
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 31
31
 4
4


Disruptor的高性能,是多种技术结合以及本身架构的结果。本文主要讲源码,涉及到的相关知识点需要读者自行去了解,以下列出:
此节结合demo来看更容易理解:传送门 。
下图来自官方文档 。
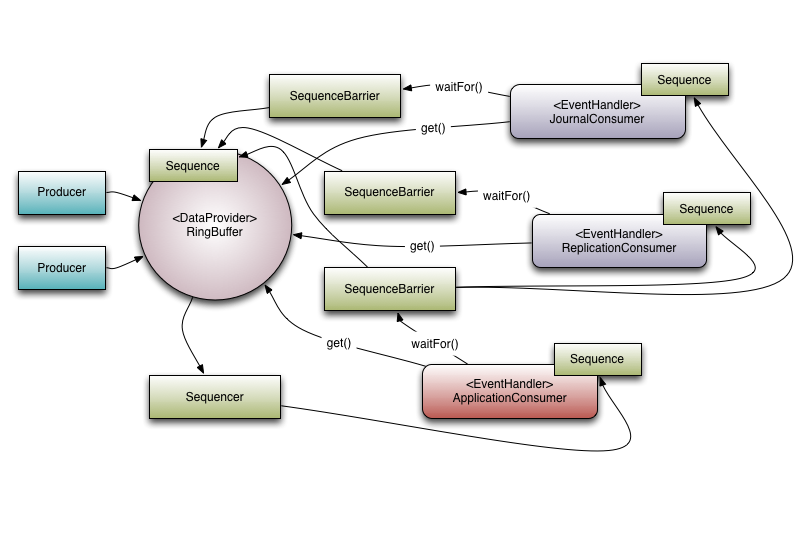
官方原图有点乱,我翻译一下 。
在讲原理前,先了解 Disruptor 定义的术语 。
Event 。
存放数据的单位,对应 demo 中的 LongEvent 。
Ring Buffer 。
环形数据缓冲区:这是一个首尾相接的环,用于存放 Event ,用于生产者往其存入数据和消费者从其拉取数据 。
Sequence 。
序列:用于跟踪进度(生产进度、消费进度) 。
Sequencer 。
Disruptor的核心,用于在生产者和消费者之间传递数据,有单生产者和多生产者两种实现.
Sequence Barrier 。
序列屏障,消费者之间的依赖关系就靠序列屏障实现 。
Wait Strategy 。
等待策略,消费者等待生产者将发布的策略 。
Event Processor 。
事件处理器,循环从 RingBuffer 获取 Event 并执行 EventHandler.
Event Handler 。
事件处理程序,也就是消费者 。
Producer 。
生产者 。
环形数据缓冲区(RingBuffer),逻辑上是首尾相接的环,在代码中用数组来表示 Object[] 。Disruptor生产者发布分两步 。
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
// 获取下一个可用位置的下标(步骤1)
long sequence = ringBuffer.next();
try {
// 返回可用位置的元素
LongEvent event = ringBuffer.get(sequence);
// 设置该位置元素的值
event.set(l);
} finally {
// 发布
ringBuffer.publish(sequence);
}
这两个步骤由 Sequencer 完成,分为单生产者和多生产者实现 。
如果申请 2 个元素,则如下图所示(圆表示 RingBuffer) 。
// 一般不会有以下写法,这里为了讲解源码才使用next(2)
// 向RingBuffer申请两个元素
long sequence = ringBuffer.next(2);
for (long i = sequence-1; i <= sequence; i++) {
try {
// 返回可用位置的元素
LongEvent event = ringBuffer.get(i);
// 设置该位置元素的值
event.set(1);
} finally {
ringBuffer.publish(i);
}
}
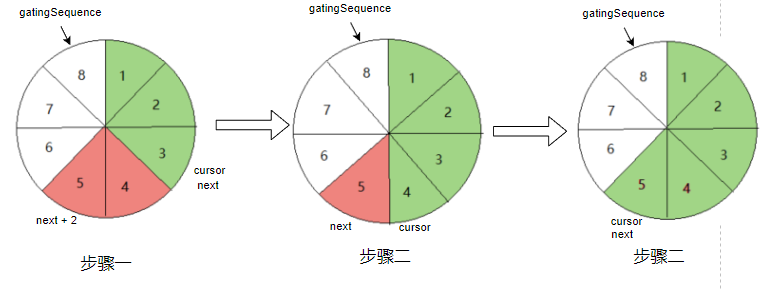
next 申请成功的序列,cursor 消费者最大可用序列,gatingSequence 表示能申请的最大序列号。红色表示待发布,绿色表示已发布。 申请相当于占位置,发布需要一个一个按顺序发布 。
如果 RingBuffer 满了呢,在上图步骤二的基础上,生产者发布了3个元素,消费者消费1个。此时生产者再申请 2个元素,就会变成下图所示 。
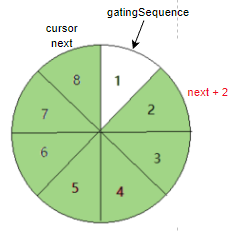
只剩下 1 个空间,但是要申请 2个元素,此时程序会自旋等待空间足够.
