
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 30
30
 4
4


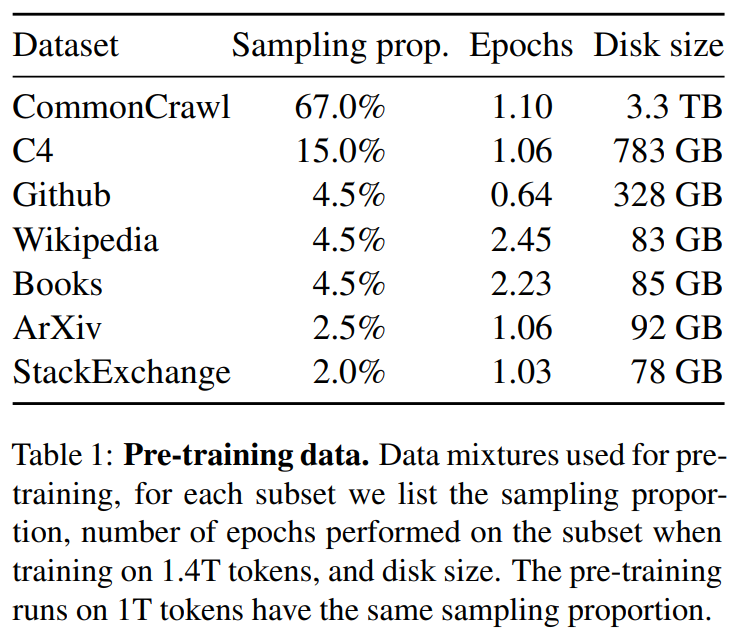
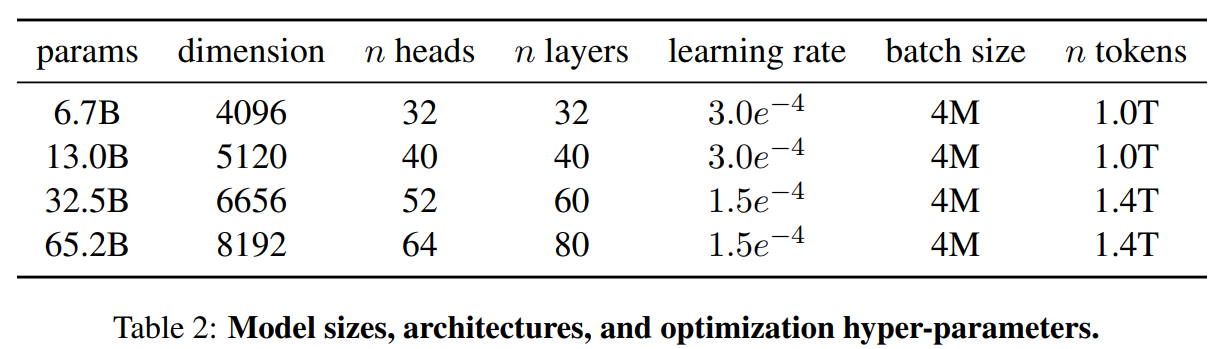
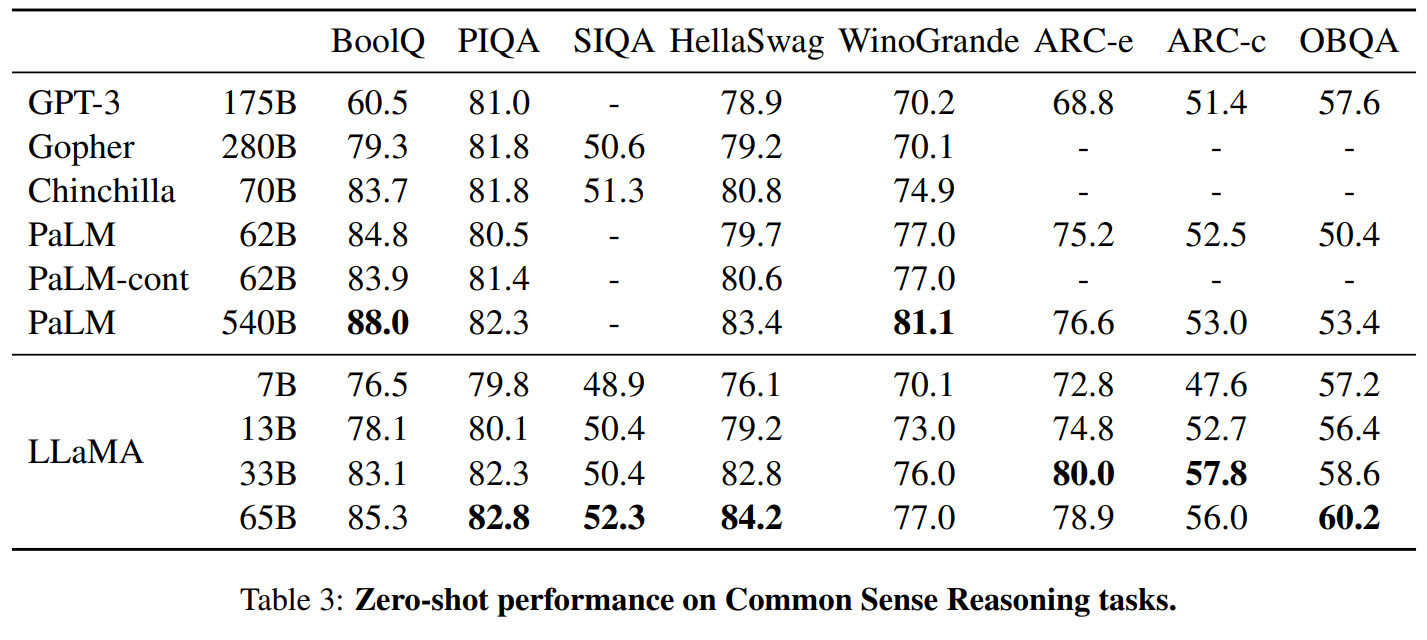
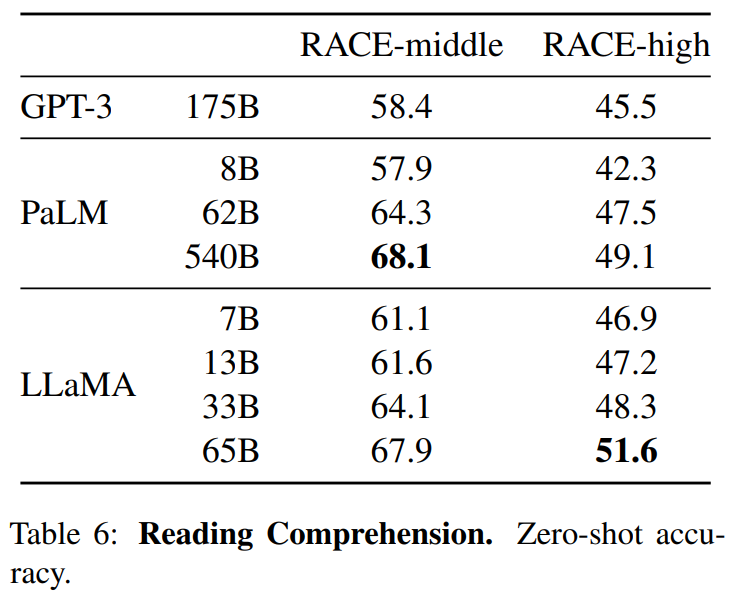
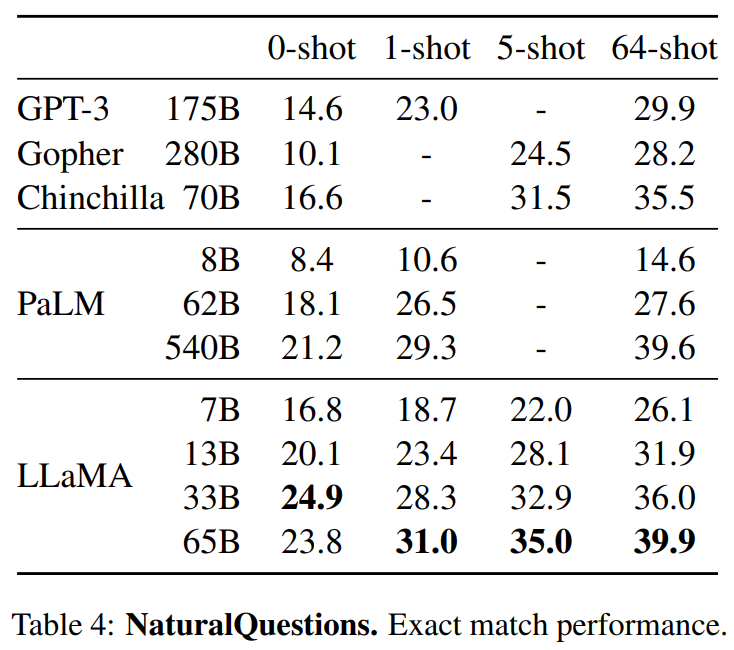
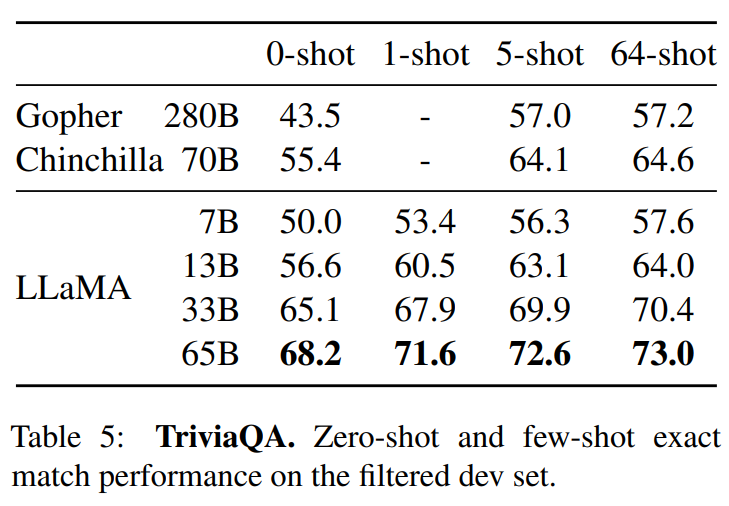
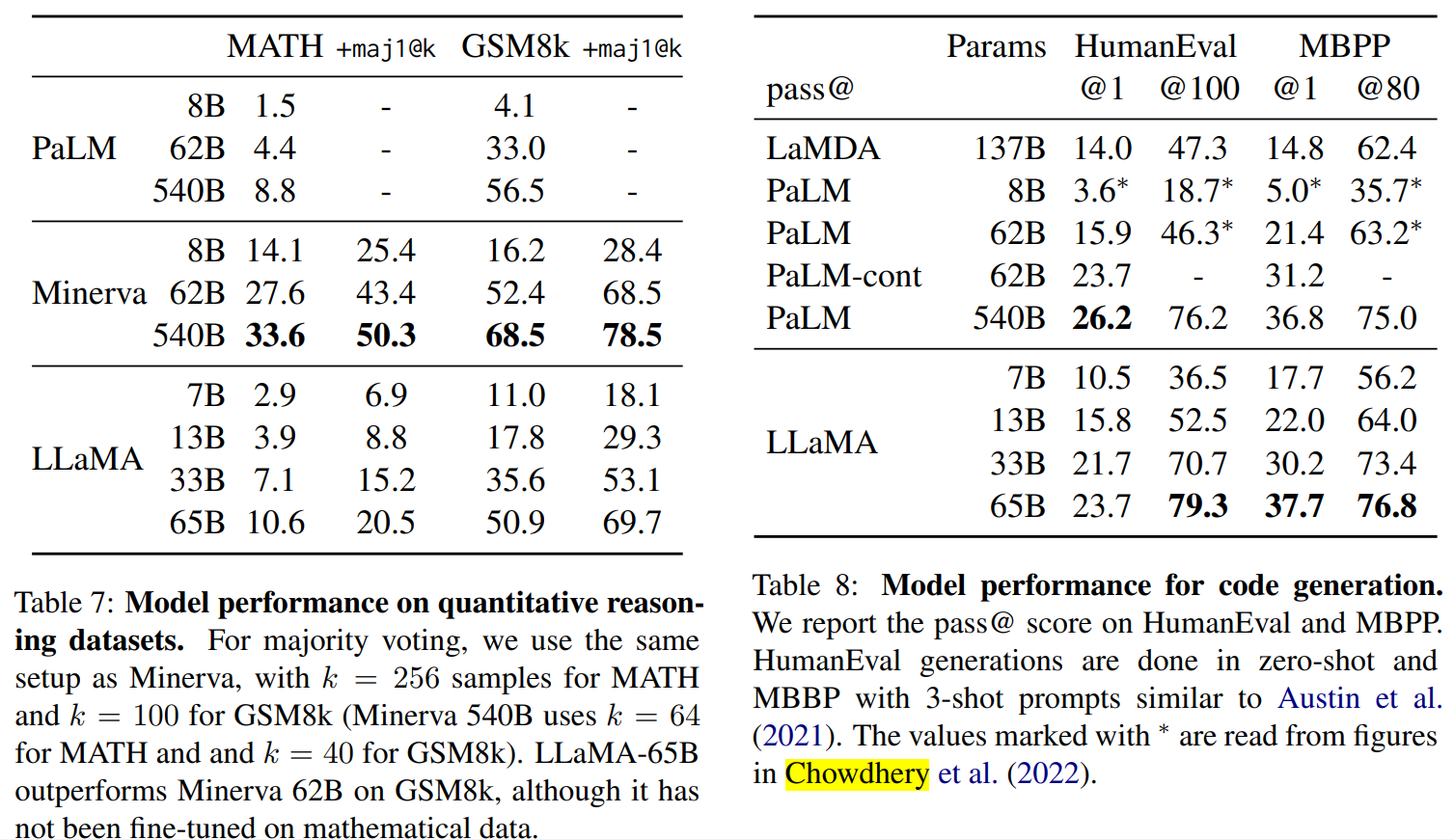
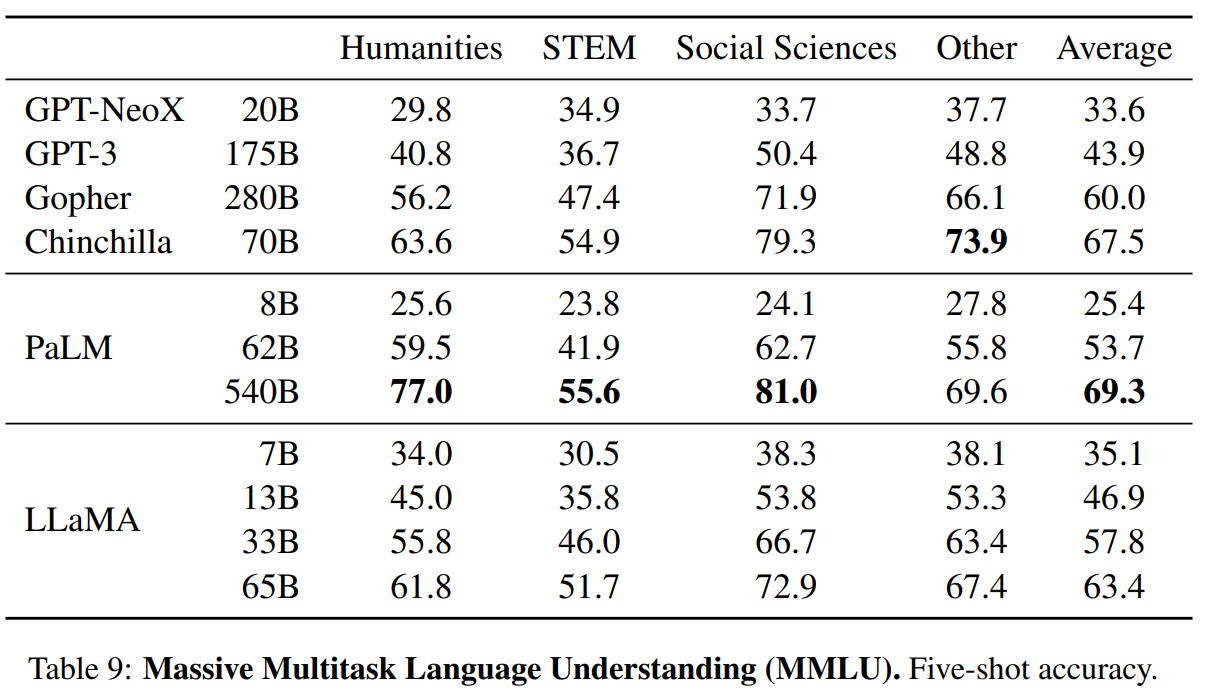
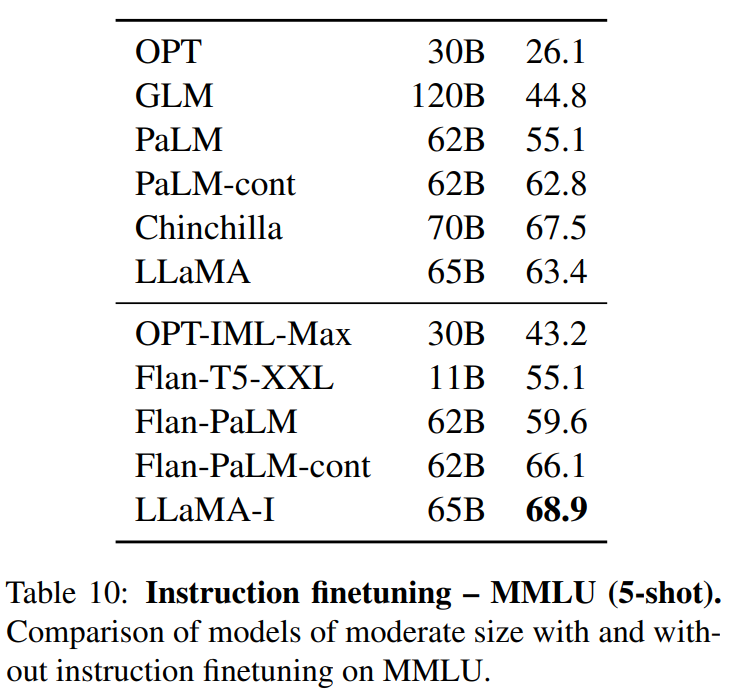
LLaMA:开放和高效的基础语言模型 。 https://arxiv.org/pdf/2302.13971.pdf 。 https://github.com/facebookresearch/llama 。 我们介绍了LLaMA,这是一个参数范围从7B到65B的基础语言模型集合。我们在数以万亿计的标记上训练我们的模型,并表明有可能完全使用公开可用的数据集来训练最先进的模型,而不必求助于专有的和不可获取的数据集。特别是,LLaMA-13B 在大多数基准上超过了GPT-3(175B), LLaMA-65B与最好的模型Chinchilla-70B和PaLM-540B相比具有竞争力。我们向研究界发布了我们所有的模型. 