
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 28
28
 4
4


@ 。
Apache Ozone 官网地址 https://ozone.apache.org/ 最新版本1.3.0 。
Apache Ozone 官网最新文档地址 https://ozone.apache.org/docs/1.3.0/ 。
Apache Ozone 源码地址 https://github.com/apache/ozone 。
Apache Ozone是一个高度可扩展、冗余的分布式对象存储,适用于分析、大数据和云原生应用,以在Kubernetes等容器化环境中有效地工作。Ozone支持S3兼容的对象API以及Hadoop兼容的文件系统实现。它针对高效的对象存储和文件系统操作进行了优化。建立高可用性、可复制的块存储层的Hadoop分布式数据存储(Hadoop Distributed Data Store, hds),像Apache Spark, Hive和YARN这样的应用程序在使用Ozone时无需任何修改即可工作;Ozone附带了一个Java客户端库、S3协议支持和一个命令行接口.
Apache Ozone 可与Cloudera 数据平台(CDP) 一起使用,可以扩展到数十亿个不同大小的对象。它被设计为原生的对象存储,可提供极高的规模、性能和可靠性,以使用 S3 API 或传统的 Hadoop API 处理多个分析工作负载。Ozone其发展是准备替代HDFS的下一代的大数据存储系统,着力要解决的目前HDFS存在的问题如NameNode的扩展性和小文件的性能问题.
先回顾一下HDFS,HDFS通过把文件系统元数据全部加载到数据节点Namenode内存中,给客户端提供了低延迟的元数据访问。由于元数据需要全部加载到内存,所以一个HDFS集群能支持的最大文件数,受Java堆内存的限制,上限大概是4亿~5亿个文件。所以HDFS适合大量大文件[几百兆字节(MB)以上]的集群,如果集群中有非常多的小文件,HDFS的元数据访问性能会受到影响。虽然可以通过各种Federation技术来扩展集群的节点规模,但单个HDFS集群仍然没法很好地解决小文件的限制.
Ozone是新一代的对象存储系统,其架构设计简单的可以总结为:
Ozone目前社区开发比较活跃;架构比较合理,在扩展性和小文件方面优异;其设计目标和应用场景也比较明确清晰:弥补HDFS的缺陷,替换HDFS在大数据领域的地位.
Ozone主要设计要点是可扩展性,它的目标是扩展到数十亿个对象;Ozone将命名空间管理和块空间管理分开;命名空间由名为Ozone Manager (OM)的守护进程管理,块空间由Storage Container Manager (SCM)管理。Ozone命名空间由多个存储体组成。存储卷也被用作存储会计的基础;Ozone由volumes、buckets、keys组成:
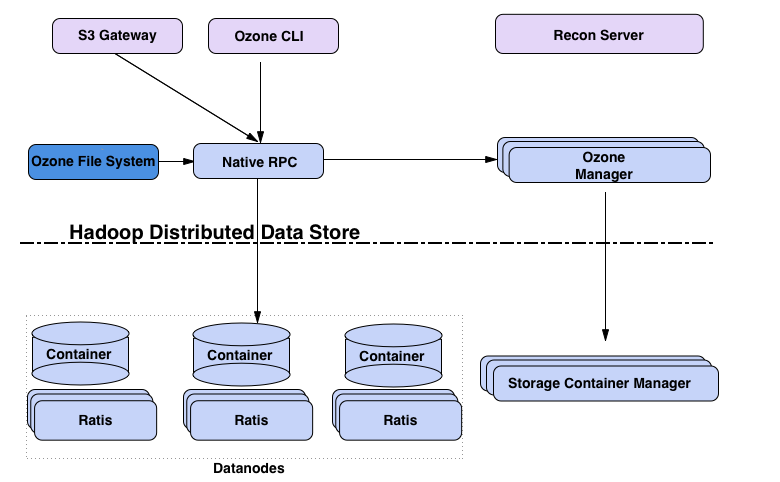
Ozone的核心组件:
客户端 :S3 Gateway 提供 s3 协议的客户端,Ozone FileSystem为兼容HDFS的文件系统客户端.
