
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


在本篇文章当中主要给大家介绍在 cpython 内部,bytes 的实现原理、内存布局以及与 bytes 相关的一个比较重要的优化点—— bytes 的拼接.
typedef struct {
PyObject_VAR_HEAD
Py_hash_t ob_shash;
char ob_sval[1];
/* Invariants:
* ob_sval contains space for 'ob_size+1' elements.
* ob_sval[ob_size] == 0.
* ob_shash is the hash of the string or -1 if not computed yet.
*/
} PyBytesObject;
typedef struct {
PyObject ob_base;
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;
typedef struct _object {
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
} PyObject;
上面的数据结构用图示如下所示:
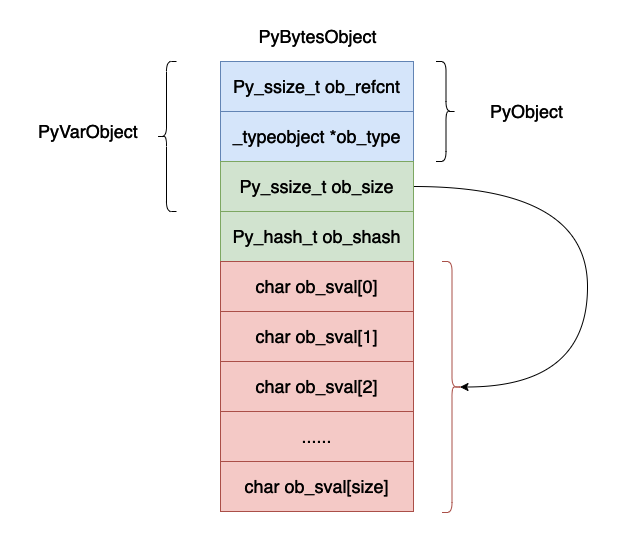
现在我们来解释一下上面的数据结构各个字段的含义:
可能你会有疑问上面的结构体当中并没有后面的那么多字节啊,数组只有一个字节的数据啊,这是因为在 cpython 的实现当中除了申请 PyBytesObject 大的小内存空间之外,还会在这个基础之上申请连续的额外的内存空间用于保存数据,在后续的源码分析当中可以看到这一点.
下面我们举几个例子来说明一下上面的布局:
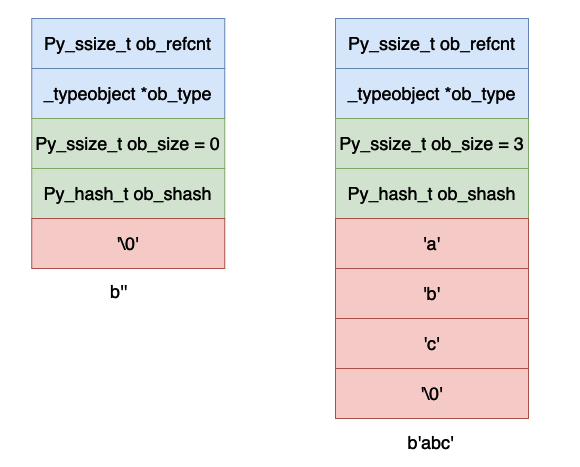
上面是空和字符串 abc 的字节表示.
下面是在 cpython 当中通过字节数创建 PyBytesObject 对象的函数。下面的函数的主要功能是创建一个能够存储 size 个字节大小的数据的 PyBytesObject 对象,下面的函数最重要的一个步骤就是申请内存空间.
