
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4


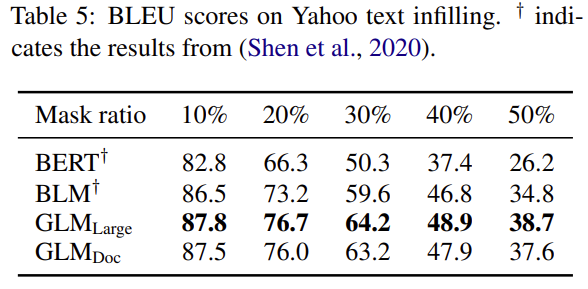
ChatGPT已经火了一段时间了,国内也出现了一些平替,其中比较容易使用的是ChatGLM-6B: https://github.com/THUDM/ChatGLM-6B ,主要是能够让我们基于单卡自己部署。ChatGLM的基座是GLM: General Language Model Pretraining with Autoregressive Blank Infilling论文中提出的模型,接下来我们来看看.
论文名称:GLM: General Language Model Pretraining with Autoregressive Blank Infilling 。
论文地址: https://aclanthology.org/2022.acl-long.26.pdf 。
代码地址: https://github.com/THUDM/GLM 。
预训练语言吗模型大体可以分为三种:自回归(GPT系列)、自编码(BERT系列)、编码-解码(T5、BART),它们每一个都在各自的领域上表现不俗,但是,目前没有一个预训练模型能够很好地完成所有任务。GLM是一个通用的预训练语言模型,它在NLU(自然语言理解)、conditional(条件文本生成) and unconditional generation(非条件文本生成)上都有着不错的表现.
GLM的核心是:Autoregressive Blank Infilling,如下图1所示:
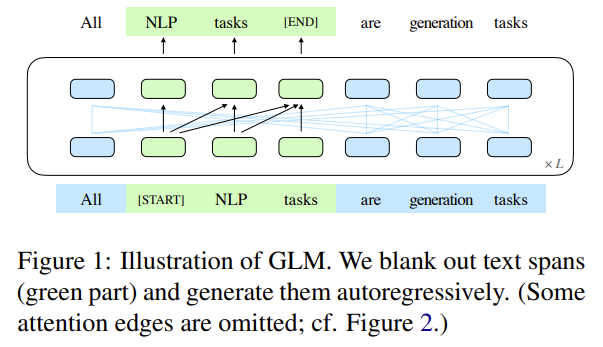
即,将文本中的一段或多段空白进行填充识别。具体细节如图2所示:

说明,对于一个文本: \(x_{1},x_{2},x_{3},x_{4},x_{5}\) ,空白长度会以 \(\lambda=3\) 的泊松分布进行采样。重复采样直到空白token的总数目占文本token数的15%。将文本分为两部分,A部分由原始token和[MASK]组成,B部分由空白token组成,最终将A部分和B部分进行拼接,同时B部分的每一个空白会被打乱,这样在自回归预测每个token的时候可以看到上下文的信息(具体通过注意力掩码来实现)。需要注意的是位置编码是2D的,位置编码1用于表示token在文本的位置,位置编码2用于表示原始文本和每一个空白中token的顺序.
为了能够兼顾NLU和文本生成,对于文档和句子采用不同的空白填充方式.
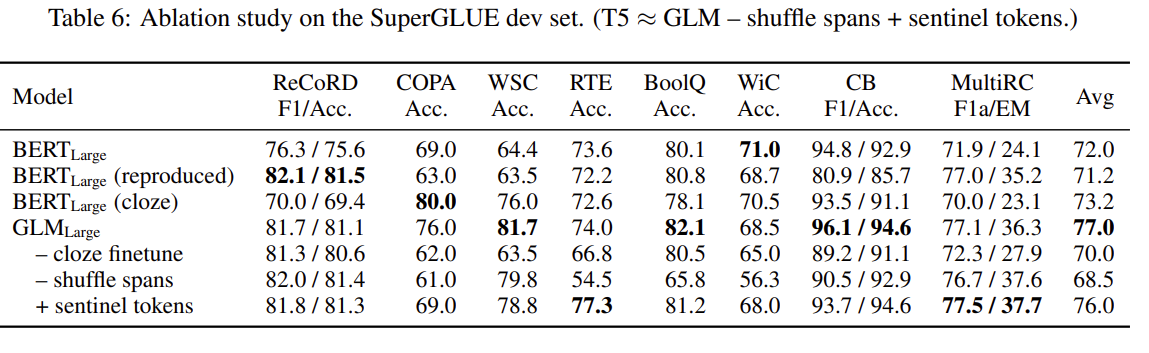
GLM使用单个Transformer,并对架构进行了修改
(1)调整layer normalization和residual connection的顺序.
