
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 35
35
 4
4


项目链接合集(必看) 。
项目专栏合集 https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc 必看 。
A.机器学习系列入门系列[一]:基于鸢尾花的逻辑回归分类预测:
逻辑回归(Logistic regression,简称LR)虽然其中带有"回归"两个字,但逻辑回归其实是一个分类模型,并且广泛应用于各个领域之中。虽然现在深度学习相对于这些传统方法更为火热,但实则这些传统方法由于其独特的优势依然广泛应用于各个领域中.
A.机器学习算法入门系列(二): 基于鸢尾花数据集的素贝叶斯分类预测 。
朴素贝叶斯算法(Naive Bayes, NB) 是应用最为广泛的分类算法之一。它是基于贝叶斯定义和特征条件独立假设的分类器方法。由于朴素贝叶斯法基于贝叶斯公式计算得到,有着坚实的数学基础,以及稳定的分类效率。NB模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。当年的垃圾邮件分类都是基于朴素贝叶斯分类器识别的.
A.机器学习系列入门系列[三]:基于horse-colic的KNN近邻分类预测:
kNN(k-nearest neighbors),中文翻译K近邻。我们常常听到一个故事:如果要了解一个人的经济水平,只需要知道他最好的5个朋友的经济能力, 对他的这五个人的经济水平求平均就是这个人的经济水平。这句话里面就包含着kNN的算法思想.
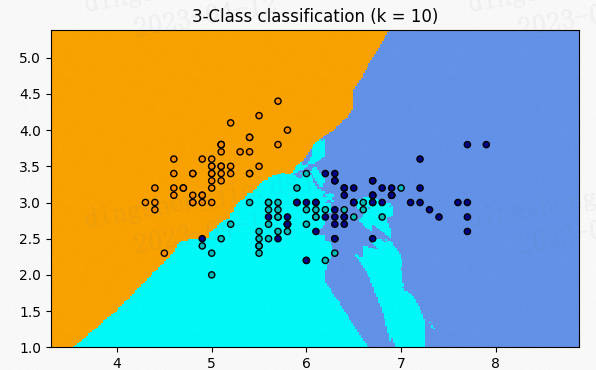
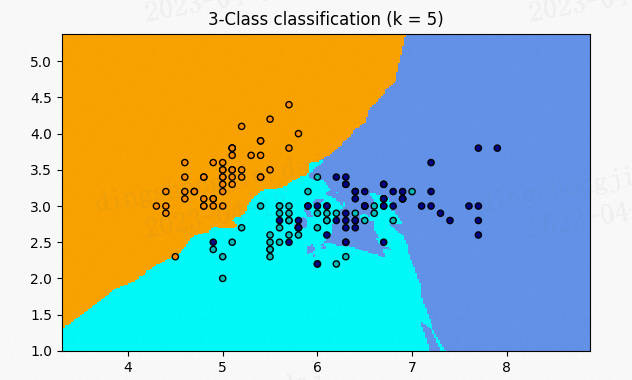
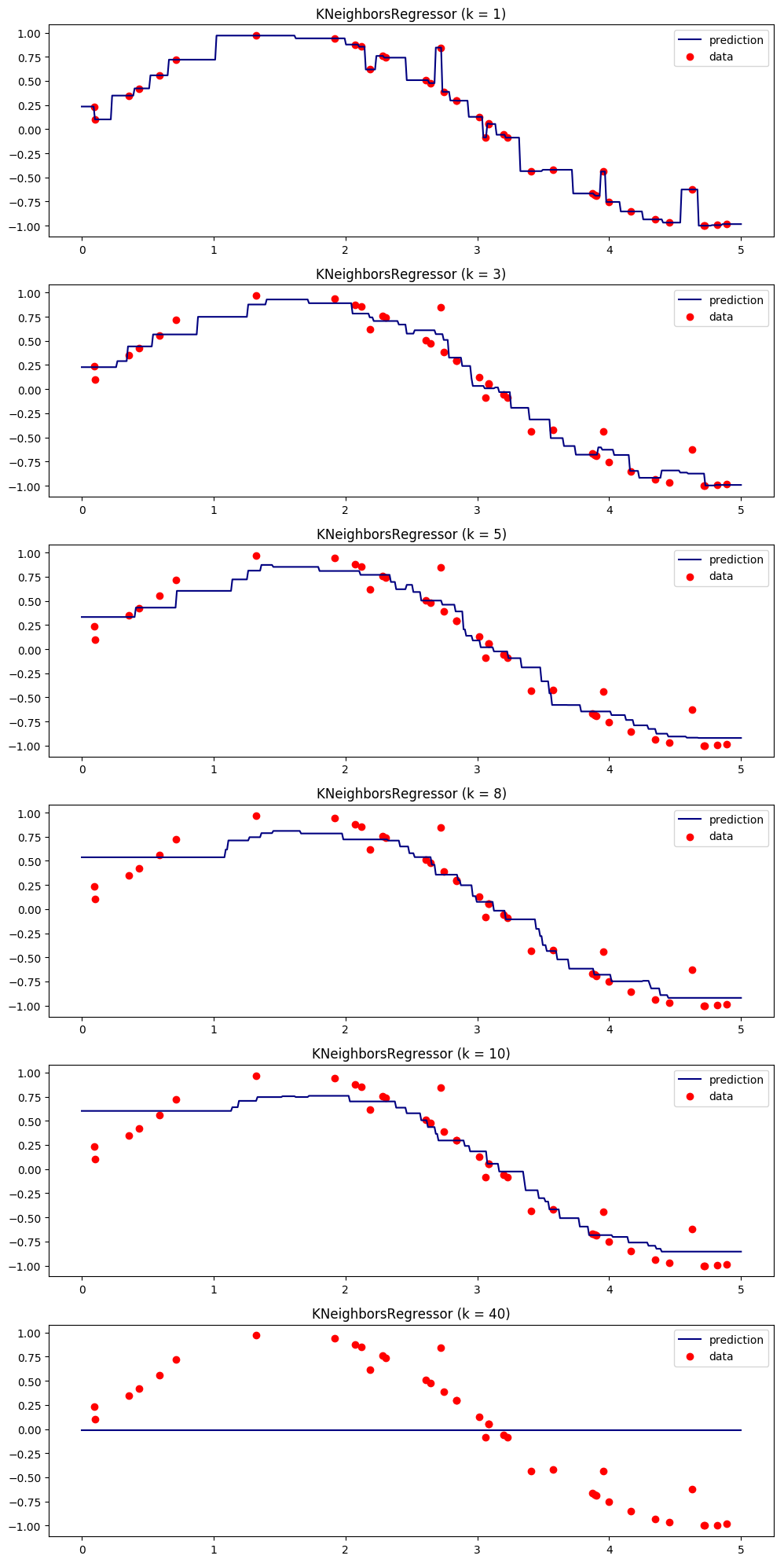
A.机器学习系列入门系列[四]:基于支持向量机的分类预测 。
支持向量机(Support Vector Machine,SVM)是一个非常优雅的算法,具有非常完善的数学理论,常用于数据分类,也可以用于数据的回归预测中,由于其其优美的理论保证和利用核函数对于线性不可分问题的处理技巧 。
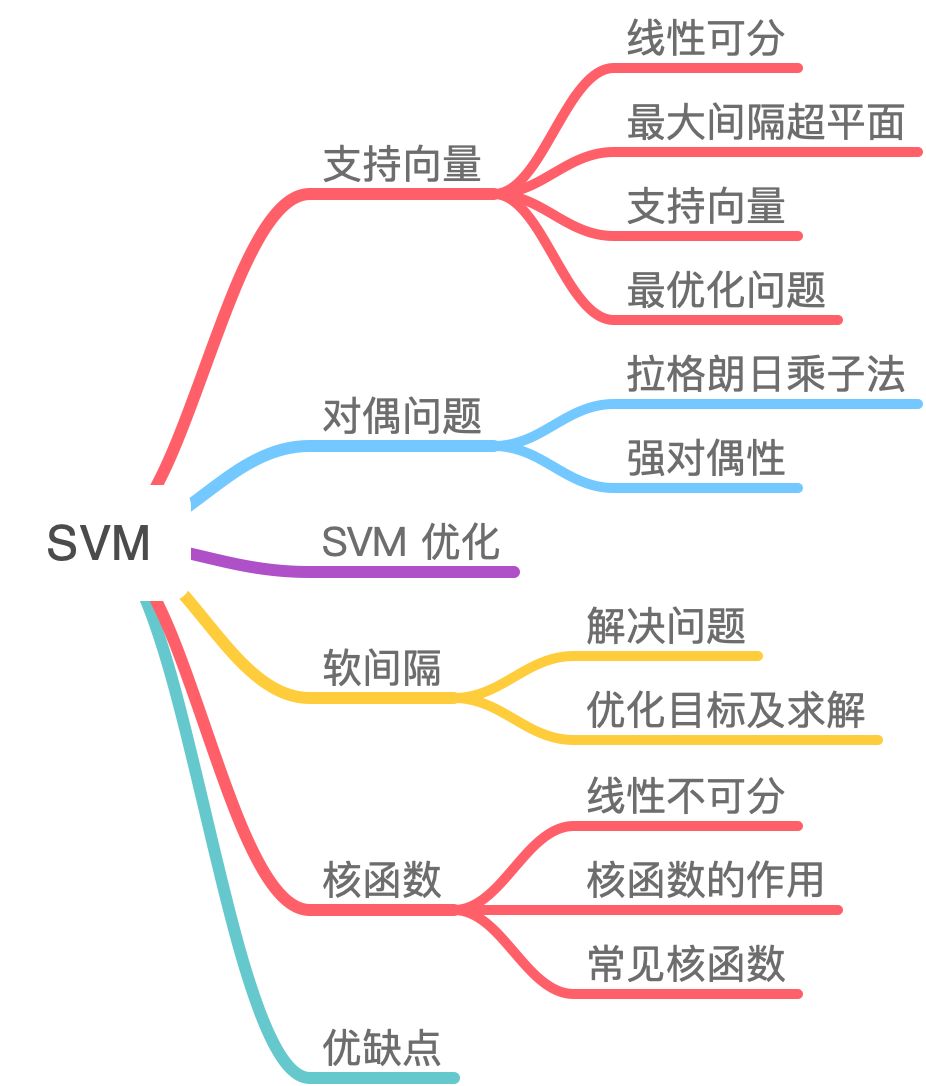
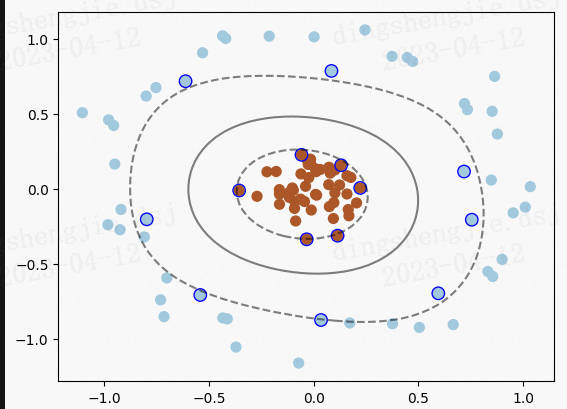
A.机器学习系列入门系列[五]:基于企鹅数据集的决策树分类预测 。
