
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 24
24
 4
4



本文发表于 2020 年 6 月 8 日,虽然时间较久远,但现在看起来仍然是非常有价值的一篇文章.
在这个全民 LLM 的狂欢里,想测测你拿到的预算够训一个多大的模型吗?本文会给你一个答案,至少给你一个计算公式.
在自然语言处理领域,有时候我们恍惚觉得大家是为了搏头条而在模型尺寸上不断进行军备竞赛。 1750 亿参数 无疑是一个很抓眼球数字!为什么不考虑高效地去训一个小一点的模型?其实,这是因为深度学习领域有一个挺惊人的缩放效应,那就是: 大神经网络计算效率更高 。这是以 OpenAI 为代表的团队在像 神经语言模型的缩放定律 这样的论文中探索出的结论。 本文的研究也基于这一现象,我们将其与 GPU 速度估计相结合,用于确保在进行语言模型实验时,我们能根据我们算力预算来设计最合适的模型尺寸 (剧透一下,这个大小比你想象的要大!)。我们将展示我们的方法是如何影响一个标准的语言建模基准的架构决策的: 我们在没有任何超参优化的前提下,仅使用了原论文 75% 的训练时间,复现了 Zhang 等人的 Transformer-XL 论文 中的 14 层模型的最佳结果 。我们还估计 来自同一篇论文的 18 层模型其实仅需要比原论文少一个数量级的步数就能达到相同的结果 。继续阅读之前想先玩玩我们的演示吗?只需单击 此处 ! 。
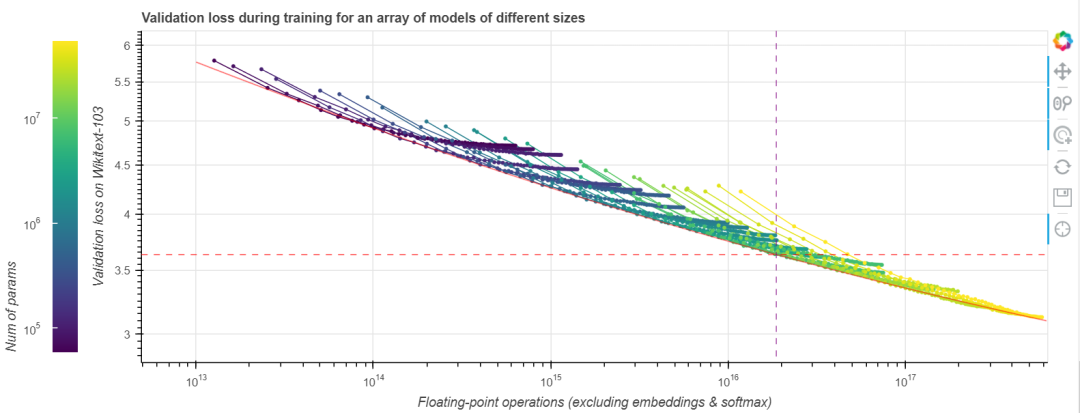
我们先观察一些损失曲线 (loss curve)。我们使用的任务是在 Wikitext-103 上训练 Transformer-XL 语言模型,Wikitext-103 是一个标准的中等体量的测试基准。 GPT-2 在此等体量的数据集上表现不佳。随着训练的进行,我们来观察计算成本 (通过浮点运算数来衡量) 与模型性能 (通过验证集上的损失来衡量) 的联动关系。我们做点实验吧!在下图中,不同颜色的线段表示不同层数和大小的 Transformer-XL 模型运行 200000 步的数据,这些模型除了层数与大小外的所有其他超参数都相同。模型参数量范围从几千到一亿 (不含嵌入)。越大的模型在图中越靠右,因为它们每一步需要的计算量更大。本图是交互式的,你可以玩一玩! 。