元数据服务器 。
数据服务器 :Datanodes用于存储数据,Containers就是block的集合,用于存储数据,其分布在Data Node上。所有数据都存储在数据节点上。客户端以块的形式写数据。Datanode将这些块聚合到一个存储容器中。存储容器是客户端写的关于块的数据流和元数据.
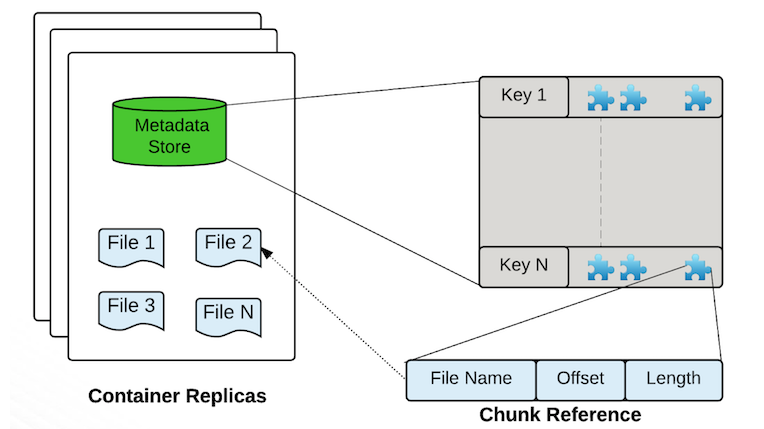
Containers是Ozone/ hdd的基本复制单元,它们由存储容器管理器(SCM)服务管理。容器是大的二进制存储单元(默认为5Gb),可以包含多个块,Container是数据复制(data replication)的基本单位.
| Open | Close |
|---|---|
| mutable (不能删除,可追加写) | Immutable (可以删除,不能追加写) |
| replicated with RAFT(Ratis) (写操作是通过 raft协议复制完成) | replicated with async container copy (删除操作和数据修复操作不需要raft协议) |
| Raft leader is used to READ/WRITE (写操作需要通过Leader,只能通过Leader读写) | All the nodes can be used to READ (所以节点都可以读) |
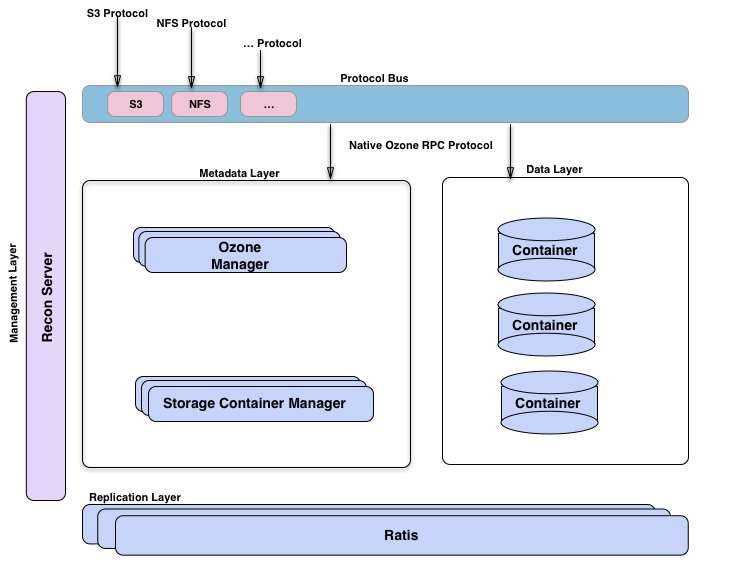
Recon Server :系统监控和管理 。
Ozone管理器是名称空间管理器,存储容器管理器管理物理层和数据层,Recon是Ozone的管理接口。从另一个的视角来看Ozone,将其想象为构建在hdd(一个分布式块存储)之上的名称空间服务的Ozone Manager。可视化臭氧的方法是观察功能层;这里有元数据管理层,由Ozone管理器和存储容器管理器组成。数据存储层基本上是数据节点,由SCM管理。由Ratis提供的复制层用于复制元数据(OM和SCM),也用于在数据节点上修改数据时保持一致性。Recon管理服务器与Ozone的所有其他组件进行通信,并为Ozone提供统一的管理API和用户体验。协议总线允许通过其他协议扩展Ozone。目前只有通过协议总线构建的S3协议支持。协议总线提供了一个通用概念,可以实现调用O3 Native协议的新文件系统或对象存储协议。Apache Ratis是开源的java版的raft协议的实现。对于数据和元数据都用了Raft协议来保障数据的一致性和高可用.
