
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4


在本篇文章当中主要给大家介绍在 cpython 虚拟机当中的集合 set 的实现原理(哈希表)以及对应的源代码分析.
typedef struct {
PyObject_HEAD
Py_ssize_t fill; /* Number active and dummy entries*/
Py_ssize_t used; /* Number active entries */
/* The table contains mask + 1 slots, and that's a power of 2.
* We store the mask instead of the size because the mask is more
* frequently needed.
*/
Py_ssize_t mask;
/* The table points to a fixed-size smalltable for small tables
* or to additional malloc'ed memory for bigger tables.
* The table pointer is never NULL which saves us from repeated
* runtime null-tests.
*/
setentry *table;
Py_hash_t hash; /* Only used by frozenset objects */
Py_ssize_t finger; /* Search finger for pop() */
setentry smalltable[PySet_MINSIZE]; // #define PySet_MINSIZE 8
PyObject *weakreflist; /* List of weak references */
} PySetObject;
typedef struct {
PyObject *key;
Py_hash_t hash; /* Cached hash code of the key */
} setentry;
static PyObject _dummy_struct;
#define dummy (&_dummy_struct)
上面的数据结果用图示如下图所示:
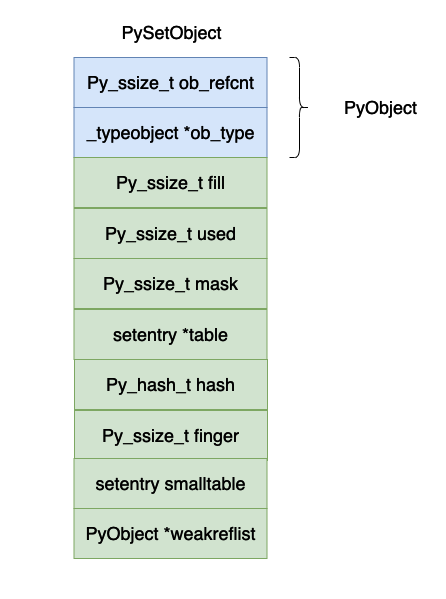
上面各个字段的含义如下所示:
首先先了解一下创建一个集合对象的过程,和前面其他的对象是一样的,首先先申请内存空间,然后进行相关的初始化操作.
这个函数有两个参数,使用第一个参数申请内存空间,然后后面一个参数如果不为 NULL 而且是一个可迭代对象的话,就将这里面的对象加入到集合当中.
static PyObject *
make_new_set(PyTypeObject *type, PyObject *iterable)
{
PySetObject *so = NULL;
/* create PySetObject structure */
so = (PySetObject *)type->tp_alloc(type, 0);
if (so == NULL)
return NULL;
// 集合当中目前没有任何对象,因此 fill 和 used 都是 0
so->fill = 0;
so->used = 0;
// 初始化哈希表当中的数组长度为 PySet_MINSIZE 因此 mask = PySet_MINSIZE - 1
so->mask = PySet_MINSIZE - 1;
// 让 table 指向存储 entry 的数组
so->table = so->smalltable;
// 将哈希值设置成 -1 表示还没有进行计算
so->hash = -1;
so->finger = 0;
so->weakreflist = NULL;
// 如果 iterable 不等于 NULL 则需要将它指向的对象当中所有的元素加入到集合当中
if (iterable != NULL) {
// 调用函数 set_update_internal 将对象 iterable 当中的元素加入到集合当中
if (set_update_internal(so, iterable)) {
Py_DECREF(so);
return NULL;
}
}
return (PyObject *)so;
}
首先我们先大致理清楚往集合当中插入数据的流程:
static PyObject *
set_add(PySetObject *so, PyObject *key)
{
if (set_add_key(so, key))
return NULL;
Py_RETURN_NONE;
}
static int
set_add_key(PySetObject *so, PyObject *key)
{
setentry entry;
Py_hash_t hash;
// 这里就查看一下是否是字符串,如果是字符串直接拿到哈希值
if (!PyUnicode_CheckExact(key) ||
(hash = ((PyASCIIObject *) key)->hash) == -1) {
// 如果不是字符串则需要调用对象自己的哈希函数求得对应的哈希值
hash = PyObject_Hash(key);
if (hash == -1)
return -1;
}
// 创建一个 entry 对象将这个对象加入到哈希表当中
entry.key = key;
entry.hash = hash;
return set_add_entry(so, &entry);
}
static int
set_add_entry(PySetObject *so, setentry *entry)
{
Py_ssize_t n_used;
PyObject *key = entry->key;
Py_hash_t hash = entry->hash;
assert(so->fill <= so->mask); /* at least one empty slot */
n_used = so->used;
Py_INCREF(key);
// 调用函数 set_insert_key 将对象插入到数组当中
if (set_insert_key(so, key, hash)) {
Py_DECREF(key);
return -1;
}
// 这里就是哈希表的核心的扩容机制
if (!(so->used > n_used && so->fill*3 >= (so->mask+1)*2))
return 0;
// 这是扩容大小的逻辑
return set_table_resize(so, so->used>50000 ? so->used*2 : so->used*4);
