
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 34
34
 4
4


论文标题:Pairwise Adversarial Training for Unsupervised Class-imbalanced Domain Adaptation
论文作者:Weili Shi, Ronghang Zhu, Sheng Li
论文来源:KDD 2022
论文地址: download
论文代码:download
视屏讲解:click
提出问题:类不平衡问题; 。
解决方法:
In class-imbalanced domain adaptation, both the source and target domains suffer from label distribution shift. We are given a source domain $\mathcal{D}_{s}=\left\{\left(x_{i}^{s}, y_{i}^{s}\right)\right\}_{i=1}^{N_{s}}$ with $N^{s}$ labelled samples and a target domain $\mathcal{D}_{t}=\left\{x_{i}^{t}\right\}_{i=1}^{N_{t}}$ with $N^{t}$ unlabelled samples. Each domain contains $K$ classes, and the class label is denoted as $y^{S} \in\{1,2, \ldots, K\}$ . Let $p$ and $q$ denote the probability distributions of the source and target domains, respectively. We assume that both the covariate shift (i.e., $p(x) \neq q(x)$ ) and label distribution shift (i.e., $p(y) \neq q(y)$ and $p(x \mid y) \neq q(x \mid y)$) exist in two domains. The model typically consists of a feature extractor $g: \mathcal{X} \rightarrow \mathcal{Z}$ and a classifier $f: \mathcal{Z} \rightarrow \boldsymbol{y}$ . The predicted label $\hat{y}=f(g(x))$ and empirical risk is defined as $\epsilon=\operatorname{Pr}_{x \sim \mathcal{D}}(\hat{y} \neq y)$ , where $y$ is ground-truth