
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


作者:京东零售 于泷 。
在高并发场景中,为防止大量请求直接访问数据库,缓解数据库压力,常用的方式一般会增加缓存层起到缓冲作用,减少数据库压力。引入缓存,就会涉及到缓存与数据库中数据如何保持一致性问题,本文将对几种缓存与数据库保证数据一致性的使用方式进行分析。 为保证高并发性能,以下分析场景不考虑执行的原子性及加锁等强一致性要求的场景,仅追求最终一致性.

• 读缓存 。
• 如果缓存里没有值,那就读取数据库的值 。
• 同时把这个值写进缓存中 。
更新操作有多种策略,各有优劣,主要针对此场景进行分析 。
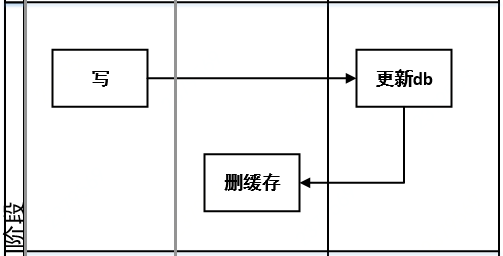
问题:
1.如果更新db成功,删缓存失败,将导致数据不一致 。
2.极端场景,请求A读,B写 。
1)此时缓存刚好失效 2)A查库得到旧值 3)B更新DB成功 。
4)B删除缓存 5)A将查到的旧值更新到缓存中 。
此场景的发生需要步骤2)查db 始终慢于 3)的更新db,才能导致4)先于5)执行,通常db的查询是要快于写入的,所以此极端场景的产生过于严格,不易发生 。
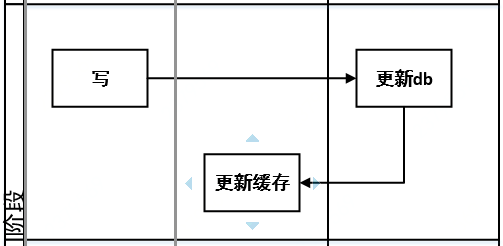
问题:
1.并发更新场景下,更新缓存会导致数据不一致 。
2.根据读写比,考虑是否有必要频繁同步更新缓存,而且,如果构造缓存中数据过于复杂,或者数据更新频繁,但是读取并不频繁的情况,还会造成不必要的性能损耗 。
此种方式不推荐 。
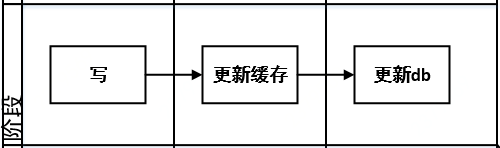
同上,不推荐 。
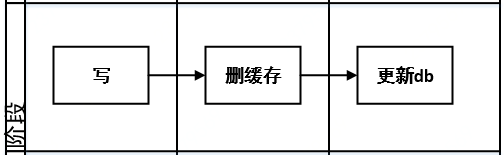
先删缓存,虽然解决了策略1中,后删缓存如果失败的场景,但也会发生不一致的问题 。
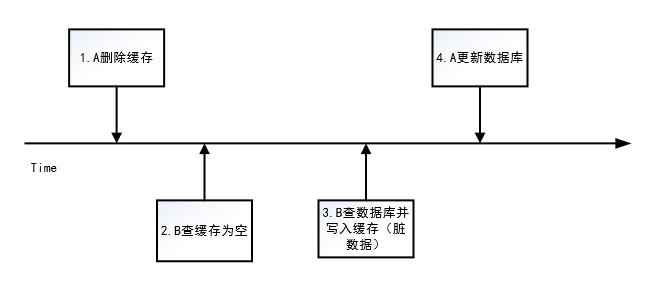
例如:请求 A 删除缓存,这时请求B来查,就会击穿到数据库,B读取到旧的值后写入缓存,A正常更新db,由于时间差导致数据不一致的情况 。
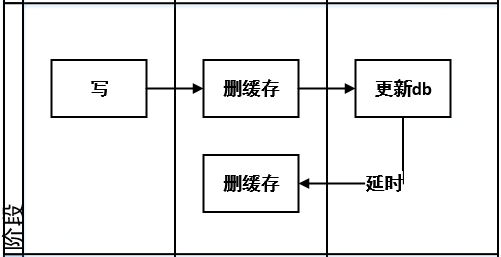
该策略兼容了策略1和策略4,解决了先删缓存还是后删缓存的问题,如策略1中,更新db后删缓存失败和策略4中的不一致场景,该策略可以将延时时间内(比如延时10ms)所造成的缓存脏数据,再次删除。但是,如果延时删缓存失败,策略4中不一致问题还会发生,同时延时的实现,如创建线程,或者引入mq异步,可能会增加系统复杂度问题.
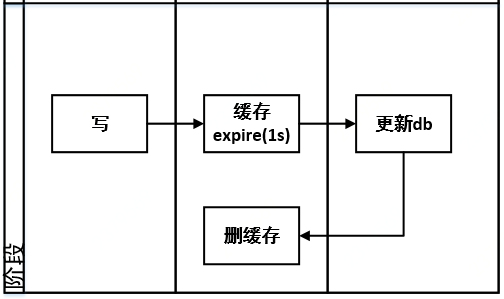
该策略针对策略1中后删缓存失败的场景,前置一层缓存数据过期时间(具体时间根据自身系统本身评估,如可覆盖db读写耗时或一致性容忍度等),更新db后就算删缓存失败,在expire时间后也能保证缓存中无数据。同时,前置expire失败,或者更新db失败,都不会影响数据一致.
能够解决策略4中的问题:请求 A 删除缓存,这时请求B来查,就会击穿到数据库,B读取到旧的值后写入缓存,A正常更新db,由于时间差导致数据不一致的情况,描述图如下:
本策略中步骤1为expire缓存,不会发生击穿缓存到数据库的情况,数据将直接返回。除非更极端情况,如下图
expire时间没有覆盖住更新db的耗时,类似策略1中极端场景,此处不赘述 。