决策树是一种常见的分类模型,在金融风控、医疗辅助诊断等诸多行业具有较为广泛的应用。决策树的核心思想是基于树结构对数据进行划分,这种思想是人类处理问题时的本能方法。由于决策树模型中自变量与因变量的非线性关系以及决策树简单的计算方法,使得它成为集成学习中最为广泛使用的基模型。梯度提升树(GBDT),XGBoost以及LightGBM等先进的集成模型都采用了决策树作为基模型,在广告计算、CTR预估、金融风控等领域大放异彩,成为当今与神经网络相提并论的复杂模型,更是数据挖掘比赛中的常客。在新的研究中,南京大学周志华教授提出一种多粒度级联森林模型,创造了一种全新的基于决策树的深度集成方法,为我们提供了决策树发展的另一种可能.
A.机器学习系列入门系列[六]:基于天气数据集的XGBoost分类预测:
XGBoost是2016年由华盛顿大学陈天奇老师带领开发的一个可扩展机器学习系统。严格意义上讲XGBoost并不是一种模型,而是一个可供用户轻松解决分类、回归或排序问题的软件包。它内部实现了梯度提升树(GBDT)模型,并对模型中的算法进行了诸多优化,在取得高精度的同时又保持了极快的速度,在一段时间内成为了国内外数据挖掘、机器学习领域中的大规模杀伤性武器.
更重要的是,XGBoost在系统优化和机器学习原理方面都进行了深入的考虑。毫不夸张的讲,XGBoost提供的可扩展性,可移植性与准确性推动了机器学习计算限制的上限,该系统在单台机器上运行速度比当时流行解决方案快十倍以上,甚至在分布式系统中可以处理十亿级的数据.