总结: 英语CommonCrawl[67%] :我们用CCNet管道( Wenzek等人 , 2020年)对五个CommonCrawl转储进行预处理,范围从2017年到2020年。这个过程在行的层面上对数据进行了删除,用fastText线性分类器进行语言识别,以去除非英语页面,并用n-gram语言模型过滤低质量内容。此外,我们训练了一个线性模型来对维基百科中用作参考文献的页面与随机抽样的页面进行分类,并丢弃了未被分类为参考文献的页面. C4 [15%] :在探索性的实验中,我们观察到,使用多样化的预处理Com-monCrawl数据集可以提高性能。因此,我们将公开的C4数据集( Raffel等人,2020)纳入我们的数据。C4的预处理也包含重复数据删除和语言识别步骤:与CCNet的主要区别在于质量过滤,它主要依赖于标点符号的存在或网页中的单词和句子的数 量等判例. Github[4.5%] :我们使用谷歌BigQuery上的GitHub公共数据集。我们只保留在Apache、BSD和MIT许可下发布的项目。此外,我们用基于行长或字母数字字符比例的启发式方法过滤了低质量的文件,并用规范的表达式删除了模板,如标题。最后,我们在文件层面上对结果数据集进行重复计算,并进行精确匹配. 维基百科[4.5%] :我们添加了2022年6月至8月期间的维基百科转储,涵盖了20使用拉丁字母或西里尔字母的语言:BG、CA、CS、DA、DE、EN、ES、FR、HR、HU、IT、NL、PL、PT、RO、RU、SL、SR、SV、UK。我们对数据进行处理,以删除超链接、评论和其他格式化的模板. 