
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 29
29
 4
4


承接之前的【精华推荐 |【算法数据结构专题】「延时队列算法」史上非常详细分析和介绍如何通过时间轮(TimingWheel)实现延时队列的原理指南】,让我们基本上已经知道了「时间轮算法」原理和核心算法机制,接下来我们需要面向于实战开发以及落地角度进行分析如何实现时间轮的算法机制体系.
相比传统的队列形式的调度器来说,时间轮能够批量高效的管理各种延时任务、周期任务、通知任务等等。例如延时队列/延时任务体系 。
**延时任务、周期性任务,应用场景主要在延迟大规模的延时任务、周期性的定时任务等.
比如,对于耗时的网络请求( 比如Produce时等待ISR副本复制成功 )会被封装成DelayOperation进行延迟处理操作,防止阻塞Kafka请求处理线程,从而影响效率和性能.
Kafka没有使用传统的队列机制(JDK自带的Timer+DelayQueue实现)。因为 时间复杂度 上这两者插入和删除操作都是 O(logn),不能满足Kafka的高性能要求.
JDK Timer和DelayQueue底层都是个优先队列,即采用了minHeap的数据结构,最快需要执行的任务排在队列第一个,不一样的是Timer中有个线程去拉取任务执行,DelayQueue其实就是个容器,需要配合其他线程工作.
ScheduledThreadPoolExecutor是JDK的定时任务实现的一种方式,其实也就是DelayQueue+池化线程的一个实现 .
时间轮算法的插入删除操作都是O(1)的时间复杂度,满足了Kafka对于性能的要求。除了Kafka以外,像 Netty 、ZooKeepr、Dubbo等开源项目、甚至Linux内核中都有使用到时间轮的实现.
当流量小时,使用DelayQueue效率更高。当流量大事,使用时间轮将大大提高效率.
数据结构模型主要由:时间轮环形队列和时间轮任务列表组成.
时间轮(TimingWheel) 是一个存储定时任务的 环形队列(cycle array) ,底层采用环形数组实现,数组中的每个元素可以对应一个 时间轮任务任务列表(TimeWheelTaskList) .
时间轮任务任务列表(TimeWheelTaskList) 是一个环形的双向链表,其中的每个元素都是延时/定时任务项(TaskEntry),其中封装了任务基本信息和元数据(Metadata).
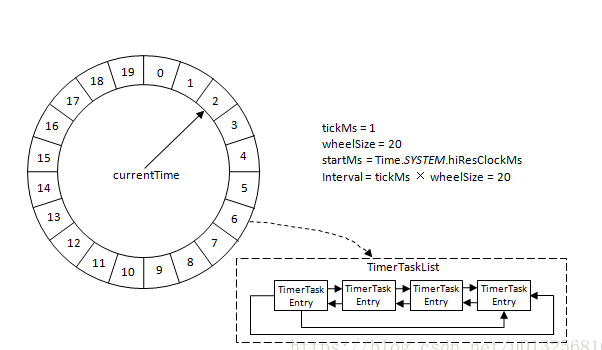
可以看到图中的几个参数:
startMs: 开始时间 。
tickMs: 时间轮执行的最小单位 。 时间轮 由多个时间格组成,每个 时间格 代表当前时间轮的基本时间跨度就是tickMs.
wheelSize: 时间轮中环形队列的数量 。 时间轮 的时间格数量是固定的,可用wheelSize来表示.
interval: 时间轮的整体时间跨度 = tickMs * wheelSize 。
根据上面这两个属性,我们就可以讲整个时间轮的总体时间跨度(interval)可以通过公式tickMs × wheelSize计算得出。例如果时间轮的 tickMs=1ms , wheelSize=20 ,那么可以计算得出interval为 20ms .
此外,时间轮还有一个游标指针,我们称之为(currentTime),它用来表示时间轮当前所处的时间,currentTime是tickMs的整数倍.