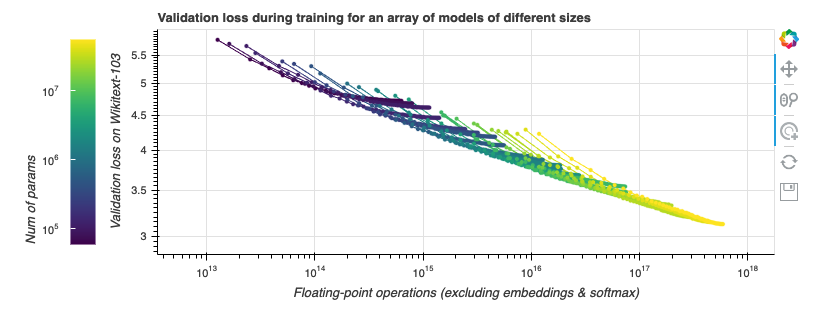
与 缩放定律 一文中的做法一样,我们的横轴为非嵌入浮点运算数 (non-embedding FLoating Point Operations, neFLOs),纵轴为验证集损失。对于给定的 neFLOs 预算,似乎存在一个任何模型都没法越过的性能边界,我们在图中用红色线段表示。在 缩放定律 一文中,它被称为计算边界 (compute frontier)。我们可以看到,在所有的实验中,几乎每个实验都能在经过初始若干步的损失迅速降低后达到或接近该计算边界,随后又在训练接近尾声时,因训练效率降低而偏离该计算边界。这个现象有其实际意义: 给定固定的浮点运算预算,为了达到最佳性能,你应该选择一个模型尺寸,使得在浮点运算预算见顶时正好达到计算边界,然后我们就可以在此时停止训练。此时离模型收敛所需的时间还很远,模型收敛还需要 10 倍左右的时间。事实上,如果此时你还有额外的钱可用于计算,你应该把大部分用到增大模型上,而只将一小部分用于增加训练步数。[ 译者注: 这是因为性能边界本质上度量了每 neFLOs 带来的 loss 的降低是多少,到达计算边界后,后面的每 neFLOs 能带来的 loss 的降低变小,不划算了。我们应该转而去寻求增大模型所带来的接近计算边界的高回报,而不应该卷在增加训练步数带来的低回报上。 ] 。
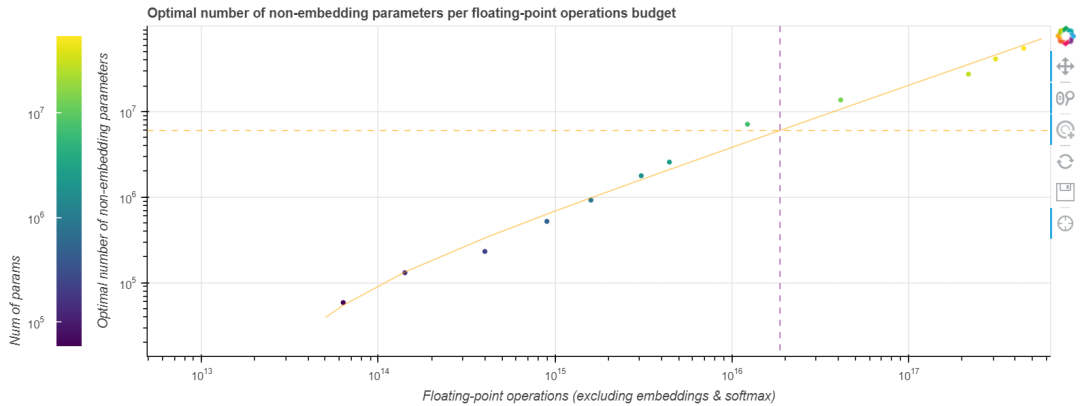
在 缩放定律 一文中,OpenAI 团队用幂律函数拟合了一个 GPT-2 训练的计算边界。这似乎也适用于我们的任务,我们也拟合了一个以预算为自变量,最适合该预算的模型参数量为因变量的幂律函数。如下图所示.
