
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4


本文系原创,转载请说明出处 。
。
Please Subscribe Wechat Official Account:信安科研人,获取更多的原创安全资讯 。
源码: https://github.com/momalab/ICSREF 。
原论文: ICSREF: A Framework for Automated Reverse Engineering of Industrial Control Systems Binaries - NDSS Symposium 。
到2019年为止,没人研究PLC控制应用程序二进制文件的逆向工程问题.
为什么要逆向工程这个PLC的控制应用程序二进制文件?有以下几个意义:
1)在发生攻击事件后能够迅速调查取证 。
就是说网络攻击调查团队可以通过逆向分析恶意控制应用程序的二进制文件来看看 这个恶意文件到底干的啥事情 .
2)可以实现恶意的ICS 攻击代码的动态生成 。
这个点就是说,我可以利用二进制文件中特定字段对应特定功能的特性,自动化的构建恶意代码,不需要通过C&C这种信息安全领域的通信与控制方法去与我的恶意代码通信并执行命令.
为什么尽量避免通信呢?因为攻击者一般是在IT层面,而恶意软件一般会放在OT层面,OT和IT层之间基本上都会有一个防御层,普渡模型将之称为DMZ,如果攻击者长时间与恶意软件通信,会增加暴露的风险.
那么如果攻击者的恶意二进制文件在OT里面不需要通信就能一次性干完所有的恶意操作,那这个是非常有意义的一件事.
3)IT领域的二进制逆向工具一般是没法子逆向工程OT领域的二进制 。
为什么?因为用的编译器不一样,比如西门子plc采用SIMATIC STEP 7编程,Allen-Bradley plc采用Studio 5000 Logix Designer编程,大多数其他ICS供应商采用CODESYS框架编程,这些编程软件的编译器和传统软件的编译器如gcc根本就不一样,逆向工程就更别谈了.
PLC软件开发过程如上图所示:
1、工程师在工程工作站开发PLC逻辑。工程工作站配备了供应商提供的符合IEC 61131-3标准的集成开发环境(ide)和工厂中使用的特定PLC型号的编译器。用于控制物理过程的PLC逻辑是使用上面列出的一种或多种IEC 61131-3语言开发的,然后使用IEC编译器进行编译.
IEC 61131-3描述了以下用于plc的图形和文本编程语言
•梯形图(LD)、图形 。
•结构化文本(ST)、文本 。
•功能框图(FBD)、图形 。
•顺序功能图(SFC)、图形 。
•指令列表(IL)、文本(已弃用) 。
2、二进制文件被传输到PLC,这个过程在ICS术语中称为程序下载,PLC的runtime处理二进制文件的加载和执行,执行实时要求,并启用PLC二进制执行的调试和监控.
3、在正常运行期间,二进制文件被加载到PLC的快速、易失性存储器中(比如内存)并从中执行.
4、为了确保在停机时快速恢复,PLC二进制文件还存储在非易失性内存中.
执行模型
常规二进制和PLC二进制的执行模型也有所不同.
非plc语言的二进制文件,如传统的C语言编写的程序,通常遵循工作单元的顺序执行(例如,C编程语言的;-分隔语句).
相反,PLC二进制的执行模型是由扫描周期决定的,无限地执行它的三个组成步骤.
阻碍点:这可能会妨碍对整个PLC二进制文件的动态分析,因为它们具有无限执行的特性,需要为单个动态分析划分出适当的代码段.
I/O操作:
大多数传统二进制文件也依赖I/O操作来获取输入变量并产生相应的输出,但I/O操作对于PLC二进制文件的重要性要高得多.
在PLC二进制文件中,I/O操作是其功能的关键和必要部分, 占据了三分之二的扫描周期 .
文件格式
常规的操作系统(os)编译的二进制文件通常遵循良好的文档格式,例如Linux的可执行和可链接格式(ELF)和Windows的可移植可执行格式(PE)。这些格式的可执行文件由各自操作系统的加载器处理.
相反,PLC二进制文件的加载通常由专有的加载程序(例如CODESYS运行时)处理,PLC二进制文件的格式是自定义的,且未知.
编译器优化
由于需要保证生产的稳定和实时执行的时限,PLC二进制的编译器通常只进行非常保守的优化.
相反,不控制物理世界的传统二进制文件通常会使用非常优秀的编译器优化技术.
方法架构——两个阶段: 平台确定阶段 和 自动化二进制分析阶段 .
。
阶段目标: 提取不同平台对应的PLC二进制文件信息.