整个时间轮的总体跨度是不变的,随着指针currentTime的不断流动,当前时间轮所能处理的时间段也在不断后移,整个时间轮的时间范围在currentTime和currentTime+interval之间.
currentTime可以将整个时间轮划分为到期部分和未到期部分,currentTime当前指向的时间格也属于到期部分,表示刚好到期,需要处理此时间格所对应的TimeWheelTaskList中的所有任务.
初始情况下表盘指针currentTime指向时间格0,此时有一个定时为2ms的任务插入进来会存放到时间格为2的任务列表中.
随着时间的不断推移,指针currentTime不断向前推进,过了2ms之后,当到达时间格2时,就需要将时间格2所对应的任务列表中的任务做相应的到期操作.
此时若又有一个定时为8ms的任务插入进来,则会存放到时间格10中,currentTime再过8ms后会指向时间格10.
总之,整个时间轮的总体跨度是不变的,随着指针currentTime的不断推进,当前时间轮所能处理的时间段也在不断后移,总体时间范围在currentTime和currentTime+interval之间 .
如果当提交了超过整体跨度(interval)的延时任务,如何解决呢?因此引入了层级时间轮的概念,当任务的到期时间超过了当前时间轮所表示的时间范围时,就会尝试添加到层次时间轮中.
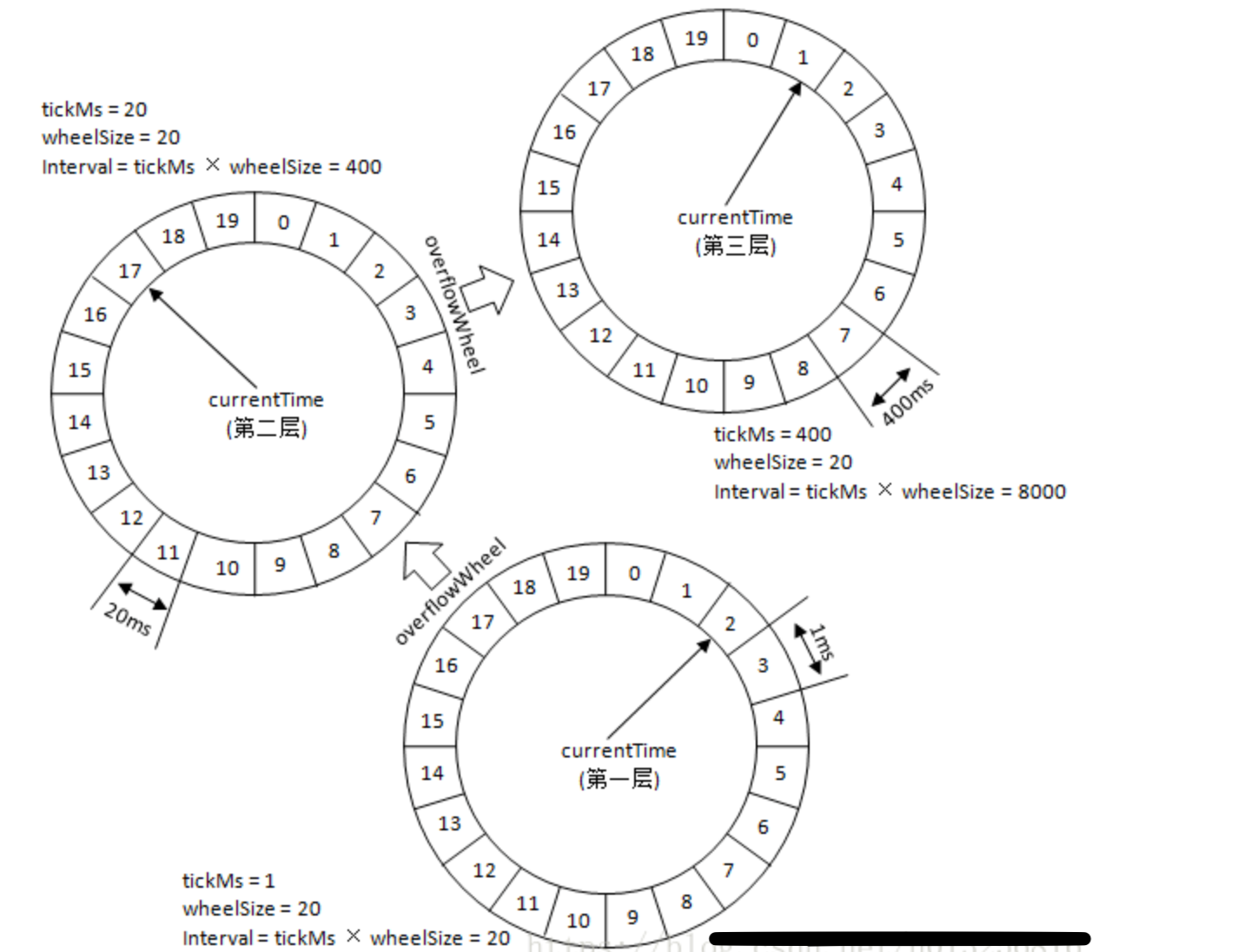
在任务插入时,如果第一层时间轮不满足条件,就尝试插入到高一层的时间轮,以此类推.
