
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4


这节课开始进入了网络层的学习,讲述了网络层提供的功能,还有路由器内部是什么样子的,以及virtual circuit网络和datagram网络的一点比较.
网络层有什么作用呢?用一句话来说,就是需要负责将传输层的报文段从发送端传输到接收端。再详细一点点就是:
网络层的功能有两个: routing 和 forwarding .
用旅行来比喻:如果数据报是需要出门旅行的人,那么 routing 就是提前决定好一条旅游的路线(从哪到哪然后到哪再到哪……), forwarding 则是在路线中的某一个站点进出的过程.
routing 使用路由算法找到一条从src到dest的最短路径.
routing 属于网络层的 控制平面 ,需要多个路由器进行协调,以后慢慢阐述.
“ Forwarding 是网络层 数据平面 唯一需要实现的功能。“ 。
Forwarding 通过switching,来将数据包从节点入口移动到指定的节点出口,“在某个时刻一个包进来了,决定在哪个端口出去”。在这个过程还需要做 error handling , queuing 和 scheduling .
其中router进行switching的过程和二层交换机是十分相似的,router有一个 forwarding table ,起到了类似于交换机表的作用:
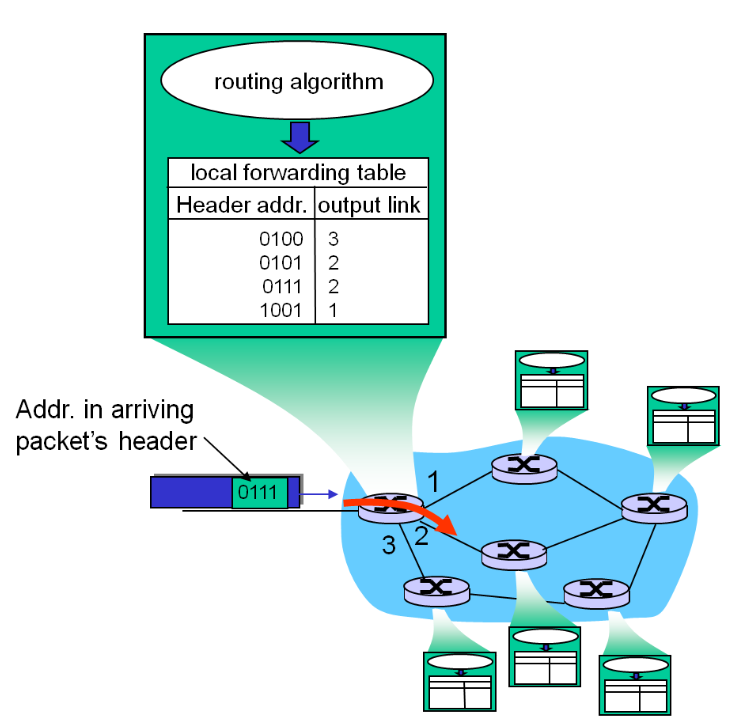
但forwarding table并不是自学习得来的,而是需要各个路由器之间的路由算法进行通信后才可以配置完成。也就是说,控制平面的routing决定了数据平面需要使用的forwarding table.
forwarding 时网络层还会提供一点其它的功能,如queuing 和 scheduling,因为拥塞实时存在,所以加上这两个功能.
网络层的服务模型( service model )是指,如果想要传输一个数据报,那么传输所用的"channel"应该为什么样子的呢?
