
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


本文内容翻译自《数据密集型应用系统设计》(大名鼎鼎的 DDIA).
什么是「 数据密集型应用系统 」?
其实我们平时遇到的大部分系统都是数据密集型的——应用代码访问内存、硬盘、数据库、消息队列中的数据,经过业务逻辑处理,再返回给用户.
。
。
。
。
。
。
Online analytical processing和Online analytical processing.
查询类型主要分为两大类:
| 引擎类型 。 |
请求数量 。 |
数据量 。 |
瓶颈 。 |
存储格式 。 |
用户 。 |
场景举例 。 |
产品举例 。 |
| OLTP 。 |
相对频繁,侧重在线交易 。 |
总体和单次查询都相对较小 。 |
Disk Seek 。 |
多用行存 。 |
比较普遍,一般应用用的比较多 。 |
银行交易 。 |
MySQL 。 |
| OLAP 。 |
相对较少,侧重离线分析 。 |
总体和单次查询都相对巨大 。 |
Disk Bandwidth 。 |
列存逐渐流行 。 |
多为商业用户 。 |
商业分析 。 |
ClickHouse 。 |
其中,OLTP 侧,常用的存储引擎又有两种流派:
| 流派 。 |
主要特点 。 |
基本思想 。 |
代表 。 |
| log-structured 流 。 |
只允许追加,所有修改都表现为文件的追加和文件整体增删 。 |
变随机写为顺序写 。 |
Bitcask、LevelDB、RocksDB、Cassandra、Lucene 。 |
| update-in-place 流 。 |
以页(page)为粒度对磁盘数据进行修改 。 |
面向页、查找树 。 |
B 族树,所有主流关系型数据库和一些非关系型数据库 。 |
此外,针对 OLTP, 还探索了常见的建索引的方法,以及一种特殊的数据库 —— 全内存数据库.
对于数据仓库,本章分析了它与 OLTP 的主要不同之处。数据仓库主要侧重于聚合查询,需要扫描很大量的数据,此时,索引就相对不太有用。需要考虑的是存储成本、带宽优化等,由此引出列式存储.
。
本节由一个 shell 脚本出发,到一个相当简单但可用的存储引擎 Bitcask,然后引出 LSM-tree,他们都属于日志流范畴。之后转向存储引擎另一流派 ——B 族树,之后对其做了简单对比。最后探讨了存储中离不开的结构 —— 索引.
首先来看,世界上 “最简单” 的数据库,由两个 Bash 函数构成:
| 1 。 2 。 3 。 4 。 5 。 6 。 7 。 8 。 |
#!/bin/bash 。 db_set () { 。 echo " $1 , $2 " >> database 。 } 。 。 db_get () { 。 grep "^ $1 ," database | sed -e "s/^ $1 ,//" | tail -n 1 。 } 。 |
。
这两个函数实现了一个基于字符串的 KV 存储(只支持 get/set,不支持 delete):
| 1 。 2 。 3 。 4 。 |
$ db_set 123456 '{"name":"London","attractions":["Big Ben","London Eye"]}' 。 $ db_set 42 '{"name":"San Francisco","attractions":["Golden Gate Bridge"]}' 。 $ db_get 42 。 { "name" : "San Francisco" , "attractions" :[ "Golden Gate Bridge" ]} 。 |
。
来分析下它为什么 work,也反映了日志结构存储的最基本原理:
可以看出:写很快,但是读需要全文逐行扫描,会慢很多。典型的以读换写。为了加快读,我们需要构建 索引: 一种允许基于某些字段查找的额外数据结构.
索引从原数据中构建,只为加快查找。因此索引会耗费一定额外空间,和插入时间(每次插入要更新索引),即,重新以空间和写换读取.
这便是数据库存储引擎设计和选择时最常见的 权衡(trade off) :
存储格式一般不好动,但是索引构建与否,一般交予用户选择.
。
本节主要基于最基础的 KV 索引.