方法: 1)逆向工程并收集基于不同平台的PLC二进制程序的通用格式;2)构建知识数据库,这个数据库包含I/O信息、已知的函数信息.
方法:有很多现有的嵌入式系统或文件逆向工程方法可以参考 {原文的参考文献[8],[41],[48],[11],这里mark一下} .
难点一:PLC二进制的格式私有.
难点二:PLC二进制的执行模型。由于扫描周期的无限特性,动态分析不能对整个PLC二进制进行,而只能对适当的指令序列进行分析。然而,在PLC二进制文件中缺乏编译优化可能有利于这一步,因为不可变的编译结果,可以更容易地逆向工程.
结果:一般来说,二进制格式逆向工程步骤的结果应该包括header内容的信息,子例程(subroutine)是如何分隔的,子例程的提取及其反汇编清单,符号表和动态链接函数的标识,以及代码和数据段的信息.
Subroutine(又称子程序)是一段可以重复使用的程序代码,可以被多次调用并执行。在计算机编程中,Subroutine通常用来完成特定的任务,它可以接收一些参数、执行一些计算、修改一些变量的值,然后返回结果。Subroutine也被称为子例程、过程、函数等,不同的编程语言可能会有不同的术语.
Subroutine的优点是可以提高代码的可读性和可维护性。如果程序中有多处需要重复使用的代码,将这些代码封装成一个Subroutine,就可以避免代码重复,并且在需要修改时也只需要修改一处代码。Subroutine还可以使程序结构更加清晰,便于代码组织和管理.
。
目的:加速逆向工程 。
包含:
1)二进制的I/O操作信息数据库。这个I/O信息数据库应该包括二进制文件如何从物理I/O读写的信息、在内存映射外设的常见情况下,这些I/O外设的对应地址应该被标识并包含在数据库中.
2)已知库函数和代码片段的签名。这些签名可以将一些已知的子例程进行指纹化,从而加速逆向工程。有点抽象,简单的说就是比如MODBUS中处理网络通信的F/FB表示一般来说是固定的,将这段固定的代码记下来形成指纹,下次逆向工程就能“一眼看出”.
。
核心步骤:
第一步:利用前一阶段的二进制文件格式信息,分析二进制文件及其组成组件。在这一步中,所有的子例程都被分解,并且标识出描述动态链接函数的代码/数据节和符号表.
第二步:通过查找和解析分支的目标来重建一个尽可能完整的CFG图.
第三步:识别I/O操作的指令,并利用知识数据库对已知函数进行指纹识别.
补充步骤:
第一步:使用动态二进制分析和符号执行技术,自动化提取传递给函数调用的参数,这一步可以提取PLC所控制的物理环境的语义信息,比如一些I/O参数.
第二步:二进制文件修改。这一步允许动态的payload生成,或者注入基于host的防御。当然,修改文件是需要考虑CRC校验问题的.
第三步:可视化.
先使用codesys ide按照IEC61131-3编程语言的所有种类写控制应用程序.
请注意!作者是面向WAGO 750-881所采用的ARM体系结构编写程序,得到相应的PLC二进制文件(WAGO Codesys二进制文件扩展名为PRG).
。
。
PRG二进制文件的前80个字节构成包含一般信息的报头。 见表二:
报头内偏移量0x20处后推4字节的值,加0x18,得到的值是程序的入口点,结果值是 内存初始化子例程 的位置。 作者发现,只对头的一部分进行逆向工程就足以实现自动化分析.
将github上PRG文件放入010editor进行分析,80字节有这么多:
。
。
比较重要的几个信息有(下面几张图为从ICSREF的数据集中2.PRG文件的分析):
1) 程序入口点 。
该值减去0x18,就是程序入口点,这里涉及到一个大端小端序的问题,论文里作者没给出来,下面我会讨论一下可能性 。
。
2) 栈大小 。
。
我尝试从作者的代码中寻找答案,找到如下的代码:
。
第三个参数bigendian为false,可以确认作者在处理文件时使用的是小端序.
。
一个子例程的开始指令:
。
。
子例程退出的指令:
LDMDB R11, {R11, SP, PC}
LDMDB R11, {R11, SP, PC}是一个ARM汇编指令,用于从内存中加载多个寄存器的值,其中R11寄存器存储了内存地址。具体来说,该指令会从内存地址R11处开始,依次将4个寄存器R11、SP、PC的值加载到对应的寄存器中,并将R11的值加上16,以便下次操作时从正确的内存地址开始。因此,该指令实现了从内存中加载多个寄存器的值,并更新了R11寄存器的值。在ARM汇编中,LDMDB指令的含义为“Load Multiple Decremented Before”,表示在加载多个寄存器的值之前先将地址递减.