(2)使用单一线性层进行输出token预测.
(3)将ReLU激活函数替换为GeLUs.
两个位置id通过可学习嵌入表投影到两个向量,这两个向量都被添加到输入标记嵌入中。该编码方法确保模型在重建时不知道被屏蔽的跨度的长度。这种设计适合下游任务,因为通常生成的文本的长度是事先未知的.

对于分类任务,在模板后面预测类别.
对于文本生成任务,输入的文本视为A部分,在该部分后面添加[MASK],使用自回归来生成文本.
这样的好处是预训练和微调是保持一致的.
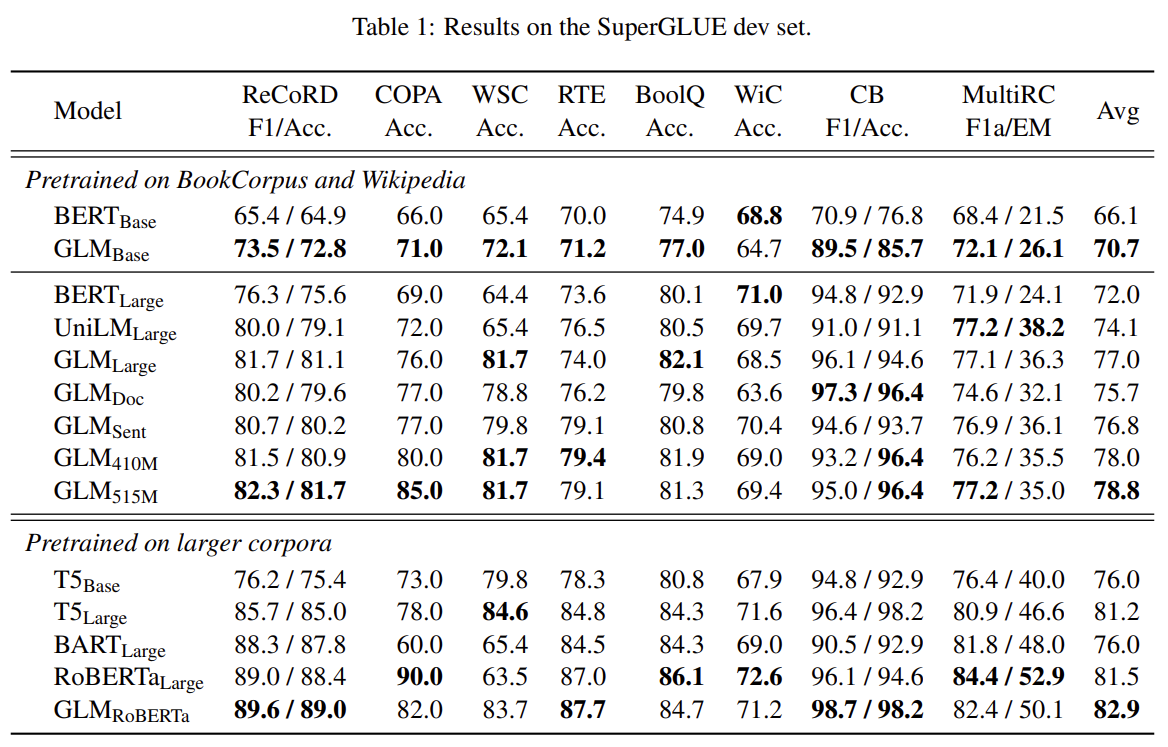
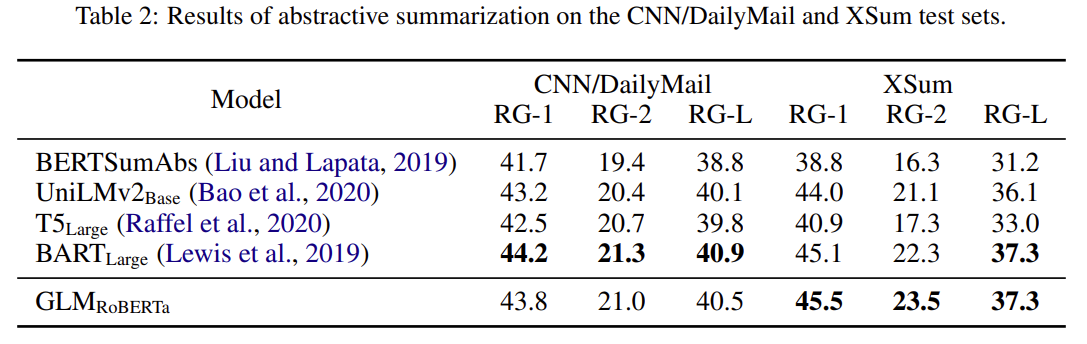
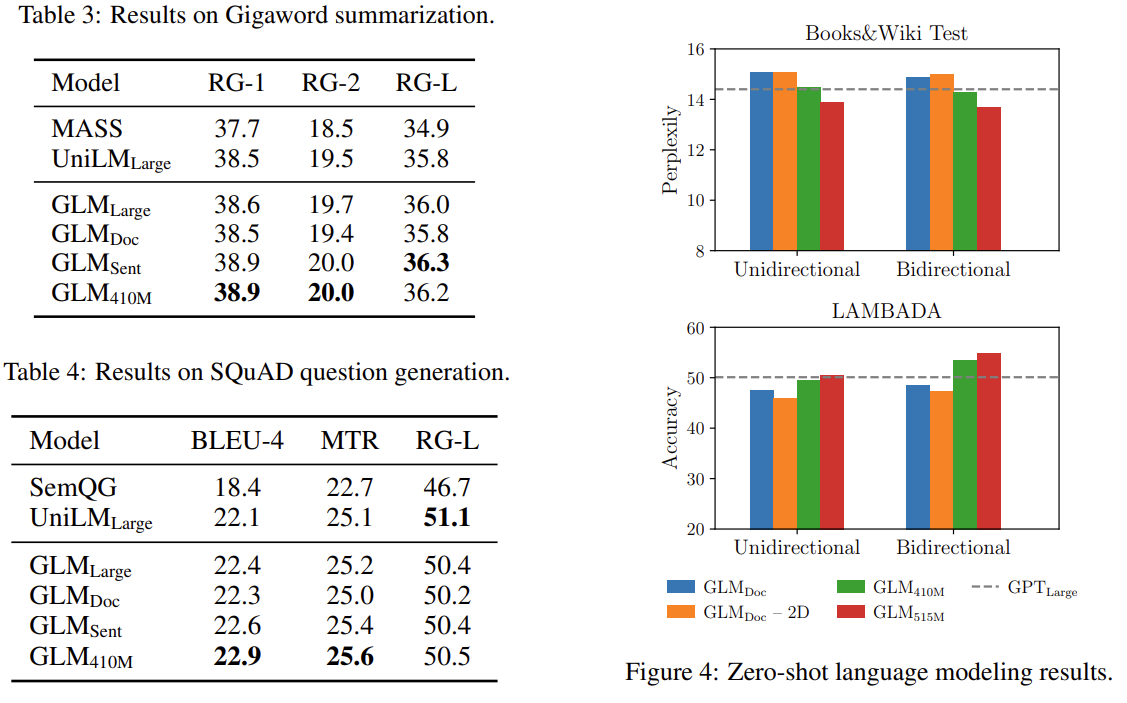
最后此篇关于GLM:通用语言模型的文章就讲到这里了,如果你想了解更多关于GLM:通用语言模型的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
我使用 AppFuse 创建项目已经有一段时间了。我已经知道有两种方法可以开发 DAO 和 Manager 类: GenericDao/GenericManager 方法 UniversalDao/U
很难说出这里问的是什么。这个问题是含糊的、模糊的、不完整的、过于宽泛的或修辞性的,无法以目前的形式得到合理的回答。如需帮助澄清此问题以便重新打开它,visit the help center 。 已关
在普通的单线程程序中,捕获异常只需要通过try ... catch ... finally ...代码块就可以了。那么,在并发情况下,比如在父线程中启动了子线程,如何在父线程中捕获来自子线程的异常,
假设我有一个这样的界面 interface Example { first_name: string, last_name: string, home_town: string
