
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4


更多技术交流、求职机会,欢迎关注 字节跳动数据平台微信公众号,回复【1】进入官方交流群 。
导读:经过十多年的发展,数据治理在传统行业以及新兴互联网公司都已经产生落地实践。字节跳动也在探索一种分布式的数据治理方式。本篇内容来源于火山引擎超话数据直播活动的回顾,将从以下四个部分展开分享:
字节的挑战与实践 。
数据治理的发展与分布式 。
分布式自治架构 。
分布式自治核心能力 。
首先来看一个问题:“一家公司,数据体系要怎么搭建?” 。
方案一: 整体规划,系统架构驱动 。
方案二: 问题出发,业务价值驱动 。
在字节跳动,我们选择的是方案二,即从业务遇到的问题出发,重视落地结果与业务过程,去解决实际的治理问题.
基于这个理念,在数据治理过程中,字节跳动也面临以下三个挑战与机遇:
业务特点:业务发展快、场景丰富、数据量大且形态各异。业务的线上服务及创新,都对数据有较强的依赖,核心业务数据延迟,质量问题将直接影响业务表现及发展.
组织特点:扁平化的组织模式,分布式的组织管理。无行政手段或强组织约束,也无全局治理委员会,且数据从采集到应用全部的生产流程,没有全局规范,业务团队需要自主制定策略并落地.
文化特点:OKR 拆解与对齐文化 ,业务团队有充足的目标定义与拆解权限,且任何人都可能有动机、有角色、甚至有权限去进行数据治理,导致数据治理的业务流程复杂 。
字节数据治理演进阶段分为 6 个阶段:
业务第一原则:坚持业务第一原则,解决业务实际遇到的治理痛点 。
优先稳定建设:优先解决交付稳定,保障数据链路与产出稳定,减少交付延迟 。
保障数据质量:核心链路质量管控,配置强质量规则,自动熔断,避免全链路数据污染;加强事前检查,从源头加强质量控制;完善事后评估,为每一张表建立健康档案,持续改进.
关注数据安全:冗余权限识别,消除授权风险;数据分类分级,风险定义与多策略控制,减少安全风险 。
重视成本优化:基于多种规则的与完备的治理元数仓,提供低门槛的治理产品能力,快速优化存储 。
提高员工幸福感:在帮助业务完成数据治理的后,还需要考虑团队的负载压力,报警治理,降低员工起夜率;归因分析,快速排查修复故障.
在这里,再介绍字节特色的“0987”量化数据服务标准。这四个数字分别指的是:稳定性 SLA 核心指标要达到 0 个事故,需求满足率要达到 90%,数仓构建覆盖 80% 的分析需求,同时用户满意度达到 70%。按照这个高标准来要求自己,同时这也是一种自监管的机制,能够有效的防止自嗨,脱离业务需求和价值.
下面通过两个例子为大家介绍数据治理在字节的场景实践.
案例一:
问题:字节跳动内部 2019 年到 2020 年间,双月内事故数量较多,对业务造成一定影响,且收敛困难,每天都有告警、起夜、对正常开发进度造成影响.
解决方案: 采用了分布式用户自治的 SLA 治理,通过数据分级保障目标管理,在各业务内部进行【拉齐链路-数据分级-广泛共识-系统管理】的行动闭环,系统化保障目标传递和落地.
效果: 截止 2020 年中,事故以每双月 30%环比下降,在 1 年内达到稳定性问题彻底收敛.
案例二:
问题:抖音的实时数仓治理人员的精力分散,以被动的运动式、“救火”式的工作模式为主。协同效率低,人力投入巨大,缺少可持续性.
解决方案: 覆盖质量、成本、SLA、安全等治理方向,以业务评估体系,构建治理方案进行例行诊断,对存量问题进行识别和派发,形成一套【评估->识别->规划->执行->复盘】业务内部分布式自治的治理机制.
效果: 从 21 年至今,治理人员的精力彻底从”运动式“治理的模式中解放出来,更多精力会集中在监督执行与规则优化中,团队起夜率降低 30%。质量保障覆盖率达到 100%。双月存储优化均在 20+PB.
众所周知,有很多机构都分享了对数据治理的定义,这里简单分享一下 。
国际数据管理协会(DAMA): 数据治理是对数据资产管理行使权力和控制的活动集合 。
IBM:数据治理是对企业中的数据可用性、相关性、 完整性和安全性的全面管理。它帮助组织管理 他们的信息知识和作为决策依据 。
维基百科对数据治理的定义:数据治理是一个涉及全体组织的数据管理概念,通过数据治理,确保在数据的整个生命周期中拥有高数据质量的能力,也是对业务目标的支持。数据治理的关键的重点领域包括可用性、一致性、数据完整性和数据安全性,也包括建立流程来确保整个企业实施有效数据管理.
在传统的数据治理方法论与定义中,注意到他有以下共性特点,同时也是现在大多数公司的实践路径,即:

但是在实际的执行过程中,他需要以下几个前提和随之带来的落地难点 。
。
1.需要明确组织制度 。
梳理业务数据部门,设立公司级别数据治理委员会/部门,各业务分设执行部门,公司内各业务宣导讨论,统一制定公司数据治理规章制度 。
难点一:组织依赖重、建设周期长。需要招聘大量专业的治理专家或引入外部咨询机构,计划制定周期长;专设部门牵头,若无自顶向下的项目背景,业务协调对齐困难.
2. 需要明确权责管理 。
梳理公司数据资产,迁移、拆分、业务改造。确保资产归属与治理权责明确,定期梳理资产类目,维护资产元数据的有效性,确保治理边界清晰 。
难点二:业务影响大,目标对齐难。需完成存量的资产归属划分、改造生产开发体系,对增量定期人力打标,确保资产归属与权责边界清晰,因可能业务系统改造,会对业务发展造成影响 。
3.需要进行复盘抽查 。
管理组织定期检查各业务治理过程是否符合公司治理制度,定期检查各项治理结果是否落地,线下复盘与推动不符合预期的治理过程 。
难点三:沟通成本高,执行推动难。如何制定适用于不同业务特点与发展阶段的团队的治理评估体系,各团队是否认可评估标准.
。
为了解决以上三个问题,我们有些新的思考,即引入「分布式」的理念.
。
Governance 一词在根源上同 Government,1990 年代被经济学家和政治科学家重新创造,由联合国、世界货币组织和世界银行等机构进行传播。其核心有以下两种论述:
第一个论述:标准与规范。指的是一定范围内的一致的管理,统一的政策,某一责任区指导以及合适的监管和可问责机制。这种行政力的集中化管理存在一些问题,比如决策成本高,人力投入高、落地阻力大,精力消耗大.
第二个论述:过程与结果。指的是只要关注结果和产出以及业务内部实践,通过分布式协作让业务的治理结果、业务痛点和治理方式及手段在内部闭环,而不是由中台层面统一推动.
我们尝试从第二种论述,即重视过程落地和治理结果产出的出发,更快的落地产品,落地数据治理的产品解决方案 。
基于分布式的数据自治的理念,我们来解决在落地执行上的两个最困难的点 。
1、组织制度分布式:尝试将组织的强管理属性转换到监督属性,治理单元与制度设计回归到业务单元。好处是,不强依赖横向中心化组织,业务治理痛点闭环在业务单元,且业务基于自身发展阶段制定治理目标,ROI 论证回归业务.
2、权责验收分布式:基于产品体系与落地解决方案,支持业务按需自驱,市场化执行,平台辅助与按需验收。好处是,无须长周期的资产类目梳理,业务系统改造,权责均由业务区分,基于业务单元与多维视角,按需验收治理结果,业务单元内对齐.
