
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 31
31
 4
4


服务监控系列文章 。
服务监控系列视频 。
网络问题往往是性能排查中最复杂的一个问题,因为网络问题往往涉及的链路比较长,排查起来不仅仅是看本地机器的指标就可以了。本文将展示一个比较系统的排查网络问题的思路.
我们往往都是通过类似prometheus,grafana搭建的监控平台对机器的各项指标进行监控,其中就包括网络性能,当发现指标异常后,你就需要定位到具体的进程了,定位到进程还没完,你还需要定位到进程中是哪段代码引发的这个问题。整个过程你可以看到是一个大范围到小范围逐步定位的过程,大致分为3个步骤:
1,系统层面发现问题 。
2,定位到具体异常进程 。
3,定位到进程中引发异常的代码段 。
你就像侦探一样,一层层抽丝剥茧,排查过程十分有趣.
接下来,我们来挨个看看,具体每个步骤,我们应该如何做?
衡量网络性能,往往我们会根据几个重要的指标,来挨个看看.
首先是 网卡流入流出的流量 ,衡量流量大小也是有几种单位方式,MBS代表每秒多少个MB字节,Mbps代表每秒多少个M比特位,他们的换算关系是 MBS = Mbps / 8.
接着一个指标是 每秒收发包的数量 英文是pps,一个完整的网络请求是其实是分成很多个网络包进行发送的,在描述网卡性能时,一般都是将 流入流出流量大小和pps大小结合起来阐述.
然后是另一个指标 丢包数 当产生丢包行为时,可能会因为tcp的重传机制,让丢了的包重新发送到对端,但是重传必然会导致网络延迟的增大,当丢包数急剧上升时,我们也认为这是网络的一个异常表现.
丢包数或者丢包率指标我认为 是 pps和流入流出的流量 功能 不太一样的指标类型,pps和流入流出的流量我把它们称作流量类型的网络指标,通过它们,能够知道网络流量的大小,而丢包数 是则是形容网络传输的好坏.
好了,说完了几个指标,再谈谈如何用上系统工具来实际的观察下这些指标值,不然与纸上谈兵又有何异.
可以使用sar命令 每1秒统计一次网络接口的发包数以及进出流量,连续显示5次.
sar -n DEV 1 5
03:05:31 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
03:05:32 PM eth0 3.00 1.00 0.26 0.20 0.00 0.00 0.00
03:05:32 PM lo 138.00 138.00 40.56 40.56 0.00 0.00 0.00
IFACE:网络接口名称.
rxpck/s、txpck/s:每秒收或发的数据包数量.
rxkB/s、txkB/s:每秒收或发的字节数,以kB/s为单位.
rxcmp/s、txcmp/s:每秒收或发的压缩过的数据包数量.
rxmcst/s:每秒收到的多播数据包.
sar不能看到 丢包数的指标信息 ,因为丢包问题涉及的链路较长,我将放在此文的后面专门阐述。但是起码sar能够看pps以及进出流量了。不过这个只是从系统层面宏观的看网络情况,当你发现系统层面流量异常后,如何定位到是哪个进程导致流量异常的呢?
接下来,我们从进程的进程来看网络情况。观察的内容还是和系统层面差不多,不外乎就是进出流量,发送数据包等等。我将介绍两种工具,对比起系统层面看网络情况,它们能从更低的维度看网络情况.
首先是iftop 工具,它能找出是哪个ip消耗流量最多.