第一层的时间轮tickMs=1ms, wheelSize=20, interval=20ms 。
第二层的时间轮的tickMs为第一层时间轮的interval,即为20ms 。
第一层和第二层时间轮的wheelSize是固定的,都是20,那么第二层的时间轮的总体时间跨度interval为400ms。正好是第一层时间轮的20倍。 以此类推,这个400ms也是第三层的tickMs的大小,第三层的时间轮的总体时间跨度为8000ms .
随着时间推进,也会有一个时间轮降级的操作,原本延时较长的任务会从高一层时间轮重新提交到时间轮中,然后会被放在合适的低层次的时间轮当中等待处理; 。
例如:350ms的定时任务,显然第一层时间轮不能满足条件,所以就升级到第二层时间轮中,最终被插入到第二层时间轮中时间格17所对应的TimeWheelTaskList中。如果此时又有一个定时为450ms的任务,那么显然第二层时间轮也无法满足条件,所以又升级到第三层时间轮中,最终被插入到第三层时间轮中时间格1的TimeWheelTaskList中.
在 [400ms,800ms) 区间的多个任务(比如446ms、455ms以及473ms的定时任务)都会被放入到第三层时间轮的时间格1中,时间格1对应的TimerTaskList的超时时间为400ms 。
随着时间的流逝,当次TimeWheelTaskList到期之时,原本定时为450ms的任务还剩下50ms的时间,还不能执行这个任务的到期操作.
这里就有一个时间轮降级的操作,会将这个剩余时间为50ms的定时任务重新提交到层级时间轮中,此时第一层时间轮的总体时间跨度不够,而第二层足够,所以该任务被放到第二层时间轮到期时间为[40ms,60ms)的时间格中.
再经历了40ms之后,此时这个任务又被“察觉”到,不过还剩余10ms,还是不能立即执行到期操作。所以还要再有一次时间轮的降级,此任务被添加到第一层时间轮到期时间为[10ms,11ms)的时间格中,之后再经历10ms后,此任务真正到期,最终执行相应的到期操作.
接下来小编会出【算法数据结构专题】「延时队列算法」史上手把手教你针对层级时间轮(TimingWheel)实现延时队列的开发实战落地(下),进行实战编码进行开发对应的层次化的时间轮算法落地.
最后此篇关于【算法数据结构专题】「延时队列算法」史上手把手教你针对层级时间轮(TimingWheel)实现延时队列的开发实战落地(上)的文章就讲到这里了,如果你想了解更多关于【算法数据结构专题】「延时队列算法」史上手把手教你针对层级时间轮(TimingWheel)实现延时队列的开发实战落地(上)的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
29
4
 0
0
滑动窗口限流 滑动窗口限流是一种常用的限流算法,通过维护一个固定大小的窗口,在单位时间内允许通过的请求次数不超过设定的阈值。具体来说,滑动窗口限流算法通常包括以下几个步骤: 初始化:设置窗口
表达式求值:一个只有+,-,*,/的表达式,没有括号 一种神奇的做法:使用数组存储数字和运算符,先把优先级别高的乘法和除法计算出来,再计算加法和减法 int GetVal(string s){
【算法】前缀和 题目 先来看一道题目:(前缀和模板题) 已知一个数组A[],现在想要求出其中一些数字的和。 输入格式: 先是整数N,M,表示一共有N个数字,有M组询问 接下来有N个数,表示A[1]..
