
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 27
27
 4
4


摘要: 本文就带大家了解在昇腾平台上对TensorFlow训练网络进行性能调优的常用手段。
本文分享自华为云社区《 在昇腾平台上对TensorFlow网络进行性能调优 》,作者:昇腾CANN .
用户将TensorFlow训练网络迁移到昇腾平台后,如果存在性能不达标的问题,就需要进行调优。本文就带大家了解在昇腾平台上对TensorFlow训练网络进行性能调优的常用手段.
首先了解下性能调优的全流程:
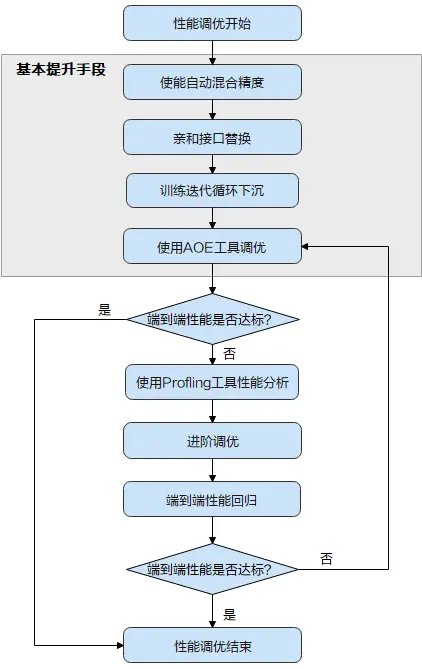
当TensorFlow训练网络性能不达标时,首先可尝试昇腾平台提供的“三板斧”操作,即上图中的“基本提升手段”:使能自动混合精度 > 进行亲和接口的替换 > 使能训练迭代循环下沉 > 使用AOE工具进行调优.
基本调优操作完成后,需要再次执行模型训练并评估性能,如果性能达标了,调优即可结束;如果未达标,需要使用Profling工具采集详细的性能数据进一步分析,从而找到性能瓶颈点,并进一步针对性的解决,这部分调优操作需要用户有一定的经验,难度相对较大,我们将这部分调优操作称为进阶调优.
本文主要带大家详细了解基本调优操作,即上图中的灰色底纹部分.
混合精度是业内通用的性能提升方式,通过降低部分计算精度提升数据计算的并行度。混合计算训练方法通过混合使用float16和float32数据类型来加速深度神经网络的训练过程,并减少内存使用和存取,从而可以提升训练网络性能,同时又能基本保证使用float32训练所能达到的网络精度.
Ascend平台提供了“precision_mode”参数用于配置网络的精度模式,用户可以在训练脚本的运行配置中添加此参数,并将取值配置为“allow_mix_precision”,从而使能自动混合精度,下面以手工迁移的训练脚本为例,介绍配置方法.
npu_config=
NPURunConfig(
model_dir
=
FLAGS.model_dir,
save_checkpoints_steps
=FLAGS.save_checkpoints_steps, session_config=tf.ConfigProto(allow_soft_placement=True,log_device_placement=
False),
precision_mode
=
"
allow_mix_precision
"
)
config = tf.ConfigProto(allow_soft_placement=
True)
custom_op
=
config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name
=
"
NpuOptimizer
"
custom_op.parameter_map[
"
use_off_line
"
].b =
True
custom_op.parameter_map[
"
precision_mode
"
].s = tf.compat.as_bytes(
"
allow_mix_precision
"
)
…
with tf.Session(config
=config)
as
sess:
print(sess.run(cost))
针对TensorFlow训练网络中的dropout、gelu接口,Ascend平台提供了硬件亲和的替换接口,从而使网络获得更优性能.
layers = npu_ops.dropout()
from
npu_bridge.estimator.npu import npu_convert_dropout
例如,TensorFlow原始代码:
迁移后的代码:
from
npu_bridge.estimator.npu_unary_ops import npu_unary_ops
layers
= npu_unary_ops.gelu(x)
训练迭代循环下沉是指在Host调用一次,在Device执行多次迭代,从而减少Host与Device间的交互次数,缩短训练时长。用户可通过iterations_per_loop参数指定训练迭代的次数,该参数取值大于1即可使能训练迭代循环下沉的特性.
使用该特性时,要求训练脚本使用TF Dataset方式读数据,并开启数据预处理下沉,即enable_data_pre_proc开关配置为True,例如sess.run配置示例如下:
custom_op.parameter_map[
"
enable_data_pre_proc
"
].b = True
其他使用约束,用户可参见 昇腾文档中心的《TensorFlow模型迁移和训练指南》.
Estimator模式下,通过NPURunConfig中的iterations_per_loop参数配置训练迭代循环下沉的示例如下:
session_config=tf.ConfigProto(allow_soft_placement=
True)
config
= NPURunConfig(session_config=session_config, iterations_per_loop=
10
)
昇腾平台提供了AOE自动调优工具,可对网络进行子图调优、算子调优与梯度调优,生成最优调度策略,并将最优调度策略固化到知识库。模型再次训练时,无需开启调优,即可享受知识库带来的收益.