古腾堡和Books3[4.5%] :我们的训练数据 包括两个书体:Guten- berg项目和TheP-ile( Gao等人,2020)的Books3部分,后者是一个用于训练大型语言模型的公开可用数据集。我们在书籍层面上进行重复数据删除,删除内容重叠度超过90%的书籍. ArXiv[2.5%] : 我们处理了arXiv的Latex文件,将科学数据添加到我们的数据集中。按照Lewkowycz等人(2022)的做法,我们删除了第一节之前的所有内容,以及书目。我们还删除了.tex文件中的注释,以及用户写的内联扩展的定义和宏,以提高不同论文的一致性. Stack Exchange[2%] :我们包括了Stack Exchange的转储,这是一个高质量的问题和答案的网站,涵盖了从计算机科学到化学等不同的领域。我们保留了28个最大网站的数据,重新将HTML标签从文本中移出,并将答案按分数(从高到低)排序. 标记器 : 我们用字节对编码(BPE)算法( Sennrich等人,2015)对数据进行标记,使用 Sentence-Piece(Kudo和Richardson,2018)中的实现。值得注意的是,我们将所有数字分割成单个数字,并回退到字节来分解未知的UTF-8字符. 总的来说,我们的整个训练数据集在标记化之后大约包含1.4T的标记。对于我们的大多数训练数据,每个标记在训练过程中只使用一次,但维基百科和图书领域除外,我们对其进行了大约两个epochs训练. 基本还是transformer结构,主要是以下一些不同: 预归一化[GPT3] :为了提高训练的稳定性,我们对每个transformer子层的输入进行规范化,而不是对输出进行规范化。我们使用Zhang和Sennrich(2019)介绍的RMSNorm归一化函数. SwiGLU激活函数[PaLM] :我们用SwiGLU激活函数替换ReLU的非线性,由Shazeer(2020)引入以提高性能。