
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 28
28
 4
4


论文标题:Generalized Domain Adaptation with Covariate and Label Shift CO-ALignment
论文作者:Shuhan Tan, Xingchao Peng, Kate Saenko
论文来源:ICLR 2020
论文地址:download
论文代码:download
视屏讲解:click
提出问题:标签偏移; 。
解决方法:
原型分类器模拟类特征分布,并使用 Minimax Entropy 实现条件特征对齐; 。
使用高置信度目标样本伪标签实现标签分布修正; 。
假设条件标签分布不变 $p(y \mid x)=q(y \mid x)$,只有特征偏移 $p(x) \neq q(x)$,忽略标签偏移 $p(y) \neq q(y)$.
假设不成立的原因:
本文提出类不平衡域适应 (CDA),需要同时处理 条件特征转移 和 标签转移 .
具体来说,除了协变量偏移假设 $p(x) \neq q(x)$, $p(y \mid x)=q(y \mid x)$,进一步假设 $p(x \mid y) \neq q(x \mid y)$ 和 $p(y) \neq q(y)$.
CDA 的主要挑战:
CDA 概述:
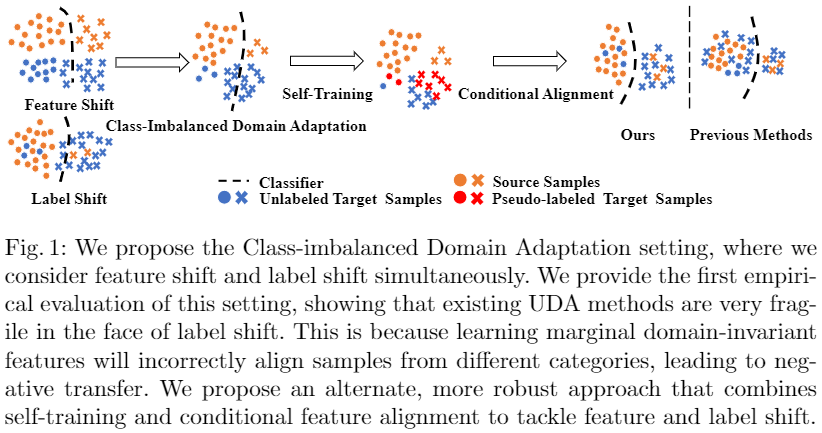
In Class-imbalanced Domain Adaptation, we are given a source domain $\mathcal{D}_{\mathcal{S}}= \left\{\left(x_{i}^{s}, y_{i}^{s}\right)_{i=1}^{N_{s}}\right\}$ with $N_{s}$ labeled examples, and a target domain $\mathcal{D}_{\mathcal{T}}=\left\{\left(x_{i}^{t}\right)_{i=1}^{N_{t}}\right\}$ with $N_{t}$ unlabeled examples. We assume that $p(y \mid x)=q(y \mid x)$ but $p(x \mid y) \neq q(x \mid y)$, $p(x) \neq q(x)$ , and $p(y) \neq q(y)$ . We aim to construct an end-to-end deep neural network which is able to transfer the knowledge learned from $\mathcal{D}_{\mathcal{S}}$ to $\mathcal{D}_{\mathcal{T}}$ , and train a classifier $y=\theta(x)$ which can minimize task risk in target domain $\epsilon_{T}(\theta)=\operatorname{Pr}_{(x, y) \sim q}[\theta(x) \neq y]$. 。

目的:对齐 $p(x \mid y)$ 和 $q(x \mid y)$ 。
步骤:首先使用原型分类器(基于相似度)估计 $p(x \mid y)$ ,然后使用一种 $\text{minimax entropy}$ 算法将其和 $q(x \mid y)$ 对齐; 。
原因:基于原型的分类器在少样本学习设置中表现良好,因为在标签偏移的假设下中,某些类别的设置频率可能较低; 。

#
深层原型分类器
class
Predictor_deep_latent(nn.Module):
def
__init__
(self, in_dim = 1208, num_class = 2, temp = 0.05
): super(Predictor_deep_latent, self).