Global INIT子例程是所有PRG文件的第一个子例程,起始于0x50的偏移处(HEADER一共80字节,0x50是80),也就是紧随HEADER.
Global INIT功能:
设置常量、变量,初始化IEC 61131-3程序的VAR_GLOBAL section中定义的函数.
VAR_GLOBAL section :
codesys IDE里面 VAR_GLOBAL section 长这样 。
。
。
PLC程序员通常使用本节来定义与控制下的物理环境有关的程序范围内的常数(例如,缩放因子、PID增益、定时常数).
在Global INIT子例程之后,观察到三个较短的支持子例程,每个PRG文件都有。 接着后面是一个调试器处理程序子程序(SYSDEBUG),它支持从IDE进行动态调试.
。
调试器处理程序之后是导入库F/FBS的子程序.
每个静态链接的F/FB(function block)由两个子例程组成:一个子例程执行其主要功能(staticlib),另一个子例程初始化其本地内存(staticlib init).
与PLC编程器直接开发的代码相对应的用户自定义F/FB以类似的方式放置在每个F/FB的静态链接库之后 :首先是执行其主要功能的子程序(FB),然后是其初始化子程序(FB INIT).
倒数第二个子例程是主函数,在Codesys中名为PLC_PRG。 此子程序必须存在,并作为扫描周期的起点。 。
对于二进制中的子例程目标(例如静态链接的库F/FB或用户定义的F/FB),调用表由CODESYS运行时执行最后一个子例程 Memory INIT 之后构建的.
这个子例程的功能,也是二进制的入口点,有两个功能:
首先,将二进制所需的内存空间初始化为零; 。
其次,计算调用所有包含在二进制文件中的子例程所需的索引偏移量,创建相应的调用表.
这为重构CFG图带来了极大的便利,作者用angr重构CFG.
简单的标准函数,例如对 REAL 类型变量的数学运算,在 CODESYS 二进制文件中动态链接。有关这些函数的信息包含在符号表中.

符号表包含一组NullTerminated字符串标识符,后跟两个字节的数据,如下所示:
DCB "real_add", 0
DCW 0x82
DCB "real_sub", 0
DCW 0x83
这两个数据字节“0x82”、“0x83”被运行时用来计算调用相应函数所需的跳转偏移量(具体计算细节我还未了解).
为什么有I/O机制,or I/O机制的功能是什么?
I/O机制是PLC和物理环境通信接口,在PLC中,尤其是基于codesys runtime的PLC,物理I/O模块(接到wago PLC上的几个I/O板子)会内存映射到PLC内存中的特定地址。在codesys v2.3 IDE中创建新项目的时候会有如下界面:
。
例如,在 WAGO 750-881 PLC 的中,每当二进制程序中的内存load操作,即从 0x28CFEC00 - 0x28CFF7F8 范围内的内存地址执行读取操作时,它本质上是查询传感器,并且每当内存存储操作向 0x28CFD800 - 0x28CFE3F8 范围内写时,本质上是更新执行器.
如何从PLC二进制程序中提取这些值?
。
人工地从每个PLC控制应用二进制程序中提取很枯燥无味且很没意义,通过观察IDE安装目录,作者发现,每个PLC硬件的所有架构选项都包含在目标(TRG文件格式)文件中,位于IDE的安装目录中。 。
TRG文件使用了特定的压缩编码方法:
将文件内容按照2048bit为单位分块,将每个块与一个重复使用的2048bit的固定序列进行XOR异或操作,这个固定序列在所有TRG文件中都是相同的, 不受PLC供应商和目标PLC的影响.
通过该方案,可以快速、准确地解析TRG文件,提取PLC模型的I/O内存映射,自动填充I/O数据库,从而节省人工操作的时间和成本.
。
二进制程序中静态链接的函数的操作码对应codesys中FB的特定功能,如形成数据库,将方便逆向工程。方法如图:
图左是function_x对应的汇编指令集合,作者删除了操作指令后面的参数,因为参数是可变,指令不会变,然后将集合sha256编码,形成签名,存入数据库.