static PyObject *
_PyBytes_FromSize(Py_ssize_t size, int use_calloc)
{
PyBytesObject *op;
assert(size >= 0);
if (size == 0 && (op = nullstring) != NULL) {
#ifdef COUNT_ALLOCS
null_strings++;
#endif
Py_INCREF(op);
return (PyObject *)op;
}
if ((size_t)size > (size_t)PY_SSIZE_T_MAX - PyBytesObject_SIZE) {
PyErr_SetString(PyExc_OverflowError,
"byte string is too large");
return NULL;
}
/* Inline PyObject_NewVar */
// PyBytesObject_SIZE + size 就是实际申请的内存空间的大小 PyBytesObject_SIZE 就是表示 PyBytesObject 各个字段占用的实际的内存空间大小
if (use_calloc)
op = (PyBytesObject *)PyObject_Calloc(1, PyBytesObject_SIZE + size);
else
op = (PyBytesObject *)PyObject_Malloc(PyBytesObject_SIZE + size);
if (op == NULL)
return PyErr_NoMemory();
// 将对象的 ob_size 字段赋值成 size
(void)PyObject_INIT_VAR(op, &PyBytes_Type, size);
// 由于对象的哈希值还没有进行计算 因此现将哈希值赋值成 -1
op->ob_shash = -1;
if (!use_calloc)
op->ob_sval[size] = '\0';
/* empty byte string singleton */
if (size == 0) {
nullstring = op;
Py_INCREF(op);
}
return (PyObject *) op;
}
我们可以使用一个写例子来看一下实际的 PyBytesObject 内存空间的大小.
>>> import sys
>>> a = b"hello world"
>>> sys.getsizeof(a)
44
>>>
上面的 44 = 32 + 11 + 1 .
其中 32 是 PyBytesObject 4 个字段所占用的内存空间,ob_refcnt、ob_type、ob_size和 ob_shash 各占 8 个字节。11 是表示字符串 "hello world" 占用 11 个字节,最后一个字节是 '\0' .
这个函数主要是返回 PyBytesObject 对象的字节长度,也就是直接返回 ob_size 的值.
static Py_ssize_t
bytes_length(PyBytesObject *a)
{
// (((PyVarObject*)(ob))->ob_size)
return Py_SIZE(a);
}
在 python 当中执行下面的代码就会执行字节拼接函数:
>>> b"abc" + b"edf"
下方就是具体的执行字节拼接的函数:
/* This is also used by PyBytes_Concat() */
static PyObject *
bytes_concat(PyObject *a, PyObject *b)
{
Py_buffer va, vb;
PyObject *result = NULL;
va.len = -1;
vb.len = -1;
// Py_buffer 当中有一个指针字段 buf 可以用户保存 PyBytesObject 当中字节数据的首地址
// PyObject_GetBuffer 函数的主要作用是将 对象 a 当中的字节数组赋值给 va 当中的 buf
if (PyObject_GetBuffer(a, &va, PyBUF_SIMPLE) != 0 ||
PyObject_GetBuffer(b, &vb, PyBUF_SIMPLE) != 0) {
PyErr_Format(PyExc_TypeError, "can't concat %.100s to %.100s",
Py_TYPE(b)->tp_name, Py_TYPE(a)->tp_name);
goto done;
}
/* Optimize end cases */
if (va.len == 0 && PyBytes_CheckExact(b)) {
result = b;
Py_INCREF(result);
goto done;
}
if (vb.len == 0 && PyBytes_CheckExact(a)) {
result = a;
Py_INCREF(result);
goto done;
}
if (va.len > PY_SSIZE_T_MAX - vb.len) {
PyErr_NoMemory();
goto done;
}
result = PyBytes_FromStringAndSize(NULL, va.len + vb.len);
// 下方就是将对象 a b 当中的字节数据拷贝到新的
if (result != NULL) {
// PyBytes_AS_STRING 宏定义在下方当中 主要就是使用 PyBytesObject 对象当中的
// ob_sval 字段 也就是将 buf 数据(也就是 a 或者 b 当中的字节数据)拷贝到 ob_sval当中
memcpy(PyBytes_AS_STRING(result), va.buf, va.len);
memcpy(PyBytes_AS_STRING(result) + va.len, vb.buf, vb.len);
}
done:
if (va.len != -1)
PyBuffer_Release(&va);
if (vb.len != -1)
PyBuffer_Release(&vb);
return result;
}
#define PyBytes_AS_STRING(op) (assert(PyBytes_Check(op)), \
(((PyBytesObject *)(op))->ob_sval))
我们修改一个这个函数,在其中加入一条打印语句,然后重新编译 python 执行结果如下所示:

Python 3.9.0b1 (default, Mar 23 2023, 08:35:33)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> b"abc" + b"edf"
In concat function: abc <> edf
b'abcedf'
>>>
在上面的拼接函数当中会拷贝原来的两个字节对象,因此需要谨慎使用,一旦发生非常多的拷贝的话是非常耗费内存的。因此需要警惕使用循环内的内存拼接。比如对于 [b"a", b"b", b"c"] 来说,如果使用循环拼接的话,那么会将 b"a" 拷贝两次.
