
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4


新接触一个spark集群,明明集群资源(core,内存)还有剩余,但是提交的任务却申请不到资源.
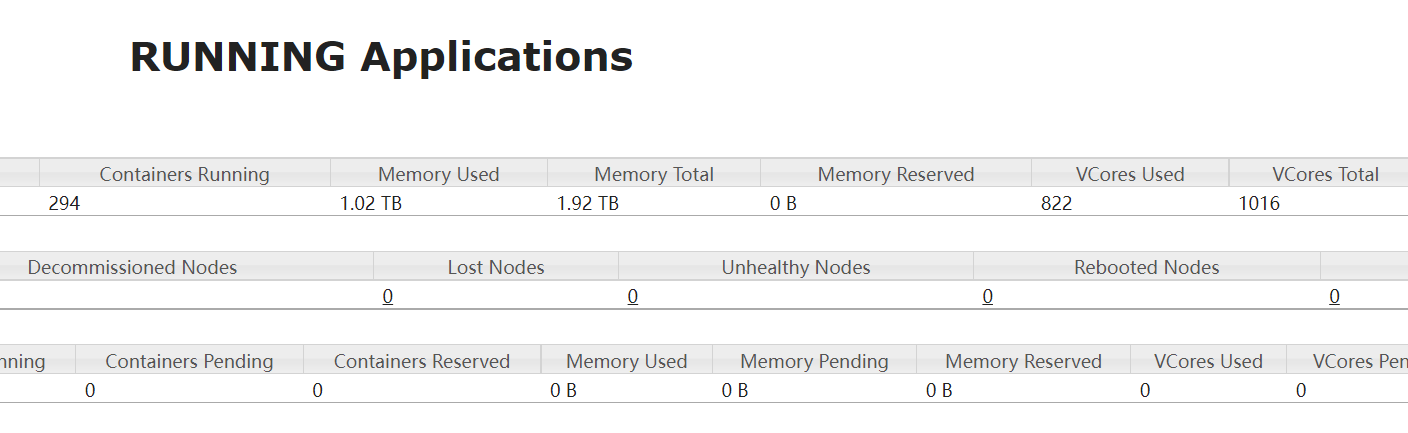
spark 2.2.0 基于yarn集群 。
spark任务提交参数中最重要的几个: spark-submit --master yarn --driver-cores 1 --driver-memory 5G --executor-cores 2 --num-executors 16 --executor-memory 4G 。
driver-cores driver端核数 driver-memory driver端内存大小 executor-cores 每个执行器的核数 num-executors 此任务申请的执行器总数 executor-memory 每个执行器的内存大小 。
那么,该任务将申请多少资源呢?
申请的执行器总内存数大小=num-executor * (executor-memory +spark.yarn.executor.memoryOverhead) = 16 * (4 + 2) = 96 申请的总内存=执行器总内存+dirver端内存=101 申请的总核数=num-executor*executor-core + yarn.AM(默认为1)=33 运行的总容器(contanier) = num-executor + yarn.AM(默认为1) = 17 。
所以这里还有一个关键的参数 spark.yarn.executor.memoryOverhead 。
这个参数是什么意思呢? 堆外内存,每个executor归spark 计算的内存为executor-memory,每个executor是一个单独的JVM,这个JAVA虚拟机本向在的内存大小即为spark.yarn.executor.memoryOverhead,不归spark本身管理。在spark集群中配置。也可在代码中指定 spark.set("spark.yarn.executor.memoryOverhead", 1) 。
这部份实际上是存放spark代码本身的究竟,在 executor-memory 内存不足的时候也能应应急顶上.
假设一个节点16G的内存,每个 executor-memory=4 ,理想情况下 4x4=16 ,那么该节点可以分配出 4 个节点供spark任务计算所用。 1.但应考虑到 spark.yarn.executor.memoryOverhead . 如果 spark.yarn.executor.memoryOverhead=2 ,那么每个executor所需申请的资源为 4+2=6G ,那么该节点只能分配2个节点,剩余16-6x2= 4G 的内存,无法使用.
如果一个集群共100个节点,用户将在yarn集群主界面看到,集群内存剩余400G,但一直无法申请到资源.
2.core也是一样的道理.
很多同学容易忽略 spark.yarn.executor.memoryOverhead 此参数,然后陷入怀疑,怎么申请的资源对不上,也容易陷入优化的误区.