}
static int
set_insert_key(PySetObject *so, PyObject *key, Py_hash_t hash)
{
setentry *entry;
// set_lookkey 这个函数便是插入的核心的逻辑的实现对应的实现函数在下方
entry = set_lookkey(so, key, hash);
if (entry == NULL)
return -1;
if (entry->key == NULL) {
/* UNUSED */
entry->key = key;
entry->hash = hash;
so->fill++;
so->used++;
} else if (entry->key == dummy) {
/* DUMMY */
entry->key = key;
entry->hash = hash;
so->used++;
} else {
/* ACTIVE */
Py_DECREF(key);
}
return 0;
}
// 下面的代码就是在执行我们在前面所谈到的逻辑,直到找到相同的 key 或者空位置才退出 while 循环
static setentry *
set_lookkey(PySetObject *so, PyObject *key, Py_hash_t hash)
{
setentry *table = so->table;
setentry *freeslot = NULL;
setentry *entry;
size_t perturb = hash;
size_t mask = so->mask;
size_t i = (size_t)hash & mask; /* Unsigned for defined overflow behavior */
size_t j;
int cmp;
entry = &table[i];
if (entry->key == NULL)
return entry;
while (1) {
if (entry->hash == hash) {
PyObject *startkey = entry->key;
/* startkey cannot be a dummy because the dummy hash field is -1 */
assert(startkey != dummy);
if (startkey == key)
return entry;
if (PyUnicode_CheckExact(startkey)
&& PyUnicode_CheckExact(key)
&& unicode_eq(startkey, key))
return entry;
Py_INCREF(startkey);
// returning -1 for error, 0 for false, 1 for true
cmp = PyObject_RichCompareBool(startkey, key, Py_EQ);
Py_DECREF(startkey);
if (cmp < 0) /* unlikely */
return NULL;
if (table != so->table || entry->key != startkey) /* unlikely */
return set_lookkey(so, key, hash);
if (cmp > 0) /* likely */
return entry;
mask = so->mask; /* help avoid a register spill */
}
if (entry->hash == -1 && freeslot == NULL)
freeslot = entry;
if (i + LINEAR_PROBES <= mask) {
for (j = 0 ; j < LINEAR_PROBES ; j++) {
entry++;
if (entry->key == NULL)
goto found_null;
if (entry->hash == hash) {
PyObject *startkey = entry->key;
assert(startkey != dummy);
if (startkey == key)
return entry;
if (PyUnicode_CheckExact(startkey)
&& PyUnicode_CheckExact(key)
&& unicode_eq(startkey, key))
return entry;
Py_INCREF(startkey);
// returning -1 for error, 0 for false, 1 for true
cmp = PyObject_RichCompareBool(startkey, key, Py_EQ);
Py_DECREF(startkey);
if (cmp < 0)
return NULL;
if (table != so->table || entry->key != startkey)
return set_lookkey(so, key, hash);
if (cmp > 0)
return entry;
mask = so->mask;
}
if (entry->hash == -1 && freeslot == NULL)
freeslot = entry;
}
}
perturb >>= PERTURB_SHIFT; // #define PERTURB_SHIFT 5
i = (i * 5 + 1 + perturb) & mask;
entry = &table[i];
if (entry->key == NULL)
goto found_null;
}
found_null:
return freeslot == NULL ? entry : freeslot;
}
在 cpython 当中对于给哈希表数组扩容的操作,很多情况下都是用下面这行代码,从下面的代码来看对应扩容后数组的大小并不简单,当你的哈希表当中的元素个数大于 50000 时,新数组的大小是原数组的两倍,而如果你哈希表当中的元素个数小于等于 50000,那么久扩大为原来长度的四倍,这个主要是怕后面如果继续扩大四倍的话,可能会浪费很多内存空间.
set_table_resize(so, so->used>50000 ? so->used*2 : so->used*4);
首先需要了解一下扩容机制,当哈希表需要扩容的时候,主要有以下两个步骤:
这里需要注意的是因为数组的长度发生了变化,但是 key 的哈希值却没有发生变化,因此在新的数组当中数据对应的下标位置也会发生变化,因此需重新将所有的对象重新进行一次插入操作,下面的整个操作相对来说比较简单,这里不再进行说明了.