接下来结合代码看,单生产者的 Sequencer 实现为 SingleProducerSequencer,先看看构造方法 。
abstract class SingleProducerSequencerPad extends AbstractSequencer
{
protected long p1, p2, p3, p4, p5, p6, p7;
SingleProducerSequencerPad(int bufferSize, WaitStrategy waitStrategy)
{
super(bufferSize, waitStrategy);
}
}
abstract class SingleProducerSequencerFields extends SingleProducerSequencerPad
{
SingleProducerSequencerFields(int bufferSize, WaitStrategy waitStrategy)
{
super(bufferSize, waitStrategy);
}
long nextValue = Sequence.INITIAL_VALUE;
long cachedValue = Sequence.INITIAL_VALUE;
}
public final class SingleProducerSequencer extends SingleProducerSequencerFields
{
protected long p1, p2, p3, p4, p5, p6, p7;
public SingleProducerSequencer(int bufferSize, WaitStrategy waitStrategy)
{
super(bufferSize, waitStrategy);
}
}
这是 Disruptor 高性能的技巧之一,SingleProducerSequencer 需要的类变量只有 nextValue 和cachedValue,p1 ~ p7 的作用是填充缓存行,这能保证 nextValue 和cachedValue 必定在独立的缓存行,我们可以用 ClassLayout 打印内存布局看看 。
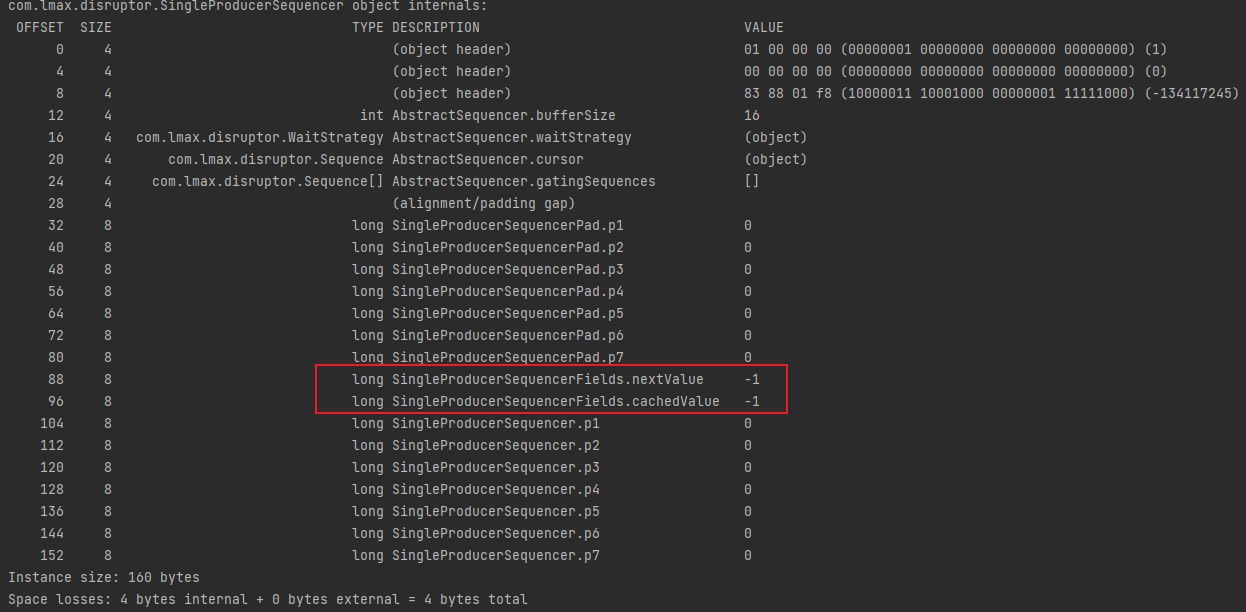
接下来看如何获取序列号(也就是步骤一) 。