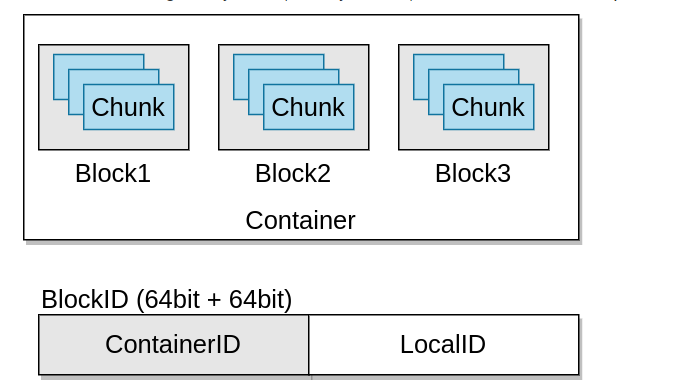
写入数据时,向Ozone管理器请求一个块,Ozone管理器会返回一个块并记住该信息 。
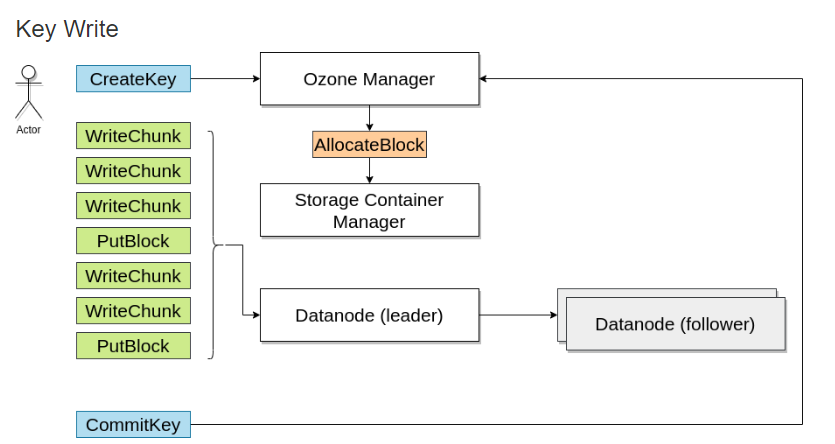
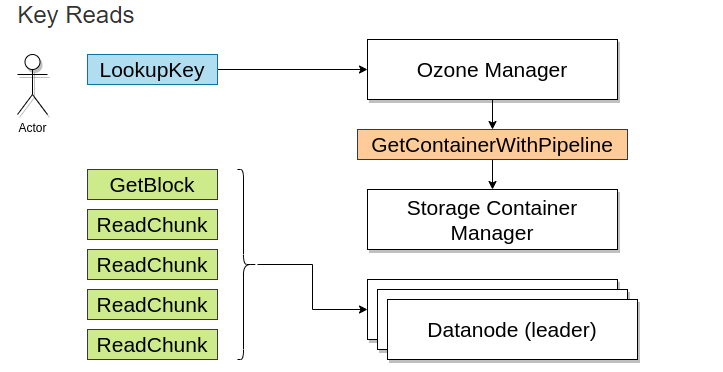
当读取该文件时,由Ozone Manager返回需要块的地址.