我们使用的维度是$\frac{2}{3}4d$,而不是PaLM中的4d. 旋转嵌入[GPTNeo] :我们删除了绝对位置嵌入,取而代之的是在网络的每一层添加Su等人(2021)介绍的旋转位置嵌入(RoPE)。表2中给出了我们不同模型的超参数细节. 我们的模型使用 AdamW optimizer( Loshchilov和Hutter,2017)进行训练,超参数如下:β1 = 0.9,β2 = 0.95。我们使用一个余弦学习率计划,使最终的学习率等于最大的10%。我们使用0.1的权重衰减和梯度剪裁为1.0。我们使用2,000个预热步骤,并随着模型的大小而改变学习率和批次大小(详见表2). 我们进行了一些优化,以提高我们模型的训练速度。首先,我们使用causal multi-head attention,以减少内存使用和运行时间。这个实现可在xformers库中找到。这是通过不存储注意力权重和不计算由于语言建模任务的因果性质而被掩盖的键/查询分数来实现的. 为了进一步提高训练效率,我们重新缩减了在后向传递过程中建议使用的激活量。更确切地说,我们保存了计算成本较高的激活,如线性层的输出。这是通过手动实现transformer层的后向函数来实现的,而不是依靠PyTorch的autograd。为了充分受益于这种优化,我们需要如Korthikanti等人(2022)所述,通过使用模 型和序列并行,减少模型的内存使用。此外,我们还尽可能地过度重视激活的计算和GPU之间通过网络的通信(由于all_reduce操作)。当训练一个65B参数的模型时,我们的代码在2048个A100GPU和80GB的内存上处理大约380个令牌/秒/GPU。 这意味着在我们包含1.4T标记的数据集上进行训练大约需要21天. Part1 前言