我已经成为 hg 用户几年了,对此我很高兴! 我必须开始一个我以前从未做过的项目。我们的想法是开发一个具有批处理模式和 GUI 的软件。 因此,批处理模式和 GUI 模式都有共同的源,但每种模式也都包
我可以在Silverlight中使用generic.xaml来设置应用程序中所有TextBlock的样式吗? 我原以为它会起作用,但它没
顶部 map 有 3 个子 map ,每个子 map 都有不同的对象。 像下面的代码,如何将通用添加到 map 顶部? Map top = new ConcurrentHashMap();
我想创建一个hashmap,其中键是接口(interface)A,值是接口(interface)B。然后我想用实现A和B的类来初始化它。是否可以使用java泛型来做到这一点? 也就是说,我想要类似的东
Enum 位于 java.lang.Enum 中,Object 位于 java.lang.Object 中>。那么,为什么 Enum 不是 Object 呢? (我收到一个java.lang.Clas
我有一种方法,check,它有两个 HashMap 作为参数。这些映射的键是 String,值是 String 或 Arraylist。 哪个是更好的解决方案: public static boole
我启动了针对iPhone的应用程序,现在我也想将其应用程序用于iPad。当我开始做iPhone项目时,即使我添加了iPad xib,它也无法正确显示,如何转换我的项目同时适用于iPhone和iPad(
这行代码(代码1)有什么区别 auto l1 = [](auto a) { static int l = 0; std::cout operator() for type const char*) 被