# 如果是用于开发测试,可以通过容器启动Ozone;启动一体化Ozone容器最简单的方法是从docker hub中使用最新的docker镜像,该容器将运行所需的元数据服务器(Ozone Manager、Storage container Manager)、一个数据节点和S3兼容的REST服务器(S3 Gateway)。
docker run -p 9878:9878 -p 9876:9876 apache/ozone

# 本地多容器集群,如果要部署伪集群,每个组件在自己的容器中运行,则可以使用docker-compose启动,从docker hub中的映像中提取这些文件
docker run apache/ozone cat docker-compose.yaml > docker-compose.yaml
docker run apache/ozone cat docker-config > docker-config
# docker-compose启动集群
docker-compose up -d
# 如果需要多个数据节点,可以按比例扩展:
docker-compose up -d --scale datanode=3

访问Ozone Recon的控制台页面http://hadoop3:9888 ,查看概览可以看下Datanodes、Pipelines、Volumes、Buckets、Keys等,还可以查看数据节点信息 。
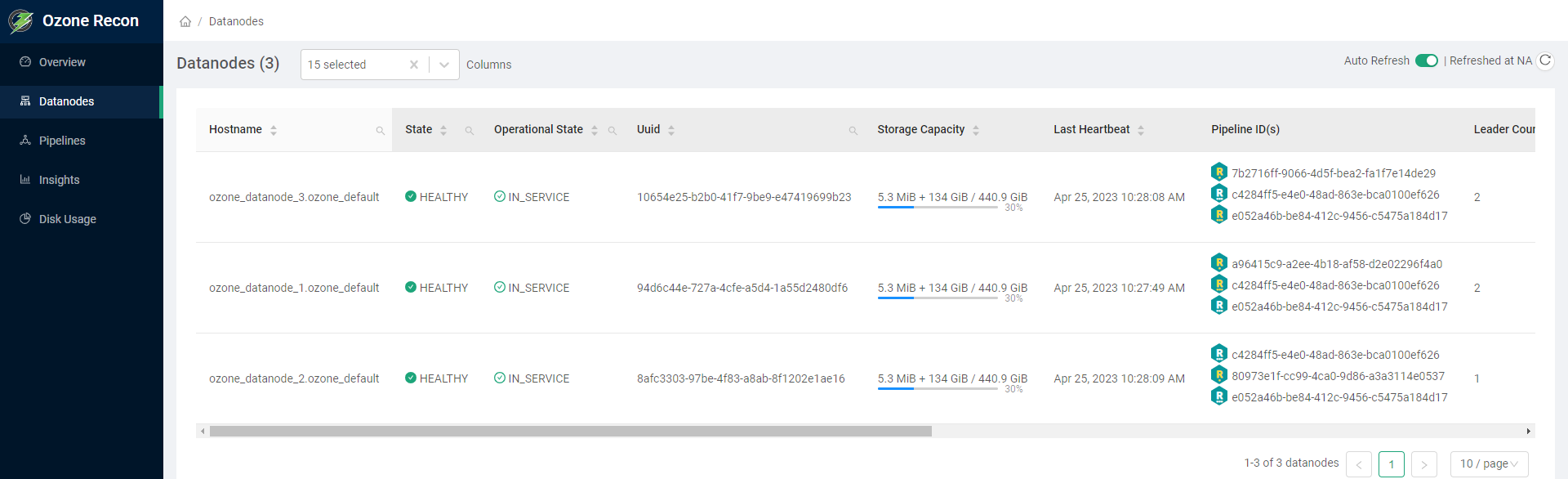
可以在一个真正的集群中设置臭氧,建立一个真正的集群,其组成部分 。
# 下载ozone最新版本的1.3.0
wget https://dlcdn.apache.org/ozone/1.3.0/ozone-1.3.0.tar.gz
# 解压文件
tar -xvf ozone-1.3.0.tar.gz
# 进入目录
cd ozone-1.3.0
# 配置文件位于ozone根目录下的etc/hadoop/ozone-site.xml
<property>
<name>ozone.metadata.dirs</name>
<value>/data/disk1/meta</value>
</property>
ozone.scm.names 。
<property>
<name>ozone.scm.names</name>
<value>scm.hadoop.apache.org</value>
</property>
ozone.scm.datanode.id.dir 。
<property>
<name>ozone.scm.datanode.id.dir</name>
<value>/data/disk1/meta/node</value>
</property>
ozone.om.address 。
<property>
<name>ozone.om.address</name>
<value>ozonemanager.hadoop.apache.org</value>
</property>
# scm初始化
ozone scm --init
# scm启动
ozone --daemon start scm
# om初始化
ozone om --init
# om启动
ozone --daemon start om
# 数据节点启动
ozone --daemon start datanode
# 简洁启动
ozone scm --init
ozone om --init
start-ozone.sh
Ozone shell是从命令行与Ozone交互的主要接口,其背后使用Java API。如果不使用ozone sh命令,就无法访问一些功能。例如
所有这些都是一次性的管理任务。应用程序可以使用其他接口,如Hadoop兼容文件系统(o3fs或ofs)或S3接口来使用臭氧,而不需要这个CLI.
