38
top_p=
1
,
39
frequency_penalty=
0
,
40
presence_penalty=
0
,
41
stop=[
"
\n\n
"
]
42
)
43
return
response[
'
choices
'
][
0
][
'
text
'
]
44
except Exception
as
e:
45
print(
"
创建问题错误 %s
"
%
e)
46
return
""
47
48
49
# 根据问题,生成答案
50
def get_answers(row):
51
print(
"
正在生成答案
"
)
52
try
:
53
response =
openai.Completion.create(
54
engine=
COMPLETION_MODEL,
55
prompt=f
"
基于下面的文本生成答案\n\n文本: {row.context}\n\n问题集:\n{row.questions}\n\n答案集:\n1.
"
,
56
temperature=
0
,
57
max_tokens=
500
,
58
top_p=
1
,
59
frequency_penalty=
0
,
60
presence_penalty=
0
61
)
62
return
response[
'
choices
'
][
0
][
'
text
'
]
63
except Exception
as
e:
64
print (e)
65
return
""
66
67
68
# 获取训练数据 /Users/jijunjian/
tuningdata.xlsx
69
if
__name__ ==
'
__main__
'
:
70
openai_config()
71
df =
get_training_data()
72
df[
'
tokens
'
] =
df.context.apply(count_tokens)
73
# questions 根据返回生成
74
df[
'
questions
'
]=
df.context.apply(get_questions)
75
df[
'
questions
'
] =
"
1.
"
+
df.questions
76
77
df[
'
answers
'
]= df.apply(get_answers, axis=
1
)
78
df[
'
answers
'
] =
"
1.
"
+
df.answers
79
df = df.dropna().reset_index().drop(
'
index
'
,axis=
1
)
80
81
print(
"
正在保存数据
"
)
82
df.to_csv(
'
nursing_qa.csv
'
, index=
False)
83
84
85
86
df[
'
prompt
'
] = df.context +
"
\n\n###\n\n
"
87
df[
'
completion
'
] =
"
yes\n\n###\n\n
"
88
89
df[[
'
prompt
'
,
'
completion
'
]].to_json(FILE_TUNE_FILE, orient=
'
records
'
, lines=
True)
90
91
search_file =
openai.File.create(
92
file=
open(FILE_TUNE_FILE),
93
purpose=
'
fine-tune
'
94
)
95
qa_search_fileid = search_file[
'
id
'
]
96
print(
"
上传文件成功,文件ID为:%s
"
%
qa_search_fileid)
97
98
# file_id = file-Bv5gP2lAmxLL9rRtdaQXixHF
。
3,根据生成数据集,创建新的模型.
官方的demo,还有生成验证集,测试集,生成相识的文本,同样的问题与答案来增加一些对抗性,因为最终效果不太好,再是文档中有使用search 模块,但是这已经下线了,我用prompt-completion的数据结构模拟了下,也不知道有没有效果, 因为使用openai tools 创建模型可以有一些交互动作,也方便看一些执行结果,花费数据,这里就使用这这工具作了演示,执行一段时间后,可以通过”openai.Model.list()“查看我们创建的模型。当时大概有1000来个问题与答案,花费了0.78刀。(这是4月13尝试的,因为效果不好,结果一放就是半月有余了。时间真是如白驹过隙一般) 。
1
openai api fine_tunes.create -t
"
discriminator_train.jsonl
"
-v
"
discriminator_test.jsonl
"
--batch_size
16
--compute_classification_metrics --classification_positive_class yes --model ada --suffix
'
discriminator
'
2
3
Uploaded file
from
discriminator_train.jsonl: file-
5OeHx3bMDqk******
4
Uploaded file
from
discriminator_test.jsonl: file-
AnOiDwG1Oqv3Jh******
5
Created fine-tune: ft-
cQBMLPzqVNml1ZWqkGYQKUdO
6
Streaming events until fine-tuning
is
complete...
7
8
(Ctrl-C will interrupt the stream, but not cancel the fine-
tune)
9
[
2023
-
04
-
13
23
:
17
:
05
] Created fine-tune: ft-
cQBMLPz********
10
[
2023
-
04
-
13
23
:
17
:
22
] Fine-tune costs $
0.78
11
[
2023
-
04
-
13
23
:
17
:
23
] Fine-tune enqueued. Queue number:
3
最后,效果不太理想,一番尝试后,看到文档中的提示信息:
”Note: To answer questions based on text documents, we recommend the procedure in Question Answering using Embeddings . Some of the code below may rely on deprecated API endpoints .“ 于是借着五一的空闲,开始尝试emebedding 方式 了 。
GPT擅长回答训练数据中存在的问题,对于一些不常见的话题,或者企业内部的语料信息,则可以通过把相关信息放在上下文中,传给GPT,根据上下问进行回答。因为不同模型对于token的限制,以及Token本身的成本因素.