要用的"channel"需要考虑的因素非常多,即我们的"channel"应该为传输提供了什么样的服务……例如有以下服务:

对需求做出抽象后产生的服务功能越强,那么实现起来的代价就越大——所以作为应用最广的协议层,便宜很重要! 。
先不提实现成本,来看看IP和ATM协议的对比——它们提供了什么服务:
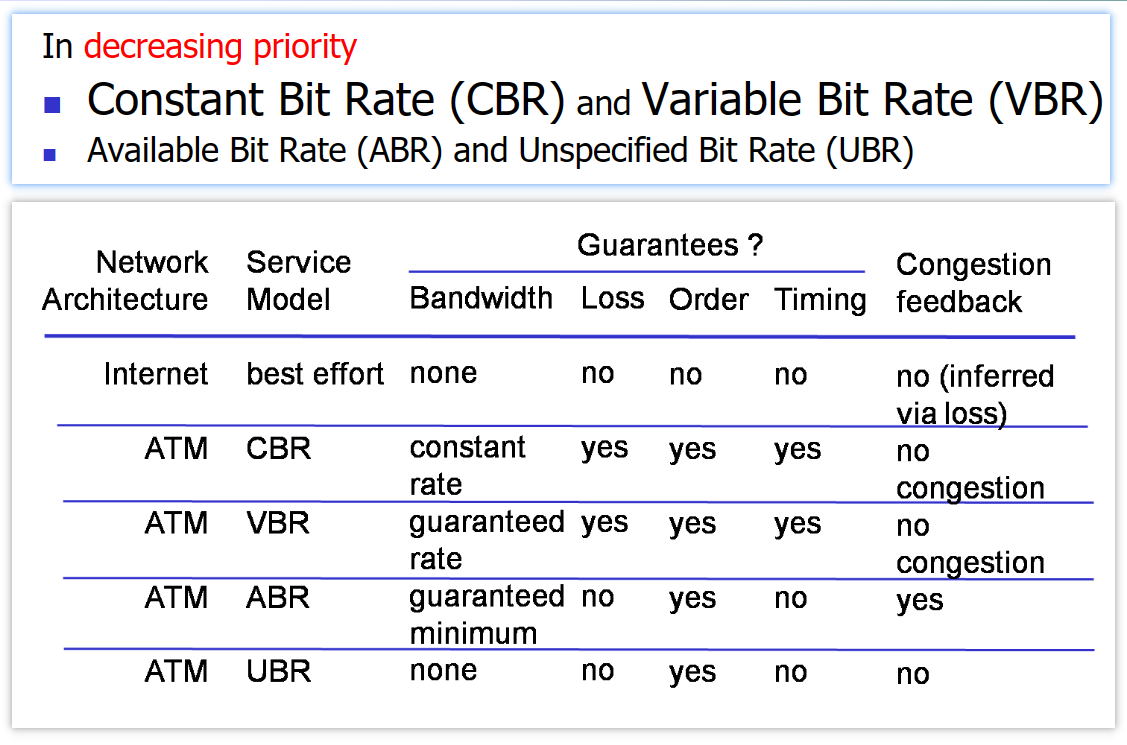
可以看到,IP协议的 best effort 服务真是够鬼舞的……好像什么都干不了,看看ATM协议能做的还真多,还分了四种优先级供人选择.
但ATM协议还是败了,就是败在了实现成本这方面。虽然IP看上去不咋地,但在现今与适当的带宽供给相结合已经能够用于大量的应用,已经“足够好”.
Overview了网络层提供的功能和服务,我们来看路由器的工作原理,看它是如何进行 forwarding 的.
其中 N 为路由器的外端口数量;R 为 端口的传输速率 (即“line rate”); 。
在 RFC 8238 第五部分的定义(5.1)有:
The line rate or physical-layer frame rate is the maximum capacity to send frames of a specific size at the transmit clock frequency of the DUT. 。
The term "nominal value of line rate" defines the maximum speed capability for the given port -- for example (expressed as Gigabit Ethernet), 1 GE, 10 GE, 40 GE, 100 GE. 。
路由器是有种类区分的,在不同应用场景下的路由器的配置也有所不同:
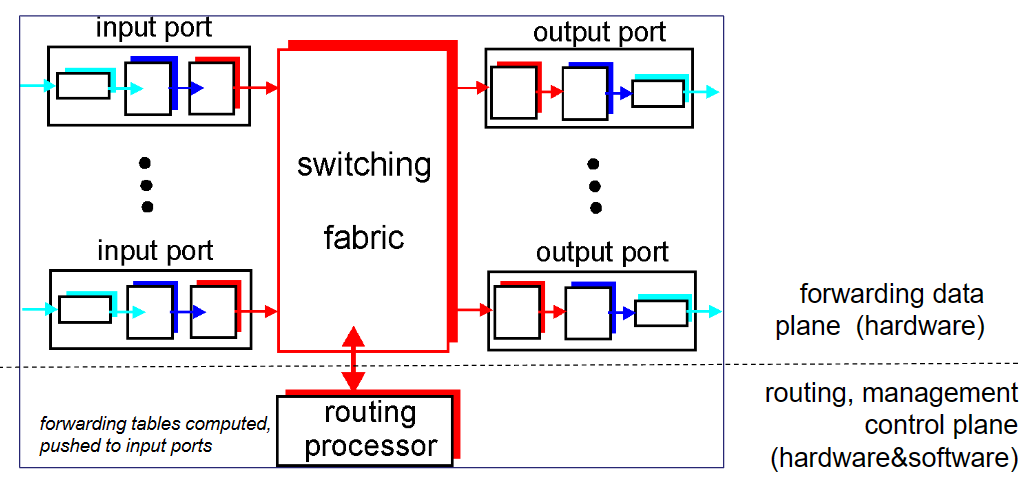
routing ,数据平面负责 forwarding ; 问:为什么输入输出端口以及交换结构大部分用硬件实现?
主要challenge:接收数据包的速率的时间要求(例如100B大小的包要达到40Gbps的速率接收,则只有20ns时间处理)远远快于软件实现;所以不用普通的x86芯片,用的更快的ASICs实现(专用的网络处理器).