# 查看卷的帮助ozone sh volume --help# 查看具体操作帮助ozone sh volume create --help# 创建卷ozone sh volume create /vol1# 查看卷信息ozone sh volume info /vol1# 列出卷ozone sh volume list /
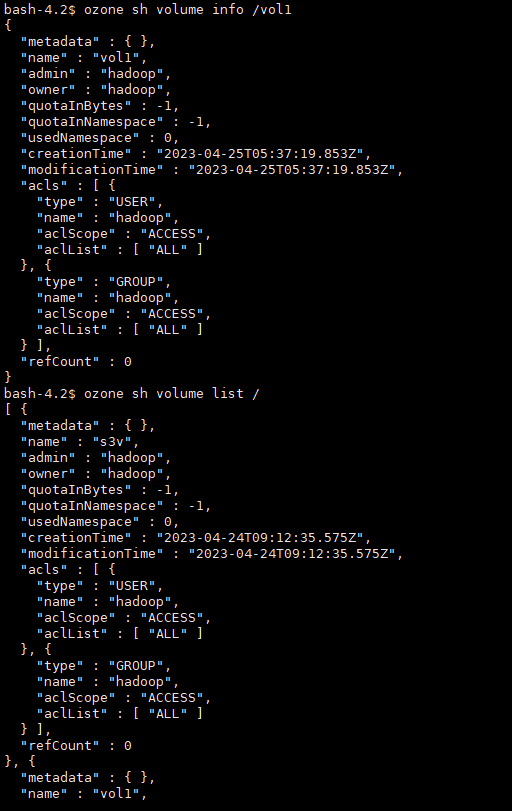
# 创建桶ozone sh bucket create /vol1/bucket1# 查看桶ozone sh bucket info /vol1/bucket1# 存储键数据ozone sh key put /vol1/bucket1/anaconda-post.log /anaconda-post.log# 查看键数据ozone sh key info /vol1/bucket1/anaconda-post.log# 读取键数据到本地ozone sh key get /vol1/bucket1/anaconda-post.log /data/
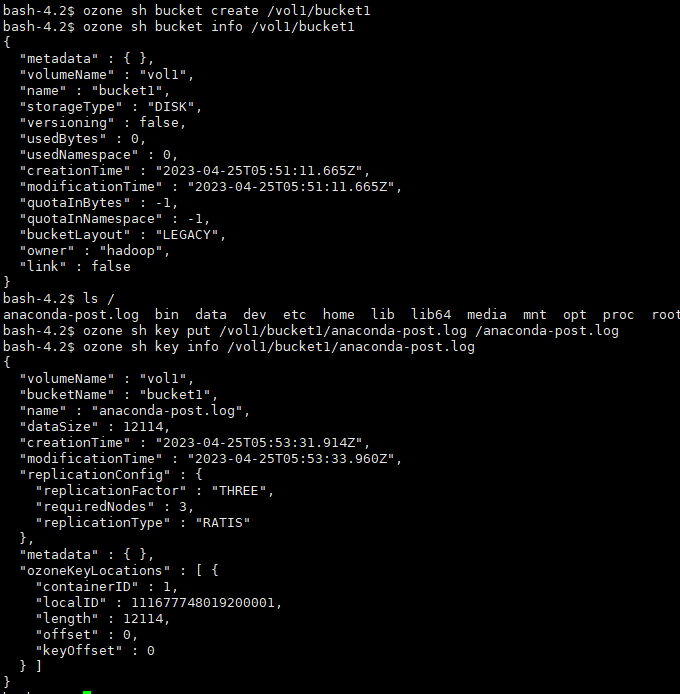
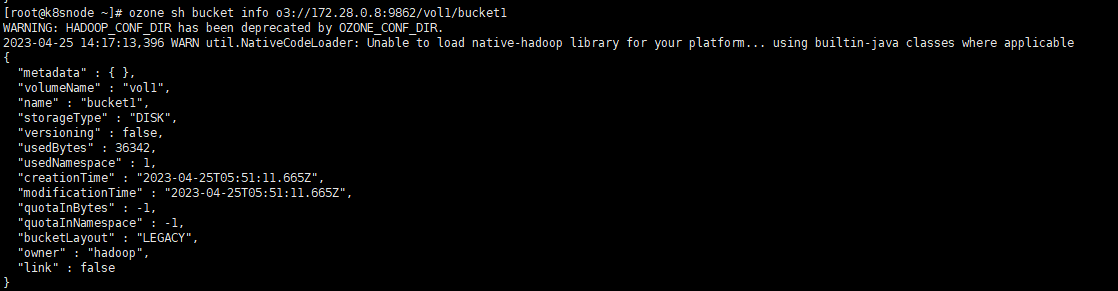
# 指定URLozone sh bucket info o3://172.28.0.8:9862/vol1/bucket1
Hadoop兼容的文件系统接口允许像Ozone这样的存储后端轻松集成到Hadoop生态系统中。Ozone文件系统是一个与Hadoop兼容的文件系统.
目前,Ozone支持o3fs://和ofs://两种方案。o3fs和ofs之间最大的区别在于,o3fs只支持单个桶上的操作,而ofs支持跨所有卷和桶的操作,并提供所有卷/桶的完整视图.
卷和挂载位于OFS文件系统的根级别。桶自然列在卷下。键和目录位于每个桶的下面。注意,对于挂载,目前只支持临时挂载/tmp.
请将下面内容添加到core-site.xml中.
<property> <name>fs.ofs.impl</name> <value>org.apache.hadoop.fs.ozone.RootedOzoneFileSystem</value></property><property> <name>fs.defaultFS</name> <value>ofs://hadoop3/</value></property>
将ozone- filessystem -hadoop3.jar文件添加到类路径中(注意如果使用Hadoop 2.X,使用ozone- filessystem -hadoop2-*.jar) 。
export HADOOP_CLASSPATH=/opt/ozone/share/ozone/lib/ozone-filesystem-hadoop3-*.jar:$HADOOP_CLASSPATH
设置了默认的文件系统,用户就可以运行ls、put、mkdir等命令.