最终优化结果,将spark.yarn.executor.memoryOverhead调小,并根据node节点资源合理优化executor-memory,executor-core大小,将之前经常1.6T的内存占比,降到1.1左右。并能较快申请到资源.
最后此篇关于一次spark任务提交参数的优化的文章就讲到这里了,如果你想了解更多关于一次spark任务提交参数的优化的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
比较代码: const char x = 'a'; std::cout > (0C310B0h) 00C3100B add esp,4 和 const i
您好,我正在使用 Matlab 优化求解器,但程序有问题。我收到此消息 fmincon 已停止,因为目标函数值小于目标函数限制的默认值,并且约束满足在约束容差的默认值范围内。我也收到以下消息。警告:矩
处理Visual Studio optimizations的问题为我节省了大量启动和使用它的时间 当我必须进行 J2EE 开发时,我很难回到 Eclipse。因此,我还想知道人们是否有任何提示或技巧可
情况如下:在我的 Excel 工作表中,有一列包含 1-name 形式的条目。考虑到数字也可以是两位数,我想删除这些数字。这本身不是问题,我让它工作了,只是性能太糟糕了。现在我的程序每个单元格输入大约
这样做有什么区别吗: $(".topHorzNavLink").click(function() { var theHoverContainer = $("#hoverContainer");
这个问题已经有答案了: 已关闭11 年前。 Possible Duplicate: What is the cost of '$(this)'? 我经常在一些开发人员代码中看到$(this)引用同一个
我刚刚结束了一个大型开发项目。我们的时间紧迫,因此很多优化被“推迟”。既然我们已经达到了最后期限,我们将回去尝试优化事情。 我的问题是:优化 jQuery 网站时您要寻找的最重要的东西是什么。或者,我
所以我一直在用 JavaScript 编写游戏(不是网络游戏,而是使用 JavaScript 恰好是脚本语言的游戏引擎)。不幸的是,游戏引擎的 JavaScript 引擎是 SpiderMonkey
这是我在正在构建的页面中使用的 SQL 查询。它目前运行大约 8 秒并返回 12000 条记录,这是正确的,但我想知道您是否可以就如何使其更快提出可能的建议? SELECT DISTINCT Adve
如何优化这个? SELECT e.attr_id, e.sku, a.value FROM product_attr AS e, product_attr_text AS a WHERE e.attr
我正在使用这样的结构来测试是否按下了所需的键: def eventFilter(self, tableView, event): if event.type() == QtCore.QEven
我正在使用 JavaScript 从给定的球员列表中计算出羽毛球 double 比赛的所有组合。每个玩家都与其他人组队。 EG。如果我有以下球员a、b、c、d。它们的组合可以是: a & b V c
我似乎无法弄清楚如何让这个 JS 工作。 scroll function 起作用但不能隐藏。还有没有办法用更少的代码行来做到这一点?我希望 .down-arrow 在 50px 之后 fade out
我的问题是关于用于生产的高级优化级联样式表 (CSS) 文件。 多么最新和最完整(准备在实时元素中使用)的 css 优化器/最小化器,它们不仅提供删除空格和换行符,还提供高级功能,如删除过多的属性、合
我读过这个: 浏览器检索在 中请求的所有资源开始呈现 之前的 HTML 部分.如果您将请求放在 中section 而不是,那么页面呈现和下载资源可以并行发生。您应该从 移动尽可能多的资源请求。
我正在处理一些现有的 C++ 代码,这些代码看起来写得不好,而且调用频率很高。我想知道我是否应该花时间更改它,或者编译器是否已经在优化问题。 我正在使用 Visual Studio 2008。 这是一
我正在尝试使用 OpenGL 渲染 3 个四边形(1 个背景图,2 个 Sprite )。我有以下代码: void GLRenderer::onDrawObjects(long p_dt) {
我确实有以下声明: isEnabled = false; if(foo(arg) && isEnabled) { .... } public boolean foo(arg) { some re
(一)深入浅出理解索引结构 实际上,您可以把索引理解为一种特殊的目录。微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引、簇集索引)和非聚集索引(no
一、写在前面 css的优化方案,之前没有提及,所以接下来进行总结一下。 二、具体优化方案 2.1、加载性能 1、css压缩:将写好的css进行打包,可以减少很多的体积。 2、css单一样式:在需要下边

我是一名优秀的程序员,十分优秀!