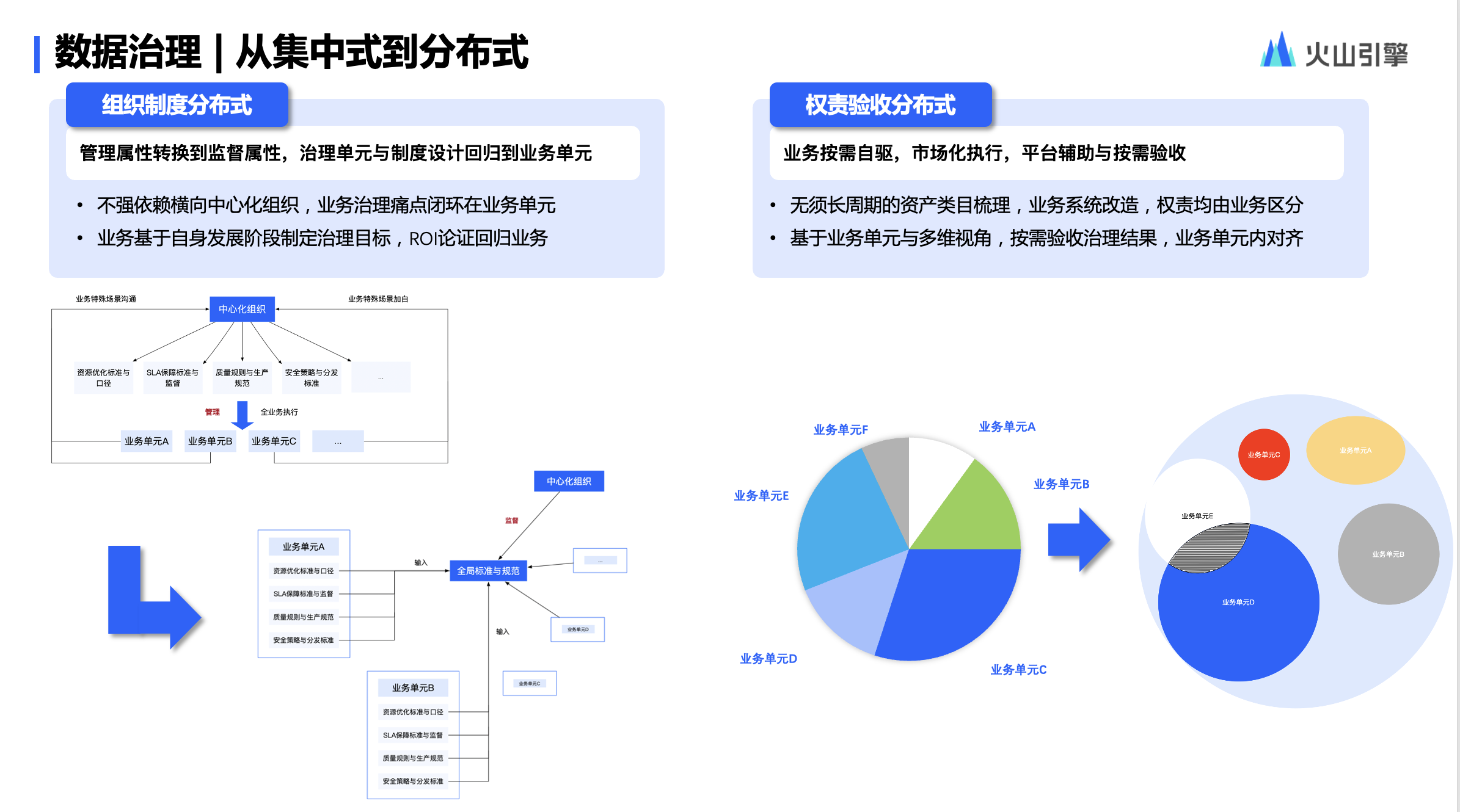
如上图展示的饼图,对于一个公司的数据资产,传统来说,可以很清晰地按照业务边界来划分清楚。对于分布式数据治理,我们通常是由业务单元自行认领,业务单元 A 自行认领属于自己部分,业务单 B 也自行认领属于自己部分。认领就意味着,所有治理的动作包括结果,安全性、成本、质量、稳定都由认领业务单元负责.
当然,这样这样也可能存在两个问题,不过在分布式的理念中能够得到较好解决 。
第一是认领范围重合:这种情况往往让业务在线下对齐是否需要去做改造和划分,各自拿到自身需要的治理结果,短期无须重人力投入,不追求绝对的边界划分。长期因不同治理验收需求或团队管理需求,自行进行资产归集和整理。达到动态的平衡状态 。
第二是无人认领:针对长期无人认领的资产,我们可以基于每个业务的历史的规则和能力,形成一个治理的平均线,再从平台层面推动无人认领的资产治理,由于无人认领,这样的资产推动起来相对较快.
定义:以业务单元为数据治理闭环单元,通过完善的产品工具,将管理视角转化为监督视角,解决数据治理落地痛点;各业务团队分布式自运行,整体上达到全局最优,从形态上,适配更多业务特性和发展阶段,从效果上,强推进重落实与结果 。
字节跳动通常以业务单元作为一个数据治理闭环,即在业务单元内部完成数据稳定性、质量、存储、计算等治理。同时每个业务单元不是孤立的,也有相互协作,比如 A 业务单元的数据治理经验可以沉淀为治理模板,供后续其他业务使用.
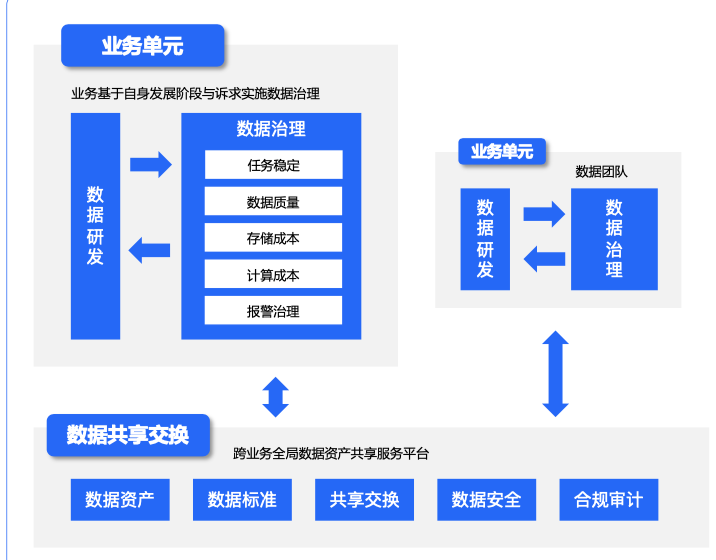
这样的分布式治理方式,有以下一些优势:
影响小,依赖小。治理下放到各个业务中,各级业务乃至个人都能自驱治理,业务根据自身发展阶段灵活组合治理工具,无须对组织强依赖.
周期短,见效快。业务自驱梳理核心数据及链路,跨团队对齐线上化、协议签署、过程追踪。治理周期显著缩短,很快就出成效,增强团队信心.
效率高,省人力。SLA 治理提高跨团队协作效率,聚焦核心数据任务集中资源保障,集中精力,报警归因减少起夜,帮助企业节省年度人力消耗 。
算清帐,降成本。各业务口径的存储计算资源消耗、核算成本,制定降本目标并追踪落地;业务经验规则化、策略化、自动化、自驱化持续降本增效.