Part2 方法
1 使用的数据
2 标记器
Part3 模型结构
3 优化器
4 高效的实现
Part4 结果
最后此篇关于LLaMA:开放和高效的基础语言模型的文章就讲到这里了,如果你想了解更多关于LLaMA:开放和高效的基础语言模型的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
30
4
 0
0
至少在某些 ML 系列语言中,您可以定义可以执行模式匹配的记录,例如http://learnyouahaskell.com/making-our-own-types-and-typeclasses -
这可能是其他人已经看到的一个问题,但我正在尝试寻找一种专为(或支持)并发编程而设计的语言,该语言可以在 .net 平台上运行。 我一直在 erlang 中进行辅助开发,以了解该语言,并且喜欢建立一个稳
As it currently stands, this question is not a good fit for our Q&A format. We expect answers to be
我正在寻找一种进程间通信工具,可以在相同或不同系统上运行的语言和/或环境之间使用。例如,它应该允许在 Java、C# 和/或 C++ 组件之间发送信号,并且还应该支持某种排队机制。唯一明显与环境和语言
我有一些以不同语言返回的文本。现在,客户端返回的文本格式为(en-us,又名美国英语): Stuff here to keep. -- Delete Here -- all of this below
问题:我希望在 R 中找到类似 findInterval 的函数,它为输入提供一个标量和一个表示区间起点的向量,并返回标量落入的区间的索引。例如在 R 中: findInterval(x = 2.6,
我是安卓新手。我正在尝试进行简单的登录 Activity ,但当我单击“登录”按钮时出现运行时错误。我认为我没有正确获取数据。我已经检查过,SQLite 中有一个与该 PK 相对应的数据。 日志猫。
大家好,感谢您帮助我。 我用 C# 制作了这个计算器,但遇到了一个问题。 当我添加像 5+5+5 这样的东西时,它给了我正确的结果,但是当我想减去两个以上的数字并且还想除或乘以两个以上的数字时,我没有
关闭。此题需要details or clarity 。目前不接受答案。 想要改进这个问题吗?通过 editing this post 添加详细信息并澄清问题. 已关闭 4 年前。 Improve th
这就是我所拥有的 #include #include void print(int a[], int size); void sort (int a[], int size); v
你好,我正在寻找我哪里做错了? #include #include int main(int argc, char *argv[]) { int account_on_the_ban
嘿,当我开始向数组输入数据时,我的代码崩溃了。该程序应该将数字读入数组,然后将新数字插入数组中,最后按升序排列所有内容。我不确定它出了什么问题。有人有建议吗? 这是我的代码 #include #in
