
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 31
31
 4
4


猫眼有一个电影榜单top100,我们将他的榜单电影数据(电影名、主演、上映时间、豆瓣评分)抓下来保存到本地的excle中 。
本案例使用css方式提取页面数据,所以会用到以下库 。
import
time
import
requests
import
parsel
#
解析库,解析css
import
csv
#
爬取的数据写入csv
创建csv文件标头信息,也就是表格第一排内容 。
f = open(
'
book.csv
'
,mode=
'
a
'
,encoding=
'
utf-8
'
,newline=
''
)
#
表头
csv_writer = csv.DictWriter(f,fieldnames=[
'
电影名字
'
,
'
主演
'
,
'
上映时间
'
,
'
评分
'
])
csv_writer.writeheader()

。
。
分析地址,每一页地址的区别在最后一个“=”号后面的数字,第一页是“10“,第二页是”20“,以此类推到”90“,所以写个循环翻页 。
https://www.maoyan.com/board/4?timeStamp=1680685769327&channelId=40011&index=8&signKey=6fa9e474efd1ed595c394e9bc497cdaf&sVersion=1&webdriver=false&offset=10 。
https://www.maoyan.com/board/4?timeStamp=1680685769327&channelId=40011&index=8&signKey=6fa9e474efd1ed595c394e9bc497cdaf&sVersion=1&webdriver=false&offset=20 。
https://www.maoyan.com/board/4?timeStamp=1680685769327&channelId=40011&index=8&signKey=6fa9e474efd1ed595c394e9bc497cdaf&sVersion=1&webdriver=false&offset=90 。
for
page
in
range(0,10
):
time.sleep(
2
)
page
= page *10
url
=
'
https://www.maoyan.com/board/4?timeStamp=1680685769327&channelId=40011&index=8&signKey=6fa9e474efd1ed595c394e9bc497cdaf&sVersion=1&webdriver=false&offset={}
'
.format(page)
print
(url)
分析页面,找到需要的数据 。
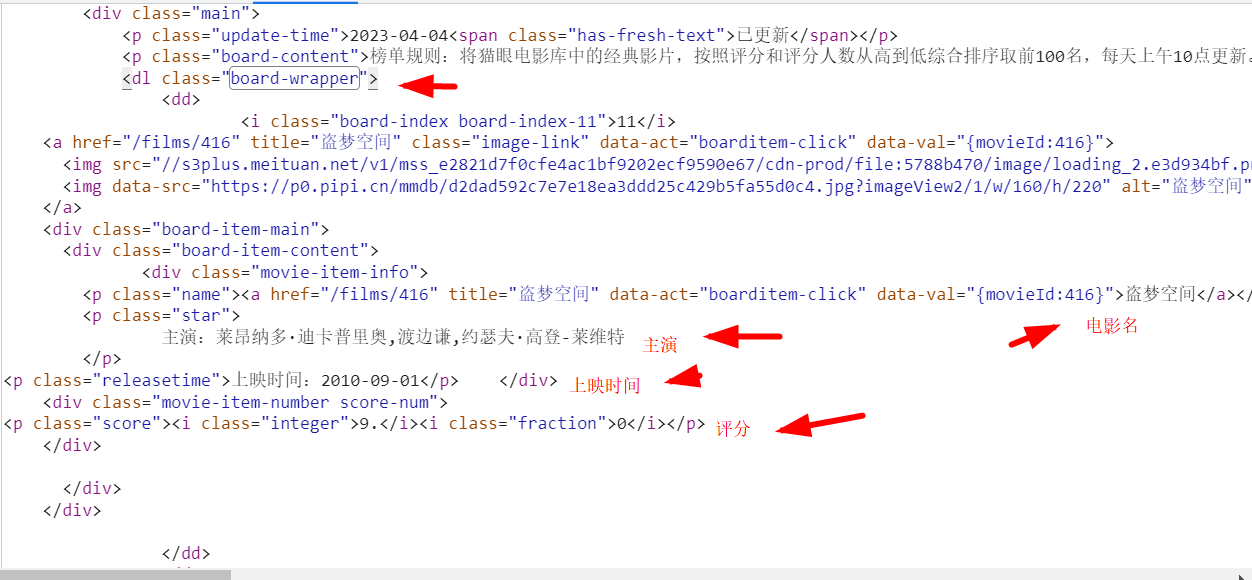
。
提取数据脚本如下 。
response = requests.get(url, headers=
headers)
selector
=
parsel.Selector(response.text)
li_s
= selector.css(
'
.board-wrapper dd
'
)
for
li
in
li_s:
name
= li.css(
'
.name a::text
'
).get()
#
电影名称
star = li.css(
'
.star::text
'
).get()
#
主演
star_string =
star.strip()
#
strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
releasetime = li.css(
'
.releasetime::text
'
).get()
#
上映时间
data_time =
releasetime.strip()
follow
= li.css(
'
.score i::text
'
).getall()
score
=
''
.join(follow)
#
join函数将列表内的值连串显示,参考“https://blog.csdn.net/weixin_50853979/article/details/125119368”
最后将获取到的数据字典化后存到csv文件中 。
dit =
{
'
电影名字
'
: name,
'
主演
'
: star_string,
'
上映时间
'
: data_time,
'
评分
'
: score,
}
csv_writer.writerow(dit)
执行后csv文件的内容 。

。
全部代码 。
import
time