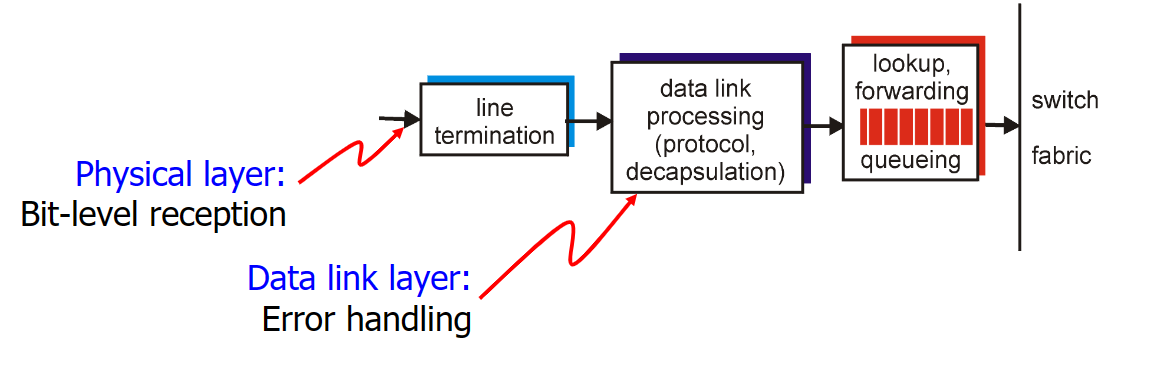
输入端口主要有以下四个任务:

进行了 线路端接 和 链路层处理 后,我们来到了执行 查找输出端口 的步骤。转发表通过路由处理器计算和更新(或者由SDN转发过来的内容更新,SDN在控制平面会讲),转发表从路由处理器经过独立总线 复制 到 line card中,使用副本可以使得查找决策可以在各个输入端口上分别执行,无须调用集中式路由处理器.
但问题来了,IP有四十亿多的地址,一个端口对应一个地址的话,转发表怎么够装?
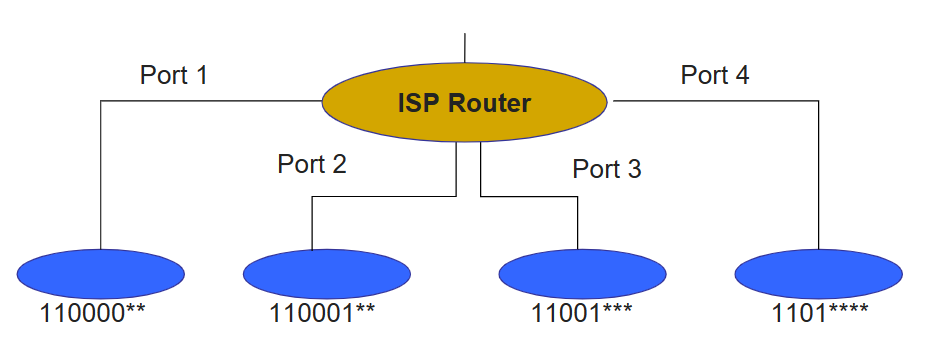
如何处理这样的规模问题?采用 地址聚合 。(可扩展性好)我们用 最长前缀匹配规则 LPM rules 来对地址们进行聚合.
LPM的定义如下:

来看一个例子。假设我们的交换机有四个端口,给出各个端口接收到的packet的地址范围(为了方便,用一个字节);可以看到这些地址的LPM分别是蓝色标记的部分:

然后我们就可以根据LPM来把地址和对应的端口写入转发表中,此时一个端口对应的是一个“聚合起来”的地址群,而不只是单单的一个.
