
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 28
28
 4
4


论文标题:MEnsA: Mix-up Ensemble Average for Unsupervised Multi Target Domain Adaptation on 3D Point Clouds
论文作者:Ashish Sinha, Jonghyun Choi
论文来源:2023 CVPR
论文地址: download
论文代码:download
视屏讲解:click
单目标域和多目标域 。
单目标域和多目标域的差异:
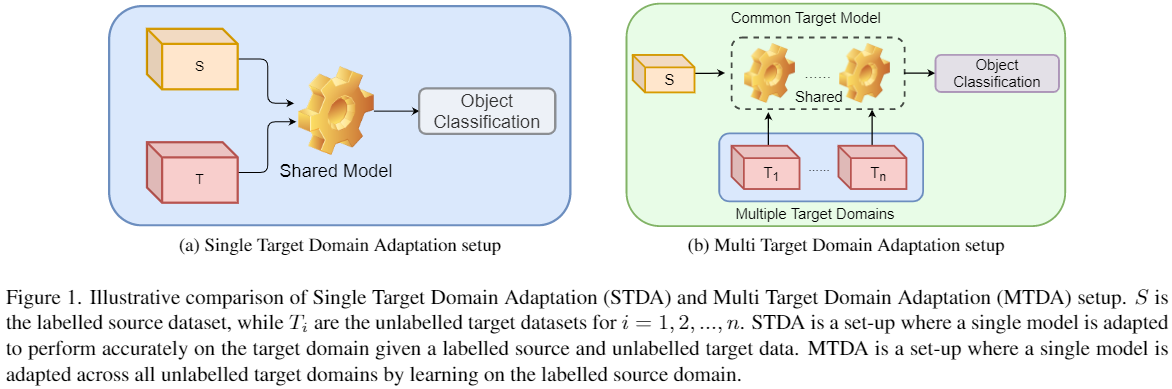

Mixup 模块:
$F_{i}^{m}=\lambda F_{s}+(1-\lambda) F_{T_{i}} \quad\quad(1)$ 。
$L_{i}^{m}=\lambda L_{s}+(1-\lambda) L_{T_{i}} \quad\quad(2)$ 。
线性差值的好处:

基线 :【多目标域场景下】 。
本文 :单源域 和 多目标域集成线性差值; 。
总损失:
$\mathcal{L}=\log \left(\sum\left(e^{\gamma\left(\mathcal{L}_{c l s}+\eta \mathcal{L}_{d c}+\zeta \mathcal{L}_{a d v}\right)}\right)\right) / \gamma \quad\quad(4)$ 。
其中:
源域分类损失: $\mathcal{L}_{c l s} =\mathcal{L}_{C E}\left(C\left(F_{s}\right), y_{s}\right) \quad\quad(4)$ 。
单源域单目标域鉴别损失:$\mathcal{L}_{d c} =\mathcal{L}_{C E}\left(D\left(F_{s}\right), L_{s}\right)+\mathcal{L}_{C E}\left(D\left(F_{T_{i}}, L_{T_{i}}\right)\right) \quad\quad(5)$ 。
对抗损失:$\mathcal{L}_{a d v} =\lambda_{1} \mathcal{L}_{m m d}+\lambda_{2} \mathcal{L}_{d c}+\lambda_{3} \mathcal{L}_{\text {mixup }} \quad\quad(6)$ 。
关于对抗损失:
MMD 损失:$\mathcal{L}_{m m d}=\mathcal{L}_{r b f}\left(C\left(F_{s}\right), F_{T_{i}}, \sigma\right) \quad\quad(7)$ 。
线性差值域鉴别损失:$\mathcal{L}_{\text {mixup }}=\mathcal{L}_{C E}\left(D\left(F_{m}^{M}\right), L_{i}^{m}\right) \quad\quad(8)$ 。
Note:
线性差值:
$F_{m}^{\text {factor }}=\lambda F_{s}+\sum_{i=1}^{n} \frac{1-\lambda}{n} F_{T_{i}}$ 。
$F_{m}^{\text {concat }}=\left[\lambda F_{s}, \frac{1-\lambda}{n} F_{T_{1}}, \ldots, \frac{1-\lambda}{n} F_{T_{n}}\right]$ 。
$.L_{m}^{\text {concat }}=[\lambda, 2 \frac{1-\lambda}{n}, \ldots, N \frac{1-\lambda}{n}]$ 。
$F_{m}^{T}=\lambda F_{T_{1}}+(1-\lambda) F_{T_{2}}$ 。
$L_{m}^{T}=\lambda L_{T_{1}}+(1-\lambda) L_{T_{2}} $ 。
。
最后此篇关于迁移学习(MEnsA)《MEnsA:Mix-upEnsembleAverageforUnsupervisedMultiTargetDomainAdaptationon3DPointClouds》的文章就讲到这里了,如果你想了解更多关于迁移学习(MEnsA)《MEnsA:Mix-upEnsembleAverageforUnsupervisedMultiTargetDomainAdaptationon3DPointClouds》的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
28
4
 0
0

我是一名优秀的程序员,十分优秀!