使用 Generic#to,我可以获得 case class 的 HList 表示: import shapeless._ case class F(x: Int, y: String) scala>
我有一个 BiDiMap 类。如何使其通用,不仅接受 String 而且接受 Object 类型的对象作为输入参数,同时保持所有原始函数正常工作。例如,我希望能够使用函数 put() 和 Object
我在编译 foreach 循环时遇到问题。我很确定这是我的泛型处理的问题,因为该错误是对象兼容性问题。我已搜索解决方案,但找不到任何可以解决该问题的内容。 这是定义 Iterable adjList
大约有 6 个 POJO 类(域实体、DTO、DMO)都具有几乎相同的字段。为了从一个对象转换为另一个对象,我传递一个对象并调用它的 getter 将其设置到另一个对象中。 private UserT
有没有什么方法可以创建一个通用的 for 循环,它可以正确地循环遍历数组或对象?我知道我可以编写以下 for 循环,但它也会遍历将添加到数组的其他属性。 for (item in x) { co
我已经有一段时间没有写js了,显然有点生疏了。试图理解以下问题。 getCurrentPosition successCallback 中的警报正确显示纬度,但最后一行警报未定义。为什么我的 clie
请帮助我,我从来没有用 xib 为 iPhone/iPad 制作过通用的 UIViewControllers。如何使用 .m 和 .h 文件以及 _iphone.xib 和 _ipad.xib 创建类
我正在尝试创建一个 createRequest 函数,我可以将其重新用于我的所有网络调用,有些需要发布 JSON 而其他则不需要,所以我正在考虑创建一个采用可选通用对象的函数;理论上是这样的: str

我是一名优秀的程序员,十分优秀!