1.前序遍历 根-左-右的顺序遍历,可以使用递归 void preOrder(Node *u){ if(u==NULL)return; printf("%d ",u->val);
先看题目 物品不能分隔,必须全部取走或者留下,因此称为01背包 (只有不取和取两种状态) 看第一个样例 我们需要把4个物品装入一个容量为10的背包 我们可以简化问题,从小到大入手分析 weightva
我最近在一次采访中遇到了这个问题: 给出以下矩阵: [[ R R R R R R], [ R B B B R R], [ B R R R B B], [ R B R R R R]] 找出是否有任
我正在尝试通过 C++ 算法从我的 outlook 帐户发送一封电子邮件,该帐户已经打开并记录,但真的不知道从哪里开始(对于 outlook-c++ 集成),谷歌也没有帮我这么多。任何提示将不胜感激。
我发现自己像这样编写了一个手工制作的 while 循环: std::list foo; // In my case, map, but list is simpler auto currentPoin
我有用于检测正方形的 opencv 代码。现在我想在检测正方形后,代码运行另一个命令。 代码如下: #include "cv.h" #include "cxcore.h" #include "high
我正在尝试模拟一个 matlab 函数“imfill”来填充二进制图像(1 和 0 的二维矩阵)。 我想在矩阵中指定一个起点,并像 imfill 的 4 连接版本那样进行洪水填充。 这是否已经存在于
我正在阅读 Robert Sedgewick 的《C++ 算法》。 Basic recurrences section it was mentioned as 这种循环出现在循环输入以消除一个项目的递
我正在思考如何在我的日历中生成代表任务的数据结构(仅供我个人使用)。我有来自 DBMS 的按日期排序的任务记录,如下所示: 买牛奶(18.1.2013) 任务日期 (2013-01-15) 任务标签(
输入一个未排序的整数数组A[1..n]只有 O(d) :(d int) 计算每个元素在单次迭代中出现在列表中的次数。 map 是balanced Binary Search Tree基于确保 O(nl
我遇到了一个问题,但我仍然不知道如何解决。我想出了如何用蛮力的方式来做到这一点,但是当有成千上万的元素时它就不起作用了。 Problem: Say you are given the followin
我有一个列表列表。 L1= [[...][...][.......].......]如果我在展平列表后获取所有元素并从中提取唯一值,那么我会得到一个列表 L2。我有另一个列表 L3,它是 L2 的某个
我们得到二维矩阵数组(假设长度为 i 和宽度为 j)和整数 k我们必须找到包含这个或更大总和的最小矩形的大小F.e k=7 4 1 1 1 1 1 4 4 Anwser是2,因为4+4=8 >= 7,
我实行 3 类倒制,每周换类。顺序为早类 (m)、晚类 (n) 和下午类 (a)。我固定的订单,即它永远不会改变,即使那个星期不工作也是如此。 我创建了一个函数来获取 ISO 周数。当我给它一个日期时
假设我们有一个输入,它是一个元素列表: {a, b, c, d, e, f} 还有不同的集合,可能包含这些元素的任意组合,也可能包含不在输入列表中的其他元素: A:{e,f} B:{d,f,a} C:
我有一个子集算法,可以找到给定集合的所有子集。原始集合的问题在于它是一个不断增长的集合,如果向其中添加元素,我需要再次重新计算它的子集。 有没有一种方法可以优化子集算法,该算法可以从最后一个计算点重新
我有一个包含 100 万个符号及其预期频率的表格。 我想通过为每个符号分配一个唯一(且前缀唯一)的可变长度位串来压缩这些符号的序列,然后将它们连接在一起以表示序列。 我想分配这些位串,以使编码序列的预

我是一名优秀的程序员,十分优秀!