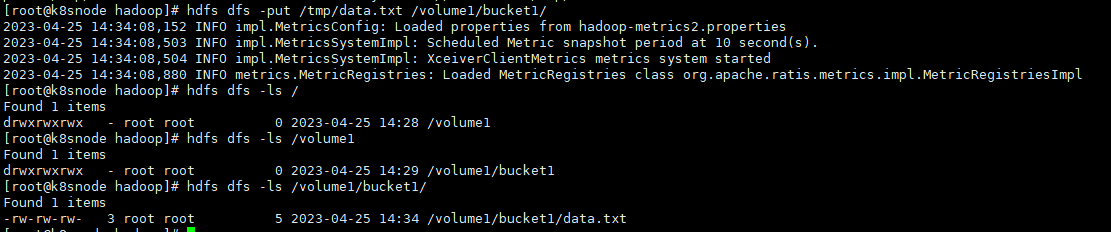
# 创建卷,也即是创建目录hdfs dfs -mkdir /volume1# 创建桶,也即是创建二级目录hdfs dfs -mkdir /volume1/bucket1# 写入数据文件hdfs dfs -put /tmp/data.txt /volume1/bucket1/# 查看文件hdfs dfs -ls /volume1/bucket1/
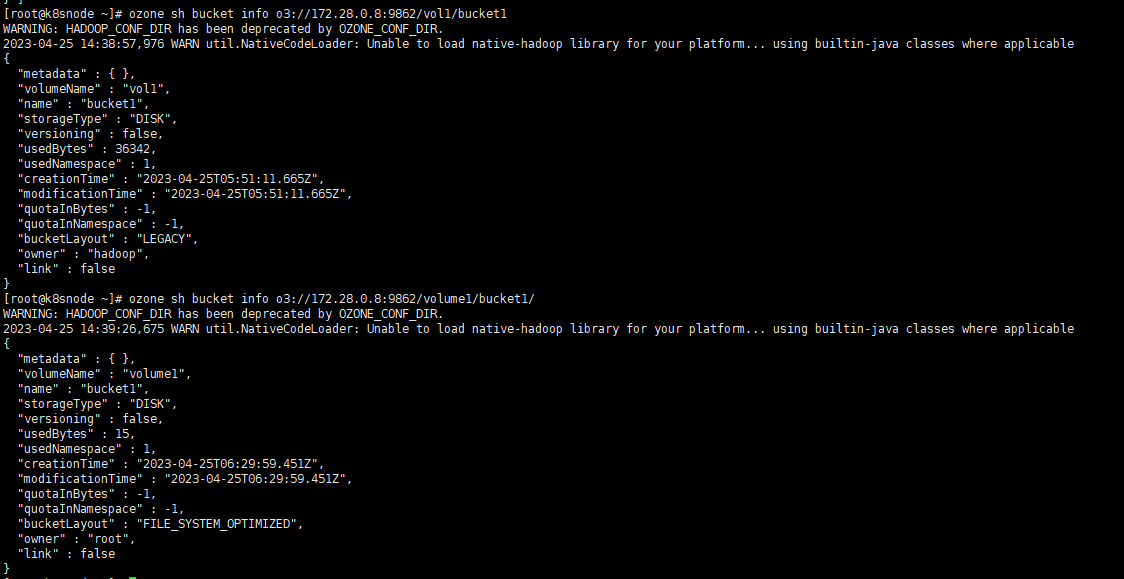
通过Ozone的shell也能查看对应的信息 。
# o3fshdfs dfs -ls o3fs://bucket.volume.cluster1/prefix/# ofshdfs dfs -ls ofs://cluster1/volume/bucket/prefix/
Recon API v1是一组HTTP端点,可帮助了解Ozone集群的当前状态,并在需要时进行故障排除.
标记为admin的端点只能由Ozone中指定的Kerberos用户访问。安全集群的Administrators或ozone.recon.administrators配置.