// 调用路径
// RingBuffer#next()
// SingleProducerSequencer#next()
public long next(int n)
{
if (n < 1)
{
throw new IllegalArgumentException("n must be > 0");
}
long nextValue = this.nextValue;
//生产者当前序号值+期望获取的序号数量后达到的序号值
long nextSequence = nextValue + n;
//减掉RingBuffer的总的buffer值,用于判断是否出现‘覆盖’
long wrapPoint = nextSequence - bufferSize;
//从后面代码分析可得:cachedValue就是缓存的消费者中最小序号值,他不是当前最新的‘消费者中最小序号值’,而是上次程序进入到下面的if判定代码段时,被赋值的当时的‘消费者中最小序号值’
//这样做的好处在于:在判定是否出现覆盖的时候,不用每次都调用getMininumSequence计算‘消费者中的最小序号值’,从而节约开销。只要确保当生产者的节奏大于了缓存的cachedGateingSequence一个bufferSize时,从新获取一下 getMinimumSequence()即可。
long cachedGatingSequence = this.cachedValue;
//(wrapPoint > cachedGatingSequence) : 当生产者已经超过上一次缓存的‘消费者中最小序号值’(cachedGatingSequence)一个‘Ring’大小(bufferSize),需要重新获取cachedGatingSequence,避免当生产者一直在生产,但是消费者不再消费的情况下,出现‘覆盖’
//(cachedGatingSequence > nextValue) : https://github.com/LMAX-Exchange/disruptor/issues/76
// 这里判断就是生产者生产的填满BingBUffer,需要等待消费者消费
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > nextValue)
{