依上小节的例子,所有数据顺序追加到磁盘上。为了加快查询,我们在内存中构建一个哈希索引:
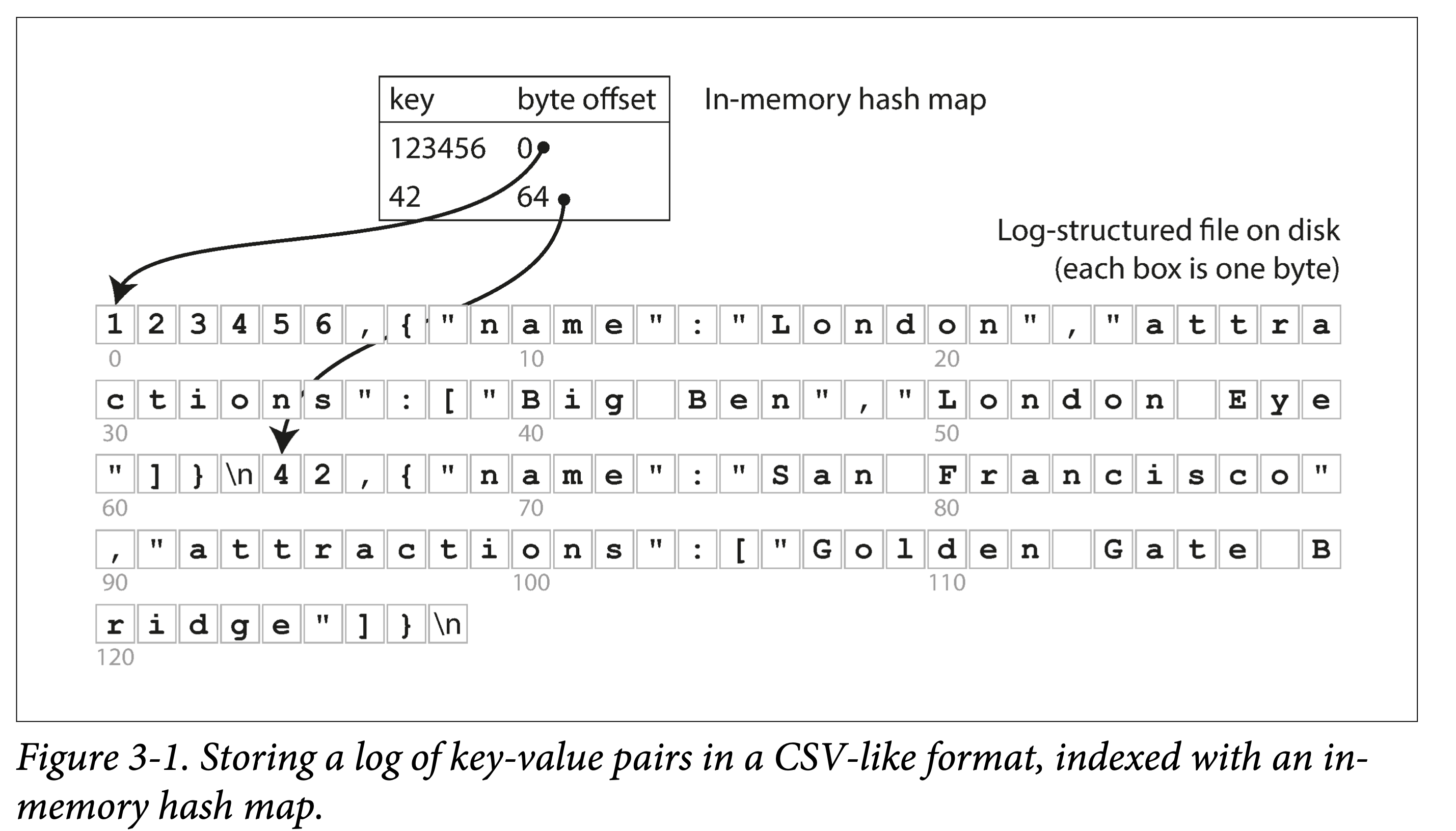
。
。
。
看来很简单,但这正是 Bitcask 的基本设计,但关键是,他 Work(在小数据量时,即所有 key 都能存到内存中时):能提供很高的读写性能:
。
。
如果你的 key 集合很小(意味着能全放内存),但是每个 key 更新很频繁,那么 Bitcask 便是你的菜。举个栗子:频繁更新的视频播放量,key 是视频 url,value 是视频播放量.