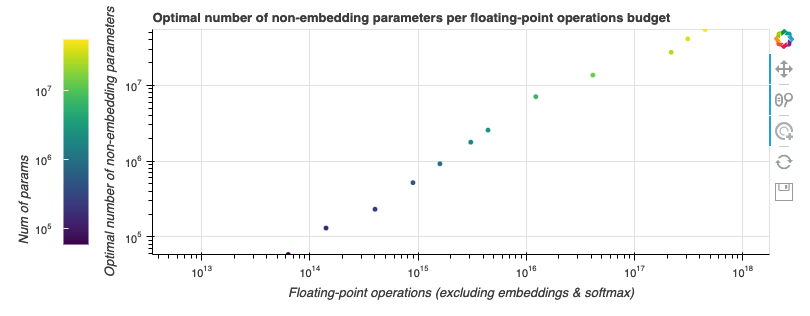
由于好的模型的 neFLOs- 损失 曲线往往会与计算边界相切比较长时间,因此最终的拟合函数会存在一些噪声。然而,这恰恰也意味着基于该拟合函数的估计的容忍度会比较好,即使我们预测尺寸有点偏差,其结果仍然会非常接近最优值。我们发现,如果将算力预算乘以 10,最佳模型尺寸会随之乘以 7.41,而最佳训练步数仅乘以 1.35。将此规则外推到 Tranformer-XL 论文中的那个更大的 18 层最先进模型,我们发现 其最佳训练步数约为 25 万步 。即使这个数字由于模型尺寸的变化而变得不那么精确,它也比论文中所述的 收敛所需的 400 万步 小得多。以更大的模型、更少的训练步数为起点,在给定的 (庞大的) 预算下我们能训到更小的损失.
我们现在有了一个将性能和最佳模型尺寸与 neFLOs 联系起来的规则。然而,neFLOs 有点难以具象化。我们能否将其转化为更直观的指标,如训练时间?其实,无论你是有时间上的限制还是财务上的限制,主要关注的都是 GPU 时间。为了在 neFLOs 和 GPU 时间之间建立联系,我们在谷歌云平台上用 4 种不同 GPU 实例以及各种不同大小的 Transformer-XL 模型进行了数万次的基准测试 (包括混合精度训练测试)。以下是我们的发现
每秒 neFLOs (即公式中的 speed ) 可以建模为由模型宽度 (每层神经元数) 、深度 (层数) 和 batch size 三个因子组成的多变量函数,这三个因子的重要性递减。在我们的实验中,观察到的最大预测误差为测量值的 15%.
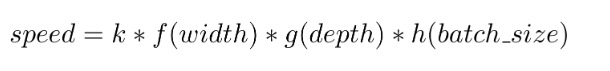
GPU 针对宽 transfomer 模型的大型前馈层进行了优化。在我们所有的实验中,每秒 neFLOs 与模型宽度 呈 1.6 次方的幂律关系 ,这意味着两倍宽的模型需要 4 倍的操作。然而执行这些操作的速度也提高了大约 3.16 倍, 几乎抵消了额外的计算成本 .
每秒 neFLOs 也与深度正相关。我们目前发现的最佳关系是每秒 neFLOs 与 成正比。这与 transformer 模型必须串行地处理每一层的事实是一致的。从本质上讲, 层数更多的模型其实并不会更快,但它们似乎表现出更快,其原因主要是它们的均摊开销更小 。公式中的 常数 就代表这一开销,在我们的实验中该常数一直在 5 左右,这其实意味着 GPU 加载数据、嵌入和 softmax 这些操作的耗时大约相当于 5 个 transfomer 层的时间.
Batch size 发挥的作用最小。 Batch size 较小时,其与速度呈正相关关系,但这个关系很快就饱和了 (甚至在 V100 和 P100 上 batch size 大于 64 后、在 K80 和 P4 batch size 大于 16 后,速度比小 batch size 时还有所降低)。因此,我们将其对速度的贡献建模为对数函数以简化计算,它是 3 个因子中最弱的。因此,最终我们所有实验都是在单 GPU 上用 batch size 64 运行出来的。这是大模型的另一个好处: 因为更大的 batch size 似乎没有多大帮助,如果你的模型太大而无法塞进 GPU,你可以只使用较小的 batch size 以及梯度累积技术.