cursor.setVolatile(nextValue); // StoreLoad fence
//gatingSequences就是消费者队列末尾的序列,也就是消费者消费到哪里了
//实际上就是获得处理的队尾,如果队尾是current的话,说明所有的消费者都执行完成任务在等待新的事件了
long minSequence;
while (wrapPoint > (minSequence = Util.getMinimumSequence(gatingSequences, nextValue)))
{
// 等待1纳秒
LockSupport.parkNanos(1L); // TODO: Use waitStrategy to spin?
}
this.cachedValue = minSequence;
}
this.nextValue = nextSequence;
return nextSequence;
}
public void publish(long sequence)
{
// 更新序列号
cursor.set(sequence);
// 等待策略的唤醒
waitStrategy.signalAllWhenBlocking();
}
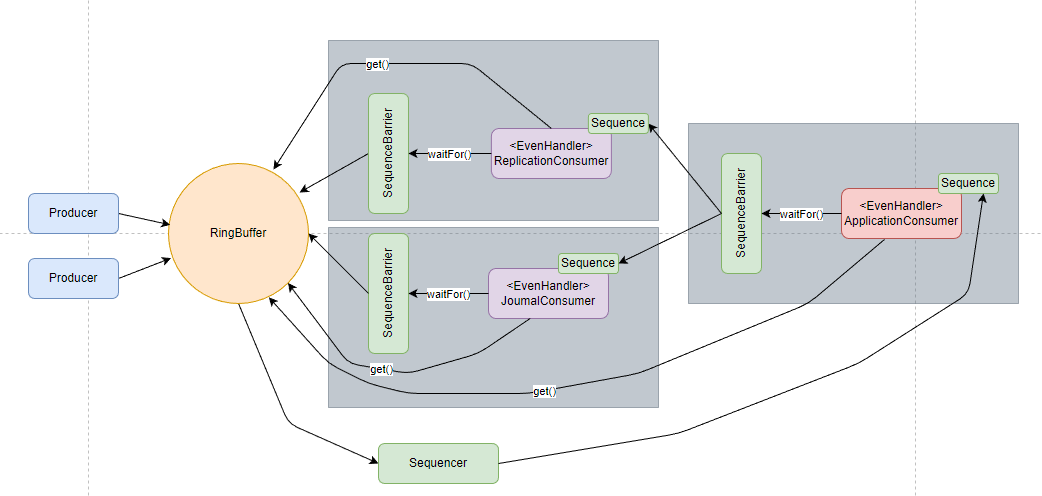
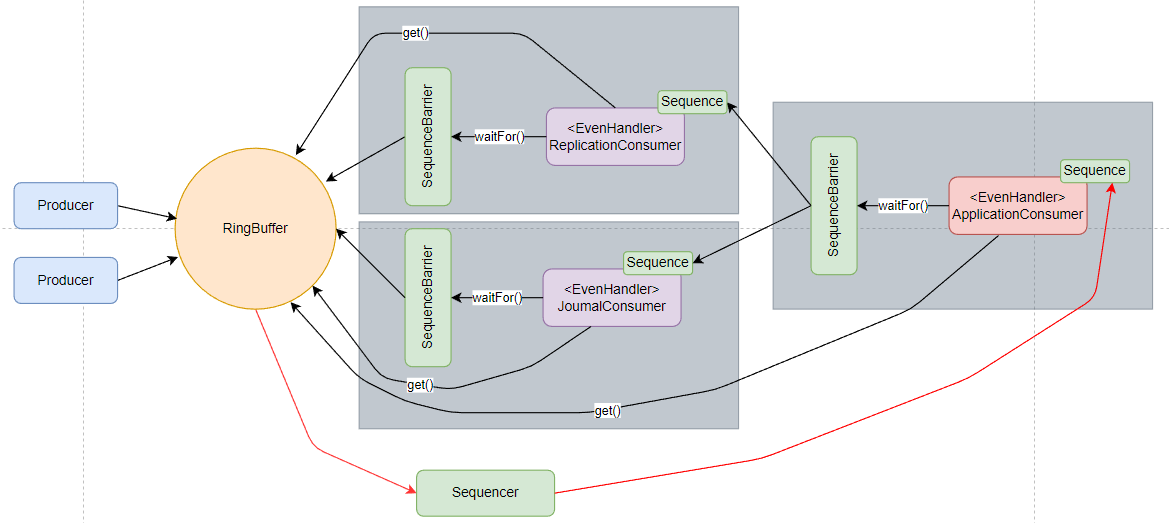
要解释的都在注释里了,gatingSequences 是消费者队列末尾的序列,对应着就是下图中的 ApplicationConsumer 的 Sequence 。
看完单生产者版,接下来看多生产者的实现。因为是多生产者,需要考虑并发的情况.
如果有A、B两个消费者都来申请 2 个元素 。
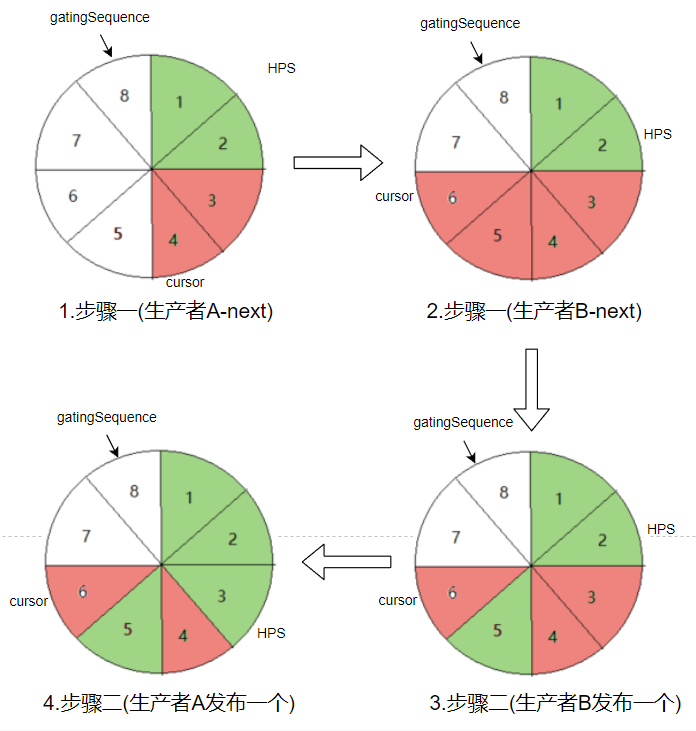
cursor 申请成功的序列,HPS 消费者最大可用序列,gatingSequence 表示能申请的最大序列号。红色表示待发布,绿色表示已发布。HPS 是我自己编的缩写,表示 getHighestPublishedSequence 方法的返回值 。
如图所示,只要申请成功,就移动 cursor 的位置。RingBuffer 并没有记录发布情况(图中的红绿颜色),这个发布情况由 MultiProducerSequencer 的 availableBuffer 来维护.