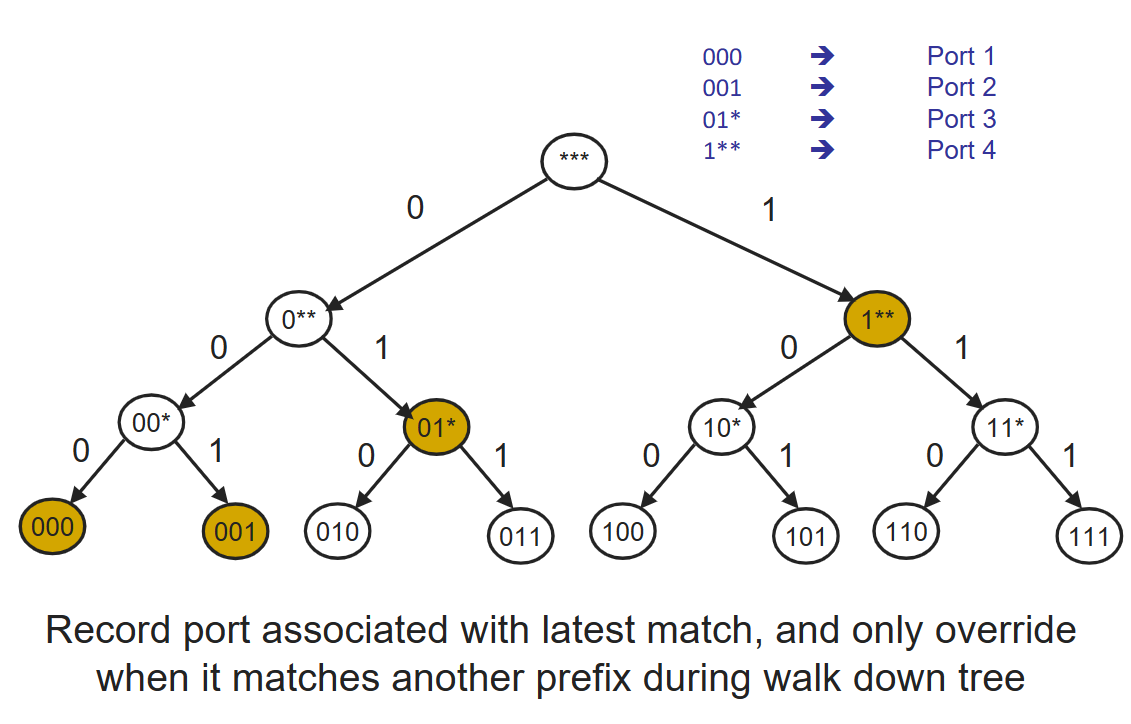
由于需要达到纳秒级别执行,即使是用硬件执行查找,简单线性搜索匹配还是太慢。所以我们用一个 Trie tree 来查找匹配。(或者看这篇: 路由查找算法研究综述 )这是针对前缀查找问题的一个好方法,有点类似哈夫曼树,可以基于前缀长度而不是前缀内容做线性遍历.
除了查找算法,在硬件上也需要进行对访存消耗的优化,如TCAM(三态内容可寻址存储器,电平控制).
交换结构 可以由三种不同的交换技术实现,即内存 memory 、总线 bus 和纵横式 crossbar .
交换速率 switching rate 是指packet从输入端口传输到输出端口的速率,通常以输入/输出的 line rate 的倍数来衡量, 。
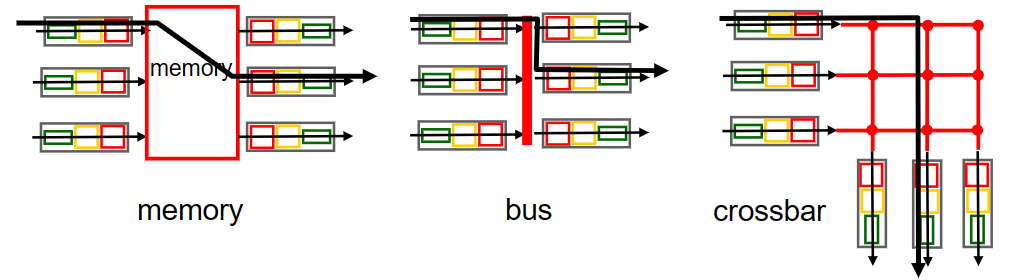
memory 。
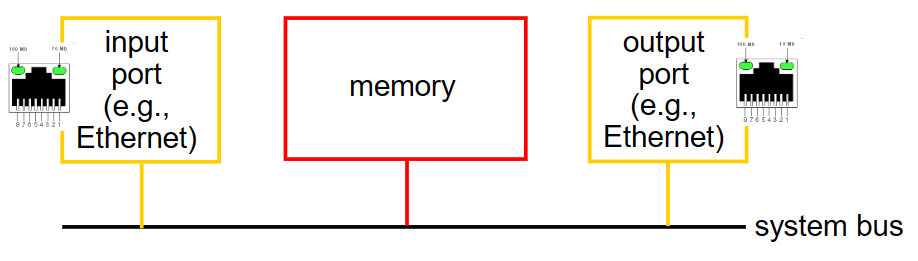
早期的路由器是传统的计算机,对packet进出的使用IO机制进行处理(即中断--系统调用,packet被copy到内存中),在这种情况下如果内存带宽每秒能读出/写入B个packet,那么总的吞吐量一定小于B/2。另外还不能同时forward两个packet,即使端口不同——因为经过系统共享总线一次只能进行一次内存读/写.