label. The source error and target error are denoted as $\epsilon_{S}$ and $\epsilon_{T}$ , respectively. Our goal is to train a model that can reduce gap between source and target domains and minimize $\epsilon_{S}$ and $\epsilon_{T}$ under label distribution shift. 。
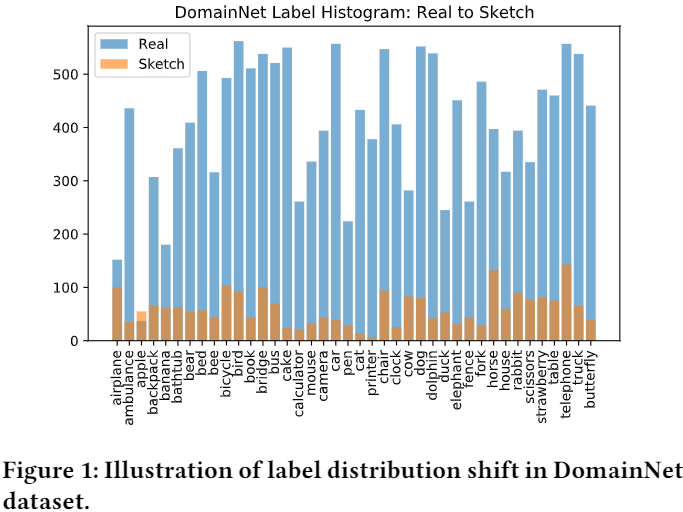
Note :简单增加两个域的数据来解决标签偏移是微不足道的,因为还要考虑域偏移的影响,本文通过生成对抗样本来缓解源域和目标域中的不平衡问题; 。
整体框架:
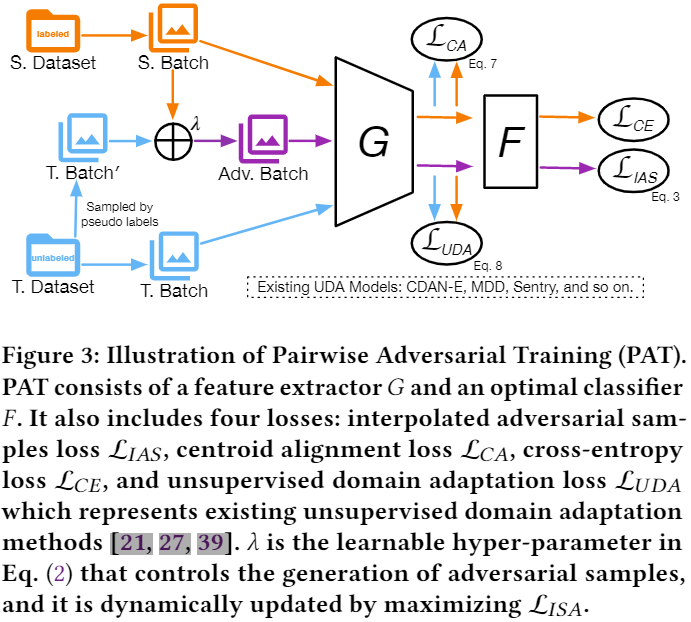
使用对抗训练增强模型鲁棒性,对抗损失如下:
$\begin{array}{l}\mathcal{L}_{c e}\left(x+\delta^{*}, y ; \theta\right) \\where \quad \delta^{*}:=\arg \max \mathcal{L}_{c e}(x+\delta, y ; \theta) , \|\delta\|_{p} \leq \epsilon \end{array} \quad\quad\quad(1)$ 。
传统对抗训练在 CDA 中不适用的原因:
基于上述两个原因,本文提出从源和目标域使用动态线性差值动态生成对抗样本来缓解类不平衡问题,以及 通过显式对齐源域和目标域的条件特征分布来减少域差异,如 Figure 3 所示:
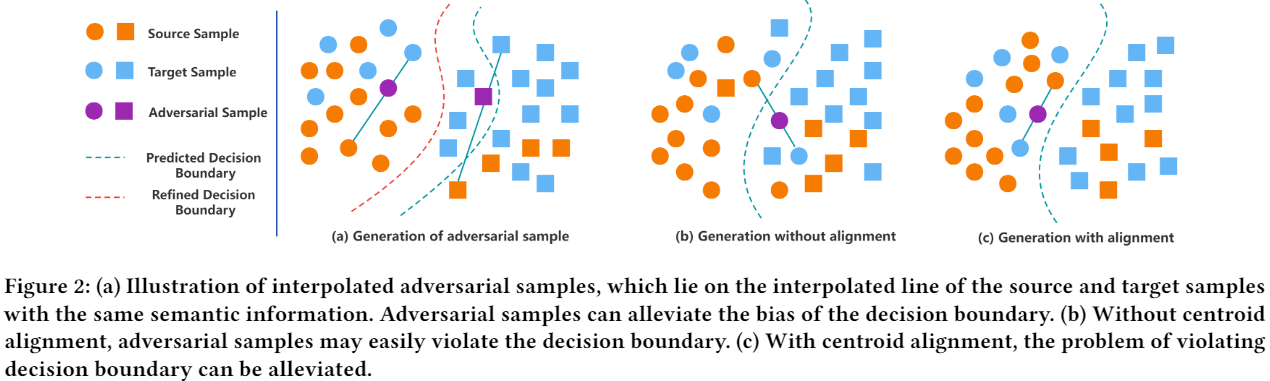
如 Figure2(a) 所示,对来自同一类的成对源和目标样本进行线性插值来生成对抗样本,插值对抗样本 (IAS) 应与其对应的源样本和目标样本具有相同的语义。通过动态利用内插对抗样本明确解决了源域中的数据不平衡问题,提高了无偏模型的泛化能力,并且可以隐式地解决目标域中的数据不平衡问题.
对于第 $k$ 类,插值的对抗样本可以定义为:
$X_{k}^{a d v}=\left\{x_{i}^{a d v} \mid x_{i}^{a d v}=x_{i}^{s}+\lambda\left(x_{i}^{t}-x_{i}^{s}\right), \lambda \in[0,1)^{C}, y_{i}^{s}=\hat{y}_{i}^{t}=k\right\} \quad\quad\quad(2)$ 。
其中:
$\hat{y}_{i}^{t}$ 是通过分类器生成的伪标签; 。
尽管采用伪标签来生成对抗样本,但 PAT 对潜在的错误累积问题具有鲁棒性,原因:
Note: 本文中并非所有类都有相同的机会生成对抗样本,采用概率阈值 $P_{k}$ 来控制来自第 $k$ 类的一对源样本和目标样本的对抗样本的生成.