最后,一个令人惊讶的收获是 宽度或 batch size 设置为 2 的幂的话其最终性能会比设为其他值高 。有或没有 Tensor Core 的 GPU 都是如此。在像 V100 这样的 Tensor Core GPU 上,NVIDIA 建议张量形状设置为 8 的倍数; 然而,我们试验过将其不断加倍至 512 的倍数,性能还会继续提高。但是,在最终拟合时我们还是只选择拟合 2 的幂的数据,因为拟合所有数据点意味着拟合质量会变差,而且最终的拟合结果会对采用 2 的幂情况下的速度估计得过于乐观。但这不妨碍你去选择最快的形状参数.
最终,我们得到运行速度的估算公式如下
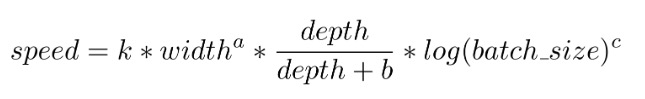
例如,在未使用混合精度的 V100 GPU 上,k=2.21 × 10^7、a=1.66、b=5.92、c=1.33。不同的 GPU 具有不同的乘性系数,但结果很接近.
现在我们已经知道了模型尺寸和训练速度之间的关系,我们可以依此预测: 对于给定的 GPU 时间或预算,适合目标任务的最佳模型尺寸及其能达到的性能.
这里使用的价格是 Google 云平台 (Google Cloud Platform,GCP) 的价格。我们使用了 Peter Henderson 的 Experiment impact tracker 来估算能源消耗,并使用了 Electricity map 的荷兰数据 (Google 的欧洲服务器所在地) 来估算 CO2 排放量。尽管巨大的训练成本常常博得头条,但事实上,我们仍然有可能以 30 美元的价格在中等规模的数据集上复现最先进的结果!对于一个恰当优化过的训练方案而言,V100 已经算一个强大的武器了.
图中所示的数据的测例为在 Wikitext-103 上使用 batch size 60 以及单 GPU 训练一个 Transformer-XL 模型,模型的目标长度 (target length) 和记忆长度 (memory length) 为 150,测试基于 CMU 的 Transformer-XL 代码库 。为了充分利用 V100 的 Tensor Core 功能,我们在该 GPU 上把 batch size 设为 64,序列长度设为 152。在我们的 模型尺寸 - 速度 预测公式中,我们假设内部前馈层维度与嵌入和注意力维度相同,并且宽深比是恒定的。 Reformer 表明,这种设置有利于节省内存。虽然 缩放定律 一文表明: 形状不会显著影响 GPT-2 的性能。然而,对于大模型而言,我们还是发现具有更大前馈层的更浅的模型的性能会更好,因此我们在图中给出了两种候选的模型形状: 一个宽而浅,一个窄而深.
为了复现中型 Transformer-XL 预训练模型 (损失为 3.15) 的结果,我们调整了原模型的大小以增加的前馈维度并使之为 2 的高次幂,同时保持相同参数量。我们最终得到了一个 14 层的模型,隐藏层维度为 768 且前馈层维度为 1024。相比之下,原文中的模型是通过激进的超参数搜索搜得的 16 层模型,形状也很奇怪,隐藏层维度为 410 且前馈层维度为 2100。我们的实验表明,由于我们的形状是 2 的高次方,并且是一个更浅、更宽的模型,因此它在 NVIDIA RTX Titan 上每 batch 的速度比原模型提高了 20%。对于该模型,CMU 团队提供的脚本已经非常接近最佳停止时间。最终,我们获得了相同的性能,同时减少了 25% 的训练时间 。最重要的是,原模型使用超参数搜索得到了对它而言更优形状,而我们什么也没调,甚至连随机种子也是直接复用的他们手调的随机种子。由于我们使用了较小规模的训练来拟合缩放定律,并依此缩放定律计算所需的模型超参,因此节省参数搜索实际上可能是我们获得的另一个也是更大的一个收益.