为达成业务分布式自治,产品需要对用户行为路径完全覆盖,对业务经验完全接受。平台提供完善的开放能力,协助业务进一步提效 。
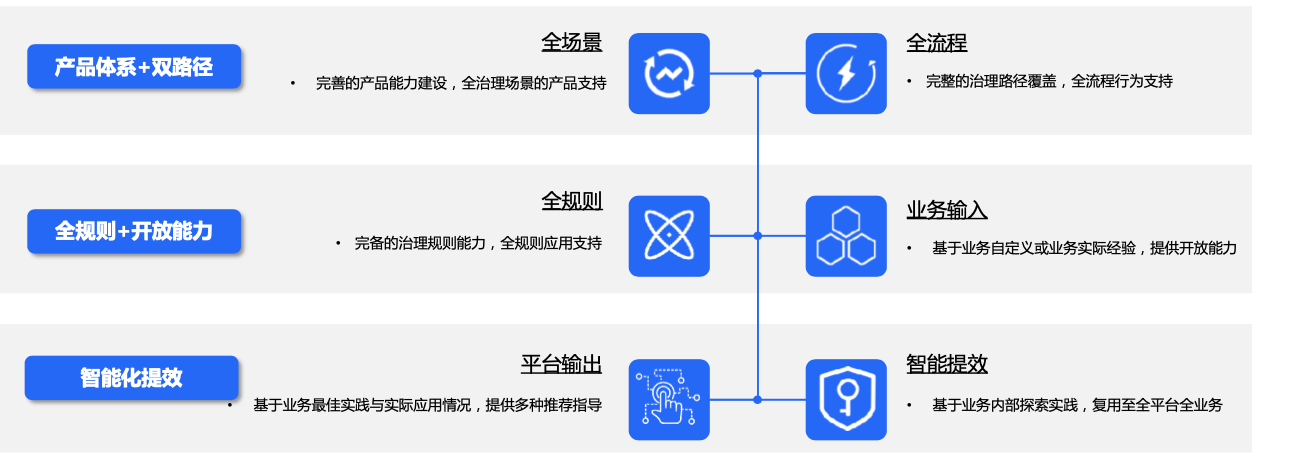
以上关于分布式的理解,下面将介绍字节分布式自治的产品体系.
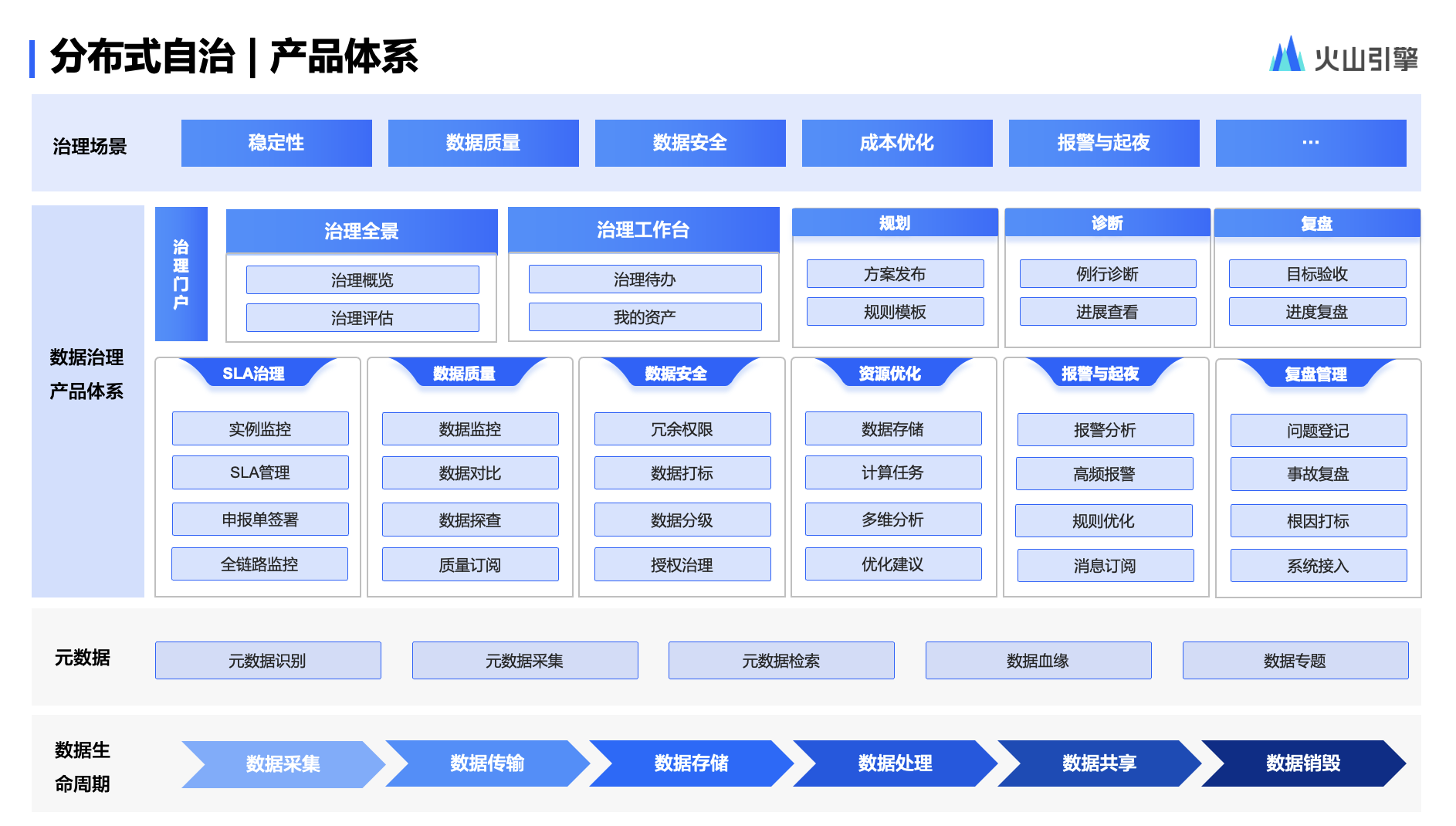
从治理门户来看,包括治理全景、工作台、规划、诊断、复盘等全流程治理环节。在治理场景中,提供数据质量安全、资源优化、报警、企业复盘管理等一系列垂直场景。在底层,包含数据全生命周期流程,从数据采集、数据传输、数据存储、数据处理、数据共享到数据销毁.