下面看代码 。
public final class MultiProducerSequencer extends AbstractSequencer
{
// 缓存的消费者中最小序号值,相当于SingleProducerSequencerFields的cachedValue
private final Sequence gatingSequenceCache = new Sequence(Sequencer.INITIAL_CURSOR_VALUE);
// 标记元素是否可用
private final int[] availableBuffer;
public long next(int n)
{
if (n < 1)
{
throw new IllegalArgumentException("n must be > 0");
}
long current;
long next;
do
{
current = cursor.get();
next = current + n;
//减掉RingBuffer的总的buffer值,用于判断是否出现‘覆盖’
long wrapPoint = next - bufferSize;
//从后面代码分析可得:cachedValue就是缓存的消费者中最小序号值,他不是当前最新的‘消费者中最小序号值’,而是上次程序进入到下面的if判定代码段时,被赋值的当时的‘消费者中最小序号值’
//这样做的好处在于:在判定是否出现覆盖的时候,不用每次都调用getMininumSequence计算‘消费者中的最小序号值’,从而节约开销。只要确保当生产者的节奏大于了缓存的cachedGateingSequence一个bufferSize时,从新获取一下 getMinimumSequence()即可。
long cachedGatingSequence = gatingSequenceCache.get();
//(wrapPoint > cachedGatingSequence) : 当生产者已经超过上一次缓存的‘消费者中最小序号值’(cachedGatingSequence)一个‘Ring’大小(bufferSize),需要重新获取cachedGatingSequence,避免当生产者一直在生产,但是消费者不再消费的情况下,出现‘覆盖’
//(cachedGatingSequence > nextValue) : https://github.com/LMAX-Exchange/disruptor/issues/76
// 这里判断就是生产者生产的填满BingBUffer,需要等待消费者消费
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current)
{
long gatingSequence = Util.getMinimumSequence(gatingSequences, current);
if (wrapPoint > gatingSequence)
{
LockSupport.parkNanos(1); // TODO, should we spin based on the wait strategy?
continue;
}
gatingSequenceCache.set(gatingSequence);
}
// 使用cas保证只有一个生产者能拿到next
else if (cursor.compareAndSet(current, next))
{
break;
}
}
while (true);
return next;
}
......
}
MultiProducerSequencer 和 SingleProducerSequencer 的 next()方法逻辑大致一样,只是多了CAS的步骤来保证并发的正确性。接着看发布方法 。
public void publish(final long sequence)
{
// 记录发布情况
setAvailable(sequence);
// 等待策略的唤醒
waitStrategy.signalAllWhenBlocking();
}
private void setAvailable(final long sequence)
{
// calculateIndex(sequence):获取序号
// calculateAvailabilityFlag(sequence):RingBuffer的圈数
setAvailableBufferValue(calculateIndex(sequence), calculateAvailabilityFlag(sequence));
}
private void setAvailableBufferValue(int index, int flag)
{
long bufferAddress = (index * SCALE) + BASE;
UNSAFE.putOrderedInt(availableBuffer, bufferAddress, flag);
// 上面相当于 availableBuffer[index] = flag 的高性能版
}
记录发布情况,其实相当于 availableBuffer[sequence] = 圈数 ,前面说了, availableBuffer 是用来标记元素是否可用的,如果消费者的圈数 ≠ availableBuffer中的圈数,则表示元素不可用 。
public boolean isAvailable(long sequence)
{
int index = calculateIndex(sequence);
// 计算圈数
int flag = calculateAvailabilityFlag(sequence);
long bufferAddress = (index * SCALE) + BASE;
// UNSAFE.getIntVolatile(availableBuffer, bufferAddress):相当于availableBuffer[sequence] 的高性能版
return UNSAFE.getIntVolatile(availableBuffer, bufferAddress) == flag;
}
private int calculateAvailabilityFlag(final long sequence)
{
// 相当于 sequence % bufferSize ,但是位操作更快
return (int) (sequence >>> indexShift);
}
isAvailable() 方法判断元素是否可用,此方法的调用堆栈看完消费者就清楚了.