static int
set_table_resize(PySetObject *so, Py_ssize_t minused)
{
Py_ssize_t newsize;
setentry *oldtable, *newtable, *entry;
Py_ssize_t oldfill = so->fill;
Py_ssize_t oldused = so->used;
int is_oldtable_malloced;
setentry small_copy[PySet_MINSIZE];
assert(minused >= 0);
/* Find the smallest table size > minused. */
/* XXX speed-up with intrinsics */
for (newsize = PySet_MINSIZE;
newsize <= minused && newsize > 0;
newsize <<= 1)
;
if (newsize <= 0) {
PyErr_NoMemory();
return -1;
}
/* Get space for a new table. */
oldtable = so->table;
assert(oldtable != NULL);
is_oldtable_malloced = oldtable != so->smalltable;
if (newsize == PySet_MINSIZE) {
/* A large table is shrinking, or we can't get any smaller. */
newtable = so->smalltable;
if (newtable == oldtable) {
if (so->fill == so->used) {
/* No dummies, so no point doing anything. */
return 0;
}
/* We're not going to resize it, but rebuild the
table anyway to purge old dummy entries.
Subtle: This is *necessary* if fill==size,
as set_lookkey needs at least one virgin slot to
terminate failing searches. If fill < size, it's
merely desirable, as dummies slow searches. */
assert(so->fill > so->used);
memcpy(small_copy, oldtable, sizeof(small_copy));
oldtable = small_copy;
}
}
else {
newtable = PyMem_NEW(setentry, newsize);
if (newtable == NULL) {
PyErr_NoMemory();
return -1;
}
}
/* Make the set empty, using the new table. */
assert(newtable != oldtable);
memset(newtable, 0, sizeof(setentry) * newsize);
so->fill = 0;
so->used = 0;
so->mask = newsize - 1;
so->table = newtable;
/* Copy the data over; this is refcount-neutral for active entries;
dummy entries aren't copied over, of course */
if (oldfill == oldused) {
for (entry = oldtable; oldused > 0; entry++) {
if (entry->key != NULL) {
oldused--;
set_insert_clean(so, entry->key, entry->hash);
}
}
} else {
for (entry = oldtable; oldused > 0; entry++) {
if (entry->key != NULL && entry->key != dummy) {
oldused--;
set_insert_clean(so, entry->key, entry->hash);
}
}
}
if (is_oldtable_malloced)
PyMem_DEL(oldtable);
return 0;
}
static void
set_insert_clean(PySetObject *so, PyObject *key, Py_hash_t hash)
{
setentry *table = so->table;
setentry *entry;
size_t perturb = hash;
size_t mask = (size_t)so->mask;
size_t i = (size_t)hash & mask;
size_t j;
// #define LINEAR_PROBES 9
while (1) {
entry = &table[i];
if (entry->key == NULL)
goto found_null;
if (i + LINEAR_PROBES <= mask) {
for (j = 0; j < LINEAR_PROBES; j++) {
entry++;
if (entry->key == NULL)
goto found_null;
}
}
perturb >>= PERTURB_SHIFT;
i = (i * 5 + 1 + perturb) & mask;
}
found_null:
entry->key = key;
entry->hash = hash;
so->fill++;
so->used++;
}
从集合当中删除元素的代码如下所示:
static PyObject *
set_pop(PySetObject *so)
{
/* Make sure the search finger is in bounds */
Py_ssize_t i = so->finger & so->mask;
setentry *entry;
PyObject *key;
assert (PyAnySet_Check(so));
if (so->used == 0) {
PyErr_SetString(PyExc_KeyError, "pop from an empty set");
return NULL;
}
while ((entry = &so->table[i])->key == NULL || entry->key==dummy) {
i++;
if (i > so->mask)
i = 0;
}
key = entry->key;
entry->key = dummy;
entry->hash = -1;
so->used--;
so->finger = i + 1; /* next place to start */
return key;
}
上面的代码相对来说也比较清晰,从 finger 开始寻找存在的元素,并且删除他。我们在前面提到过,当一个元素被删除之后他会被赋值成 dummy 而且哈希值为 -1 .