__init__
() self.in_dim
=
in_dim self.hid_dim
= 512
self.num_class
=
num_class self.temp
= temp
#
0.05
self.fc1
=
nn.Linear(self.in_dim, self.hid_dim) self.fc2
= nn.Linear(self.hid_dim, num_class, bias=
False)
def
forward(self, x, reverse=False, eta=0.1
): x
=
self.fc1(x)
if
reverse: x
=
GradReverse.apply(x, eta) feat
=
F.normalize(x) logit
= self.fc2(feat) /
self.temp
return
feat, logit
源域上的样本使用交叉熵做监督训练:
$\mathcal{L}_{S C}=\mathbb{E}_{(x, y) \in \mathcal{D}_{S}} \mathcal{L}_{c e}(h(x), y) \quad \quad \quad(1)$ 。
样本 $x$ 被分类为 $i$ 类的置信度越高,$x$ 的嵌入越接近 $w_i$。因此,在优化上式时,通过将每个样本 $x$ 的嵌入更接近其在 $W$ 中的相应权重向量来减少类内变化。所以,可以将 $w_i$ 视为 $p$ 的代表性数据点(原型) $p(x \mid y=i)$ .
目标域缺少数据标签,所以使用 $\text{Eq.1}$ 获得类原型是不可行的; 。
解决办法:
因此,提出 熵极小极大 实现上述两个目标.
具体来说,对于输入网络的每个样本 $x^{t} \in \mathcal{D}_{\mathcal{T}}$,可以通过下式计算分类器输出的平均熵 。
$\mathcal{L}_{H}=\mathbb{E}_{x \in \mathcal{D}_{\mathcal{T}}} H(x)=-\mathbb{E}_{x \in \mathcal{D}_{\mathcal{T}}} \sum_{i=1}^{c} h_{i}(x) \log h_{i}(x)\quad \quad \quad(2)$ 。
通过在对抗过程中对齐源原型和目标原型来实现条件特征分布对齐:
由于源标签分布 $p(y)$ 与目标标签分布 $q(y)$ 不同,因此不能保证在 $\mathcal{D}_{\mathcal{S}}$ 上具有低风险的分类器 $C$ 在 $\mathcal{D}_{\mathcal{T}}$ 上具有低错误。 直观地说,如果分类器是用不平衡的源数据训练的,决策边界将由训练数据中最频繁的类别主导,导致分类器偏向源标签分布。 当分类器应用于具有不同标签分布的目标域时,其准确性会降低,因为它高度偏向源域.
为解决这个问题,本文使用[19]中的方法进行自我训练来估计目标标签分布并细化决策边界。自训练为了细化决策边界,本文建议通过自训练来估计目标标签分布。 我们根据分类器 $C$ 的输出将伪标签 $y$ 分配给所有目标样本。由于还对齐条件特征分布 $p(x \mid y$ 和 $q(x \mid y)$,假设分布高置信度伪标签 $q(y)$ 可以用作目标域的真实标签分布 $q(y)$ 的近似值。 在近似的目标标签分布下用这些伪标记的目标样本训练 $C$,能够减少标签偏移的负面影响.
为了获得高置信度的伪标签,对于每个类别,本文选择属于该类别的具有最高置信度分数的目标样本的前 $k%$。利用 $h(x)$ 中的最高概率作为分类器对样本 $x$ 的置信度。 具体来说,对于每个伪标记样本 $(x, y)$,如果 $h(x)$ 位于具有相同伪标签的所有目标样本的前 $k%$ 中,将其选择掩码设置为 $m = 1$,否则 $m = 0 $。将伪标记目标集表示为 $\hat{\mathcal{D}}_{T}=\left\{\left(x_{i}^{t}, \hat{y}_{i}^{t}, m_{i}\right)_{i=1}^{N_{t}}\right\}$,利用来自 $\hat{\mathcal{D}}_{T}$ 的输入和伪标签来训练分类器 $C$,旨在细化决策 与目标标签分布的边界。 分类的总损失函数为:
$\mathcal{L}_{S T}=\mathcal{L}_{S C}+\mathbb{E}_{(x, \hat{y}, m) \in \hat{\mathcal{D}}_{T}} \mathcal{L}_{c e}(h(x), \hat{y}) \cdot m$ 。
通常,用 $k_{0}=5$ 初始化 $k$,并设置 $k_{\text {step }}=5$,$k_{\max }=30$.
Note:本文还对源域数据使用了平衡采样的方法,使得分类器不会偏向于某一类.