这个工具功能:
CFG是指程序的控制流程图(Control Flow Graph),它用图形化的方式表示程序中代码块(Basic Block)之间的控制流转移关系。CFG常常被用来进行程序分析和优化。在程序中,基本块是一组没有跳转或者只有从头到尾的跳转语句的代码集合,因此CFG可以将程序划分为一系列的基本块,并表示它们之间的控制流转移关系 。
第一步,下下来:
git clone https://github.com/momalab/ICSREF.git && cd ICSREF
第二步,给你的主机安装相关的库依赖:
sudo apt install git python-pip libcapstone3 python-dev libffi-dev build-essential virtualenvwrapper graphviz libgraphviz-dev graphviz-dev pkg-config
以及上文提到的radare2
wget https://github.com/radareorg/radare2/archive/refs/tags/3.1.3.zip
unzip 3.1.3.zip && cd radare2-3.1.3
./sys/install.sh && cd ..
第三步,创建环境,作者用的是:
mkvirtualenv icsref
然而因为python的玄学环境,我的mkvir一直报错,之前调试过一次,太麻烦,这里我直接用conda直接创建环境了,看到作者使用python 2.7 写的,所以:
conda create --name icsref python=2.7
然后直接切换到这icsref环境里:
conda activate icsref
然后去ICSREF的目录中,安装所需要的python 库即可:
pip install --no-index --find-links=wheelhouse -r requirements.txt
最后,创建bash偏好:
echo -e "\n# ICSREF alias\nalias icsref='workon icsref && python `pwd`/icsref/icsref.py'\n" >> ~/.bash_aliases && source ~/.bashrc
conda activate icsref
然后跳转到ICSREF/icsref目录下,输入 。
我要测试237.PRG,也就是项目文件中ICSREF/samples/ PRG_binaries中的文件,请注意,在输入python icsref.py后,如果需要使用Linux的命令,则需要在命令前加上!,如ls就是!ls 。
首先输入help看看有什么功能:
。
先使用analyze 分析一下文件:
分析完后,打开results文件夹:
。
输入hashmatch,匹配hash数据库中指定的函数:
。
输入graphbuilder,获得了以svg结尾的图,打开如下: 。
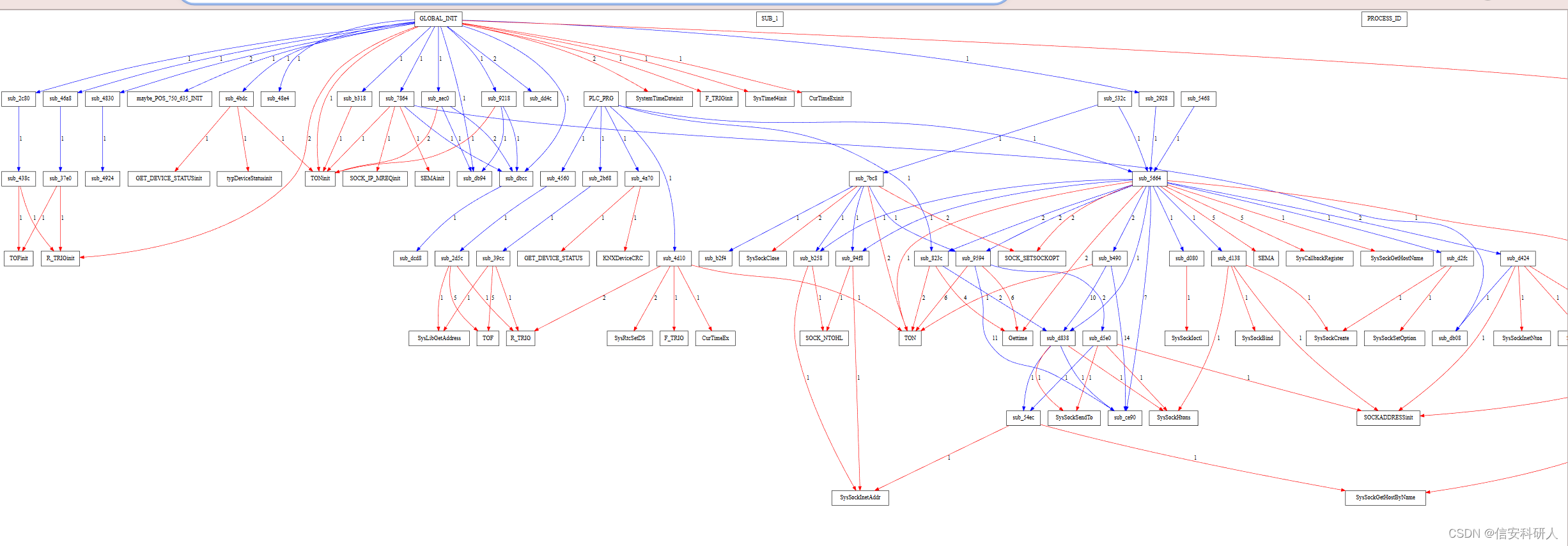
![]()
。
最后此篇关于工业控制应用程序二进制的秘密的文章就讲到这里了,如果你想了解更多关于工业控制应用程序二进制的秘密的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
我正在尝试将谷歌地图集成到 Xamarin Android。但是,如标题中所写,收到错误。此错误出现在我的 SetContentView (Resource.Layout.Main); 上,如下所示:
在 Delphi 中如何以非文本模式打开二进制文件?类似于 C 函数 fopen(filename,"rb") 最佳答案 有几个选项。 1。使用文件流 var Stream: TFileStrea
我现在正在处理一个问题,如下所示: 有两个数字 x1 和 x2 并且 x2 > x1。 例如 x1 = 5; x2 = 10; 而且我必须在二进制表示中找到 x1 和 x2 之间的总和。 5 = 10