。
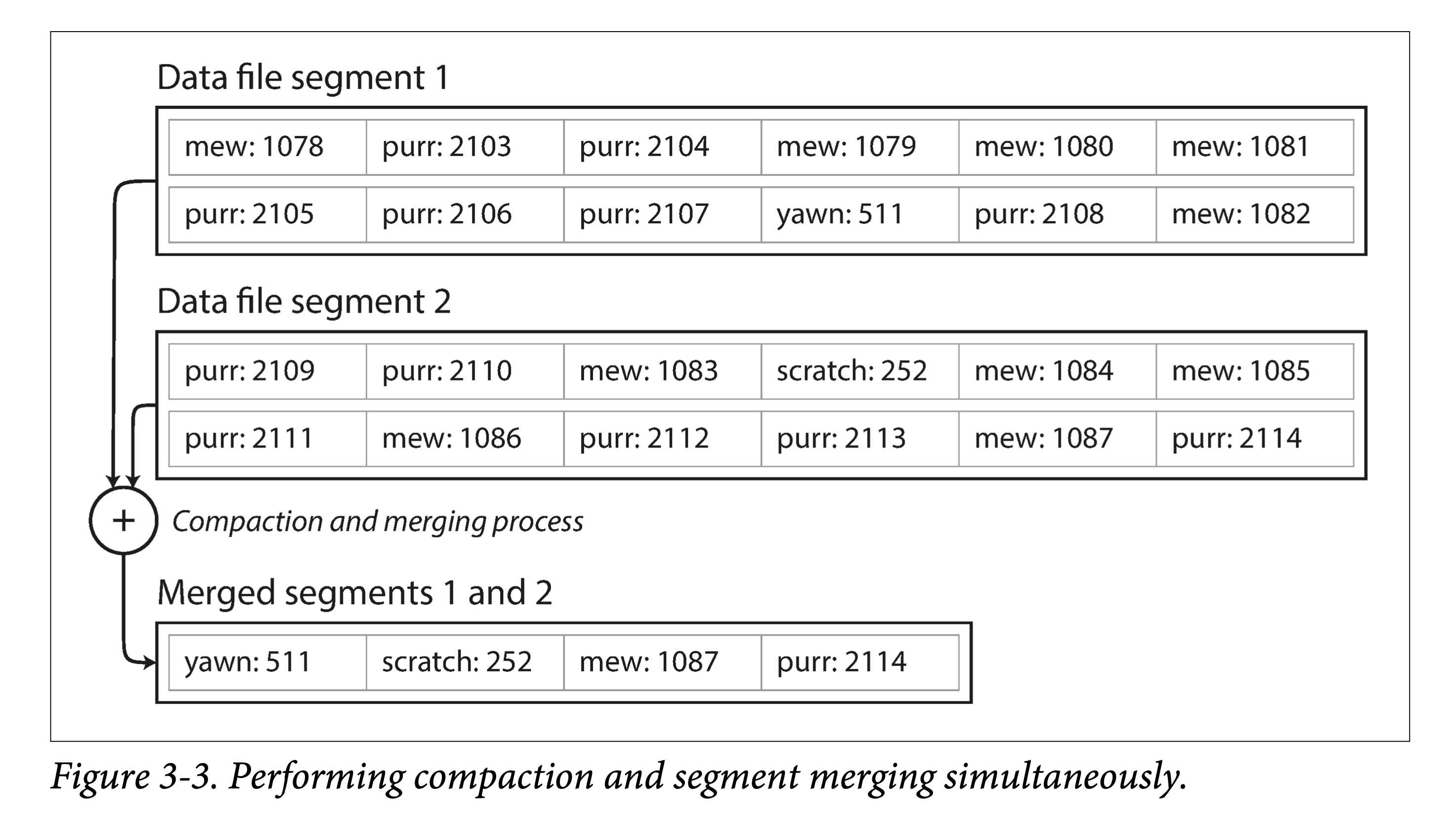
。
。
当然,如果我们想让其 工业可用 ,还有很多问题需要解决:
乍一看,基于日志的存储结构存在折不少浪费:需要以追加进行更新和删除。但日志结构有几个原地更新结构无法做的优点:
当然,基于内存的哈希索引也有其局限:
后面讲的 LSM-Tree 和 B+ 树,都能部分规避上述问题.