现代的很多路由器同样采用memory方式,但与早期不同的是,查找packet并将其switch进内存中的行为是由输入端口的line card进行处理的。(这种方式很便宜,相对其它两种) 。
bus 。
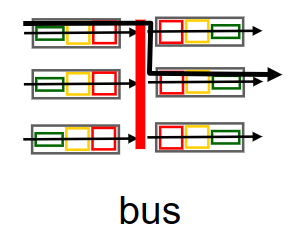
bus交换方式是通过路由器内部的背板总线来实现的,不需要路由处理器的操作。当packet查找出对应的输出端口时,packet头部被打上一个label(相当于多加一层header),这个label记录了对应的输出端口;然后它被放到总线上传输,这时所有的输出端口都能收到该packet,但只有label上记录的输出端口才能保存该packet.
因为一次只有一个packet可以通过总线(同一时间的其余packet需要原地等待),所以bus方式的 switching rate 与背板总线速率有关.
crossbar 。
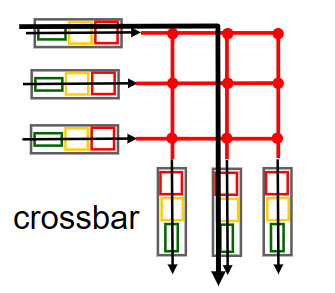
为了克服bus方式共享总线带来的速率限制,我们可以用2N条总线来构建一个复杂的互联网络(对应N个输入端口和N个输出端口);然后总线的交叉点可以通过交换结构控制器来在任何时候进行开启/关闭,由此可以实现多个packet的并行转发。这种方式面对多个输出端口不同的packet时,是 non-blocking 的.
Cisco CRS利用三级non-blocking交换策略实现对多个输出端口相同packet进行并行switching.
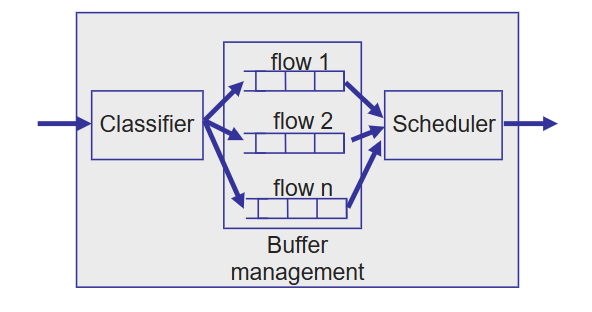
输出端口需要做的就是选择并取出正在queueing的packet,然后执行链路层功能,再进行物理层线路端接传输.
输出端口有三个组成部分:
Classifier :流分类器,负责将packet分到各个流中; Buffer management :决定哪一个packet以及在什么时候会被丢弃; Scheduler :packet调度器,在queueing的packets中决定哪一个packet以及在什么时候会被传输走; 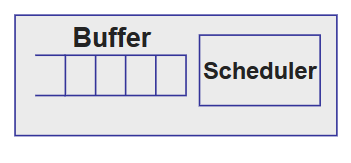
在最简单的 FIFO 机制路由器里面,没有classification机制,buffer的management仅仅是把buffer尾部溢出的packet丢弃,scheduler也只是简单地使用FIFO来对packet调度——谁先来谁就能先出去。FIFO机制弊端太多,我们来看看这三个组成部分可以在此之上有什么提升:
Packet classification 。
Classifier 可以根据packet的header来进行流分类(有意义的调度必须要先分类):

Scheduler 。
对于调度器来说,一个好的调度算法非常重要(纳秒级别的处理要尽可能快)。常见的调度算法有FIFO、优先级调度( Priority scheduler )、加权公平调度等.

我们来说一下优先级调度和加权公平调度.
对于这两个调度算法来说,buffer里面的每个流都有一个buffer队列。优先级调度的策略很容易理解:就是优先级越高的队列总是比优先级低的队列先进行packet传输;而加权公平调度则是有几种情况:最简单的 round-robin 方式就是简单的对每一个队列都进行周期性的packet传输,你一下我一下;而 weighted fair queue (WFQ)方式是对队列进行加权后,按照权值来进行周期性循环.
