
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 30
30
 4
4


实战环境 。
elastic search 8.5.0 + kibna 8.5.0 + springboot 3.0.2 + spring data elasticsearch 5.0.2 + jdk 17 。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
@Configuration
public class ElasticsearchConfig extends ElasticsearchConfiguration {
@Override
public ClientConfiguration clientConfiguration() {
return ClientConfiguration.builder()
.connectedTo("127.0.0.1:9200")
.withBasicAuth("elastic", "********")
.build();
}
}
# 日志配置
logging:
level:
#es日志
org.springframework.data.elasticsearch.client.WIRE : trace
@Data
@Document(indexName = "news") //索引名
@Setting(shards = 1,replicas = 0,refreshInterval = "1s") //shards 分片数 replicas 副本数
@Schema(name = "News",description = "新闻对象")
public class News implements Serializable {
@Id //索引主键
@NotBlank(message = "新闻ID不能为空")
@Schema(type = "integer",description = "新闻ID",example = "1")
private Integer id;
@NotBlank(message = "新闻标题不能为空")
@Schema(type = "String",description = "新闻标题")
@MultiField(mainField = @Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart"),
otherFields = {@InnerField(type = FieldType.Keyword, suffix = "keyword") }) //混合类型字段 指定 建立索引时分词器与搜索时入参分词器
private String title;
@Schema(type = "LocalDate",description = "发布时间")
@Field(type = FieldType.Date,format = DateFormat.date)
private LocalDate pubDate;
@Schema(type = "String",description = "来源")
@Field(type = FieldType.Keyword)
private String source;
@Schema(type = "String",description = "行业类型代码",example = "1,2,3")
@Field(type = FieldType.Text,analyzer = "ik_max_word",searchAnalyzer = "ik_smart")
private String industry;
@Schema(type = "String",description = "预警类型")
@Field(type = FieldType.Keyword)
private String type;
@Schema(type = "String",description = "涉及公司")
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String companies;
@Schema(type = "String",description = "新闻内容")
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String content;
}
@Repository
public interface NewsRepository extends ElasticsearchRepository<News,Integer> {
Page<News> findByType(String type, Pageable pageable);
}
/**
* 新增新闻
* @param news
* @return
*/
@Override
public void saveNews(News news) {
newsRepository.save(news);
}
/**
* 删除新闻
* @param newsId
*/
@Override
public void delete(Integer newsId) {
newsRepository.deleteById(newsId);
}
/**
* 删除新闻索引
*/
@Override
public void deleteIndex() {
operations.indexOps(News.class).delete();
}
/**
* 创建索引
*/
@Override
public void createIndex() {
operations.indexOps(News.class).createWithMapping();
}
@Override
public PageResult findByType(String type) {
// 先发布日期排序
Sort sort = Sort.by(new Order(Sort.Direction.DESC, "pubDate"));