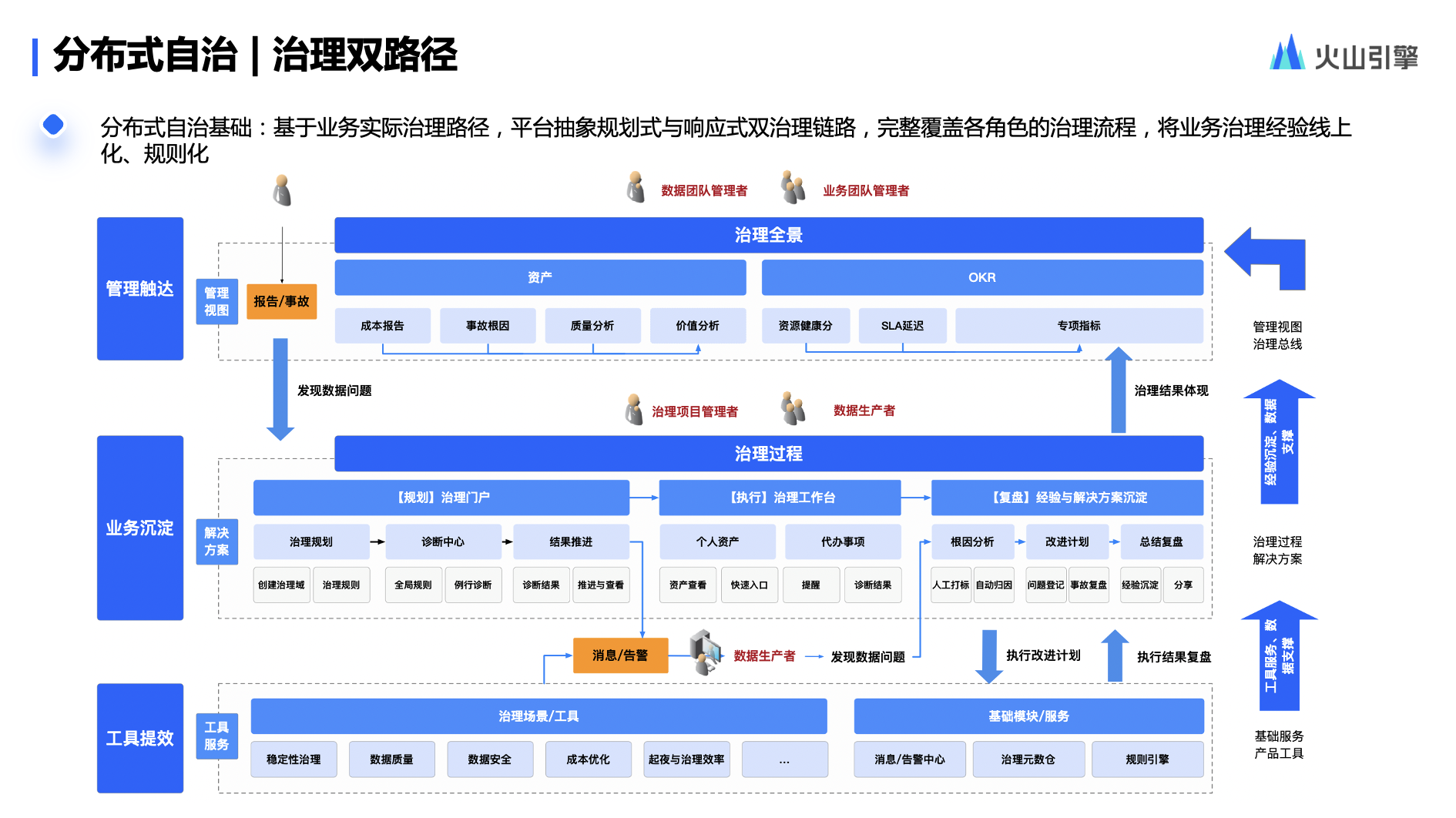
为了把用户所有治理经验沉淀为平台能力,我们抽象了 2 种治理路径.
第一种是规划式路径。这是一个比较常见的规划式路径,即从看板和报表出发,自上而下做规划。比如看板已经反映出成本增加、延时变长或者数据质量变差,团队管理者发起报告或事故,推动业务单元同事进行数据治理,最后进行复盘.
第二种是响应式。比如生产者收到一个数据质量或延时的报警,随后快速定位原因并做改进计划.
为了更好把业务经验全部线上化,我们通常双路径并行使用.
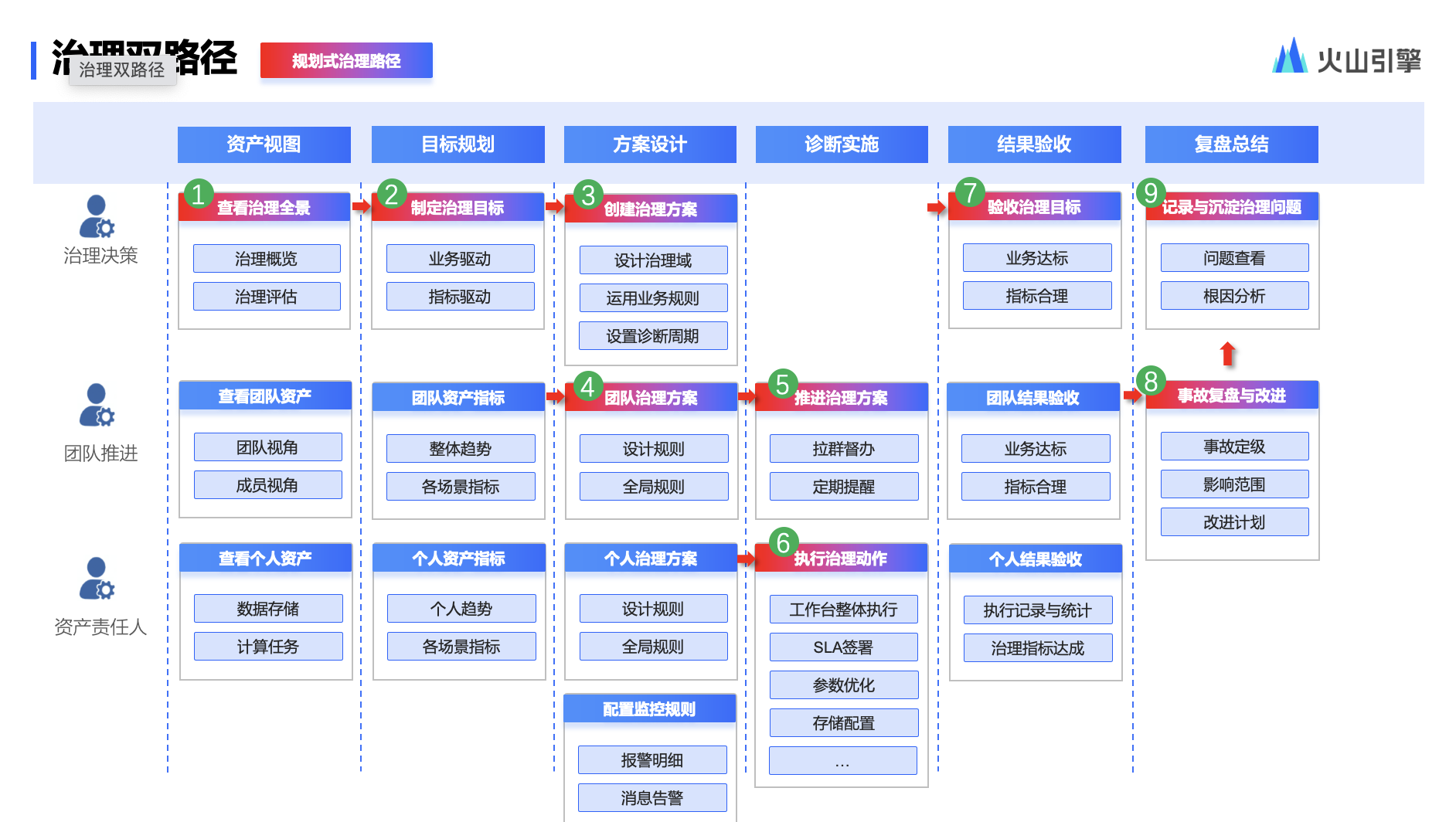
首先看通用模块资产视图,包括资产增量情况评估等,以及业务对于资产的评价,如健康分体系。我们通常根据资产情况去制定目标。如果发现问题之后,业务驱动制定目标,可能是降低存储。同时需要去应用一些业务规则,比如团队内部认为 TTL(数据生命周期)很重要,需要帮助识别出来的同时也需要设定一个诊断周期。在团队方案确认完之后,产品会做监督,包括定义提醒,同时也推动资产 owner 完成总结.