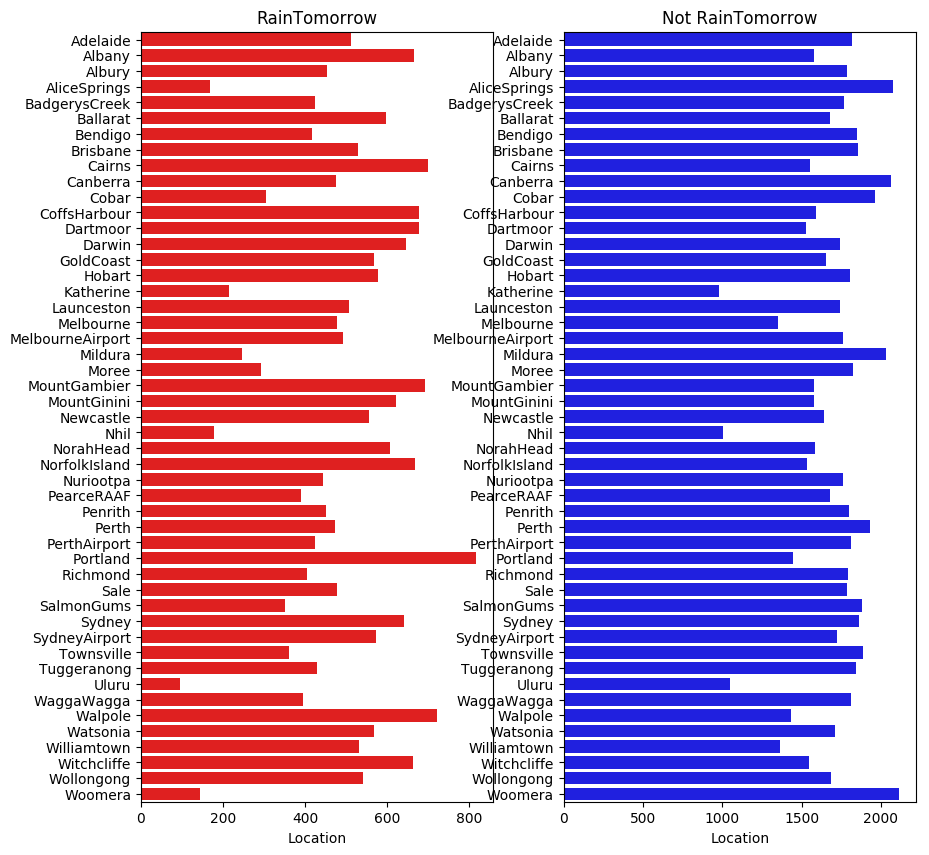
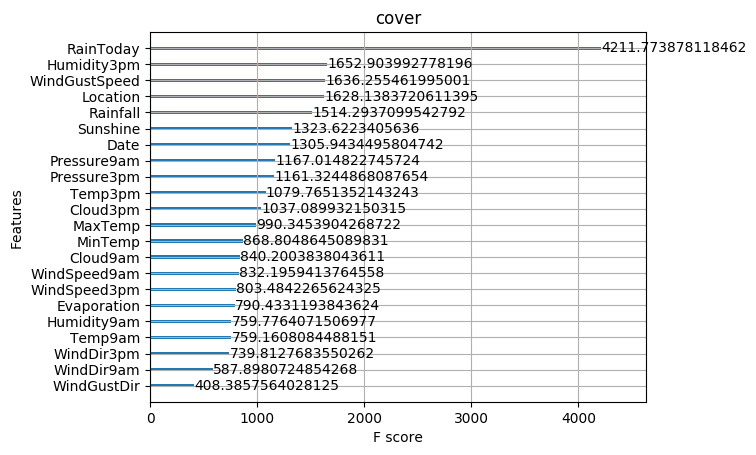
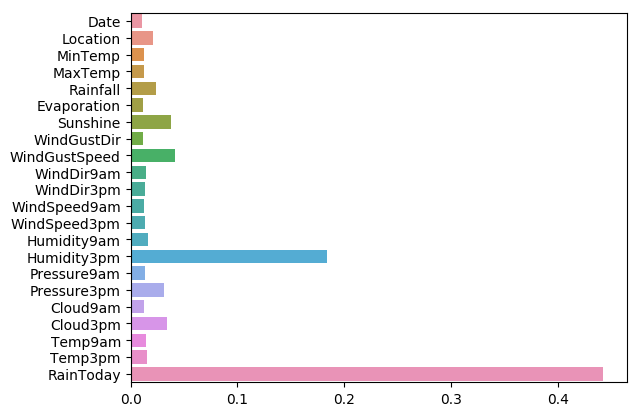
A.机器学习系列入门系列[七]:基于英雄联盟数据的LightGBM分类预测:
LightGBM是2017年由微软推出的可扩展机器学习系统,是微软旗下DMKT的一个开源项目,它是一款基于GBDT(梯度提升决策树)算法的分布式梯度提升框架,为了满足缩短模型计算时间的需求,LightGBM的设计思路主要集中在减小数据对内存与计算性能的使用,以及减少多机器并行计算时的通讯代价.