。
这一节层层递进,步步做引,从 SSTables 格式出发,牵出 LSM-Trees 全貌.
对于 KV 数据,前面的 BitCask 存储结构是:
其中外存上的数据是简单追加写而形成的,并没有按照某个字段有序.
假设加一个限制,让这些文件按 key 有序。我们称这种格式为:SSTable(Sorted String Table).
这种文件格式有什么优点呢?
高效的数据文件合并 。即有序文件的归并外排,顺序读,顺序写。不同文件出现相同 Key 怎么办?

。
。
。
不需要在内存中保存所有数据的索引 。仅需要记录下每个文件界限(以区间表示:[startKey, endKey],当然实际会记录的更细)即可。查找某个 Key 时,去所有包含该 Key 的区间对应的文件二分查找即可.
。

。
。
。
分块压缩,节省空间,减少 IO 。相邻 Key 共享前缀,既然每次都要批量取,那正好一组 key batch 到一块,称为 block,且只记录 block 的索引.
SSTables 格式听起来很美好,但须知数据是乱序的来的,我们如何得到有序的数据文件呢?
这可以拆解为两个小问题:
构建 SSTable 文件 。将乱序数据在外存(磁盘 or SSD)中上整理为有序文件,是比较难的。但是在内存就方便的多。于是一个大胆的想法就形成了:
维护 SSTable 文件 。为什么需要维护呢?首先要问,对于上述复合结构,我们怎么进行查询:
如果 SSTable 文件越来越多,则查找代价会越来越大。因此需要将多个 SSTable 文件合并,以减少文件数量,同时进行 GC,我们称之为 紧缩 ( Compaction).
该方案的问题 :如果出现宕机,内存中的数据结构将会消失。 解决方法也很经典:WAL.
将前面几节的一些碎片有机的组织起来,便是时下流行的存储引擎 LevelDB 和 RocksDB 后面的存储结构:LSM-Tree:

。
。
。
。
这种数据结构是 Patrick O’Neil 等人,在 1996 年提出的: The Log-Structured Merge-Tree .
Elasticsearch 和 Solr 的索引引擎 Lucene,也使用类似 LSM-Tree 存储结构。但其数据模型不是 KV,但类似:word → document list.
如果想让一个引擎工程上可用,还会做大量的性能优化。对于 LSM-Tree 来说,包括:
优化 SSTable 的查找。 常用 Bloom Filter 。该数据结构可以使用较少的内存为每个 SSTable 做一些指纹,起到一些初筛的作用.
层级化组织 SSTable 。以控制 Compaction 的顺序和时间。常见的有 size-tiered 和 leveled compaction。LevelDB 便是支持后者而得名。前者比较简单粗暴,后者性能更好,也因此更为常见.