PS:在早些时期,运营商可以自己调整ISP路由器中的队列优先级(谁给钱多,谁的packet就传输得越多越快),所以需要法案来规定这些东西…… 。
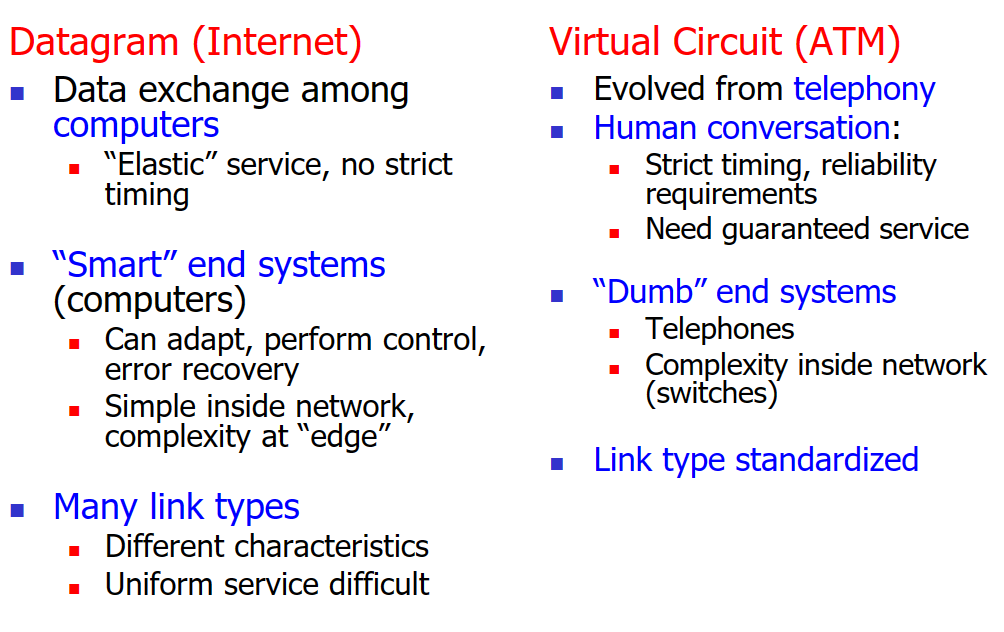
在第一节讲过我们的network的连接可以分为 电路交换模式 和 分组交换模式 。在这里我们来说一下它们在网络层中分别对应使用的具体协议实现:电路交换(virtual circuit网络)对应的是ATM协议,而分组交换(datagram网络)对应的是IP协议.

virtual circuit网络 。
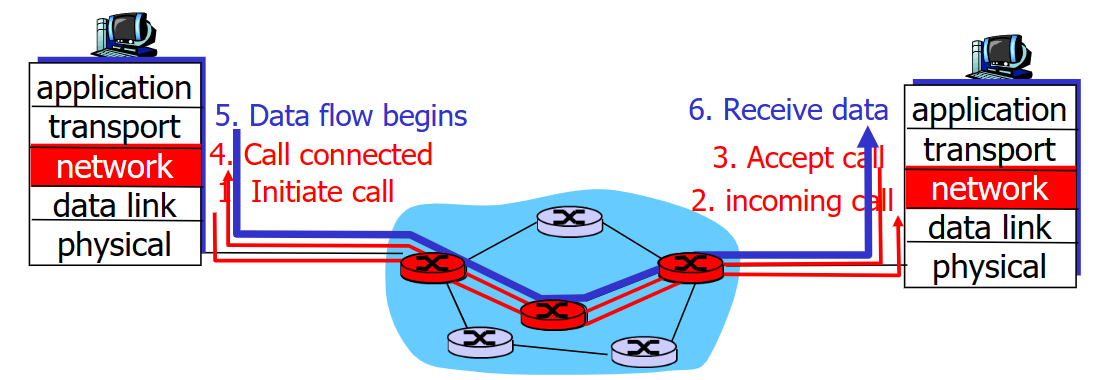
VC网络需要在传输数据前在src和dest之间先确立好一条路线,在这条路线上的路由器和交换机都是固定分配好后就不变的,这也表示这条路线是这次传输专属的,性能可以被准确估计。这条路线需要用路由器来找出(shortest path).
每一个在VC网络上传输的packet都会带着一个VC number,VC number在路线上的每一个link存在,它在转发表中的使用如下:
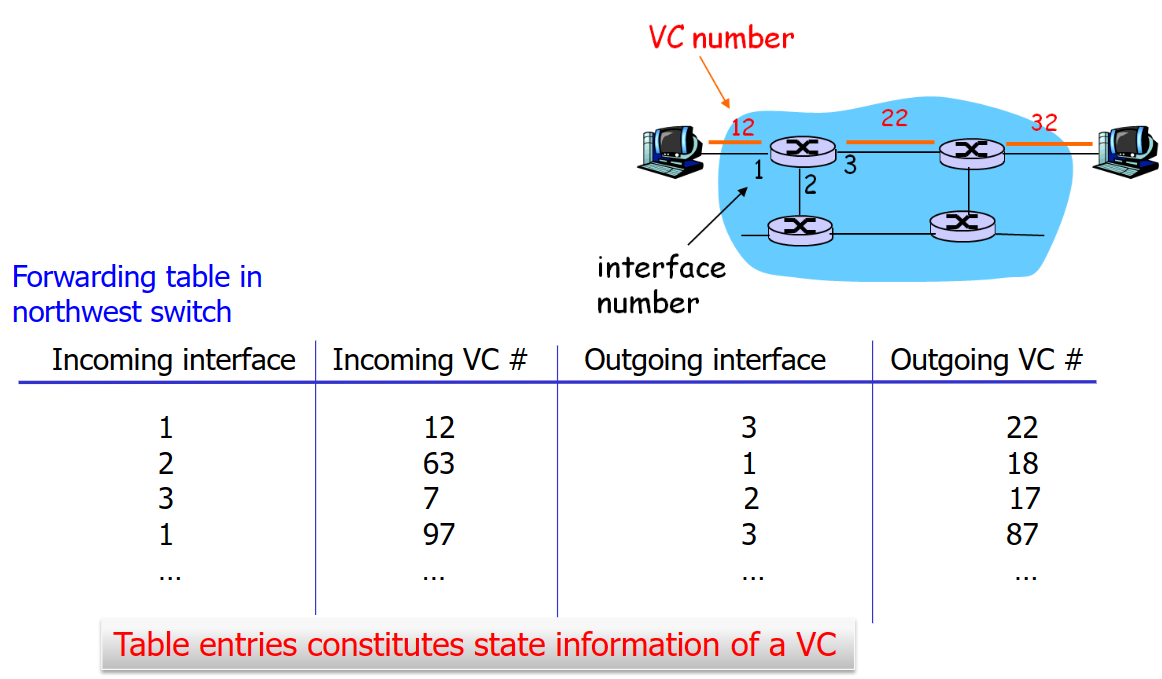
VC网络的建立和断开就像大公司招人,正式职工一般是长期聘用的,不会断开那么快。它使用信令协议( Signaling Protocols )来建立、维持以及断开VC连接,具体协议有 ATM, frame-relay, X.25 ,但是在今天的Internet已经基本看不见了(因为实现昂贵,昂贵的原因:需要保存途径连接的状态) 。
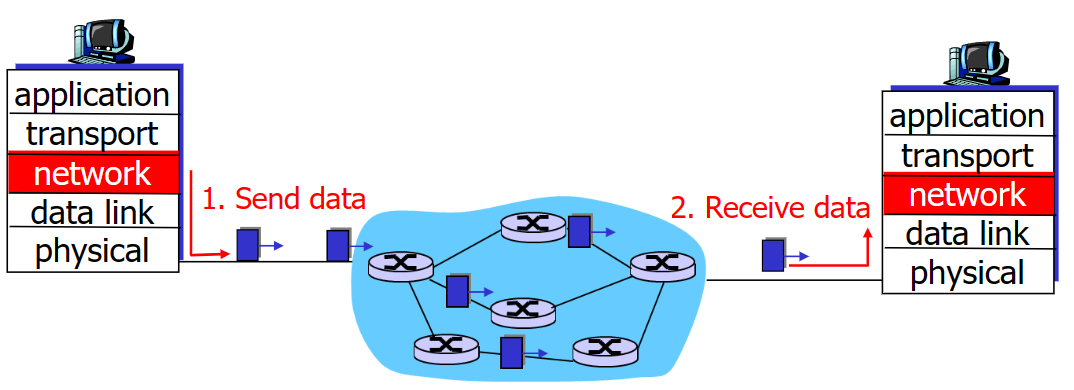
datagram网络 。
datagram网络的特点是无确定连接、无转发状态记录,同样的src-dest的packet,在网络中走的可能是不同的路线.
和VC网络的转发表不同,datagram网络的转发表记录的src地址可能是switch地址,也可能是一整个subnet的地址群:

Virtual Circuits vs Datagram Networks 。
两种网络的routing:VC网络(左)和datagram网络(右).