本小节介绍两个方面,一是 Disruptor 的消费者如何实现依赖关系的,二是消费者如何拉取消息并消费 。
我们看回这张图,每个消费者前都有一个 SequenceBarrier ,这就是消费者之间能实现依赖的关键。每个消费者都有一个 Sequence,表示自身消费的进度,如图中,ApplicationConsumer 的 SequenceBarrier 就持有 ReplicaionConsumer 和 JournalConsumer 的 Sequence,这样就能控制 ApplicationConsumer 的消费进度不超过其依赖的消费者.
下面看源码,这是 disruptor 配置消费者的代码.
EventHandler journalConsumer = xxx;
EventHandler replicaionConsumer = xxx;
EventHandler applicationConsumer = xxx;
disruptor.handleEventsWith(journalConsumer, replicaionConsumer)
.then(applicationConsumer);
// 下面两行等同于上面这行
// disruptor.handleEventsWith(journalConsumer, replicaionConsumer);
// disruptor.after(journalConsumer, replicaionConsumer).then(applicationConsumer);
先看ReplicaionConsumer 和 JournalConsumer 的配置 disruptor.handleEventsWith(journalConsumer, replicaionConsumer) 。
/** 代码都在Disruptor类 **/
public final EventHandlerGroup<T> handleEventsWith(final EventHandler<? super T>... handlers)
{
// 没有依赖的消费者就创建新的Sequence
return createEventProcessors(new Sequence[0], handlers);
}
/**
* 创建消费者
* @param barrierSequences 当前消费者组的屏障序列数组,如果当前消费者组是第一组,则取一个空的序列数组;否则,barrierSequences就是上一组消费者组的序列数组
* @param eventHandlers 事件消费逻辑的EventHandler数组
*/
EventHandlerGroup<T> createEventProcessors(
final Sequence[] barrierSequences,
final EventHandler<? super T>[] eventHandlers)
{
checkNotStarted();
// 对应此事件处理器组的序列组
final Sequence[] processorSequences = new Sequence[eventHandlers.length];
final SequenceBarrier barrier = ringBuffer.newBarrier(barrierSequences);
for (int i = 0, eventHandlersLength = eventHandlers.length; i < eventHandlersLength; i++)
{
final EventHandler<? super T> eventHandler = eventHandlers[i];
// 创建消费者,注意这里传入了SequenceBarrier
final BatchEventProcessor<T> batchEventProcessor =
new BatchEventProcessor<>(ringBuffer, barrier, eventHandler);
if (exceptionHandler != null)
{
batchEventProcessor.setExceptionHandler(exceptionHandler);
}
consumerRepository.add(batchEventProcessor, eventHandler, barrier);
processorSequences[i] = batchEventProcessor.getSequence();
}
// 每次添加完事件处理器后,更新门控序列,以便后续调用链的添加
// 所谓门控,就是RingBuffer要知道在消费链末尾的那组消费者(也是最慢的)的进度,避免消息未消费就被写入覆盖
updateGatingSequencesForNextInChain(barrierSequences, processorSequences);
return new EventHandlerGroup<>(this, consumerRepository, processorSequences);
}
createEventProcessors() 方法主要做了3件事,创建消费者、保存eventHandler和消费者的映射关系、更新 gatingSequences 。
gatingSequences 我们在前面说过,生产者通过 gatingSequences 知道消费者的进度,防止生产过快导致消息被覆盖,更新操作在 updateGatingSequencesForNextInChain() 方法中 。
// 为消费链下一组消费者,更新门控序列
// barrierSequences是上一组事件处理器组的序列(如果本次是第一次,则为空数组),本组不能超过上组序列值
// processorSequences是本次要设置的事件处理器组的序列
private void updateGatingSequencesForNextInChain(final Sequence[] barrierSequences, final Sequence[] processorSequences)
{
if (processorSequences.length > 0)
{
// 将本组序列添加到Sequencer中的gatingSequences中
ringBuffer.addGatingSequences(processorSequences);
// 将上组消费者的序列从gatingSequences中移除
for (final Sequence barrierSequence : barrierSequences)