具体实现时,我们需要把文本信息Chunk(分块)并Embed(不知道如何翻译)得到一个值,收到问题时,同样进行Embed,找到最相近的Chunk,做为上下文传给GPT。官方文档如下: 。
Specifically, this notebook demonstrates the following procedure
一开始本想参考这个demo Question_answering_using_embeddings.ipynb 编写代码,后来有意无意看到使用llama_index的实现,并且对于语料信息格式无要求,就摘抄过来了,感谢代码的贡献者,节省了大家好些时间.
#!/usr/bin/env python
# coding=utf-8
from langchain import OpenAI
from llama_index import SimpleDirectoryReader, LangchainEmbedding, GPTListIndex,GPTSimpleVectorIndex, PromptHelper
from llama_index import LLMPredictor, ServiceContext
import gradio as gr
import sys
import os
os.environ["OPENAI_API_KEY"] = 'sk-fHstI********************'
#MODEL_NAME = "text-davinci-003"
MODEL_NAME = "ada:ft-primecare:*************"
def construct_index(directory_path):
max_input_size = 2048
num_outputs = 512
max_chunk_overlap = 20
chunk_size_limit = 600
prompt_helper = PromptHelper(max_input_size, num_outputs, max_chunk_overlap, chunk_size_limit=chunk_size_limit)
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0.7, model_name=MODEL_NAME, max_tokens=num_outputs))
documents = SimpleDirectoryReader(directory_path).load_data()
#index = GPTSimpleVectorIndex(documents, llm_predictor=llm_predictor, prompt_helper=prompt_helper)
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, prompt_helper=prompt_helper)
index = GPTSimpleVectorIndex.from_documents(documents, service_context=service_context)
index.save_to_disk('index.json')
return index
def chatbot(input_text):
index = GPTSimpleVectorIndex.load_from_disk('data/index.json')
response = index.query(input_text, response_mode="compact")
return response.response
if __name__ == '__main__':
iface = gr.Interface(fn=chatbot,inputs=gr.inputs.Textbox(lines=7, label="输入你的问题"),outputs="text",title="护理智能机器人")
## 用于生成数据, 放在docs文件夹下
##index = construct_index("docs")
iface.launch(share=True, server_name='0.0.0.0', server_port=8012)
使用了gradio 作为演示,效果如下,基本可以根据我们的内部培训资料中回复,美中不足的就是通过要10几秒才可以完成回复,至少比之前fine-tune有了很大的进步了。至此,总算可以安抚下这半月的苦恼了。(下图中的output 如果变成自定义的文本,尝试多次一起没有成功,也是有点遗憾) 。
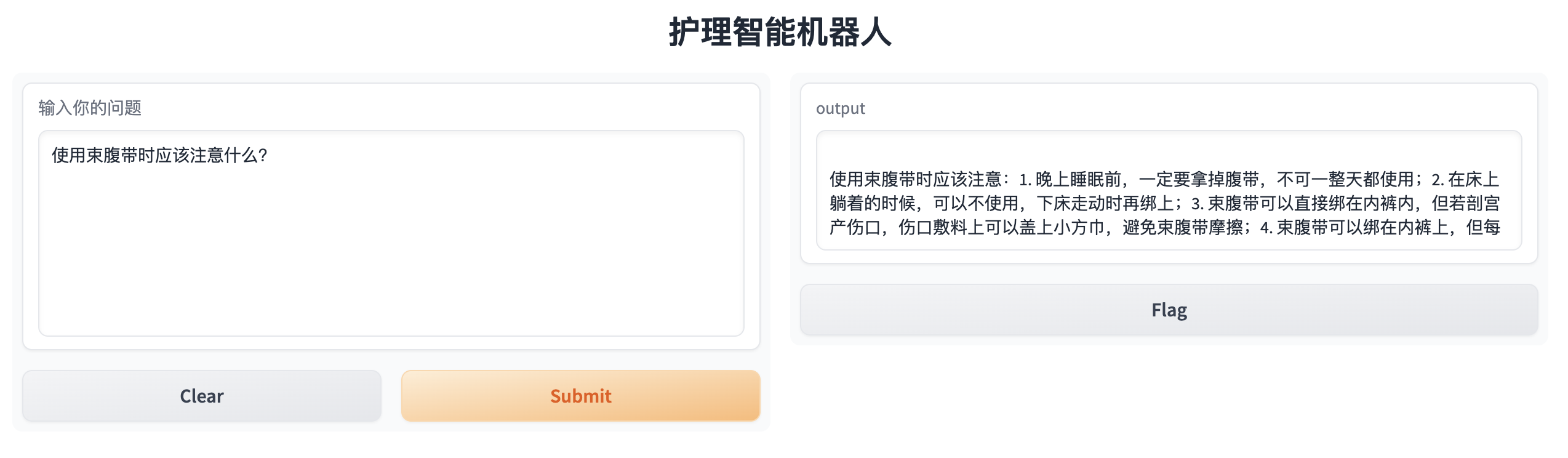
。
。
孟子有云:独乐乐不如众乐乐。如何让同事们一起体验,又是一个艰巨任务开始了。再则也需要让护理专家们看看回复的质量,以及如何优化文本内容。原本以为部署是一件简答的事儿,但是对于python菜-鸡的我,每一步都是坎坷.