└─────────────────────┴─────────────────────┴──────────────────────┴─────────────────────┴──────────────────────
hw-sg1-test-0001 => 192.168.0.94 1.93Kb 3.35Kb 3.35Kb
<= 34.1Kb 99.1Kb 99.1Kb
hw-sg1-test-0001 => 192.168.0.133 3.36Kb 4.68Kb 4.68Kb
<= 17.5Kb 93.3Kb 93.3Kb
hw-sg1-test-0001 => 192.168.0.233 6.07Kb 5.03Kb 5.03Kb
<= 108Kb 90.3Kb 90.3Kb
hw-sg1-test-0001 => 192.168.0.119 0b 800b 800b
<= 0b 14.1Kb 14.1Kb
hw-sg1-test-0001 => 47.74.128.115 5.17Kb 1.72Kb 1.72Kb
<= 25.5Kb 8.50Kb 8.50Kb
hw-sg1-test-0001 => 192.168.0.95 0b 604b 604b
<= 0b 7.41Kb 7.41Kb
hw-sg1-test-0001 => ec2-3-120-42-58.eu-central-1.compute.amaz 1.63Kb 2.05Kb 2.05Kb
<= 0b 5.45Kb 5.45Kb
hw-sg1-test-0001 => 183.6.45.216 4.94Kb 5.05Kb 5.05Kb
<= 1.08Kb 920b 920b
hw-sg1-test-0001 => 192.168.0.107 2.48Kb 848b 848b
<= 12.1Kb 4.05Kb 4.05Kb
hw-sg1-test-0001 => 100.125.128.250 904b 1.41Kb 1.41Kb
<= 1.44Kb 2.50Kb 2.50Kb
hw-sg1-test-0001 => 47.74.249.92 0b 53b 53b
<= 0b 61b 61b
hw-sg1-test-0001 => 192.168.0.170 0b 53b 53b
<= 0b 53b 53b
hw-sg1-test-0001 => 172.21.2.153 0b 69b 69b
<= 0b 0b 0b
────────────────────────────────────────────────────────────────────────────────────────────────────────────────
TX: cum: 19.3KB peak: 30.1Kb rates: 26.5Kb 25.7Kb 25.7Kb
RX: 244KB 391Kb 199Kb 326Kb 326Kb
TOTAL: 264KB 417Kb 226Kb 351Kb 351Kb
=> 和<= 代表网络包的流向,每一行右边有3列变化的值,分别是在2s内,10s内,40s内的平均每秒流量的大小,而在iftop输出的最下面,则是系统整体的网络流量情况了。但是这样只能看ip,如果定位到进程呢?iftop可以根据目的地址和源地址聚合流量,当进入iftop输出界面时,按s就是按源地址聚合流量,按d则是按目的地址聚合流量。 默认iftop输出界面时不显示端口的,但如果要按端口维度对流量进行区分,需要在iftop输出界面,按S或者D,S和D分别代表按源地址的端口对流量进行划分,D代表按目的地址端口对流量进行划分.
当在iftop界面 分别按S和d后,将会得到主机上按端口维度进行区分的流量情况。如下所示:
hw-sg1-test-0001:wap-wsp => * 9.92Kb 10.5Kb 11.4Kb
<= 161Kb 117Kb 171Kb
hw-sg1-test-0001:64340 => * 0b 811b 608b
<= 0b 39.1Kb 29.4Kb
hw-sg1-test-0001:51338 => * 0b 810b 624b
<= 0b 38.7Kb 29.0Kb
这样便能看到主机上是哪个端口占用的流程最高了,有了端口就能很好的定位到进程了.
关于iftop一些高级用法可以通道man iftop去查看,这里就不再展开了 。
对比起iftop而言,有个更简单帮助我们查看进程上网络情况的工具,叫做nethogs.