Pageable pageable = PageRequest.of(0,10,sort);
final Page<News> newsPage = newsRepository.findByType(type, pageable);
return new PageResult(newsPage.getTotalElements(),newsPage.getContent());
}
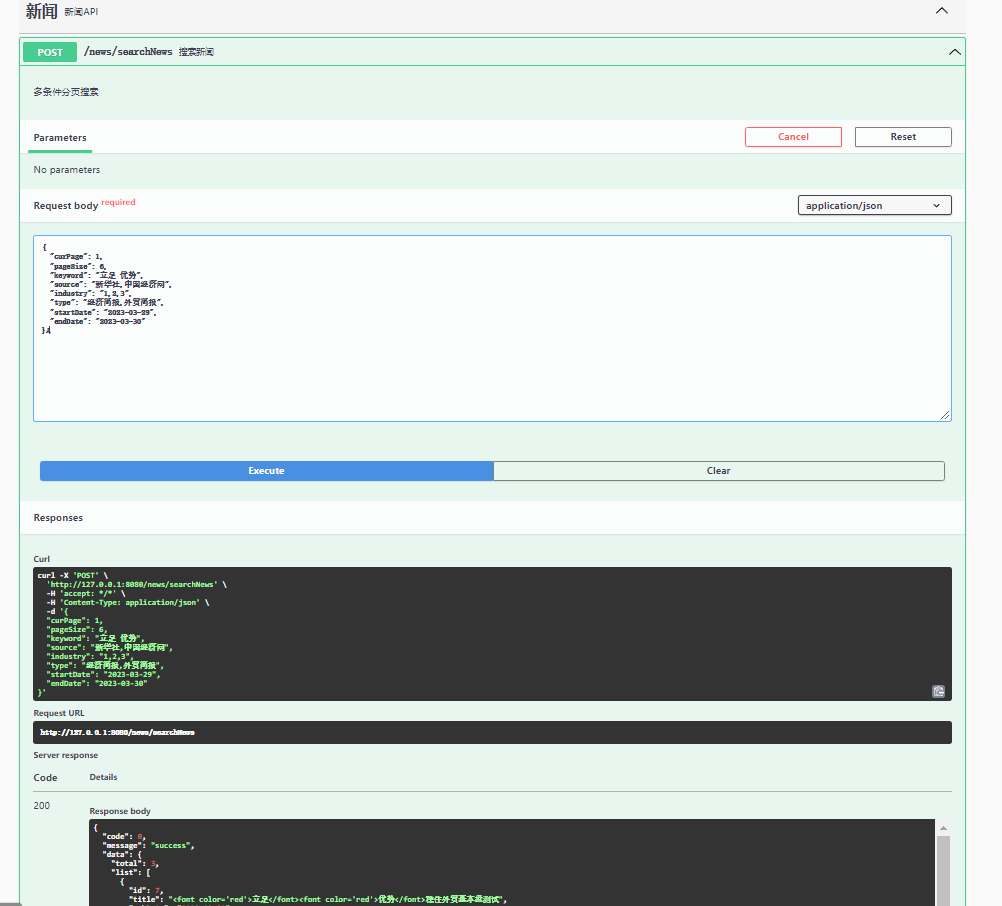
实现效果图片:
实际执行的DSL语句:
注意: 当指定排序条件时 _score 会被置空 。
@Override
public PageResult searchNews(NewsPageSearch search) {
//创建原生查询DSL对象
final NativeQueryBuilder nativeQueryBuilder = new NativeQueryBuilder();
// 先发布日期再得分排序
Sort sort = Sort.by(new Order(Sort.Direction.DESC, "pubDate"),new Order(Sort.Direction.DESC, "_score"));
Pageable pageable = PageRequest.of(search.getCurPage(), search.getPageSize(),sort);
final BoolQuery.Builder boolBuilder = new BoolQuery.Builder();
//过滤条件
setFilter(search, boolBuilder);
//关键字搜索
if (StringUtils.isNotBlank(search.getKeyword())){
setKeyWordAndHighlightField(search, nativeQueryBuilder, boolBuilder);
}else {
nativeQueryBuilder.withQuery(q -> q.bool(boolBuilder.build()));
}
nativeQueryBuilder.withPageable(pageable);
SearchHits<News> searchHits = operations.search(nativeQueryBuilder.build(), News.class);
//高亮回填封装
final List<News> newsList = searchHits.getSearchHits().stream()
.map(s -> {
final News content = s.getContent();
final List<String> title = s.getHighlightFields().get("title");
final List<String> contentList = s.getHighlightFields().get("content");
if (!CollectionUtils.isEmpty(title)){
s.getContent().setTitle(title.get(0));
}
if (!CollectionUtils.isEmpty(contentList)){
s.getContent().setContent(contentList.get(0));
}
return content;
}).collect(Collectors.toList());
return new PageResult<News>(searchHits.getTotalHits(),newsList);
}
/**
* 设置过滤条件 行业类型 来源 预警类型
* @param search
* @param boolBuilder
*/
private void setFilter(NewsPageSearch search, BoolQuery.Builder boolBuilder) {
//行业类型
if(StringUtils.isNotBlank(search.getIndustry())){
// 按逗号拆分
List<Query> industryQueries = Arrays.asList(search.getIndustry().split(",")).stream().map(p -> {
Query.Builder queryBuilder = new Query.Builder();
queryBuilder.term(t -> t.field("industry").value(p));
return queryBuilder.build();
}).collect(Collectors.toList());
boolBuilder.filter(f -> f.bool(t -> t.should(industryQueries)));
}
// 来源
if(StringUtils.isNotBlank(search.getSource())){
// 按逗号拆分
List<Query> sourceQueries = Arrays.asList(search.getSource().split(",")).stream().map(p -> {
Query.Builder queryBuilder = new Query.Builder();
queryBuilder.term(t -> t.field("source").value(p));
return queryBuilder.build();
}).collect(Collectors.toList());
boolBuilder.filter(f -> f.bool(t -> t.should(sourceQueries)));
}
// 预警类型
if(StringUtils.isNotBlank(search.getType())){
// 按逗号拆分
List<Query> typeQueries = Arrays.asList(search.getType().split(",")).stream().map(p -> {