>>> res = b""
>>> for item in [b"a", b"b", b"c"]:
... res += item
...
>>> res
b'abc'
>>>
因为 b"a", b"b" 在拼接的时候会将他们分别拷贝一次,在进行 b"ab",b"c" 拼接的时候又会将 ab 和 c 拷贝一次,那么具体的拷贝情况如下所示:
但是实际上我们的需求是只需要对 [b"a", b"b", b"c"] 当中的数据各拷贝一次,如果我们要实现这一点可以使用 b"".join([b"a", b"b", b"c"]),直接将 [b"a", b"b", b"c"] 作为参数传递,然后各自只拷贝一次,具体的实现代码如下所示,在这个例子当中 sep 就是空串 b"",iterable 就是 [b"a", b"b", b"c"] .
Py_LOCAL_INLINE(PyObject *)
STRINGLIB(bytes_join)(PyObject *sep, PyObject *iterable)
{
char *sepstr = STRINGLIB_STR(sep);
const Py_ssize_t seplen = STRINGLIB_LEN(sep);
PyObject *res = NULL;
char *p;
Py_ssize_t seqlen = 0;
Py_ssize_t sz = 0;
Py_ssize_t i, nbufs;
PyObject *seq, *item;
Py_buffer *buffers = NULL;
#define NB_STATIC_BUFFERS 10
Py_buffer static_buffers[NB_STATIC_BUFFERS];
seq = PySequence_Fast(iterable, "can only join an iterable");
if (seq == NULL) {
return NULL;
}
seqlen = PySequence_Fast_GET_SIZE(seq);
if (seqlen == 0) {
Py_DECREF(seq);
return STRINGLIB_NEW(NULL, 0);
}
#ifndef STRINGLIB_MUTABLE
if (seqlen == 1) {
item = PySequence_Fast_GET_ITEM(seq, 0);
if (STRINGLIB_CHECK_EXACT(item)) {
Py_INCREF(item);
Py_DECREF(seq);
return item;
}
}
#endif
if (seqlen > NB_STATIC_BUFFERS) {
buffers = PyMem_NEW(Py_buffer, seqlen);
if (buffers == NULL) {
Py_DECREF(seq);
PyErr_NoMemory();
return NULL;
}
}
else {
buffers = static_buffers;
}
/* Here is the general case. Do a pre-pass to figure out the total
* amount of space we'll need (sz), and see whether all arguments are
* bytes-like.
*/
for (i = 0, nbufs = 0; i < seqlen; i++) {
Py_ssize_t itemlen;
item = PySequence_Fast_GET_ITEM(seq, i);
if (PyBytes_CheckExact(item)) {
/* Fast path. */
Py_INCREF(item);
buffers[i].obj = item;
buffers[i].buf = PyBytes_AS_STRING(item);
buffers[i].len = PyBytes_GET_SIZE(item);
}
else if (PyObject_GetBuffer(item, &buffers[i], PyBUF_SIMPLE) != 0) {
PyErr_Format(PyExc_TypeError,
"sequence item %zd: expected a bytes-like object, "
"%.80s found",
i, Py_TYPE(item)->tp_name);
goto error;
}
nbufs = i + 1; /* for error cleanup */
itemlen = buffers[i].len;
if (itemlen > PY_SSIZE_T_MAX - sz) {
PyErr_SetString(PyExc_OverflowError,
"join() result is too long");
goto error;
}
sz += itemlen;
if (i != 0) {
if (seplen > PY_SSIZE_T_MAX - sz) {
PyErr_SetString(PyExc_OverflowError,
"join() result is too long");
goto error;
}
sz += seplen;
}
if (seqlen != PySequence_Fast_GET_SIZE(seq)) {
PyErr_SetString(PyExc_RuntimeError,