建议按照如下顺序使用AOE工具进行调优:
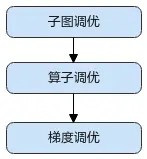
训练场景下使能AOE调优有两种方式:
#
1
:子图调优
#
2
:算子调优
#
4
:梯度调优
export AOE_MODE
=
2
sess.run模式,训练脚本修改方法如下:
custom_op.parameter_map[
"
aoe_mode
"
].s = tf.compat.as_bytes(
"
2
"
)
estimator模式下,训练脚本修改方法如下:
config =
NPURunConfig(
session_config
=
session_config,
aoe_mode
=
2
)
以上就是TensorFlow网络在昇腾平台上进行性能调优的常见手段。关于更多文档介绍,可以在 昇腾文档中心 查看,您也可在 昇腾社区在线课程 板块学习视频课程,学习过程中的任何疑问,都可以在 昇腾论坛 互动交流! 。
[1] 昇腾文档中心 。
[2] 昇腾社区在线课程 。
[3] 昇腾论坛 。
。
点击关注,第一时间了解华为云新鲜技术~ 。
最后此篇关于在昇腾平台上对TensorFlow网络进行性能调优的文章就讲到这里了,如果你想了解更多关于在昇腾平台上对TensorFlow网络进行性能调优的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
27
4
 0
0
在这段令人惊叹的视频 ( https://www.youtube.com/watch?v=udix3GZouik ) 中,Alex Blom 谈到了 Ember 在移动世界中的“黑客攻击”。 在 22
我们希望通过我们的应用收集使用情况统计信息。因此,我们希望在服务器端的某个地方跟踪用户操作。 就性能而言,哪个选项更合适: 在 App Engine 请求日志中跟踪用户操作。即为每个用户操作写入一个日
在针对对象集合的 LINQ 查询的幕后究竟发生了什么?它只是语法糖还是发生了其他事情使其更有效的查询? 最佳答案 您是指查询表达式,还是查询在幕后的作用? 查询表达式首先扩展为“普通”C#。例如: v
我正在构建一个简单的照片库应用程序,它在列表框中显示图像。 xaml 是:
对于基于 Web 的企业应用程序,使用“静态 Hashmap 存储对象” 和 apache java 缓存系统有何优缺点?哪一个最有利于性能并减少堆内存问题 例如: Map store=Applica
我想知道在性能方面存储类变量的最佳方式是什么。我的意思是,由于 Children() 函数,存储一个 div id 比查找所有其他类名更好。还是把类名写在变量里比较好? 例如这样: var $inne
我已经阅读了所有这些关于 cassandra 有多快的文章,例如单行读取可能需要大约 5 毫秒。 到目前为止,我不太关心我的网站速度,但是随着网站变得越来越大,一些页面开始需要相当多的查询,例如一个页
最近,我在缓存到内存缓存之前的查询一直需要很长时间才能处理!在这个例子中,它花费了 10 秒。在这种情况下,我要做的就是获得 10 个最近的点击。 我感觉它加载了所有 125,592 行然后只返回 1
我找了几篇文章(包括SA中的一些问题),试图找到基本操作的成本。 但是,我尝试制作自己的小程序,以便自己进行测试。在尝试测试加法和减法时,我遇到了一些问题,我用简单的代码向您展示了这一点
这个问题在这里已经有了答案: Will Java app slow down by presence of -Xdebug or only when stepping through code? (
我记得很久以前读过 with() 对 JavaScript 有一些严重的性能影响,因为它可能对范围堆栈进行非确定性更改。我很难找到最近对此的讨论。这仍然是真的吗? 最佳答案 与其说 with 对性能有
我们有一个数据仓库,其中包含非规范化表,行数从 50 万行到 6 多万行不等。我正在开发一个报告解决方案,因此出于性能原因我们正在使用数据库分页。我们的报告有搜索条件,并且我们已经创建了必要的索引,但
我有一条有效的 SQL 语句,但需要很长时间才能处理 我有一个 a_log 表和一个 people 表。我需要在 people 表中找到给定人员的每个 ID 的最后一个事件和关联的用户。 SELECT
很难说出这里问的是什么。这个问题是含糊的、模糊的、不完整的、过于宽泛的或修辞性的,无法以目前的形式得到合理的回答。如需帮助澄清此问题以便重新打开它,visit the help center 。 已关
通常当我建立一个站点时,我将所有的 CSS 放在一个文件中,并且一次性定义与一组元素相关的所有属性。像这样: #myElement { color: #fff; background-
两者之间是否存在任何性能差异: p { margin:0px; padding:0px; } 并省略最后的分号: p { margin:0px; padding:0px } 提前致谢!
我的应用程序 (PHP) 需要执行大量高精度数学运算(甚至可能出现一共100个数字) 通过这个论坛的最后几篇帖子,我发现我必须使用任何高精度库,如 BC Math 或 GMP,因为 float 类型不
我一直在使用 javamail 从 IMAP 服务器(目前是 GMail)检索邮件。 Javamail 非常快速地从服务器检索特定文件夹中的消息列表(仅 id),但是当我实际获取消息(仅包含甚至不包含
我非常渴望开发我的第一个 Ruby 应用程序,因为我的公司终于在内部批准了它的使用。 在我读到的关于 Ruby v1.8 之前的所有内容中,从来没有任何关于性能的正面评价,但我没有发现关于 1.9 版
我是 Redis 的新手,我有一个包含数百万个成员(member) ID、电子邮件和用户名的数据集,并且正在考虑将它们存储在例如列表结构中。我认为 list 和 sorted set 可能最适合我的情

我是一名优秀的程序员,十分优秀!