{
ringBuffer.removeGatingSequence(barrierSequence);
}
// 取消标记上一组消费者为消费链末端
consumerRepository.unMarkEventProcessorsAsEndOfChain(barrierSequences);
}
}
让我们把视线再回到消费者的设置方法 。
disruptor.handleEventsWith(journalConsumer, replicaionConsumer)
.then(applicationConsumer);
journalConsumer 和 replicaionConsumer 已经设置了,接下来是 applicationConsumer 。
/** 代码在EventHandlerGroup类 **/
public final EventHandlerGroup<T> then(final EventHandler<? super T>... handlers)
{
return handleEventsWith(handlers);
}
public final EventHandlerGroup<T> handleEventsWith(final EventHandler<? super T>... handlers)
{
return disruptor.createEventProcessors(sequences, handlers);
}
可以看到,设置 applicationConsumer 最终调用的也是 createEventProcessors() 方法,区别就在于 createEventProcessors() 方法的第一个参数,这里的 sequences 就是 journalConsumer 和 replicaionConsumer 这两个消费者的 Sequence 。
消费者的主要消费逻辑在 EventProcessor#run() 方法中,下面以 BatchEventProcessor 举例 。
// BatchEventProcessor#run()
// BatchEventProcessor#processEvents()
private void processEvents()
{
T event = null;
long nextSequence = sequence.get() + 1L;
while (true)
{
try
{
// 获取最大可用序列
final long availableSequence = sequenceBarrier.waitFor(nextSequence);
...
// 执行消费逻辑
while (nextSequence <= availableSequence)
{
// dataProvider就是RingBuffer
event = dataProvider.get(nextSequence);
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
nextSequence++;
}
sequence.set(availableSequence);
}
catch ()
{
// 异常处理
}
}
}
方法简洁明了,在死循环中通过 sequenceBarrier 获取最大可用序列,然后从 RingBuffer 中获取 Event 并调用 EventHandler 进行消费。重点在 sequenceBarrier.waitFor(nextSequence); 中 。
public long waitFor(final long sequence)
throws AlertException, InterruptedException, TimeoutException
{
checkAlert();
// 获取可用的序列,这里返回的是Sequencer#next方法设置成功的可用下标,不是Sequencer#publish
// cursorSequence:生产者的最大可用序列
// dependentSequence:依赖的消费者的最大可用序列
long availableSequence = waitStrategy.waitFor(sequence, cursorSequence, dependentSequence, this);
if (availableSequence < sequence)
{
return availableSequence;
}
// 获取最大的已发布成功的序号(对于发布是否成功的校验在此方法中)
return sequencer.getHighestPublishedSequence(sequence, availableSequence);
}
熟悉的 getHighestPublishedSequence() 方法,忘了就回去看看生产者小节。waitStrategy.waitFor() 对应着图片中的 waitFor() .
前面讲了消费者的处理逻辑,但是 BatchEventProcessor#run() 是如何被调用的呢,关键在于 disruptor.start(),
// Disruptor#start()
public RingBuffer<T> start()
{
checkOnlyStartedOnce();
for (final ConsumerInfo consumerInfo : consumerRepository)
{
consumerInfo.start(executor);
}
return ringBuffer;
}
class EventProcessorInfo<T> implements ConsumerInfo
{
public void start(final Executor executor)
{
// eventprocessor就是消费者
executor.execute(eventprocessor);
}
}
还记得 consumerRepository 吗,没有就往上翻翻设置消费者那里的 disruptor.handleEventsWith() 方法.
所以启动过程就是 disruptor#start() → ConsumerInfo#start() → Executor#execute() → EventProcessor#run() 。
课后作业:Disruptor 的消费者使用了多少线程?
本文讲了 Disruptor 大体逻辑和源码,当然其高性能的秘诀不止文中描述的那些。还有不同的等待策略,Sequence 中使用 Unsafe 而不是JDK中的 Atomic 原子类等等.