总体目标:
$\begin{array}{l}\hat{C}=\underset{C}{\arg \min } \mathcal{L}_{S T}-\alpha \mathcal{L}_{H} \\\hat{F}=\underset{F}{\arg \min } \mathcal{L}_{S T}+\alpha \mathcal{L}_{H}\end{array}$ 。
略 。
最后此篇关于迁移学习(COAL)《GeneralizedDomainAdaptationwithCovariateandLabelShiftCO-ALignment》的文章就讲到这里了,如果你想了解更多关于迁移学习(COAL)《GeneralizedDomainAdaptationwithCovariateandLabelShiftCO-ALignment》的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
28
4
 0
0
我试图找出在表格单元格上放置对齐属性与使用 text-align css 属性之间的区别。下面的代码显示了 IE 与其他浏览器中的不同结果。在 IE 中,对齐最终会对齐每个子子项,因此文本“test”
我正在 summernote HTML 编辑器上做一些 POC,我正在使用自定义工具栏,但我不知道如何添加对齐(左对齐、居中对齐、右对齐)工具栏,所以有人可以帮助我实现这一目标。 还有人可以帮我找到更
以下是从节对齐转换为文件对齐的步骤: 找到数据的 RVA 从 RVA 导出引用的数据所属的部分。这是微不足道的,因为部分不重叠。文件头中提供了各个部分的起始地址。 找出RVA和section的起始地址
align-self 在以下代码中, align-self 与 flex-wrap: nowrap 一起使用。 flex-container { display: flex; flex-wra
这是CSS: .divPhoto { border:1px solid #999; width:140px; height:140px; border-radius:3
我正在为 Windows Phone 8 开发,我已经设计了我的应用程序,我注意到有一个“分配网格”代码,默认情况下可以在新项目中取消注释。 看看下面的文件中的描述: --> 这是取
我们有浏览器前缀或黑客 (for Google and Safari) text-align: -webkit-right; (for Firefox) text-align:
最近我观察到,在 Clang 9.0 上 alignof 和 __alignof 为 unsigned long long 返回不同的值,并且在 https://reviews.llvm.org/D5
我已经一年多没有为 Android 开发了,我对它有点生疏了。我正在尝试设置一个有点简单的 UI:屏幕底部的底部栏和它上面的 fragment (但没有填充整个高度)。像这样: 我认为这会很简单,但经
你好,我正在尝试找到一种使用“讨厌的”align=center 技巧的方法.. 嗯,当我查看一些代码时,我注意到两个非常相似的片段呈现的并不相同。我找不到让他们表现相同的方法。这包括用 div 替换顶
抱歉这个愚蠢的问题。我只想知道我们什么时候讨论内存中的数据应该如何对齐之类的。这个主题是叫“内存对齐”还是“数据对齐”,还是我可以随便叫它什么? 最佳答案 在编程的上下文中,它被称为 data str
所以我只是想制作一个简单的导航栏,并且我刚开始使用 flexbox。为什么 align-content 在这里不起作用?我可以让 justify-content 工作,但我就是无法垂直对齐。这是代码。
我从这个 SO 开始答案,我试图使用提供的纯 flexbox 答案。 然而,当我尝试这个时,我看到了以下结果。 我不确定为什么 Button 4 在行中出现的位置高于其余元素。 HTML
我已通读 A complete guide to Grid ,但仍然对两组容器属性之间的差异感到困惑,即“justify/align-items”与“justify/align-content”。 我
我有一个simple plunker here. .container { display:flex; flex-flow: row nowrap; justify-content: sp
从 http://code.google.com/p/berkeleyaligner/ 下载主干代码后,我将该项目添加到 Eclipse 上的构建路径中。然后,使用下面的代码,我可以提取从 sourc
这个问题在这里已经有了答案: What's the difference between align-content and align-items? (15 个答案) 关闭 7 年前。 我发现 C
[short text][image1][image2]____________________________________ [this is a reallyyyyyyy............
我有一个很小的菜单列表,当鼠标靠近时它应该会增长。在其原始状态下,菜单是右对齐的,悬停时每第二个元素向右移动并左对齐以为增加的高度腾出空间(参见 JSFiddle )。 ul { font-siz
这个问题在这里已经有了答案: Align child elements of different blocks (3 个答案) 关闭 3 年前。

我是一名优秀的程序员,十分优秀!