"sequence changed size during iteration");
goto error;
}
}
/* Allocate result space. */
res = STRINGLIB_NEW(NULL, sz);
if (res == NULL)
goto error;
/* Catenate everything. */
p = STRINGLIB_STR(res);
if (!seplen) {
/* fast path */
for (i = 0; i < nbufs; i++) {
Py_ssize_t n = buffers[i].len;
char *q = buffers[i].buf;
Py_MEMCPY(p, q, n);
p += n;
}
goto done;
}
// 具体的实现逻辑就是在这里
for (i = 0; i < nbufs; i++) {
Py_ssize_t n;
char *q;
if (i) {
// 首先现将 sepstr 拷贝到新的数组里面但是在我们举的例子当中是空串 b""
Py_MEMCPY(p, sepstr, seplen);
p += seplen;
}
n = buffers[i].len;
q = buffers[i].buf;
// 然后将列表当中第 i 个 bytes 的数据拷贝到 p 当中 这样就是实现了我们所需要的效果
Py_MEMCPY(p, q, n);
p += n;
}
goto done;
error:
res = NULL;
done:
Py_DECREF(seq);
for (i = 0; i < nbufs; i++)
PyBuffer_Release(&buffers[i]);
if (buffers != static_buffers)
PyMem_FREE(buffers);
return res;
}
在 cpython 的内部实现当中给单字节的字符做了一个小的缓冲池:
static PyBytesObject *characters[UCHAR_MAX + 1]; // UCHAR_MAX 在 64 位系统当中等于 255
当创建的 bytes 只有一个字符的时候就可以检查是否 characters 当中已经存在了,如果存在就直接返回这个已经创建好的 PyBytesObject 对象,否则再进行创建。新创建的 PyBytesObject 对象如果长度等于 1 的话也会被加入到这个数组当中。下面是 PyBytesObject 的另外一个创建函数:
PyObject *
PyBytes_FromStringAndSize(const char *str, Py_ssize_t size)
{
PyBytesObject *op;
if (size < 0) {
PyErr_SetString(PyExc_SystemError,
"Negative size passed to PyBytes_FromStringAndSize");
return NULL;
}
// 如果创建长度等于 1 而且对象在 characters 当中存在的话那么就直接返回
if (size == 1 && str != NULL &&
(op = characters[*str & UCHAR_MAX]) != NULL)
{
#ifdef COUNT_ALLOCS
one_strings++;
#endif
Py_INCREF(op);
return (PyObject *)op;
}
op = (PyBytesObject *)_PyBytes_FromSize(size, 0);
if (op == NULL)
return NULL;
if (str == NULL)
return (PyObject *) op;
Py_MEMCPY(op->ob_sval, str, size);
/* share short strings */
// 如果创建的对象的长度等于 1 那么久将这个对象保存到 characters 当中
if (size == 1) {
characters[*str & UCHAR_MAX] = op;
Py_INCREF(op);
}
return (PyObject *) op;
}
我们可以使用下面的代码进行验证:
>>> a = b"a"
>>> b =b"a"
>>> a == b
True
>>> a is b
True
>>> a = b"aa"
>>> b = b"aa"
>>> a == b
True
>>> a is b
False
从上面的代码可以知道,确实当我们创建的 bytes 的长度等于 1 的时候对象确实是同一个对象.
在本篇文章当中主要给大家介绍了在 cpython 内部对于 bytes 的实现,重点介绍了 cpython 当中 PyBytesObject 的内存布局和创建 PyBytesObject 的函数,以及对于 bytes 对象的拼接细节和 cpython 内部单字节字符的缓冲池。在程序当中最好使用 join 操作进行 btyes 的拼接操作,否则效率会比较低.
本篇文章是深入理解 python 虚拟机系列文章之一,文章地址: https://github.com/Chang-LeHung/dive-into-cpython 。
更多精彩内容合集可访问项目: https://github.com/Chang-LeHung/CSCore 。
关注公众号:一无是处的研究僧,了解更多计算机(Java、Python、计算机系统基础、算法与数据结构)知识.