LightGBM底层实现了GBDT算法,并且添加了一系列的新特性:
A.机器学习系列入门系列[八]:基于BP神经网络的乳腺癌分类预测 。
BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。BP神经网络模型拓扑结构包括输入层(input)、隐层(hide layer)和输出层(output layer)。在模拟过程中收集系统所产生的误差,通过误差反传,然后调整权值大小,通过该不断迭代更新,最后使得模型趋于整体最优化(这是一个循环,我们在训练神经网络的时候是要不断的去重复这个过程的).
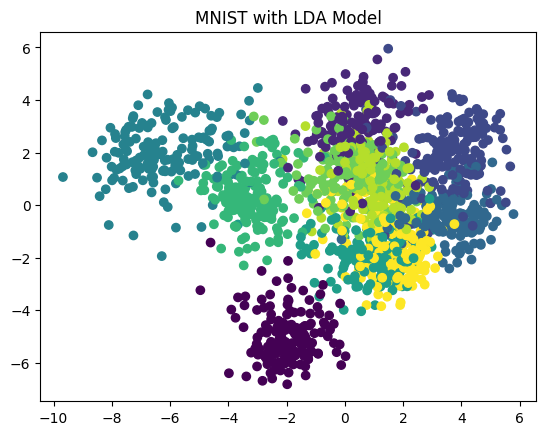
A.机器学习系列入门系列[九]:基于线性判别模型的LDA手写数字分类识别:
线性判别模型(LDA)在模式识别领域(比如人脸识别等图形图像识别领域)中有非常广泛的应用。LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”。我们要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。即:将数据投影到维度更低的空间中,使得投影后的点,会形成按类别区分,一簇一簇的情况,相同类别的点,将会在投影后的空间中更接近方法.
B.机器学习实战系列[一]:工业蒸汽量预测(最新版本上篇)含数据探索特征工程等:
B.机器学习实战系列[一]:工业蒸汽量预测(最新版本下篇)含特征优化模型融合等:
背景介绍 火力发电的基本原理是:燃料在燃烧时加热水生成蒸汽,蒸汽压力推动汽轮机旋转,然后汽轮机带动发电机旋转,产生电能。在这一系列的能量转化中,影响发电效率的核心是锅炉的燃烧效率,即燃料燃烧加热水产生高温高压蒸汽。锅炉的燃烧效率的影响因素很多,包括锅炉的可调参数,如燃烧给量,一二次风,引风,返料风,给水水量;以及锅炉的工况,比如锅炉床温、床压,炉膛温度、压力,过热器的温度等.
相关描述 经脱敏后的锅炉传感器采集的数据(采集频率是分钟级别),根据锅炉的工况,预测产生的蒸汽量.
数据说明 数据分成训练数据(train.txt)和测试数据(test.txt),其中字段”V0”-“V37”,这38个字段是作为特征变量,”target”作为目标变量。选手利用训练数据训练出模型,预测测试数据的目标变量,排名结果依据预测结果的MSE(mean square error).
结果评估 预测结果以mean square error作为评判标准.
在工业蒸汽量预测上篇中,主要讲解了数据探索性分析:查看变量间相关性以及找出关键变量;数据特征工程对数据精进:异常值处理、归一化处理以及特征降维;在进行归回模型训练涉及主流ML模型:决策树、随机森林,lightgbm等。下一篇中将着重讲解模型验证、特征优化、模型融合等.
【机器学习入门与实践】数据挖掘-二手车价格交易预测:
来自 Ebay Kleinanzeigen 报废的二手车,数量超过 370,000,包含 20 列变量信息,为了保证 比赛的公平性,将会从中抽取 10 万条作为训练集,5 万条作为测试集 A,5 万条作为测试集 B。同时会对名称、车辆类型、变速箱、model、燃油类型、品牌、公里数、价格等信息进行 脱敏.