Query.Builder queryBuilder = new Query.Builder();
queryBuilder.term(t -> t.field("type").value(p));
return queryBuilder.build();
}).collect(Collectors.toList());
boolBuilder.filter(f -> f.bool(t -> t.should(typeQueries)));
}
//范围区间
if (StringUtils.isNotBlank(search.getStartDate())){
boolBuilder.filter(f -> f.range(r -> r.field("pubDate")
.gte(JsonData.of(search.getStartDate()))
.lte(JsonData.of(search.getEndDate()))));
}
}
/**
* 关键字搜索 title 权重更高
* 高亮字段 title 、content
* @param search
* @param nativeQueryBuilder
* @param boolBuilder
*/
private void setKeyWordAndHighlightField(NewsPageSearch search, NativeQueryBuilder nativeQueryBuilder, BoolQuery.Builder boolBuilder) {
final String keyword = search.getKeyword();
//查询条件
boolBuilder.must(b -> b.multiMatch(m -> m.fields("title","content","companies").query(keyword)));
//高亮
final HighlightFieldParameters.HighlightFieldParametersBuilder builder = HighlightFieldParameters.builder();
builder.withPreTags("<font color='red'>")
.withPostTags("</font>")
.withRequireFieldMatch(true) //匹配才加标签
.withNumberOfFragments(0); //显示全文
final HighlightField titleHighlightField = new HighlightField("title", builder.build());
final HighlightField contentHighlightField = new HighlightField("content", builder.build());
final Highlight titleHighlight = new Highlight(List.of(titleHighlightField,contentHighlightField));
nativeQueryBuilder.withQuery(
f -> f.functionScore(
fs -> fs.query(q -> q.bool(boolBuilder.build()))
.functions( FunctionScore.of(func -> func.filter(
fq -> fq.match(ft -> ft.field("title").query(keyword))).weight(100.0)),
FunctionScore.of(func -> func.filter(
fq -> fq.match(ft -> ft.field("content").query(keyword))).weight(20.0)),
FunctionScore.of(func -> func.filter(
fq -> fq.match(ft -> ft.field("companies").query(keyword))).weight(10.0)))
.scoreMode(FunctionScoreMode.Sum)
.boostMode(FunctionBoostMode.Sum)
.minScore(1.0)))
.withHighlightQuery(new HighlightQuery(titleHighlight,News.class));
}
加权前效果:
加权后效果:
DSL 语句:
{
"from": 0,
"size": 6,
"sort": [{
"pubDate": {
"mode": "min",
"order": "desc"
}
}, {
"_score": {
"order": "desc"
}
}],
"highlight": {
"fields": {
"title": {
"number_of_fragments": 0,
"post_tags": ["</font>"],
"pre_tags": ["<font color='red'>"]
},
"content": {
"number_of_fragments": 0,
"post_tags": ["</font>"],
"pre_tags": ["<font color='red'>"]
}
}
},
"query": {
"function_score": {
"boost_mode": "sum",
"functions": [{
"filter": {
"match": {
"title": {
"query": "立足优势稳住外贸基本盘"
}
}
},
"weight": 100.0
}, {
"filter": {
"match": {
"content": {
"query": "立足优势稳住外贸基本盘"
}
}
},
"weight": 20.0
}, {
"filter": {
"match": {
"companies": {
"query": "立足优势稳住外贸基本盘"
}
}
},
"weight": 10.0
}],
"min_score": 1.0,