最后此篇关于Disruptor-源码解读的文章就讲到这里了,如果你想了解更多关于Disruptor-源码解读的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
31
4
 0
0
由于 RingBuffer 预先分配给定类型的对象,如何使用单个环形缓冲区来处理各种不同类型的消息? 您不能创建新的对象实例来插入到 ringBuffer 中,这会破坏预先分配的目的。 因此,您可以在
Disruptor 是否应该仅用于 POD 数据类型? 我的意思是应该Disruptor仅用于 T取值如 byte[], int[], etc ? 我的疑问是,如果我们使用 T其中有 Object引用
我有以下关于干扰器的问题: 消费者(事件处理器)没有实现他们实现的 EventHandler 的任何 Callable 或 Runnable 接口(interface),那么他们如何并行运行,例如,我
我有以下关于干扰器的问题: 消费者(事件处理器)没有实现他们实现的 EventHandler 的任何 Callable 或 Runnable 接口(interface),那么他们如何并行运行,例如,我
我们在生产中使用 LMAX Disruptor 已经将近一年了。一切都很好,直到上周我们看到 Disruptor 丢弃了消息。我们的 Disruptor 结构非常简单: Kafka -> RingBu
嗨, 目前我正在开发一个程序,它从 amq 队列中获取 2 个值并对它们执行一系列数学计算。在我的程序订阅并通过回调(监听器)接收消息的 amq 服务器上创建了一个主题。 现在,每当消息到达时,这两个
我们有一个具有固定长度数组的 Disruptor 实现。是否有可能实现一个不依赖于此数组的模式版本,而是包含(可能是自描述的)可变长度对象列表。例如,Protobuf 对象的 Ringbuffer?
前言 Disruptor是一个高性能的无锁并发框架,其主要应用场景是在高并发、低延迟的系统中,如金融领域的交易系统,游戏服务器等。其优点就是非常快,号称能支撑每秒600万订单。需要注意的是,D
前言 Disruptor的高性能,是多种技术结合以及本身架构的结果。本文主要讲源码,涉及到的相关知识点需要读者自行去了解,以下列出: 锁和CAS 伪共享和缓存行 v
Q1) 熟悉 Java Disruptor 模式的人是否知道他们对结果进行基准测试的消息大小?我正在编写一个类似的系统(出于纯粹的兴趣),当我阅读他们的测试描述时,没有提到发送的消息大小? http:
在disruptor(版本3.3.2)中,每个事件都是一个Runnable(因为EventProcessor扩展了runnable)。 我正在编写一个应用程序,每当EventHandler抛出异常时,
我正在研究LMAX Disruptor的源代码,我进入了RingBuffer抽象类。为什么 RingBufferPad 中正好有 7 个长字段 (p1 ... p7)?这是实际代码: https://
本文整理了Java中com.lmax.disruptor.YieldingWaitStrategy类的一些代码示例,展示了YieldingWaitStrategy类的具体用法。这些代码示例主要来源于G
我对 LMAX Disruptor 的理解它是一个 JAR,充满了速度惊人、并发的 Java 代码,每秒可实现 2000 万条消息的吞吐量(如果使用正确)。 我们目前的 ActiveMQ 实例对于我们
我正在使用 Disruptor-net在 C# 应用程序中。我在理解如何在破坏者模式中执行异步操作时遇到了一些困难。 假设我有几个事件处理程序,并且链中的最后一个将消息传递给我的业务逻辑处理器,我如何
有什么办法可以在一个结构中同时拥有这两种功能 - BlockingQueue 的语义,即非阻塞 peek、阻塞 poll 和阻塞 put。多个提供者一个消费者。 RingBuffer,它有效地充当对象
我正在使用 Disruptor-net在 C# 应用程序中。我在理解如何在破坏者模式中执行异步操作时遇到了一些困难。 假设我有几个事件处理程序,并且链中的最后一个将消息传递给我的业务逻辑处理器,我如何
我需要从 mongodb 存储和获取大量数据,所以我被要求使用 lmax Disruptor 接收和存储数据,我已经花了几天时间在 lmax github 帐户上寻找一个简单的教程,但我不太明白如何将
Disruptor github地址为:https://github.com/LMAX-Exchange/disruptor 我有一个简单的测试如下: public class DisruptorMa
我最近一直在学习 LMAX Disruptor 并进行了一些实验。令我困惑的一件事是 EventHandler 的 onEvent 处理程序方法的 endOfBatch 参数。考虑我的以下代码。首先,

我是一名优秀的程序员,十分优秀!