插值对抗样本的生成可以通过解决以下优化问题来实现:
$\begin{array}{l}\mathcal{L}_{I A S}:=\mathcal{L}_{C E}\left(\hat{x}^{a d v}, y ; \theta\right) \\\text { where } \quad \hat{x}^{a d v}=\underset{x^{a d v} \in \mathcal{X}^{a d v}}{\arg \max } \mathcal{L}_{C E}^{\prime}\left(x^{a d v}, y ; \theta\right)\end{array} \quad\quad\quad(3) $ 。
外部最小化 使用标准交叉熵损失 $\mathcal{L}_{C E}$,即:
$\mathcal{L}_{C E}\left(\hat{x}^{a d v}, y ; \theta\right)=-\log \left(\sigma_{y}\left(f\left(g\left(\hat{x}^{a d v}\right)\right)\right)\right) \quad\quad\quad(4)$ 。
内部最大化 使用交叉熵的修改版,可以缓解熵损失最大化时梯度爆炸或消失的问题,它写成:
$\mathcal{L}_{C E}^{\prime}\left(x^{a d v}, y ; \theta\right)=\log \left(1-\sigma_{y}\left(f\left(g\left(x^{a d v}\right)\right)\right)\right. \quad\quad\quad(5)$ 。
本文生成对抗样本的方法如 Algorithm 1 :

IAS 代码:

def
get_perturb_point(self,input_source,labels_source): self.model.train(False) src_point
=
[] tgt_point
=
[] point_label
=
[]
for
src_index,label
in
enumerate(labels_source):
if
torch.rand(1) >
self.thresh_prob_class[label.cpu().item()]: cond_one
= self.target_label ==
label cond_two
= self.target_prob >
self.thresh_prob_pesudo cond
=
torch.bitwise_and(cond_one, cond_two) cond_index
= torch.nonzero(cond,as_tuple=
True)[0]
if
cond_index.size(0) >
0: src_sample
=
input_source[src_index] tgt_index
= cond_index[torch.randint(cond_index.size(0),(1
,))] _,tgt_sample,_
=
self.target_dataset[tgt_index] src_point.append(src_sample) tgt_point.append(tgt_sample) point_label.append(label)
if
len(point_label) <= 1
:
return
None src_point
=
torch.stack(src_point) tgt_point
=
torch.stack(tgt_point) point_label
=
torch.as_tensor(point_label).long() src_point
=
src_point.to(self.device) tgt_point
=
tgt_point.to(self.device) point_label
=
point_label.to(self.device) perturb_num
=
src_point.size(0) cof
= torch.rand(perturb_num,3,1,1,device=
self.device) cof.requires_grad_(True) optim
= SGD([cof],lr=0.001,momentum=0.9
) loop
=
self.max_loop
for
i
in
range(loop): optim.zero_grad() perturbed_point
= src_point + cof * (tgt_point -
src_point) _,perturbed_output,_,_
=
self.model(perturbed_point) perturbed_output_softmax
= 1 - F.softmax(perturbed_output, dim=1
) perturbed_output_logsoftmax
= torch.log(perturbed_output_softmax.clamp(min=
self.epsilon)) loss
= F.nll_loss(perturbed_output_logsoftmax, point_label,reduction=
'
none
'
) final_loss
=
torch.sum(loss) final_loss.backward() optim.step() cof.data.clamp_(0,
1
) self.model.zero_grad() cof
=
cof.detach() perturbed_point
= src_point + cof * (tgt_point -
src_point) self.model.train(True)
return
(perturbed_point,point_label)
本文中并非所有类都有相同的机会生成对抗样本,采用概率阈值 $P_{k}$ 来控制来自第 $k$ 类的一对源样本和目标样本的对抗样本的生成.
${\large P_{k}=\frac{n_{k}}{n_{\max }+\tau}} \quad\quad\quad(6)$ 。
其中:
$n_{k}$ 是第 $k$ 类的样本数; 。
$n_{\max }= \max _{k}\left\{n_{k}\right\}_{k=1}^{K}$; 。
此外,使用移动平均质心对齐[38],显式匹配两个域的质心来对齐源域和目标域的 条件特征分布 .
如 Figure 2b 所示,如果没有质心对齐,则可能会从一对样本中生成对抗性样本,其中一个样本与其他类未对齐,从而使对抗性样本的嵌入超出决策边界。 通过 Figure 2c 所示的质心对齐,可以消除这种越界对抗样本的出现。 移动平均质心对齐的损失函数定义为:
$\mathcal{L}_{C A}=\sum_{k=1}^{K} \operatorname{dist}\left(C_{k}^{S}, C_{k}^{t}\right) \quad\quad\quad(7)$ 。
其中,$C_{k}^{s}$ 和 $C_{k}^{t}$ 分别表示源域和目标域中第 $k$ 类的质心.