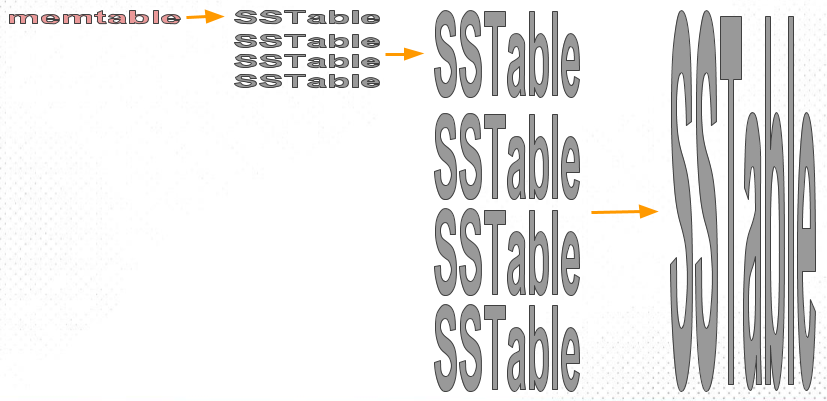
。
。
对于 RocksDB 来说,工程上的优化和使用上的优化就更多了。在其 Wiki 上随便摘录几点:
但无论有多少变种和优化,LSM-Tree 的核心思想 —— 保存一组合理组织、后台合并的 SSTables —— 简约而强大。可以方便的进行范围遍历,可以变大量随机为少量顺序.
虽然先讲的 LSM-Tree,但是它要比 B+ 树新的多.
B 树于 1970 年被 R. Bayer and E. McCreight 提出 后,便迅速流行了起来。现在几乎所有的关系型数据中,它都是数据索引标准一般的实现.
与 LSM-Tree 一样,它也支持高效的 点查 和 范围查 。但却使用了完全不同的组织方式.
其特点有:

。
。
查找 。从根节点出发,进行二分查找,然后加载新的页到内存中,继续二分,直到命中或者到叶子节点。 查找复杂度,树的高度 —— O (lgn),影响树高度的因素:分支因子(分叉数,通常是几百个).
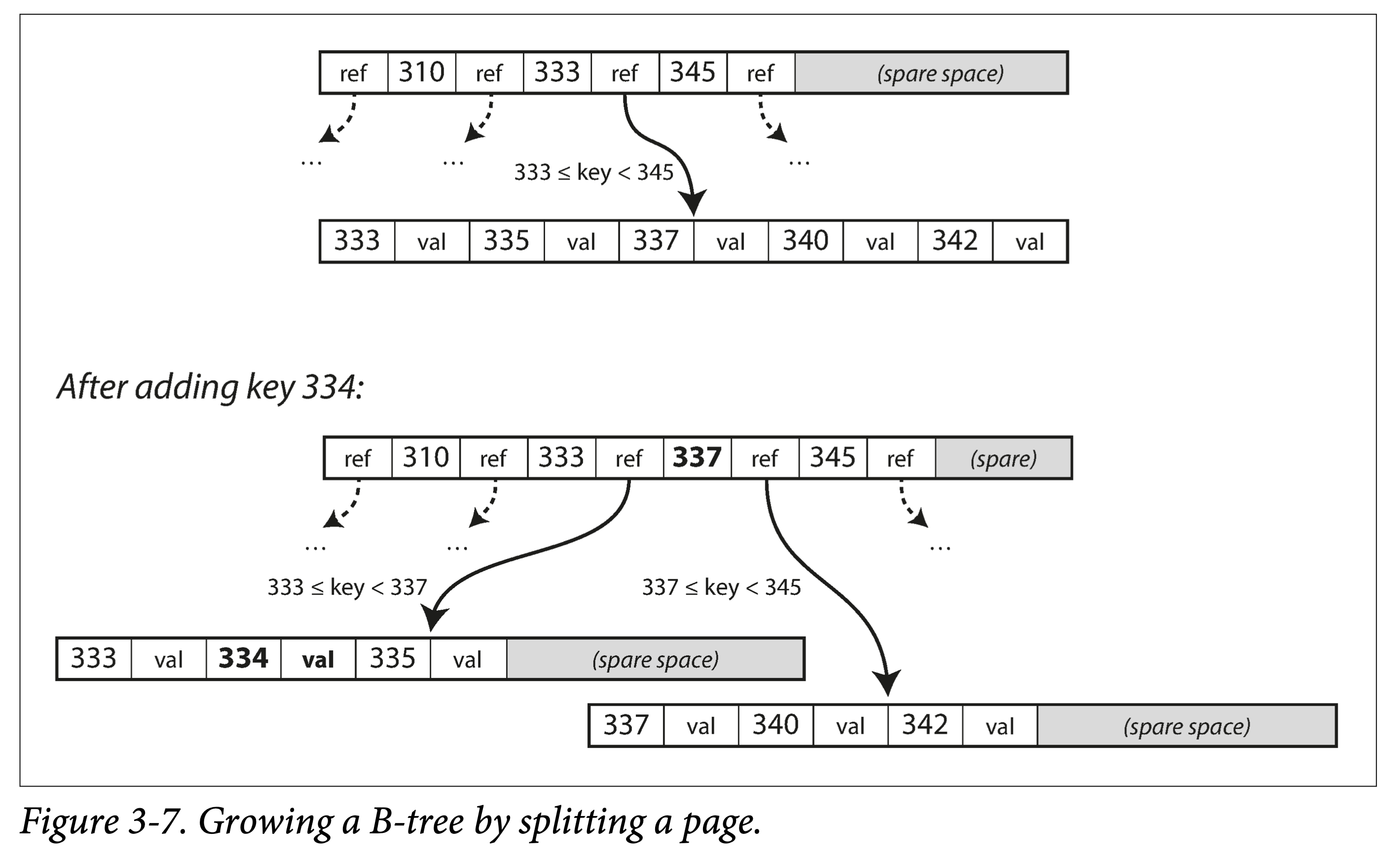
。
。
插入 or 更新 。和查找过程一样,定位到原 Key 所在页,插入或者更新后,将页完整写回。如果页剩余空间不够,则分裂后写入.
分裂 or 合并 。级联分裂和合并.
一个记录大于一个 page 怎么办?
B 树不像 LSM-Tree ,会在原地修改数据文件.
在树结构调整时,可能会级联修改很多 Page。比如叶子节点分裂后,就需要写入两个新的叶子节点,和一个父节点(更新叶子指针).
B 树出来了这么久,因此有很多优化:
| 存储引擎 。 |
B-Tree 。 |
LSM-Tree 。 |
备注 。 |
| 优势 。 |
读取更快 。 |
写入更快 。 |
。 |
| 写放大 。 |
1. 数据和 WAL 。 2. 更改数据时多次覆盖整个 Page 。 |
1. 数据和 WAL 。 2. Compaction 。 |
SSD 不能过多擦除。因此 SSD 内部的固件中也多用日志结构来减少随机小写. |
| 写吞吐 。 |
相对较低: 1. 大量随机写. |
相对较高: 1. 较低的写放大(取决于数据和配置) 。 2. 顺序写入. 3. 更为紧凑. |
。 |
| 压缩率 。 |
1. 存在较多内部碎片. |
1. 更加紧凑,没有内部碎片. 2. 压缩潜力更大(共享前缀). |
但紧缩不及时会造成 LSM-Tree 存在很多垃圾 。 |
| 后台流量 。 |
1. 更稳定可预测,不会受后台 compaction 突发流量影响. |
1. 写吞吐过高,compaction 跟不上,会进一步加重读放大. 2. 由于外存总带宽有限,compaction 会影响读写吞吐. 3. 随着数据越来越多,compaction 对正常写影响越来越大. |