我已经盯着这个问题好几个星期了,但我一无所获!它不起作用,我知道那么多,但我不知道为什么或出了什么问题。我确实知道开发人员针对我突出显示的行吐出了“错误:预期表达式”,但这实际上只是冰山一角。如果有人
我正在编写一个点对点聊天程序。在此程序中,客户端和服务器功能写入一个唯一的文件中。首先我想问一下我程序中的机制是否正确? I fork() two processes, one for client
基本上我需要找到一种方法来发现段落是否以句点 (.) 结束。 此时我已经可以计算给定文本的段落数,但我没有想出任何东西来检查它是否在句点内结束。 任何帮助都会帮助我,谢谢 char ch; FI
我的函数 save_words 接收 Armazena 和大小。 Armazena 是一个包含段落的动态数组,size 是数组的大小。在这个函数中,我想将单词放入其他称为单词的动态数组中。当我运行它时
我有一个结构 struct Human { char *name; struct location *location; int
我正在尝试缩进以下代码的字符串输出,但由于某种原因,我的变量不断从文件中提取,并且具有不同长度的噪声或空间(我不确定)。 这是我的代码: #include #include int main (v
我想让用户选择一个选项。所以我声明了一个名为 Choice 的变量,我希望它输入一个只能是 'M' 的 char 、'C'、'O' 或 'P'。 这是我的代码: char Choice; printf
我正在寻找一种解决方案,将定义和变量的值连接到数组中。我已经尝试过像这样使用 memcpy 但它不起作用: #define ADDRESS {0x00, 0x00, 0x00, 0x00, 0x0

我是一名优秀的程序员,十分优秀!