查看进程占用带宽情况 ,命令如下:
sudo nethogs eth0
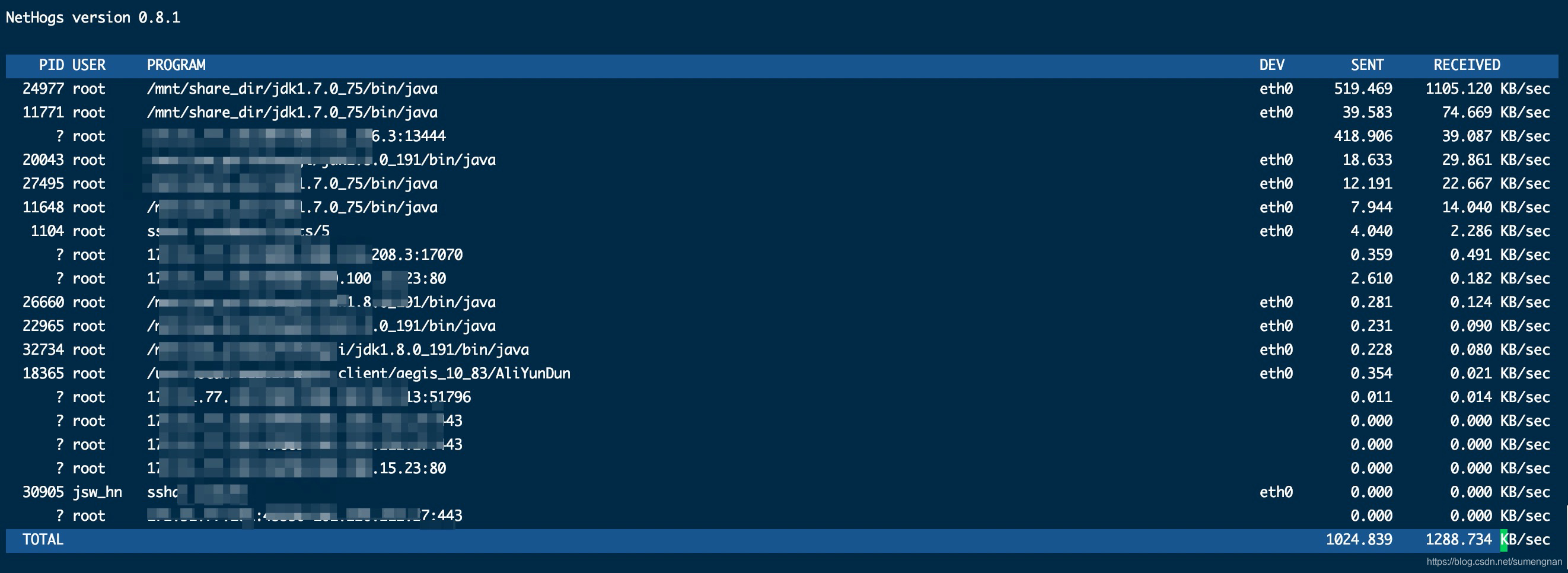
查看nethogs 的输出,每一行最后则是进程瞬时每秒的发送与接收的流量。通过nethogs,我们可以直接定位到是哪个进程有流量异常产生.
通过iftop和nethogs 命令,我们可以定位是哪个进程产生的流量异常了,但是如何定位到具体的代码呢?
由于我比较熟悉golang,这里介绍下用go开发的程序,可以怎么找出流量异常的代码,golang自带有分析网络延迟的工具 go trace可以查看网络调度延迟。 如果是go开发的程序 发生流量异常,相信通过go trace的grapgh能找到 网络延迟最高的一部分代码,定位到问题。关于go trace的原理以及使用,我在 golang pprof 监控系列(1) —— go trace 统计原理与使用 的详细的介绍.
有了上述的排查思路,相信在面对 流量异常 的情况,我们能很快的找到具体是哪段代码引发的异常了。接下来我们来谈谈如何排查丢包问题.
tcp ip模型已经成为事实标准,网络包会经过tcp,ip模型的几个层次,发送和接收的每一个步骤都有可能产生丢包。排查的过程则是检查每一个步骤是否有丢包行为产生.
首先来看下应用层丢包如何排查.
内核在监听套接字的时候,在三次握手时,会创建两个队列,在服务器收到syn 包时,会创建半连接队列,并将这条握手未完成的连接 放到里面,然后回复ack,syn包给客户端,当客户端回复ack时,内核会将这条连接放到全连接队列里,调用accept就是将连接从全连接队列里取出.
如果半连接队列或者全连接队列满了,则可能发生丢包行为.
半连接队列大小由内核参数tcp_max_syn_backlog定义.
sysctl -w net.ipv4.tcp_max_syn_backlog=1024
另外,上述行为受到内核参数tcp_syncookies的影响,若启用syncookie机制,当半连接队列溢出时,并不会直接丢弃SYN包,而是回复带有syncookie的SYN+ACK包,设计的目的是防范SYN Flood造成正常请求服务不可用.
sysctl -w net.ipv4.tcp_syncookies=1
如何确认是半连接导致的丢包呢,我们可以通过下面的命令.
dmesg | grep "TCP: drop open request from"
dmesg可以查看内核的输出日志,如果半连接有丢包产生,那么dmesg会看到对应的输出.