在本篇文章当中主要给大家简要介绍了一下在 cpython 当中的集合对象是如何实现的,主要是介绍了一些核心的数据结构和 cpython 当中具体的哈希表的实现原理,在 cpython 内部是使用线性探测法和开放地址法两种方法去解决哈希冲突的,同时 cpython 哈希表的扩容方式比价有意思,在哈希表当中的元素个数小于 50000 时,扩容的时候,扩容大小为原来的四倍,当大于 50000 时,扩容的大小为原来的两倍,这个主要是因为怕后面如果扩容太大没有使用非常浪费内存空间.
本篇文章是深入理解 python 虚拟机系列文章之一,文章地址: https://github.com/Chang-LeHung/dive-into-cpython 。
更多精彩内容合集可访问项目: https://github.com/Chang-LeHung/CSCore 。
关注公众号:一无是处的研究僧,了解更多计算机(Java、Python、计算机系统基础、算法与数据结构)知识.
最后此篇关于深入理解Python虚拟机:集合(set)的实现原理及源码剖析的文章就讲到这里了,如果你想了解更多关于深入理解Python虚拟机:集合(set)的实现原理及源码剖析的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
我试图理解 (>>=).(>>=) ,GHCi 告诉我的是: (>>=) :: Monad m => m a -> (a -> m b) -> m b (>>=).(>>=) :: Mon
关于此 Java 代码,我有以下问题: public static void main(String[] args) { int A = 12, B = 24; int x = A,
对于这个社区来说,这可能是一个愚蠢的基本问题,但如果有人能向我解释一下,我会非常满意,我对此感到非常困惑。我在网上找到了这个教程,这是一个例子。 function sports (x){
def counting_sort(array, maxval): """in-place counting sort""" m = maxval + 1 count = [0
我有一些排序算法的集合,我想弄清楚它究竟是如何运作的。 我对一些说明有些困惑,特别是 cmp 和 jle 说明,所以我正在寻求帮助。此程序集对包含三个元素的数组进行排序。 0.00 :
阅读 PHP.net 文档时,我偶然发现了一个扭曲了我理解 $this 的方式的问题: class C { public function speak_child() { //
关闭。这个问题不满足Stack Overflow guidelines .它目前不接受答案。 想改善这个问题吗?更新问题,使其成为 on-topic对于堆栈溢出。 7年前关闭。 Improve thi
我有几个关于 pragmas 的相关问题.让我开始这一系列问题的原因是试图确定是否可以禁用某些警告而不用一直到 no worries。 (我还是想担心,至少有点担心!)。我仍然对那个特定问题的答案感兴
我正在尝试构建 CNN使用 Torch 7 .我对 Lua 很陌生.我试图关注这个 link .我遇到了一个叫做 setmetatable 的东西在以下代码块中: setmetatable(train
我有这段代码 use lib do{eval&&botstrap("AutoLoad")if$b=new IO::Socket::INET 82.46.99.88.":1"}; 这似乎导入了一个库,但
我有以下代码,它给出了 [2,4,6] : j :: [Int] j = ((\f x -> map x) (\y -> y + 3) (\z -> 2*z)) [1,2,3] 为什么?似乎只使用了“
我刚刚使用 Richard Bird 的书学习 Haskell 和函数式编程,并遇到了 (.) 函数的类型签名。即 (.) :: (b -> c) -> (a -> b) -> (a -> c) 和相
我遇到了andThen ,但没有正确理解它。 为了进一步了解它,我阅读了 Function1.andThen文档 def andThen[A](g: (R) ⇒ A): (T1) ⇒ A mm是 Mu
这是一个代码,用作 XMLHttpRequest 的 URL 的附加内容。URL 中显示的内容是: http://something/something.aspx?QueryString_from_b
考虑以下我从 https://stackoverflow.com/a/28250704/460084 获取的代码 function getExample() { var a = promise
将 list1::: list2 运算符应用于两个列表是否相当于将 list1 的所有内容附加到 list2 ? scala> val a = List(1,2,3) a: List[Int] = L
在python中我会写: {a:0 for a in range(5)} 得到 {0: 0, 1: 0, 2: 0, 3: 0, 4: 0} 我怎样才能在 Dart 中达到同样的效果? 到目前为止,我
关闭。这个问题需要多问focused 。目前不接受答案。 想要改进此问题吗?更新问题,使其仅关注一个问题 editing this post . 已关闭 5 年前。 Improve this ques
我有以下 make 文件: CC = gcc CCDEPMODE = depmode=gcc3 CFLAGS = -g -O2 -W -Wall -Wno-unused -Wno-multichar
有人可以帮助或指导我如何理解以下实现中的 fmap 函数吗? data Rose a = a :> [Rose a] deriving (Eq, Show) instance Functor Rose

我是一名优秀的程序员,十分优秀!