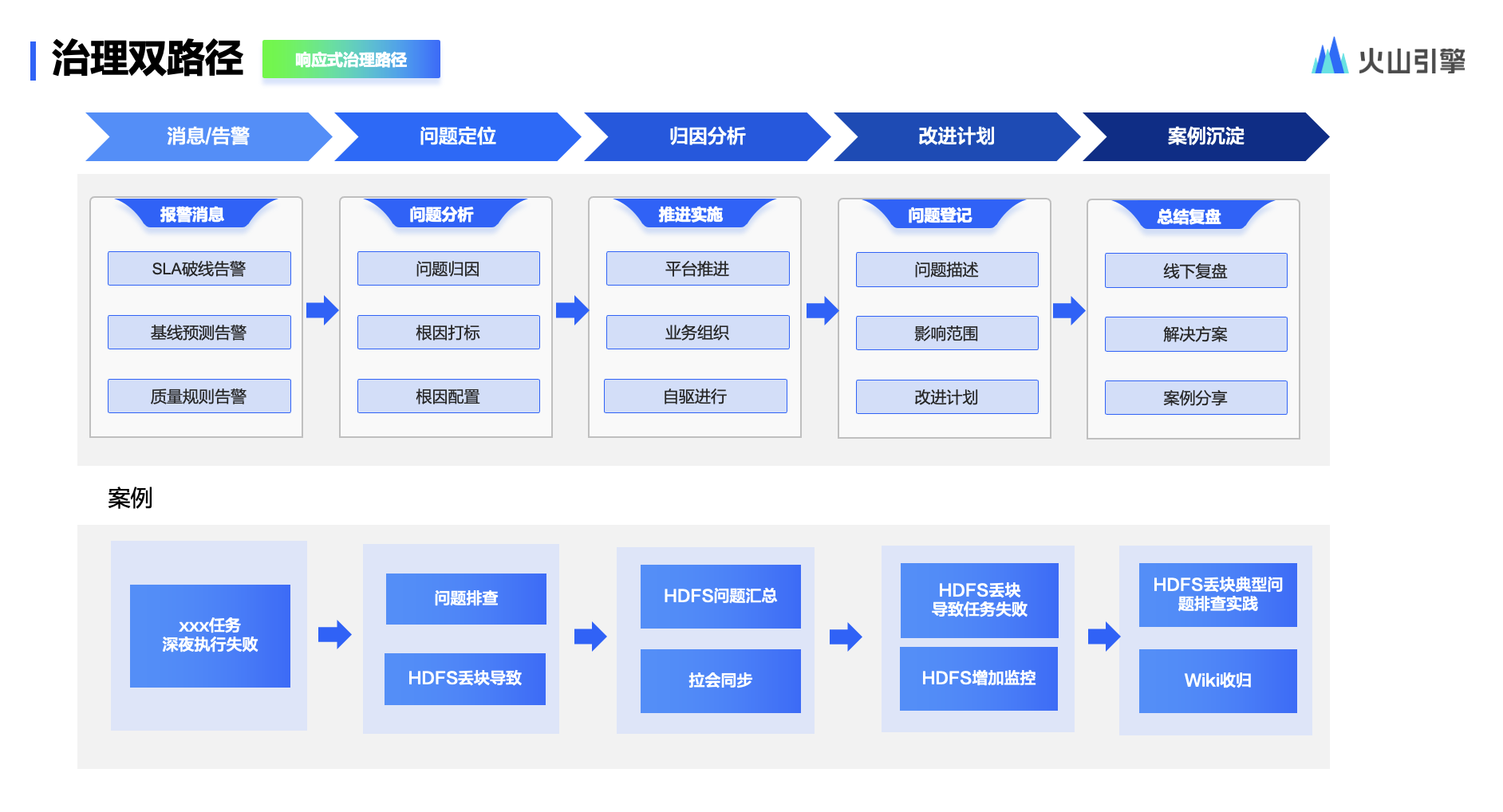
例如,我们发现一些任务在深夜执行失败了,需要先做问题排查,发现问题是 HDFS 丢块导致。在传统情况下,解决方案是去检查 API 问题,再去拉相关人员,可能 2- 3 小时才能完成,最后配合监控并收归到 wiki 中。而在 DataLeap 数据治理产品里,可以直接实现归因打标等能力,最后快速复盘.

如果要覆盖业务的全部属性,治理平台需要形成有效且全面的规则模板。目前,我们的规则模板包含两个部分:
第一是规则引擎,具体包括业务输入、平台输入、推荐输入.
业务输入:主要依据业务团队的治理经验以及行业经验.
平台输入:平台会提供一些基础能力,如存储、计算、质量、报警等几个维度。截止目前已经提供了 80 多个规则.
推荐输入:基于业务输入和平台输入,去做分析和挖掘,发现哪些规则用得多、哪些规则阈值更合理.
第二是治理数仓,具体包括行为数据、治理操作、效果数据.
行为数据:包括用户规则配置等内容是否有重复以及带元素标签的资产数据等.
治理操作:包括生命周期、任务关闭、数据删除、SLA 签署等.
效果数据:包括操作收益、资产收益、指标收益等.
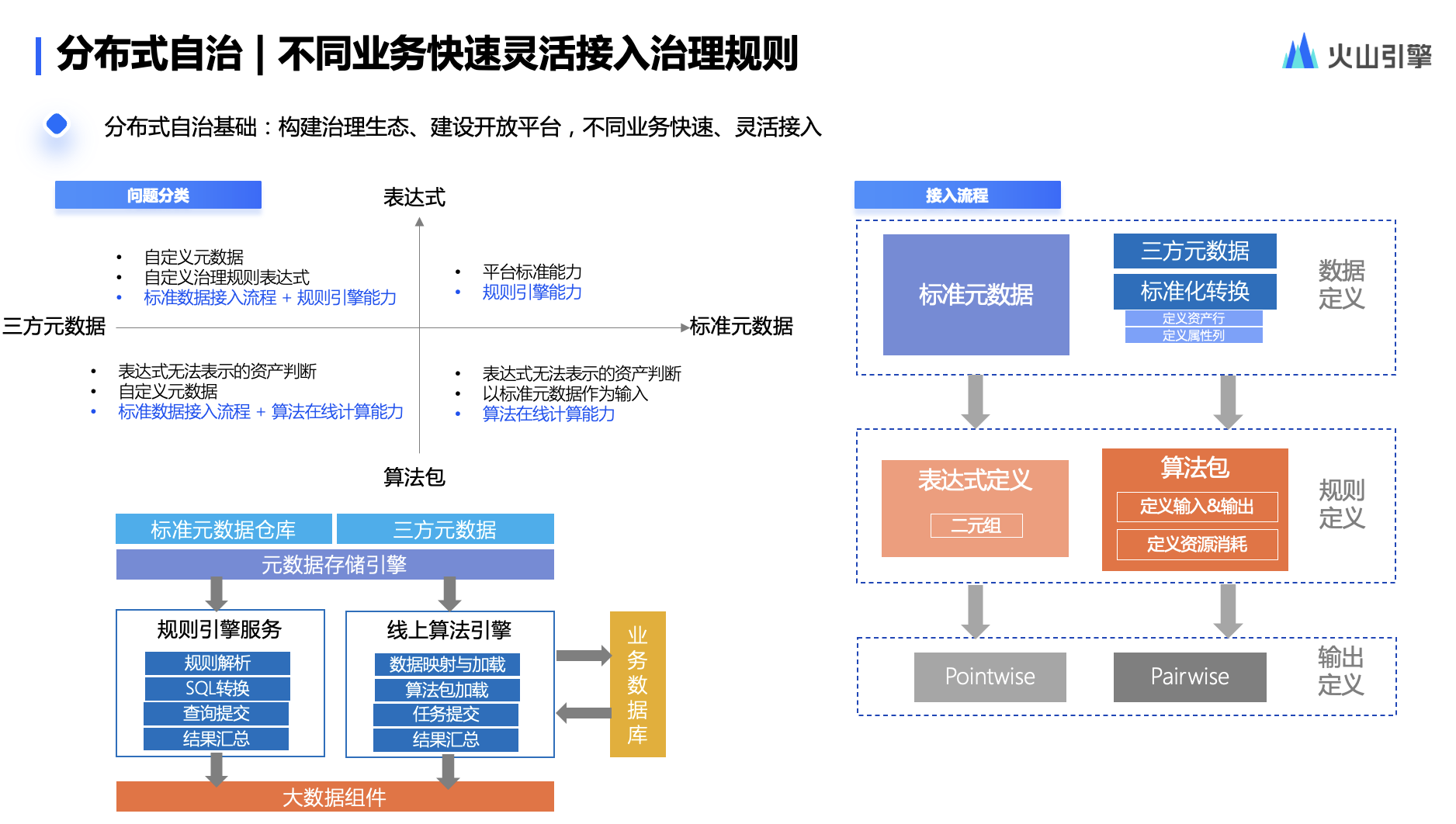
分布式自治基础是要构建治理生态、建设开放平台,让不同业务能够快速、灵活接入.