半连接队列的连接数量也可以通过netstat命令统计SYN_RECV状态的连接得知。因为在3次握手时,收到syn包的连接的状态是SYN_RECV状态,而整个状态的持续时间是很短的,如果用netstat发现SYN_RECV状态的连接非常多,则说明半连接队列可能满了.
netstat -ant|grep SYN_RECV|wc -l
接着我们来看下分析全连接队列相关的命令.
ss 命令可以查看全连接队列大小 。
# -l 显示正在监听
# -n 不解析服务名称
# -t 只显示 tcp socket
$ ss -lnt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 50 *:2181 *:*
LISTEN 0 32768 127.0.0.1:9200 *:*
LISTEN 0 32768 192.168.0.233:9200 *:*
Recv-Q:当前全连接队列的大小,也就是当前已完成三次握手并等待服务端 accept() 的 TCP 连接; Send-Q:当前全连接最大队列长度,上面的输出结果说明监听 8088 端口的 TCP 服务,最大全连接长度为 128; listen 的全连接大小可以在listen系统调用的时候指定 go源码里读取的是 /proc/sys/net/core/somaxconn 里的值.
# -n 不解析服务名称
# -t 只显示tcp socket
$ ss -nt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 0 192.168.0.233:27266 192.168.0.129:3306
ESTAB 0 0 192.168.0.233:30212 192.168.0.129:3306
ESTAB 0 0 192.168.0.233:8000 100.125.64.81:44948
Recv-Q:已收到但未被应用进程读取的字节数; Send-Q:已发送但未收到确认的字节数; 。
当全连接队列满了后,默认内核会将包丢弃,但是也可以指定其他策略.
cat /proc/sys/net/ipv4/tcp_abort_on_overflow
0
0 :如果全连接队列满了,那么 server 扔掉 client 发过来的 ack ; 1 :如果全连接队列满了,server 发送一个 reset 包给 client,表示废掉这个握手过程和这个连接; 。
通过查看应用层的全连接队列的相关指标,相信你能够定位 那些由于应用进程处理包缓慢导致的丢包场景了,因为应用进程处理包缓慢,持续小于 网卡的接包速度的话,将导致全连接队列很快就满了,导致丢包.
接着我们来看下传输层,网络层的丢包场景.
之所以把这两者放到一起进行讲解,因为很多工具的分析都横跨了这两个层次.
先来看下其中的防火墙导致丢包的情况,除了防火墙本身配置DROP规则导致丢包外,与防火墙有关的还有连接跟踪表nf_conntrack,Linux为每个经过内核网络栈的数据包,生成一个新的连接记录项,当服务器处理的连接过多时,连接跟踪表被打满,服务器会丢弃新建连接的数据包.
以下命令可以查看nf_conntrack表最大连接数 。
$ cat /proc/sys/net/netfilter/nf_conntrack_max
65536
# 查看nf_conntrack表当前连接数
$ cat /proc/sys/net/netfilter/nf_conntrack_count
7611
用nstat命令 查看网络协议层丢包情况以及丢包原因,命令如下.
[webserver@hw-sg1-test-0001 ~]$ nstat -az | grep -i drop
TcpExtLockDroppedIcmps 0 0.0
TcpExtListenDrops 939 0.0
TcpExtTCPPrequeueDropped 0 0.0
TcpExtTCPBacklogDrop 10684 0.0
TcpExtTCPMinTTLDrop 0 0.0
TcpExtTCPDeferAcceptDrop 0 0.0
TcpExtTCPReqQFullDrop 0 0.0
TcpExtTCPOFODrop 0 0.0
其实netstat -s命令也可以看tcp层的丢包情况,不过我还是强烈建议将 它换为nstat 命令因为nstat效率更高,并且统计的内容命名也更符合rfc文档规范.
nstat 除了列出丢包的情况,还有其他统计信息,具体每个指标的含义可以参考 这个文档 。
此外,网络层 mtu的设置有时可能导致丢包的产生,如果发送的mtu包的大小超过网卡规定的大小,并且网卡不允许分片,那么则会产生丢包.
接着就是链路层丢包的场景了.