英文原文: https://hf.co/calculator/ 。
原文作者: Teven Le Scao 。
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理.
审校、排版: zhongdongy (阿东) 。
最后此篇关于我的语言模型应该有多大?的文章就讲到这里了,如果你想了解更多关于我的语言模型应该有多大?的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
24
4
 0
0
我正在尝试在Elasticsearch中返回的值中考虑地理位置的接近性。我希望近距离比某些字段(例如legal_name)重要,但比其他字段重要。 从文档看来,当前的方法是使用distance_fea
我是Elasticsearch的初学者,今天在进行“多与或”查询时遇到问题。 我有一个SQL查询,需要在Elastic中进行转换: WHERE host_id = 999 AND psh_pid =
智能指针应该/可以在函数中通过引用传递吗? 即: void foo(const std::weak_ptr& x) 最佳答案 当然你可以通过const&传递一个智能指针。 这样做也是有原因的: 如果接
我想执行与以下MYSQL查询等效的查询 SELECT http_user, http_req_method, dst dst_port count(*) as total FROM my_table
我用这两个查询进行测试 用must查询 { "size": 200, "from": 0, "query": { "bool": { "must": [ { "mat
我仍在研究 Pro Android 2 的简短服务示例(第 304 页)同样,服务示例由两个类组成:如下所示的 BackgroundService.java 和如下所示的 MainActivity.j
给定标记 like this : header really_wide_table..........................................
根据 shouldJS 上的文档网站我应该能够做到这一点: ''.should.be.empty(); ChaiJS网站没有使用 should 语法的示例,但它列出了 expect 并且上面的示例似乎
我在 Stack Overflow 上读到一些 C 函数是“过时的”或“应该避免”。你能给我一些这种功能的例子以及原因吗? 这些功能有哪些替代方案? 我们可以安全地使用它们 - 有什么好的做法吗? 最
在 C++11 中,可变参数模板允许使用任意数量的参数和省略号运算符 ... 调用函数。允许该可变参数函数对每个参数做一些事情,即使每个参数的事情不是一样的: template void dummy(
我在我从事的项目之一上将Shoulda与Test::Unit结合使用。我遇到的问题是我最近更改了此设置: class MyModel :update end 以前,我的(通过)测试看起来像这样: c
我该如何做 or使用 chai.should 进行测试? 例如就像是 total.should.equal(4).or.equal(5) 或者 total.should.equal.any(4,5)
如果您要将存储库 B 中的更改 merge 到存储库 A 中,是否应该 merge .hgtags 中的更改? 存储库 B 可能具有 A 中没有的标签 1.01、1.02、1.03。为什么要将这些 m
我正在尝试执行X AND(y OR z)的查询 我需要获得该代理为上市代理或卖方的所有已售属性(property)。 我只用 bool(boolean) 值就可以得到9324个结果。当我添加 bool
我要离开 this教程,尝试使用 Mocha、Supertest 和 Should.js 进行测试。 我有以下基本测试来通过 PUT 创建用户接受 header 中数据的端点。 describe('U
我正在尝试为 Web 应用程序编写一些 UI 测试,但有一些复杂的问题希望您能帮助我解决。 首先,该应用程序有两种模式。其中一种模式是“训练”,另一种是“现场”。在实时模式下,数据直接从我们的数据库中
我有一个规范: require 'spec_helper' # hmm... I need to include it here because if I include it inside desc
我正在尝试用这个测试我在 Rails 中的更新操作: context "on PUT to :update" do setup do @countdown = Factory(:count
我还没有找到合适的答案: onclick="..." 中是否应该转义 &(& 符号)? (或者就此而言,在每个 HTML 属性中?) 我已经尝试在 jsFiddle 和 W3C 的验证器上运行转义和非
import java.applet.*; import java.awt.*; import java.awt.event.*; public class Main extends Applet i

我是一名优秀的程序员,十分优秀!