RocksDB 写入太过快会引起 write stall,即限制写入,以期尽快 compaction 将数据下沉. |
| 存储放大 。 |
1. 有些 Page 没有用满 。 |
1. 同一个 Key 存多遍 。 |
。 |
| 并发控制 。 |
1. 同一个 Key 只存在一个地方 。 2. 树结构容易加范围锁. |
同一个 Key 会存多遍,一般使用 MVCC 进行控制. |
。 |
最后此篇关于数据密集型应用存储与检索设计的文章就讲到这里了,如果你想了解更多关于数据密集型应用存储与检索设计的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
我正在通过 labrepl 工作,我看到了一些遵循此模式的代码: ;; Pattern (apply #(apply f %&) coll) ;; Concrete example user=> (a
我从未向应用商店提交过应用,但我会在不久的将来提交。 到目前为止,我对为 iPhone 而非 iPad 进行设计感到很自在。 我了解,通过将通用PAID 应用放到应用商店,客户只需支付一次就可以同时使
我有一个应用程序,它使用不同的 Facebook 应用程序(2 个不同的 AppID)在 Facebook 上发布并显示它是“通过 iPhone”/“通过 iPad”。 当 Facebook 应用程序
我有一个要求,我们必须通过将网站源文件保存在本地 iOS 应用程序中来在 iOS 应用程序 Webview 中运行网站。 Angular 需要服务器来运行应用程序,但由于我们将文件保存在本地,我们无法
所以我有一个单页客户端应用程序。 正常流程: 应用程序 -> OAuth2 服务器 -> 应用程序 我们有自己的 OAuth2 服务器,因此人们可以登录应用程序并获取与用户实体关联的 access_t
假设我有一个安装在用户设备上的 Android 应用程序 A,我的应用程序有一个 AppWidget,我们可以让其他 Android 开发人员在其中以每次安装成本为基础发布他们的应用程序推广广告。因此
Secrets of the JavaScript Ninja中有一个例子它提供了以下代码来绕过 JavaScript 的 Math.min() 函数,该函数需要一个可变长度列表。 Example:
当我分别将数组和对象传递给 function.apply() 时,我得到 NaN 的 o/p,但是当我传递对象和数组时,我得到一个数字。为什么会发生这种情况? 由于数组也被视为对象,为什么我无法使用它