链路层是物理网卡丢包的场景了,统计链路层丢包的数据可以用netstat得到。 netstat 可以统计网卡环形缓冲区溢出(RX-OVR,TX-OVR),以及网卡发生错误(RX-ERR,TX-ERR)的次数.
root@nginx:/# netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 100 157 0 344 0 94 0 0 0 BMRU
lo 65536 0 0 0 0 0 0 0 0 LRU
最后此篇关于不要再说你不会了——网络性能问题排查思路的文章就讲到这里了,如果你想了解更多关于不要再说你不会了——网络性能问题排查思路的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
31
4
 0
0
尝试使用集成到 QTCreator 的表单编辑器,但即使我将插件放入 QtCreator.app/Contents/MacOS/designer 也不会显示。不过,相同的 dylib 文件确实适用于独
在此代码示例中。 “this.method2();”之后会读到什么?在返回returnedValue之前会跳转到method2()吗? public int method1(int returnedV
我的项目有通过gradle配置的依赖项。我想添加以下依赖项: compile group: 'org.restlet.jse', name: 'org.restlet.ext.apispark', v
我将把我们基于 Windows 的客户管理软件移植到基于 Web 的软件。我发现 polymer 可能是一种选择。 但是,对于我们的使用,我们找不到 polymer 组件具有表格 View 、下拉菜单
我的项目文件夹 Project 中有一个文件夹,比如 ED 文件夹,当我在 Eclipse 中指定在哪里查找我写入的文件时 File file = new File("ED/text.txt"); e
这是奇怪的事情,这个有效: $('#box').css({"backgroundPosition": "0px 250px"}); 但这不起作用,它只是不改变位置: $('#box').animate
这个问题在这里已经有了答案: Why does OR 0 round numbers in Javascript? (3 个答案) 关闭 5 年前。 Mozilla JavaScript Guide
这个问题在这里已经有了答案: Is the function strcmpi in the C standard libary of ISO? (3 个答案) 关闭 8 年前。 我有一个问题,为什么
我目前使用的是共享主机方案,我不确定它使用的是哪个版本的 MySQL,但它似乎不支持 DATETIMEOFFSET 类型。 是否存在支持 DATETIMEOFFSET 的 MySQL 版本?或者有计划
研究 Seam 3,我发现 Seam Solder 允许将 @Named 注释应用于包 - 在这种情况下,该包中的所有 bean 都将自动命名,就好像它们符合条件一样@Named 他们自己。我没有看到
我知道 .append 偶尔会增加数组的容量并形成数组的新副本,但 .removeLast 会逆转这种情况并减少容量通过复制到一个新的更小的数组来改变数组? 最佳答案 否(或者至少如果是,则它是一个错
很难说出这里要问什么。这个问题模棱两可、含糊不清、不完整、过于宽泛或夸夸其谈,无法以目前的形式得到合理的回答。如需帮助澄清此问题以便重新打开,visit the help center . 关闭 1
noexcept 函数说明符是否旨在 boost 性能,因为生成的对象中可能没有记录异常的代码,因此应尽可能将其添加到函数声明和定义中?我首先想到了可调用对象的包装器,其中 noexcept 可能会产
我正在使用 Angularjs 1.3.7,刚刚发现 Promise.all 在成功响应后不会更新 angularjs View ,而 $q.all 会。由于 Promises 包含在 native
我最近发现了这段JavaScript代码: Math.random() * 0x1000000 10.12345 10.12345 >> 0 10 > 10.12345 >>> 0 10 我使用
我正在编写一个玩具(物理)矢量库,并且遇到了 GHC 坚持认为函数应该具有 Integer 的问题。是他们的类型。我希望向量乘以向量以及标量(仅使用 * ),虽然这可以通过仅使用 Vector 来实现
PHP 的 mail() 函数发送邮件正常,但 Swiftmailer 的 Swift_MailTransport 不起作用! 这有效: mail('user@example.com', 'test
我尝试通过 php 脚本转储我的数据,但没有命令行。所以我用 this script 创建了我的 .sql 文件然后我尝试使用我的脚本: $link = mysql_connect($host, $u
使用 python 2.6.4 中的 sqlite3 标准库,以下查询在 sqlite3 命令行上运行良好: select segmentid, node_t, start, number,title
我最近发现了这段JavaScript代码: Math.random() * 0x1000000 10.12345 10.12345 >> 0 10 > 10.12345 >>> 0 10 我使用

我是一名优秀的程序员,十分优秀!