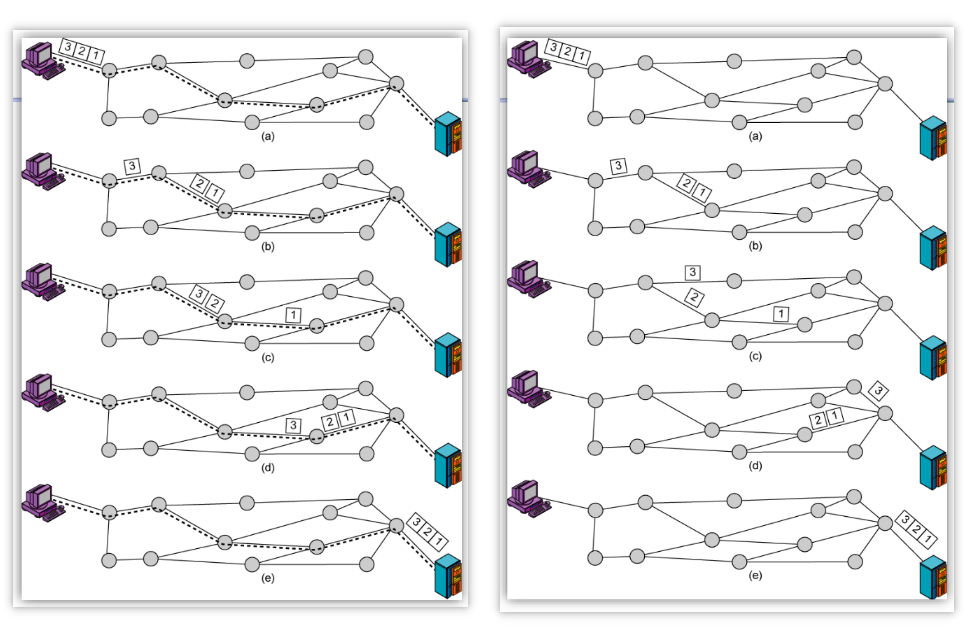
相关资料: Virtual Circuits vs Datagram Networks ;有一个小的总结:
最后此篇关于计网学习笔记六NetworkLayerOverview的文章就讲到这里了,如果你想了解更多关于计网学习笔记六NetworkLayerOverview的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
OkHttp的作用 OkHttp is an HTTP client。 如果是HTTP的方式想得到数据,就需要我们在页面上输入网址,如果网址没有问题,就有可能返回对应的String字符串,如果这个地址
Record 一个重要的字符串算法,这是第三次复习。 通过总结我认为之所以某个算法总是忘记,是因为大脑始终没有认可这种算法的逻辑(也就是脑回路)。 本篇主要讲解从KMP的应用场景,
SQL 注入基础 【若本文有问题请指正】 有回显 回显正常 基本步骤 1. 判断注入类型 数字型 or 字符型 数字型【示例】:
标签: #Prompt #LLM 创建时间:2023-04-28 17:05:45 链接: 课程(含JupyterNotebook) , 中文版 讲师: An
Swift是供iOS和OS X应用编程的新编程语言,基于C和Objective-C,而却没有C的一些兼容约束。Swift采用了安全的编程模式和添加现代的功能来是的编程更加简单、灵活和有趣。界面则基于
VulnStack-红日靶机七 概述 在 VulnStack7 是由 5 台目标机器组成的三层网络环境,分别为 DMZ 区、第二层网络、第三层网络。涉及到的知识点也是有很多,redis未授权的利用
红日靶机(一)笔记 概述 域渗透靶机,可以练习对域渗透的一些知识,主要还是要熟悉 powershell 语法,powershell 往往比 cmd 的命令行更加强大,而很多渗透开源的脚本都是 po
八大绩效域详细解析 18.1 干系人绩效域 跟干系人所有相关的活动. 一、预期目标 ①与干系人建立高效的工作关系 ②干系人认同项目目标 ③支持项目的干系人提高
18.3 开发方法和生命周期绩效域 跟开发方法,项目交付节奏和生命周期相关的活动和职能. 一、预期目标: ①开发方法与项目可交付物相符合; ②将项目交付与干系人价值紧密
18.7 度量绩效域 度量绩效域涉及评估项目绩效和采取应对措施相关的活动和职能度量是评估项目绩效,并采取适当的应对措施,以保持最佳项目绩效的过程。 一、 预期目标: ①对项目状况
pygraphviz 安装,windows系统: 正确的安装姿势: Prebuilt-Binaries/PyGraphviz at master · CristiFati/Prebuilt-Binar
今天给大家介绍IDEA开发工具如何配置devtools热加载工具。 1、devtools原理介绍 spring-boot-devtools是spring为开发者提供的热加载
一 什么是正则表达式 // 正则表达式(regular expression)是一个描述字符模式的对象; // JS定义RegExp类表示正则表达式; // String和RegExp都定义了使用
目前是2022-04-25 23:48:03,此篇博文分享到互联网上估计是1-2个月后的事了,此时的OpenCV3最新版是3.4.16 这里前提是gcc,g++,cmake都需要安装好。 没安装好的,
一、概述 1、Flink 是什么 Apache Flink is a framework and distributed processing engine for stateful comput
一、window 概述 Flink 通常处理流式、无限数据集的计算引擎,窗口是一种把无限流式数据集切割成有限的数据集进行计算。window窗口在Flink中极其重要。 二、window 类型 w
一、触发器(Trigger) 1.1、案例一 利用global window + trigger 计算单词出现三次统计一次(有点像CountWindow) 某台虚拟机或者mac 终端输入:nc -
一、时间语义 在Flink 中涉及到三个重要时间概念:EventTime、IngestionTime、ProcessingTime。 1.1、EventTime EventTime 表示日志事
一、概述 以wordcount为例,为什么每次输入数据,flink都能统计每个单词的总数呢?我们都没有显示保存每个单词的状态值,但是每来一条数据,都能计算单词的总数。事实上,flink在底层维护了每
一、概述 checkpoint机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如 异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保 证应用流图状

我是一名优秀的程序员,十分优秀!