为了让业务能快速介入,我们把数据分成了四种类型:表达式、三方元数据、标准元数据、算法包。针对不同的业务,根据当前的经验和能力,我们会提供不同的接入方式,让业务去更好把规则和能力去接入到我们的平台.
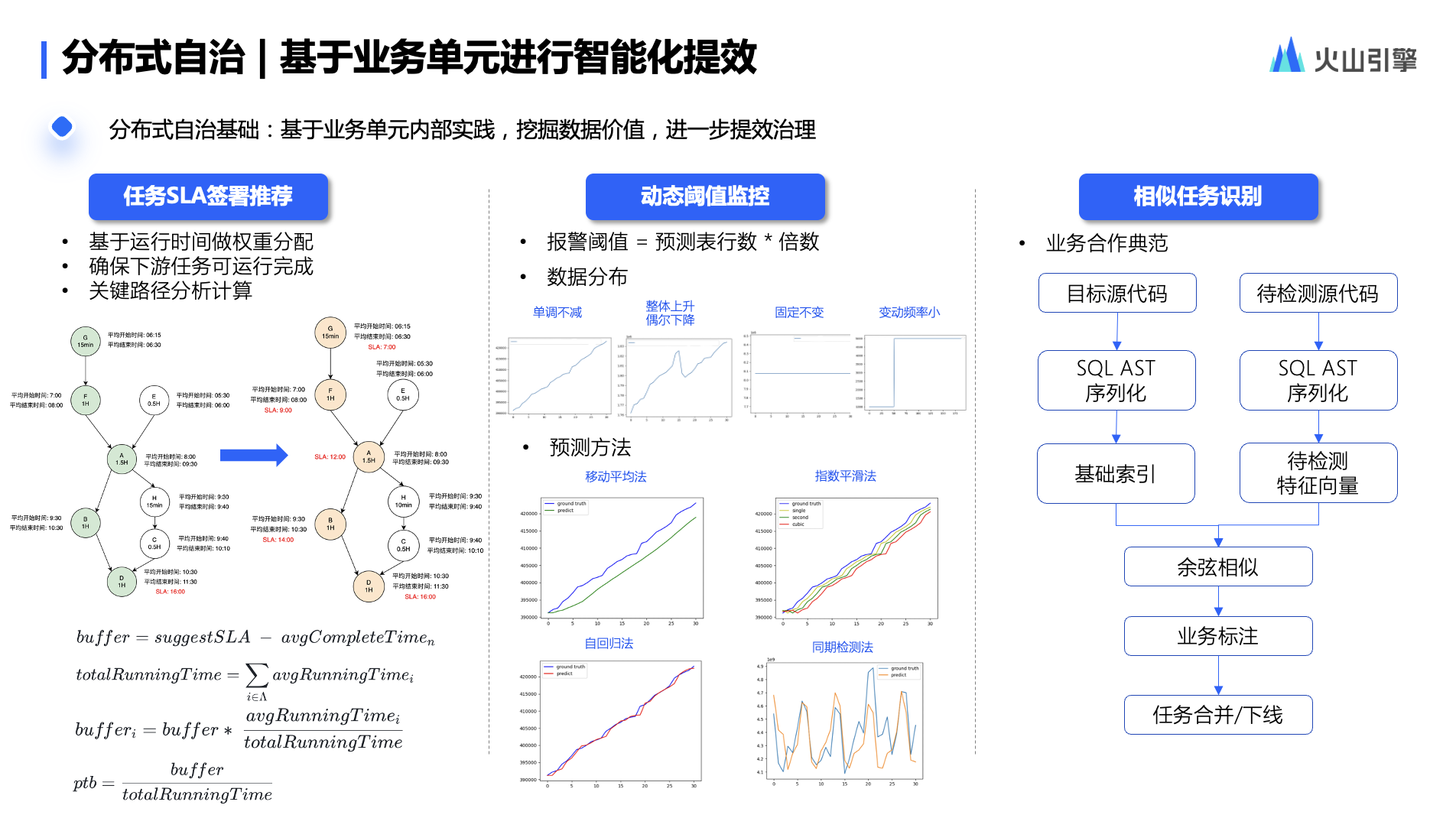
在获取不同业务的规则和能力之后,我们需要再做平台能力沉淀,把好的规则和能力复用给更多业务.
Case1:任务 SLA 签署推荐。基于运营时间做权重分配,保证下游任务运行完成,同时也会进行关键链路分析。这个规则目前在字节内部广泛使用.
Case2:动态阈值监控。这是基于业务在报警阈值上的实践提取的规则.
Case3:相似任务识别。通过序列化和向量化操作,去和底层 spark 引擎做配合。在业务内部应用覆盖 99%,且优化任务都千级以上,由此接入平台并推荐给其他业务.

在分布式验收中,会区分为全员视角、团队视角和个人视角。全员视角可以看到公司级资产,包括整体的健康分体系以及核心指标。团队视角中,主要由业务自己梳理,包括内部的评价体系.

上图为个人工作台功能,主要为了把 SLA 保障、计算任务、数据存储等治理场景展示在一个页面,方便 owner 业务全局查看治理待办事项.
第一,支持自定义治理域,灵活自治,提供多种维度,自定义组合和圈选资产范围.
第二,支持创建治理方案,例行诊断:发起人基于业务需求,选择治理域,设计治理规则,发起存储/计算/质量等类型治理方案。例行诊断与推进实施.
第三,支持规则管理,提供 80+治理基础规则,支持自定义组合和配置规则与分享.