import
requests
import
parsel
#
解析库,解析css
import
csv
#
爬取的数据写入csv
f
= open(
'
book.csv
'
,mode=
'
a
'
,encoding=
'
utf-8
'
,newline=
''
)
#
表头
csv_writer = csv.DictWriter(f,fieldnames=[
'
电影名字
'
,
'
主演
'
,
'
上映时间
'
,
'
评分
'
])
csv_writer.writeheader()
for
page
in
range(0,10
):
time.sleep(
2
)
page
= page *10
url
=
'
https://www.maoyan.com/board/4?timeStamp=1680685769327&channelId=40011&index=8&signKey=6fa9e474efd1ed595c394e9bc497cdaf&sVersion=1&webdriver=false&offset={}
'
.format(page)
print
(url)
headers
=
{
'
User-Agent
'
:
'
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36
'
,
'
Cookie
'
:
'
__mta=20345351.1670903159717.1670903413872.1670903436333.5; uuid_n_v=v1; uuid=A8065B807A9811ED82C293D7E110319C9B09821067E1411AB6F4EC82889E1869; _csrf=916b8446658bd722f56f2c092eaae35ea3cd3689ef950542e202b39ddfe7c91e; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1670903160; _lxsdk_cuid=1850996db5dc8-07670e36da28-26021151-1fa400-1850996db5d67; _lxsdk=A8065B807A9811ED82C293D7E110319C9B09821067E1411AB6F4EC82889E1869; __mta=213622443.1670903327420.1670903417327.1670903424017.4; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1670903436; _lxsdk_s=1850996db5e-8b2-284-88a%7C%7C18
'
,
'
Host
'
:
'
www.maoyan.com
'
,
'
Referer
'
:
'
https://www.maoyan.com/films/1200486
'
}
response
= requests.get(url, headers=
headers)
selector
=
parsel.Selector(response.text)
li_s
= selector.css(
'
.board-wrapper dd
'
)
for
li
in
li_s:
name
= li.css(
'
.name a::text
'
).get()
#
电影名称
star = li.css(
'
.star::text
'
).get()
#
主演
star_string =
star.strip()
#
strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
releasetime = li.css(
'
.releasetime::text
'
).get()
#
上映时间
data_time =
releasetime.strip()
follow
= li.css(
'
.score i::text
'
).getall()
score
=
''
.join(follow)
#
join函数将列表内的值连串显示,参考“https://blog.csdn.net/weixin_50853979/article/details/125119368”
dit =
{
'
电影名字
'
: name,
'
主演
'
: star_string,
'
上映时间
'
: data_time,
'
评分
'
: score,
}
csv_writer.writerow(dit)
。
最后此篇关于python-爬虫-css提取-写入csv-爬取猫眼电影榜单的文章就讲到这里了,如果你想了解更多关于python-爬虫-css提取-写入csv-爬取猫眼电影榜单的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