"query": {
"bool": {
"filter": [{
"bool": {
"should": [{
"term": {
"industry": {
"value": "1"
}
}
}, {
"term": {
"industry": {
"value": "2"
}
}
}, {
"term": {
"industry": {
"value": "3"
}
}
}]
}
}, {
"bool": {
"should": [{
"term": {
"source": {
"value": "新华社"
}
}
}, {
"term": {
"source": {
"value": "中国经济网"
}
}
}]
}
}, {
"bool": {
"should": [{
"term": {
"type": {
"value": "经济简报"
}
}
}, {
"term": {
"type": {
"value": "外贸简报"
}
}
}]
}
}, {
"range": {
"pubDate": {
"gte": "2023-03-29",
"lte": "2023-03-30"
}
}
}],
"must": [{
"multi_match": {
"fields": ["title", "content", "companies"],
"query": "立足优势稳住外贸基本盘"
}
}]
}
},
"score_mode": "sum"
}
},
"track_scores": false,
"version": true
}
最后此篇关于Elasticsearch搜索功能的实现(五)--实战的文章就讲到这里了,如果你想了解更多关于Elasticsearch搜索功能的实现(五)--实战的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
30
4
 0
0
问题情景 混淆群内的小伙伴遇到这么个问题,Mailivery 这个网站登录后,明明提交的表单(邮箱和密码也正确)、请求头等等都没问题,为啥一直重定向到登录页面呢?唉,该出手时就出手啊,我也看看咋回事
实战-行业攻防应急响应 简介: 服务器场景操作系统 Ubuntu 服务器账号密码:root/security123 分析流量包在/home/security/security.pcap 相
背景 最近公司将我们之前使用的链路工具切换为了 OpenTelemetry. 我们的技术栈是: OTLP C
一 同一类的方法都用 synchronized 修饰 1 代码 package concurrent; import java.util.concurrent.TimeUnit; public c
一 简单例子 1 代码 package concurrent.threadlocal; /** * ThreadLocal测试 * * @author cakin */ public class T
1. 问题背景 问题发生在快递分拣的流程中,我尽可能将业务背景简化,让大家只关注并发问题本身。 分拣业务针对每个快递包裹都会生成一个任务,我们称它为 task。task 中有两个字段需要
实战环境 elastic search 8.5.0 + kibna 8.5.0 + springboot 3.0.2 + spring data elasticsearch 5.0.2 +
Win10下yolov8 tensorrt模型加速部署【实战】 TensorRT-Alpha 基于tensorrt+cuda c++实现模型end2end的gpu加速,支持win10、
yolov8 tensorrt模型加速部署【实战】 TensorRT-Alpha 基于tensorrt+cuda c++实现模型end2end的gpu加速,支持win10、linux,
目录如下: 为什么需要自定义授权类型? 前面介绍OAuth2.0的基础知识点时介绍过支持的4种授权类型,分别如下: 授权码模式 简化模式 客户端模式 密码模式
今天这篇文章介绍一下如何在修改密码、修改权限、注销等场景下使JWT失效。 文章的目录如下: 解决方案 JWT最大的一个优势在于它是无状态的,自身包含了认证鉴权所需要的所有信息,服务器端
前言 大家好,我是捡田螺的小男孩。(求个星标置顶) 我们日常做分页需求时,一般会用limit实现,但是当偏移量特别大的时候,查询效率就变得低下。本文将分四个方案,讨论如何优化MySQL百万数
前言 大家好,我是捡田螺的小男孩。 平时我们写代码呢,多数情况都是流水线式写代码,基本就可以实现业务逻辑了。如何在写代码中找到乐趣呢,我觉得,最好的方式就是:使用设计模式优化自己
我们先讲一些arm汇编的基础知识。(我们以armv7为例,最新iphone5s上的64位暂不讨论) 基础知识部分: 首先你介绍一下寄存器: r0-r3:用于函数参数及返回值的传递 r4-r6
一 同一类的静态方法都用 synchronized 修饰 1 代码 package concurrent; import java.util.concurrent.TimeUnit; public
DRF快速写五个接口,比你用手也快··· 实战-DRF快速写接口 开发环境 Python3.6 Pycharm专业版2021.2.3 Sqlite3 Django 2.2 djangorestfram
一 添加依赖 org.apache.thrift libthrift 0.11.0 二 编写 IDL 通过 IDL(.thrift 文件)定义数据结构、异常和接口等数据,供各种编程语言使用 nam
我正在阅读 Redis in action e-book关于semaphores的章节.这是使用redis实现信号量的python代码 def acquire_semaphore(conn, semn
自定义控件在WPF开发中是很常见的,有时候某些控件需要契合业务或者美化统一样式,这时候就需要对控件做出一些改造。 目录 按钮设置圆角
师父布置的任务,让我写一个服务练练手,搞清楚socket的原理和过程后跑了一个小demo,很有成就感,代码内容也比较清晰易懂,很有教育启发意义。 代码 ?

我是一名优秀的程序员,十分优秀!