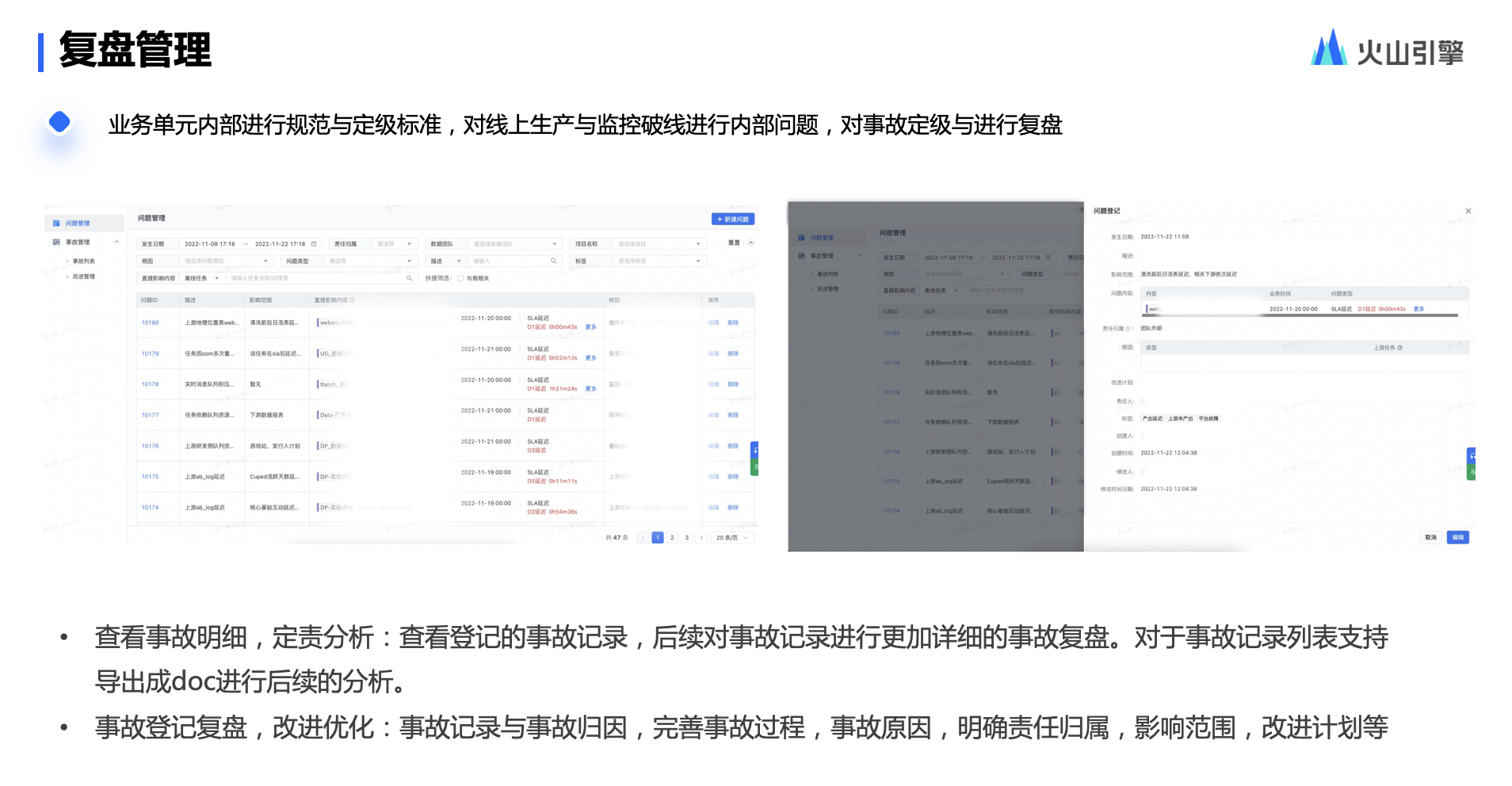
复盘管理是一个通用模块。业务根据自身需要去识别任务是否需要复盘,或者仅仅做问题登记。除此之外,业务还可以用复盘管理能力做内部管理,比如查看、检索所有的事故复盘,查看每个事故发生的原因和改进计划。同时,也可了解归因分布情况,并帮助下一个值班同学快速反馈和定位问题.
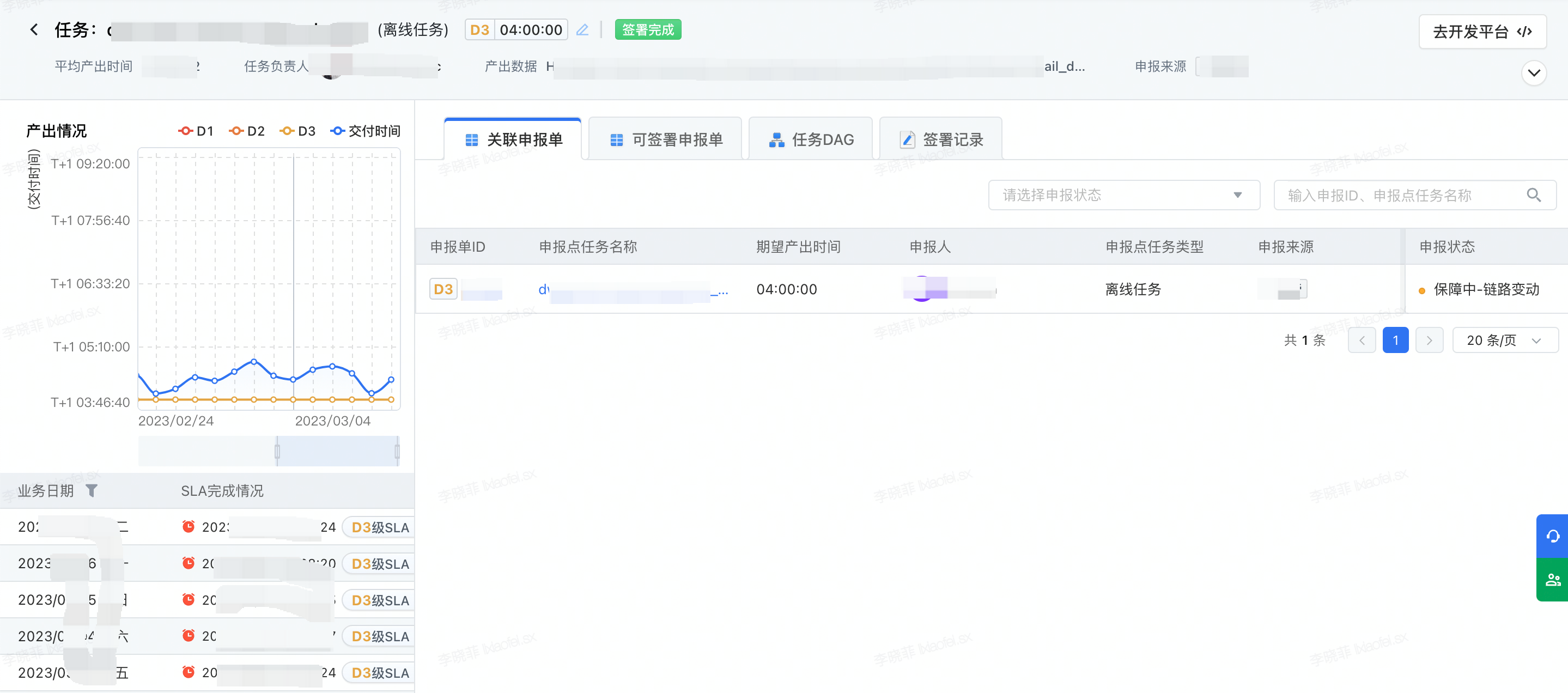
在字节跳动内部,SLA 不是平台级保障,而是源于业务团队内部。首先是业务按需申报,可能是 PM、运营或数据研发等任何角色,认为自身任务重要,填写背景、原因、等级、时间等信息之后,即可发起一个 SLA。发起之后,在团队内部进行审核,可能存在同一个团队多个高优任务的情况,这由团队内部自行调整优先级。同时,这个也是跨团队判断该任务重要性的标准.
之后是完成签署,签署也会在产品里面体现出来。每个节点时间都有实时监控,如果产生了延迟,会推动业务做复盘和登记。我们也提供基础的 DAG,包括申报业务单的查看,同时也可以让大家去查看每个等级的破线情况,以及团队对业务的服务情况.
在数据安全层面,主要专注于清理冗余权限,完善分类分级。不同团队对冗余权限定义不同,有的 90 天无访问算冗余权限,有的 70 天,有的 7 天。因此我们提供自定义能力,由业务内部发起 review,完成冗余权限的识别和定义规则,识别之后复用诊断能力.