对于每种方案策略,各有利弊,但一致性问题始终存在(文章开头排除了原子性和锁),只是发生的几率在一点点慢慢变小了,方案的评估不仅要根据自身系统的业务场景,如读写比、并发量、一致性容忍度,还要考虑系统复杂度,投入产出比等,寻找最合适的方案.
最后此篇关于缓存与数据库双写一致性几种策略分析的文章就讲到这里了,如果你想了解更多关于缓存与数据库双写一致性几种策略分析的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
我刚刚继承了一个旧的 PostgreSQL 安装,需要进行一些诊断以找出该数据库运行缓慢的原因。在 MS SQL 上,您可以使用 Profiler 等工具来查看正在运行的查询,然后查看它们的执行计划。
将目标从Analytics(分析)导入到AdWords中,然后在Analytics(分析)中更改目标条件时,是否可以通过更改将目标“重新导入”到AdWords,还是可以自动选择? 最佳答案 更改目标值
我正在使用google analytics api来获取数据。我正在获取数据,但我想验证两个参数,它们在特定日期范围内始终为0。我正在获取['ga:transactions']和['ga:goalCo
我使用Google API从Google Analytics(分析)获取数据,但指标与Google Analytics(分析)的网络界面不同。 即:我在2015年3月1日获得数据-它返回综合浏览量79
我在我的Web应用程序中使用sammy.js进行剔除。我正在尝试向其中添加Google Analytics(分析)。我很快找到了following plugin来实现页面跟踪。 我按照步骤操作,页面如
当使用 Xcode 分析 (product>analyze) 时,有没有办法忽略给定文件中的任何错误? 例如编译指示之类的? 我们只想忽略第三方代码的任何警告,这样当我们的代码出现问题时,它对我们
目录 EFK 1. 日志系统 2. 部署ElasticSearch 2.1 创建handless服务 2.2 创建s
关闭。这个问题不满足Stack Overflow guidelines .它目前不接受答案。 想改善这个问题吗?更新问题,使其成为 on-topic对于堆栈溢出。 7年前关闭。 Improve thi
GCC/G++ 是否有可用于输出分析的选项? 能够比较以前的代码与新代码之间的差异(大小、类/结构的大小)将很有用。然后可以将它们与之前的输出进行比较以进行比较,这对于许多目的都是有用的。 如果没有此
我正在浏览 LYAH,并一直在研究处理列表时列表理解与映射/过滤器的使用。我已经分析了以下两个函数,并包含了教授的输出。如果我正确地阅读了教授的内容,我会说 FiltB 的运行速度比 FiltA 慢很
在 MySQL 中可以使用 SET profiling = 1; 设置分析 查询 SHOW PROFILES; 显示每个查询所用的时间。我想知道这个时间是只包括服务器的执行时间还是还包括将结果发送到前
我用 Python 编写了几个用于生成阶乘的模块,我想测试运行时间。我找到了一个分析示例 here我使用该模板来分析我的模块: import profile #fact def main():
前几天读了下mysqld_safe脚本,个人感觉还是收获蛮大的,其中细致的交代了MySQL数据库的启动流程,包括查找MySQL相关目录,解析配置文件以及最后如何调用mysqld程序来启动实例等,有着
上一篇:《人工智能大语言模型起源篇,低秩微调(LoRA)》 (14)Rae 和同事(包括78位合著者!)于2022年发表的《Scaling Language Models: Methods, A
1 内网基础 内网/局域网(Local Area Network,LAN),是指在某一区域内有多台计算机互联而成的计算机组,组网范围通常在数千米以内。在局域网中,可以实现文件管理、应用软件共享、打印机
1 内网基础 内网/局域网(Local Area Network,LAN),是指在某一区域内有多台计算机互联而成的计算机组,组网范围通常在数千米以内。在局域网中,可以实现文件管理、应用软件共享、打印机
我有四列形式的数据。前三列代表时间,value1,value 2。第四列是二进制,全为 0 或 1。当第四列中对应的二进制值为0时,有没有办法告诉excel删除时间、值1和值2?我知道这在 C++ 或
我正在运行一个进行长时间计算的 Haskell 程序。经过一些分析和跟踪后,我注意到以下内容: $ /usr/bin/time -v ./hl test.hl 9000045000050000 Com
我有一个缓慢的 asp.net 程序正在运行。我想分析生产服务器以查看发生了什么,但我不想显着降低生产服务器的速度。 一般而言,配置生产盒或仅本地开发盒是标准做法吗?另外,您建议使用哪些程序来实现这一
我目前正在尝试分析 Haskell 服务器。服务器永远运行,所以我只想要一个固定时间的分析报告。我尝试只运行该程序 3 分钟,然后礼貌地要求它终止,但不知何故,haskell 分析器不遵守术语信号,并

我是一名优秀的程序员,十分优秀!