| Property | Value |
|---|---|
| ozone.security.enabled | true |
| ozone.security.http.kerberos.enabled | true |
| ozone.acl.enabled | true |
# 获取容器curl http://hadoop3:9888/api/v1/containers

这个相当于管理页面的后台接口 。

最后此篇关于下一代大数据分布式存储技术ApacheOzone初步研究的文章就讲到这里了,如果你想了解更多关于下一代大数据分布式存储技术ApacheOzone初步研究的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
28
4
 0
0
我即将在 uni 开始关于 OpenCL 的荣誉项目,以及如何使用它来改进现代游戏开发。我知道现在/很快有几本书关于学习 opencl,但我想知道是否有人知道关于 opencl 的任何好论文。 我一直
在 Web 开发领域,我听过很多博客,人们说用户倾向于忽略(或被激怒)华而不实/不必要的动画内容,对可用性产生不利影响,但是否有任何研究支持那个声明? 最佳答案 我找到了一对似乎符合您正在寻找的路线。
我对网络语音和音频不熟悉。 我一直在谷歌上搜索示例和解决方案来实现 p2p 语音连接(这个想法是音频 session )。 我发现 google talk xmpp 框架可以访问用户和文本聊天等信息。
我打算创建一个优化的数据结构来保存汇编代码。这样我就可以完全负责将在这个结构上工作的优化算法。如果我可以边运行边编译。这将是一种动态执行。这可能吗?有没有人见过这样的事情? 我应该使用结构将结构链接到
低代码开发平台 Mendix 最新发布的一份研究报告表明,疫情在全球范围内的扩散大大加速了对企业低代码的兴趣和使用。该报告基于来自美国、中国、英国、德国、比利时和荷兰的 1209 名 IT 专业人士
最常用的数值类型是int,但是它未必是最佳选择。bigint,smallint,tinyint可以应用在特殊场合。他们的特性如下表所示: Data type
我试图了解在使用 R 包 kernlab 中的命令 ksvm 时 SVM 预测函数是如何工作的。 我尝试使用以下命令查看预测函数: methods(class="ksvm") getAnywhere(
据我了解,XMPP 协议(protocol)基于始终在线的连接,您无法立即指示 XML 消息何时结束。 这意味着您必须在流来时对其进行评估。这也意味着,您可能必须处理异步连接,因为套接字可能会阻塞在
两天后,我发现自己正在考虑通过网站上的 ajax 请求实现流程自动化。我想做的是研究网站上执行的某些操作的一些请求,并用 javascript 复制它。例如,当我在剧院选择一些座位时,我有这个 POS
当我研究我没有编写的复杂 Java 代码时,我会定期在记事本中写下一些我对给定问题感兴趣的资源的调用堆栈。这些资源通常是方法或常量。 这是一个例子: CONSTANT_NAME com.com
我将为 Android 智能手机实现一个蜜 jar 作为我论文的研究。我从来没有使用过android、java和蜜 jar 。这就是我想开始的方式。我想到使用Honeyd的源代码(用C语言编写),Ho
Closed. This question does not meet Stack Overflow guidelines 。它目前不接受答案。 想改善这个问题吗?更新问题,使其成为 Stack Ov
晚上好。 我真的很难理解这个问题,我不确定我是否错过了一些非常愚蠢的东西,但这是我的代码和我的问题。 const question = new Map(); question.set('questio
关闭。这个问题是off-topic .它目前不接受答案。 想改进这个问题吗? Update the question所以它是on-topic用于堆栈溢出。 关闭 10 年前。 Improve thi
我想知道是否有人有任何关于编译/链接优化的好资源(论文/文章/书籍引用)。 我曾在两家以不同方式执行链接操作的公司工作。 第一公司强制代码采用严格的 DAG 结构,向我解释说使用强制树结构,链接时间非
关闭。这个问题不满足Stack Overflow guidelines .它目前不接受答案。 想改善这个问题吗?更新问题,使其成为 on-topic对于堆栈溢出。 7年前关闭。 Improve thi
我有 4 个文件想用 Python/Pandas 读取,这些文件是: https://github.com/kelsey9649/CS8370Group/tree/master/TaFengDataS
我正在尝试查找任何分析 Qt 和 Qt Creator 最新版本的研究/学术/期刊论文/文章。 具体来说,我试图从实时安全关键的角度评估 Qt,所以任何信息都是有帮助的。 附言我尝试了典型的搜索方法:
在 Main Wrapper 中,我有 5 个 Div。第一个 div 包含 4 个 Box(box_1, box_2,box_3,box_4),我的点击事件将在其中发生。 另外4个div在main
所以,我一直在用 Netbeans C++ 调试一个程序,我需要仔细查看 vector 的内容,以帮助我找出哪里出了问题。因此,我进入“变量”选项卡进行挖掘。问题是,Netbeans(或我使用过的任何

我是一名优秀的程序员,十分优秀!