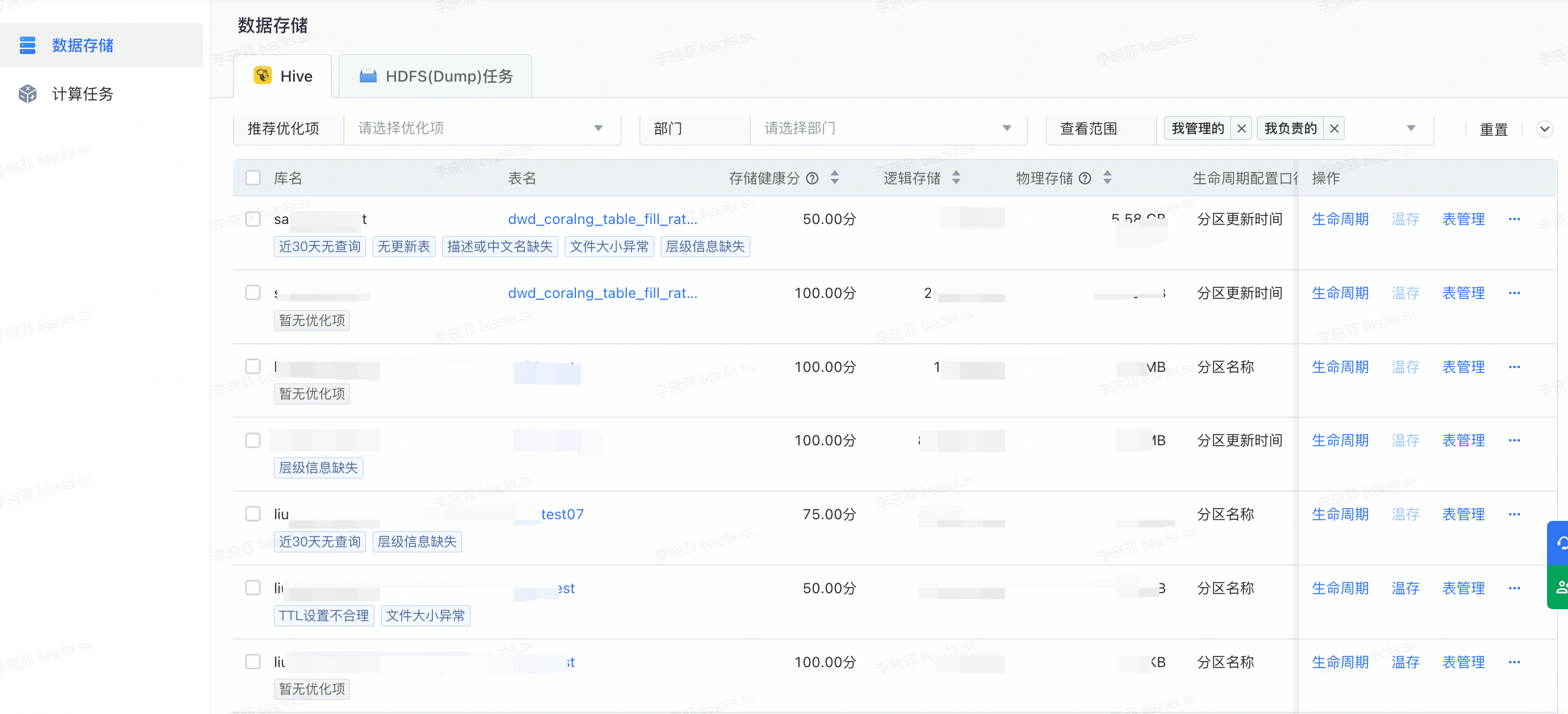
基于每个团队实际执行情况,提炼出一些通用的规则。例如,某些规则可能有几十个业务在使用,近 90% 认为近 30 天无查询需要被识别出来,我们就会在平台中提供这类能力,方便新业务或者小白业务去使用.
在报警归因方面,我们能提供所有报警明细,方便查看是否有重复规则,是否有高频报警规则,帮助用户发现无效报警和重复规则,降低告警量和跟起夜率。除此之外,我们也提供业务内部的归因登记和分析能力.
以上是字节跳动在数据治理相关实践.
。
目前,字节跳动也将沉淀的数据治理经验,通过火山引擎大数据研发治理套件 DataLeap 对外提供服务。作为一站式数据中台套件,DataLeap 汇集了字节内部多年积累的数据集成、开发、运维、治理、资产、安全等全套数据中台建设的经验,助力 ToB 市场客户提升数据研发治理效率、降低管理成本.
。
点击跳转 大数据研发治理套件 DataLeap 了解更多 。
最后此篇关于火山引擎DataLeap:一家企业,数据体系要怎么搭建?的文章就讲到这里了,如果你想了解更多关于火山引擎DataLeap:一家企业,数据体系要怎么搭建?的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
为了构建 CentOS 6.5 OSM 切片服务器,我正在寻找一些文档和/或教程。 我试过this one正如我在我的 previous post 中所说的那样但它适用于 Ubuntu 14.04,而
我正在寻找可用于集成任何源代码控制管理系统的通用 git 桥(如 git-svn、git-p4、git-tfs)模板。 如果没有这样的模板,至少有一些关于如何在 git 端集成基本操作的说明(对于其他
1、前言 redis在我们企业级开发中是很常见的,但是单个redis不能保证我们的稳定使用,所以我们要建立一个集群。 redis有两种高可用的方案: High availabilit
简介 前提条件: 确保本机已经安装 VS Code。 确保本机已安装 SSH client, 并且确保远程主机已安装 SSH server。 VSCode 已经安装了插件 C/
为什么要用ELK ELK实际上是三个工具,Elastricsearch + Logstash + Kibana,通过ELK,用来收集日志还有进行日志分析,最后通过可视化UI进行展示。一开始业务量比
在日常办公当中,经常会需要一个共享文件夹来存放一些大家共享的资料,为了保证文件数据的安全,最佳的方式是公司内部服务器搭建FTP服务器,然后分配多个用户给相应的人员。今天给大家分享FileZilla搭
最近由于业务需要,开始进行 Flutter 的研究,由于 Flutter 的环境搭建在官网上有些细节不是很清楚,笔者重新整理输出 1. 配置镜像 由于在国内访问 Flutter
目录 1. 安装go软件包 2. 配置系统变量 3. 安装git 4. 设置go代理 5. 下载gin框架 6. 创建项目 7.
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任
上篇文章给大家介绍了使用docker compose安装FastDfs文件服务器的实例详解 今天给大家介绍如何使用 docker compose 搭建 fastDFS文件服务器,内容详情如下所示:
目录 1.创建Maven 2.Maven目录和porm.xml配置 3.配置Tomcat服务器 1.创建Maven
laravel 官方提供 homestead 和 valet 作为本地开发环境,homestead 是一个官方预封装的 vagrant box,也就是一个虚拟机,但是跟 docker 比,它占用体积
这个tutorial显示了 Razor Pages 在 Asp.Net Core 2 中的实现。但是,当我运行 CLI 命令时: dotnet aspnet-codegenerator razorp
我创建了一个单独的类库项目来存储数据库上下文和模型类。在同一解决方案中,我创建了一个 ASP.NET MVC 项目并引用了类库项目,并在项目的 Web.config 文件中包含了数据库上下文的连接字符
关于代码托管,公司是基于Gitlab自建的,它功能全而强大,但是也比较重,我个人偏向于开源、小巧、轻便、实用,所以就排除了Github,在Gogs和Gitea中选者。Gogs在Github有38
目录 1、高可用简介 1.1 高可用整体架构 1.2 基于 QJM 的共享存储系统的数据同步机制分析 1.3 NameNode 主
Nginx 是由 Igor Sysoev 为俄罗斯访问量第二的 Rambler.ru 站点开发的,它已经在该站点运行超过两年半了。Igor 将源代码以类BSD许可证的形式发布。 在高并发连接的情况
对于我们的 ASP.NET Core 项目,我们使用包管理器控制台中的 Scaffold-DbContext 搭建现有数据库。 每次我们做脚手架时,上下文类与所有实体一起生成,它包含调用 option
我正在使用 .net 核心 2.0。我已经安装了以下 nuget 包:1: Microsoft.AspNetCore.All2: Microsoft.EntityFrameworkCore.Tools
我正在使用 NetBeans 及其 RAD 开发功能开发 JEE6 JSF 应用程序。我想使用脚手架来节省更新 Controller 和模型 View 的时间。 OneToMany 关联在 View

我是一名优秀的程序员,十分优秀!