我有这个“程序集”文件(仅包含 directives ) // declare protected region as somewhere within the stack .equiv prot_s
有没有办法在powershell中确定指定的文件是否包含指定的字节数组(在任何位置)? 就像是: fgrep --binary-files=binary "$data" "$filepath" 当然,
我是一名工程师,而不是软件程序员,所以请原谅我的无知。 我编写了一个 Delphi(7SE) 程序,用于从连接到两个数字温度计的 USB 端口读取“真实”数据类型。 我已经完成了该计划的大部分内容。
我有一些代码,例如: u=(float *)calloc(n, sizeof(float)); for(i=1; i
typedef struct pixel_type { unsigned char r; unsigned char g; unsigned char b;
如何判断二进制数是否为负数? 目前我有下面的代码。它可以很好地转换为二进制文件。转换为十进制时,我需要知道最左边的位是否为 1 以判断它是否为负数,但我似乎无法弄清楚该怎么做。 此外,我如何才能让它返
我有一个带有适当重载的 Vect*float 运算符的 vector 类,我正在尝试创建全局/非成员 float*Vect 运算符,如下所示:(注意这是一个经过大量编辑的示例) class Vect
对于使用 C 编程的项目,我们正在尝试将图像转换为二进制数据,反之亦然。我们在网上找到的所有其他解决方案都是用 C++ 或 Java 编写的。这是我们尝试过的方法: 将图像转换为包含二进制数据的文本文
我需要对列表的元素求和,其中包含所有零或一,如果列表中有 1,则结果为 1,否则为 0。 def binary_search(l, low=0,high=-1): if not l: retu
我到处搜索以找到将 float 转换为八进制或二进制的方法。我知道 float.hex 和 float.fromhex。是否有模块可以对八进制/二进制值执行相同的工作? 例如:我有一个 float 1
当我阅读有关 list.h 文件中的 hlist 的 FreeBSD 源代码时,我对这个宏感到困惑: #define hlist_for_each_entry_safe(tp, p, n, head,
我不知道出了什么问题,也不知道为什么会出现此错误。我四处搜索,但我终究无法弄明白。 void print_arb_base(unsigned int n, unsigned int b) {
在任何语言中都可以轻松地将十进制转换为二进制,反之亦然,但我需要一个稍微复杂一点的函数。 给定一个十进制数和一个二进制位,我需要知道二进制位是开还是关(真或假)。 示例: IsBitTrue(30,1
在下面的代码中,我创建了两个文件,一个是文本格式,另一个是二进制格式。文件的图标显示相同。但是这两个文件的特征完全相同,包括大小、字符集(==二进制)和流(八位字节)。为什么没有文本文件?因为如果我明
我想通读一个二进制文件。谷歌搜索“python binary eof”引导我here . 现在,问题: 为什么容器(SO 答案中的 x)不包含单个(当前)字节而是包含一大堆字节?我做错了什么? 如果应
为什么只允许以 10 为基数使用小数点?为什么以下会引发语法错误? 0b1011101.1101 我输入的数字是否有歧义?除了 93.8125 之外,字符串似乎没有其他可能的数字 同样的问题也适用于其
boost 库中有二进制之类的东西吗?例如我想写: binary a; 我很惭愧地承认我曾尝试找到它(Google、Boost)但没有结果。他们提到了一些关于 binary_int<> 的内容,但我既

我是一名优秀的程序员,十分优秀!