CFSDN坚持开源创造价值,我们致力于搭建一个资源共享平台,让每一个IT人在这里找到属于你的精彩世界. 这篇CFSDN的博客文章ASP转换格林威治时间函数DateDiff()应用由作者收集整理,如果你
我正在将列表传递给 map并且想要返回一个带有合并名称的 data.frame 对象。 例如: library(tidyverse) library(broom) mtcars %>% spl
我有一个非常基本的问题,但我不知道如何实现它:我有一个返回数据框,其中每个工具的返回值是按行排列的: tmp<-as.data.frame(t(data.frame(a=rnorm(250,0,1)
我正在使用我的 FB 应用创建群组并邀请用户加入我的应用群组,第一次一切正常。当我尝试创建另一个组时,出现以下错误: {"(OAuthException - #4009) (#4009) 在有更多用户
我们正在开发一款类似于“会说话的本”应用程序的 child 应用程序。它包含大量用于交互式动画的 JPEG 图像序列。 问题是动画在 iPad Air 上播放正常,但在 iPad 2 上播放缓慢或滞后
我关注 clojure 一段时间了,它的一些功能非常令人兴奋(持久数据结构、函数式方法、不可变状态)。然而,由于我仍在学习,我想了解如何在实际场景中应用,证明其好处,然后演化并应用于更复杂的问题。即,
我开发了一个仅使用挪威语的应用程序。该应用程序不使用本地化,因为它应该仅以一种语言(挪威语)显示。但是,我已在 Info.plist 文件中将“本地化 native 开发区域”设置为“no”。我还使用
读完 Anthony's response 后上a style-related parser question ,我试图说服自己编写单体解析器仍然可以相当紧凑。 所以而不是 reference ::
multicore 库中是否有类似 sapply 的东西?还是我必须 unlist(mclapply(..)) 才能实现这一点? 如果它不存在:推理是什么? 提前致谢,如果这是一个愚蠢的问题,我们深表
我喜欢在窗口中弹出结果,以便更容易查看和查找(例如,它们不会随着控制台继续滚动而丢失)。一种方法是使用 sink() 和 file.show()。例如: y <- rnorm(100); x <- r
我有一个如下所示的 spring mvc Controller @RequestMapping(value="/new", method=RequestMethod.POST) public Stri
我正在阅读 StructureMap关于依赖注入(inject),首先有两部分初始化映射,具体类类型的接口(interface),另一部分只是实例化(请求实例)。 第一部分需要配置和设置,这是在 Bo

我是一名优秀的程序员,十分优秀!