本人最近打算整合ML、DRL、NLP等相关领域的体系化项目课程,方便入门同学快速掌握相关知识。声明:部分项目为网络经典项目方便大家快速学习,后续会不断增添实战环节(比赛、论文、现实应用等) 。
上述机器学习项目为最经典的项目,但由于原课程依赖的算法库和算子替换导致部分程序无法运行,本次贡献点在于按照自己思路进行项目整合,其次是对bug修复保证案例全部调通, 。
项目专栏合集 https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc 必看 。
最后此篇关于【机器学习入门与实践】合集入门必看系列,含数据挖掘项目实战,适合新人入门的文章就讲到这里了,如果你想了解更多关于【机器学习入门与实践】合集入门必看系列,含数据挖掘项目实战,适合新人入门的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
35
4
 0
0
private boolean validateSno(double inSno) { //sno is the serial number int firstThree=(int)inSno
这个问题已经有答案了: How can I determine if a date is between two dates in Java? [duplicate] (11 个回答) 已关闭 6 年
我目前正在通过一本名为 Alex Allain - Jumping into c++ 的书学习 C++,但我卡在了第 21 章。它详细介绍了 C++ 构建过程,我明白了,除了 2 个部分: 首先: “
我有以下 Oracle 查询 SELECT * FROM table WHERE date_opened BETWEEN ((TO_DATE('2011-08-01', 'yyyy-mm-dd') -
use rand::Rng; fn main() { let mut zz = rand::thread_rng(); let mut a: [i32; 4096] = [0; 409
我正在使用 flatPickr(日历插件)来完成此任务。我将 minDate 和 maxDate(始终是星期日)从 PHP 函数发送到 JavaScript: $("#weeklySelector")
从 Eclipse 运行时,以下代码可以正常工作: System.setProperty("webdriver.gecko.driver", pathToGeckoDriver); FirefoxOp
我正在编写一个 Iphone 应用程序并使用 sqlite 作为我的数据库。如果对象在某个范围(MIN 和 MAX)之间,我有折扣,但问题是当我查询时,折扣似乎也适用于超出该范围的对象。不确定如何正确
Brunch 几乎适用于所有模板语言,并且有适用于它们的插件,但我无法使用 vanilla HTML。我只是希望在每次构建早午餐时只复制我的 html 文件(无论它们位于何处)并粘贴到公共(publi
首先我必须输入N,N成为第一个要检查的数字。 输入:79 输出应为:537.70。 int sum=0; while(1) { scanf("%d", &n
aa: { one: "hello", two: "good", three: "bye", four: "tomorrow",
我尝试解决方案,我知道这是不对的,因为程序的输出不正确。我做错了什么? 我有一个内部节点类,每个节点都有值字段。此方法应返回具有介于 int min 和 max 之间的值字段的节点数。 //-----
我正在尝试弄清楚如何执行 mysql 查询,在该查询中我返回以(例如)A-D 开头的结果,又名将返回: - 动物 - 银行 - 可乐 - 狗但不是:冰屋 看起来很简单,但找不到有效的方法。 我的意思是
我正在开发一个程序,我必须打印出 1 到 239 之间的素数,包括 1 和 239(我知道一和二可能不是素数,但我们会认为它们是素数这个程序)它一定是一个非常简单的程序,因为我们只讨论了一些基础知识。
我有一个错误,我在 jsbin 中复制了这个错误:https://jsbin.com/micinalacu/1/edit?html,console,output 铁形式,提交时serialize方法返
我正在尝试为 UIColor 定义扩展 import UIKit extension UIColor { convenience init(rgb:UInt){ let red
通过对 A 和 B(含)之间的一个或多个整数进行按位或运算,可以生成多少个不同的数字? 解释: 在这种情况下,A=7 和 B=9。对 {7, 8, 9} 的非空子集进行按位或运算可以生成四个整数:7,
在尝试将ignore_malformed添加到索引设置时,我需要帮助。 我有: from elasticsearch import Elasticsearch es = Elasticsearch(
我希望生成介于 1500 和 1650 之间的随机整数。 我已成功生成介于 25 和 55 之间的随机值(包括以下代码)。但是,我遇到的问题是,如果我修改代码以生成 1500 到 1650 之间的值(
背景 我正在使用 cx_Freeze 构建我的应用程序的 Windows 和 Mac 包;构建在两个平台上都成功执行,在 Windows 上生成 msi,在 Mac 上生成 dmg/app,我可以安装

我是一名优秀的程序员,十分优秀!