一开始以为直接用pyinstaller 打包就可以直接放在服务器上执行,结果 pyinstaller -F, -D 尝试很久都无法打包依赖, --hidden-import 也用了, .spec也用了,都不好使。索性放弃了.
到了晚上12点半时,毫无进展,索性直接放原在码放上去。结果又提示无法安装指定版本的langchain。然后开始捣腾pip版本升级到最新,python版本升级到3.10.4(和本地一样).
python升级后,又是提示ModuleNotFoundError: No module named '_bz2',总算是错误信息变了。这个错误大概就是原来自带中的版本中有_bz2模块,重安装的3.10中没有,解决版本都是复制这个文件到新的版本中.
mv _bz2.cpython-36m-x86_64-linux-gnu.so /usr/local/python/lib/python3.
10
/lib-dynload/_bz2.cpython-
310
-x86_64-linux-gnu.so
。
再次运行终于启动了,太不容易了。配置好防火墙,腾讯云的安全组, 输入外网ip:8012,潇洒的一回车 - 还是无法访问。 借用毛爷爷的一句话描述下当下的心情:它是站在海岸遥望海中已经看得见桅杆尖头了的一只航船,它是立于高山之巅远看东方已见光芒四射喷薄欲出的一轮朝日,它是躁动于母腹中的快要成熟了的一个婴儿。加之夜确实太深了,才踏实的睡下了.
1
/usr/local/python/lib/python3.
10
/site-packages/gradio/inputs.py:
27
: UserWarning: Usage of gradio.inputs
is
deprecated, and will not be supported
in
the future, please import your component
from
gradio.components
2
warnings.warn(
3
/usr/local/python/lib/python3.
10
/site-packages/gradio/deprecation.py:
40
: UserWarning: `optional` parameter
is
deprecated, and it has no effect
4
warnings.warn(value)
5
/usr/local/python/lib/python3.
10
/site-packages/gradio/deprecation.py:
40
: UserWarning: `numeric` parameter
is
deprecated, and it has no effect
6
warnings.warn(value)
7
Running on local URL: http:
//127
.0.0.1:8012
8
Running on
public
URL: https:
//
11d5*****.gradio.live
第二天,找到gradio 中Interface.launch 的参数有个 server_name 设置成 通过设置server_name=‘0.0.0.0’ 即可通过IP访问。 通过ss -tnlp | grep ":8012" 也可以看到端口的监听从 ”127.0.0.1:8012“ 就成了 ”0.0.0.0:8012 “.
LISTEN
0
128
0.0
.
0.0
:
8012
0.0
.
0.0
:* users:((
"
python
"
,pid=
2801254
,fd=
7
))
。
。
展望一下 。
从目前测试的情况来,每问一个问题成本在10美分左右(成本还是比较高),优化的方向可能Chunk的大小,太小无法包含住够的上下问,太大成本又比较高。再回头看Fine-tune的方式,应该是前期训练话费的成本会比较高,后期回答的成本会比较少,只是目前训练效果不太好,看其他文章也是同样的问题。从目前的情况来可能 emebedding的是一个较为合适的落地方式.
接下看看使用的情况,如果效果不错,考虑增加语音转文字,用GPT回复答案,甚至可以再文字转语音播报出来,这样护士们的工作可能会更加便利与快乐了.