31
4
 0
0
我有这个代码 var myChart = new FusionCharts("../themes/clean/charts/hbullet.swf", "myChartId", "400", "75
既然写入是立即进行的(复制到内核缓冲区并返回),那么使用 io_submit 进行写入有什么好处? 事实上,它 (aio/io_submit) 看起来更糟,因为您必须在堆上分配写入缓冲区并且不能使用基
我正在使用 mootool 的 Request.JSON 从 Twitter 检索推文。收到它后,我将写入目标 div 的 .innerHTML 属性。当我在本地将其作为文件进行测试时,即 file:
最终,我想将 Vertica DB 中的数据抓取到 Spark 中,训练机器学习模型,进行预测,并将这些预测存储到另一个 Vertica DB 中。 当前的问题是确定流程最后部分的瓶颈:将 Spark
我使用 WEKA 库编写了一个 Java 程序, 训练分类算法 使用经过训练的算法对未标记的数据集运行预测 将结果写入 .csv 文件 问题在于它当前写出离散分类结果(即算法猜测一行属于哪个类别)。我
背景 - 我正在考虑使用 clickonce 通过 clickonce(通过网站)部署 WinForms 应用程序。相对简单的应用程序的要素是: - 它是一个可执行文件和一个数据库文件(sqlite)
是否有更好的解决方案来快速初始化 C 数组(在堆上创建)?就像我们使用大括号一样 double** matrix_multiply(const double **l_matrix, const dou
我正在读取 JSON 文件,取出值并进行一些更改。 基本上我向数组添加了一些值。之后我想将其写回到文件中。当我将 JSONArray 写回文件时,会被写入字符串而不是 JSONArray 对象。怎样才
我为两个应用程序使用嵌入式数据库,其中一个是服务器,另一个是客户端。客户端应用程序。可以向服务器端发送获取数据请求以检索数据并显示在表格(或其他)中。问题是这样的:如何将获取的数据保存(写入)到页面文
是否有更好的解决方案来快速初始化 C 数组(在堆上创建)?就像我们使用大括号一样 double** matrix_multiply(const double **l_matrix, const dou
从问题得出问题:找到所有 result = new ArrayList(); for (int i = 2; i >(i%8) & 0x1) == 0) { result.add(i
由于某种原因,它没有写入 CSV。谁能明白为什么它不写吗? def main(): list_of_emails = read_email_csv() #read input file, cr
关闭。 这个问题是 not reproducible or was caused by typos 。它目前不接受答案。 这个问题是由于错别字或无法再重现的问题引起的。虽然类似的问题可能在这里出现,
我目前正在开发一个保存和加载程序,但我无法获得正确的结果。 编写程序: #include #include #define FILENAME "Save" #define COUNT 6 type
import java.io.*; public class Main2 { public static void main(String[] args) throws Exception {
我需要使用预定义位置字符串“Office”从所有日历中检索所有 iOS 事件,然后将结果写入 NSLog 和 UITextView。 到目前为止,这是我的代码: #import "ViewCo
我正在尝试将 BOOL 值写入 PFInstallation 中的列,但会不停地崩溃: - (IBAction)pushSwitch:(id)sender { NSUserDefaults *push
我以前在学校学过一些简单的数据库编程,但现在我正在尝试学习最佳实践,因为我正在编写更复杂的应用程序。写入 MySQL 数据库并不难,但我想知道让分布式应用程序写入 Amazon EC2 上的远程数据库
是否可以写回到ResourceBundle?目前我正在使用 ResourceBundle 来存储信息,在运行时使用以下内容读取信息 while(ResourceBundle.getBundle("bu
关闭。这个问题是not reproducible or was caused by typos .它目前不接受答案。 这个问题是由于错别字或无法再重现的问题引起的。虽然类似的问题可能是on-topi

我是一名优秀的程序员,十分优秀!