训练目标:
$\mathcal{L}=\mathcal{L}_{U D A}+\mathcal{L}_{C E}+\alpha \mathcal{L}_{I A S}+\beta \mathcal{L}_{C A} \quad\quad\quad(8)$ 。
其中:
略 。
略 。
。
最后此篇关于迁移学习(PAT)《PairwiseAdversarialTrainingforUnsupervisedClass-imbalancedDomainAdaptation》的文章就讲到这里了,如果你想了解更多关于迁移学习(PAT)《PairwiseAdversarialTrainingforUnsupervisedClass-imbalancedDomainAdaptation》的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
34
4
 0
0
我最近开始从事一个 Sails 项目。它目前在迁移表下具有以下格式的迁移。 20160826122004-create_users_table.js 'use strict'; module.expo
当我尝试迁移时 doctrine:migrations:migrate ,我收到此异常:“元数据存储不是最新的,请运行 sync-metadata-storage 命令来解决此问题。”。这仅在尝试在生
我在 ec2 linux 7 上有一个 MarkLogic 服务器。我想将它迁移到 linux 6。我将 ebs 移动到新的 linux 6 并将其安装在 /var/opt/MarkLogic . 我
我对 OpenID 很好奇。虽然我同意统一凭证的想法很棒,但我有一些保留意见。什么是防止 OpenID 提供商发疯并持有他们拥有的 OpenID 帐户直到您支付 n 美元?如果我决定不喜欢这个提供商,
使用 SQL 很容易做到这一点,但我需要编写一个我不熟悉的 Knex 迁移脚本。以下代码在 order 表中行的末尾添加了 order_id 列。我想在 id 之后添加 order_id。我该怎么做?
使用 SQL 很容易做到这一点,但我需要编写一个我不熟悉的 Knex 迁移脚本。以下代码在 order 表中行的末尾添加了 order_id 列。我想在 id 之后添加 order_id。我该怎么做?
我想通过在 Yii2 中的迁移添加一个新列,使用以下代码: public function up() { $this->addColumn('news', 'priority', $this-
我正在尝试在 SQLDelight 的表中添加更多列。我做了一个迁移文件 1.sqm .在迁移文件中,它给出了找不到表的错误。 我的 build.gradle.kts: sqldelight {
我有一个与 Flyway DB 迁移相关的问题。通常如何管理处理相同 DB 模式的多个项目(微服务)。每个项目中的 Flyway 迁移脚本如果被其他项目修改,则不允许启动。他们是否有任何文档或最佳实践
我是 Laravel 的新手。我做了一份待办事项申请作为一项学校作业。我们必须使用迁移来创建我们的数据库。 我使用迁移创建了 2 个表。我的问题是:如果你第一次在你的电脑上运行这个项目,有没有办法自动
我正在尝试在 Laravel 中创建外键,但是当我使用 artisan 迁移表时,出现以下错误: [Illuminate\Database\QueryException] SQLSTATE[HY000
我从 Django 1.7 升级到 Django 1.9。我有多次迁移。升级后我无法再创建新的数据库。 问题是“django manage.py migrate”运行检查。检查导入应用程序 URL。这
我在创建数据迁移方面遇到了困难。我的应用程序使用两个数据库。我在 settings.py 中配置了数据库,并创建了一个像 Django docs 中一样的路由器. # settings.py DB_H
我有一个像这样的sql结构: CREATE TABLE resources ( id SERIAL PRIMARY KEY, title TEXT NOT NULL, created_at
我正在尝试使用模式构建器向表添加枚举选项(不丢失当前数据集)。 我真正能够找到的关于列更改的唯一信息是 http://www.flipflops.org/2013/05/25/modify-an-ex
我尝试转移到一些 CMake 程序中,并且有一个从 xml 生成头文件的函数。 生成文件.am adaptor_glue.hpp: dbus_introspect.xml $(DBUSXX_X
我想将文件移至我的 iOS 应用程序的 CoreData 存储 ../Library/Application Support/MyApp/ 至 ../Documents/Stores/ 我可以使用 N
有没有人对数据迁移进出 NetSuite 有丰富的经验?我必须将 DB2 表导出到 MySQL,处理数据,然后导出到一个 CSV 文件中。然后获取帐户的 CSV 文件并再次操作数据以使帐户从我们的旧系
我正在尝试在 Django 上建立一个博客。我已经走到了创建模型的地步。他们在这里: from django.db import models import uuid class Users(mode
我最近使用 bluehost 上的 AutoSSL 工具将网站迁移到 HTTPS。我在内容中看到一些失真,例如缺少背景颜色、表格位移、缺少_logos 等。 有谁知道 HTTPS 迁移效果如何影响样式

我是一名优秀的程序员,十分优秀!