最后此篇关于深入理解Python虚拟机:字节(bytes)的实现原理及源码剖析的文章就讲到这里了,如果你想了解更多关于深入理解Python虚拟机:字节(bytes)的实现原理及源码剖析的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
本文全面深入地探讨了Docker容器通信技术,从基础概念、网络模型、核心组件到实战应用。详细介绍了不同网络模式及其实现,提供了容器通信的技术细节和实用案例,旨在为专业从业者提供深入的技术洞见和实
📒博客首页:崇尚学技术的科班人 🍣今天给大家带来的文章是《Dubbo快速上手 -- 带你了解Dubbo使用、原理》🍣 🍣希望各位小伙伴们能够耐心的读完这篇文章🍣 🙏博主也在学习阶段,如若发
一、写在前面 我们经常使用npm install ,但是你是否思考过它内部的原理是什么? 1、执行npm install 它背后帮助我们完成了什么操作? 2、我们会发现还有一个成为package-lo
Base64 Base64 是什么?是将字节流转换成可打印字符、将可打印字符转换为字节流的一种算法。Base64 使用 64 个可打印字符来表示转换后的数据。 准确的来说,Base64 不算
目录 协程定义 生成器和yield语义 Future类 IOLoop类 coroutine函数装饰器 总结 tornado中的
切片,这是一个在go语言中引入的新的理念。它有一些特征如下: 对数组抽象 数组长度不固定 可追加元素 切片容量可增大 容量大小成片增加 我们先把上面的理念整理在这
文章来源:https://sourl.cn/HpZHvy 引 言 本文主要论述的是“RPC 实现原理”,那么首先明确一个问题什么是 RPC 呢?RPC 是 Remote Procedure Call
源码地址(包含所有与springmvc相关的,静态文件路径设置,request请求入参接受,返回值处理converter设置等等): spring-framework/WebMvcConfigurat
请通过简单的java类向我展示一个依赖注入(inject)原理的小例子虽然我已经了解了spring,但是如果我需要用简单的java类术语来解释它,那么你能通过一个简单的例子向我展示一下吗?提前致谢。
1、背景 我们平常使用手机和电脑上网,需要访问公网上的网络资源,如逛淘宝和刷视频,那么手机和电脑是怎么知道去哪里去拿到这个网络资源来下载到本地的呢? 就比如我去食堂拿吃的,我需要
大家好,我是飞哥! 现在 iptables 这个工具的应用似乎是越来越广了。不仅仅是在传统的防火墙、NAT 等功能出现,在今天流行的的 Docker、Kubernets、Istio 项目中也经
本篇涉及到的所有接口在公开文档中均无,需要下载 GitHub 上的源码,自己创建私有类的文档。 npm run generateDocumentation -- --private yarn gene
我最近在很多代码中注意到人们将硬编码的配置(如端口号等)值放在类/方法的深处,使其难以找到,也无法配置。 这是否违反了 SOLID 原则?如果不是,我是否可以向我的团队成员引用另一个“原则”来说明为什
我是 C#、WPF 和 MVVM 模式的新手。很抱歉这篇很长的帖子,我试图设定我所有的理解点(或不理解点)。 在研究了很多关于 WPF 提供的命令机制和 MVVM 模式的文本之后,我在弄清楚如何使用这
可比较的 jQuery 函数 $.post("/example/handler", {foo: 1, bar: 2}); 将创建一个带有 post 参数 foo=1&bar=2 的请求。鉴于 $htt
如果Django不使用“延迟查询执行”原则,主要问题是什么? q = Entry.objects.filter(headline__startswith="What") q = q.filter(
我今天发现.NET框架在做计算时遵循BODMAS操作顺序。即计算按以下顺序进行: 括号 订单 部门 乘法 添加 减法 但是我四处搜索并找不到任何文档确认 .NET 绝对 遵循此原则,是否有此类文档?如
已结束。此问题不符合 Stack Overflow guidelines .它目前不接受答案。 我们不允许提出有关书籍、工具、软件库等方面的建议的问题。您可以编辑问题,以便用事实和引用来回答它。 关闭
API 回顾 在创建 Viewer 时可以直接指定 影像供给器(ImageryProvider),官方提供了一个非常简单的例子,即离屏例子(搜 offline): new Cesium.Viewer(
As it currently stands, this question is not a good fit for our Q&A format. We expect answers to be

我是一名优秀的程序员,十分优秀!