成为一名优秀的程序员! 。
最后此篇关于GPT护理机器人-让护士的工作变简单的文章就讲到这里了,如果你想了解更多关于GPT护理机器人-让护士的工作变简单的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
31
4
 0
0
我在Windows 10中使用一些简单的Powershell代码遇到了这个奇怪的问题,我认为这可能是我做错了,但我不是Powershell的天才。 我有这个: $ix = [System.Net.Dn
var urlsearch = "http://192.168.10.113:8080/collective-intellegence/StoreClicks?userid=" + userId +
我有一个非常奇怪的问题,过去两天一直让我抓狂。 我有一个我试图控制的串行设备(LS 100 光度计)。使用设置了正确参数的终端(白蚁),我可以发送命令(“MES”),然后是定界符(CR LF),然后我
我目前正试图让无需注册的 COM 使用 Excel 作为客户端,使用 .NET dll 作为服务器。目前,我只是试图让概念验证工作,但遇到了麻烦。 显然,当我使用 Excel 时,我不能简单地使用与可
我开发了简单的 REST API - https://github.com/pavelpetrcz/MandaysFigu - 我的问题是在本地主机上,WildFly 16 服务器的应用程序运行正常。
我遇到了奇怪的情况 - 从 Django shell 创建一些 Mongoengine 对象是成功的,但是从 Django View 创建相同的对象看起来成功,但 MongoDB 中没有出现任何数据。
我是 flask 的新手,只编写了一个相当简单的网络应用程序——没有数据库,只是一个航类搜索 API 的前端。一切正常,但为了提高我的技能,我正在尝试使用应用程序工厂和蓝图重构我的代码。让它与 pus
我的谷歌分析 JavaScript 事件在开发者控制台中运行得很好。 但是当从外部 js 文件包含在页面上时,它们根本不起作用。由于某种原因。 例如; 下面的内容将在包含在控制台中时运行。但当包含在单
这是一本名为“Node.js 8 the Right Way”的书中的任务。你可以在下面看到它: 这是我的解决方案: 'use strict'; const zmq = require('zeromq
我正在阅读文本行,并创建其独特单词的列表(在将它们小写之后)。我可以使它与 flatMap 一起工作,但不能使它与 map 的“子”流一起工作。 flatMap 看起来更简洁和“更好”,但为什么 di
我正在编写一些 PowerShell 脚本来进行一些构建自动化。我发现 here echo $? 根据前面的语句返回真或假。我刚刚发现 echo 是 Write-Output 的别名。 写主机 $?
关闭。这个问题不满足Stack Overflow guidelines .它目前不接受答案。 想改善这个问题吗?更新问题,使其成为 on-topic对于堆栈溢出。 4年前关闭。 Improve thi
我将一个工作 View Controller 类从另一个项目复制到一个新项目中。我无法在新项目中加载 View 。在旧项目中我使用了presentModalViewController。在新版本中,我
我对 javascript 很陌生,所以很难看出我哪里出错了。由于某种原因,我的功能无法正常工作。任何帮助,将不胜感激。我尝试在外部 js 文件、头部/主体中使用它们,但似乎没有任何效果。错误要么出在
我正在尝试学习Flutter中的复选框。 问题是,当我想在Scaffold(body :)中使用复选框时,它正在工作。但我想在不同的地方使用它,例如ListView中的项目。 return Cente
我们当前使用的是 sleuth 2.2.3.RELEASE,我们看不到在 http header 中传递的 userId 字段没有传播。下面是我们的代码。 BaggageField REQUEST_I
我有一个组合框,其中包含一个项目,比如“a”。我想调用该组合框的 Action 监听器,仅在手动选择项目“a”完成时才调用。我也尝试过 ItemStateChanged,但它的工作原理与 Action
你能看一下照片吗?现在,一步前我执行了 this.interrupt()。您可以看到 this.isInterrupted() 为 false。我仔细观察——“这个”没有改变。它具有相同的 ID (1
我们当前使用的是 sleuth 2.2.3.RELEASE,我们看不到在 http header 中传递的 userId 字段没有传播。下面是我们的代码。 BaggageField REQUEST_I
我正在尝试在我的网站上设置一个联系表单,当有人点击发送时,就会运行一个作业,并在该作业中向所有管理员用户发送通知。不过,我在失败的工作表中不断收到此错误: Illuminate\Database\El

我是一名优秀的程序员,十分优秀!