
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 27
27
 4
4


这里以Nvidia GPU设备如何在Kubernetes中管理调度为例研究, 工作流程分为以下两个方面:
想要在容器中的应用可以操作GPU, 需要实两个目标:
在应用程序中使用 GPU,由于需要安装 nvidia driver, Docker 引擎并没有原生支持。因此也就无法直接在容器中访问 GPU 资源.
为了解决容器中无法访问 GPU 资源的问题,有以下方案:
1、无nvidia-docker 在早期的时候,没有nvidia-docker,可以通过在容器内再部署一遍nvidia GPU驱动解决。同理,其他设备如果想在容器里使用,也可以采用在容器里重新安装一遍驱动解决。 2、nvidia-docker1.0 nvidia-docker是英伟达公司专门用来为docker容器使用nvidia GPU而设计的,设计方案就是把宿主机的GPU驱动文件映射到容器内部使用,可以通过tensorflow生成GPU驱动文件夹。 3、nvidia-docker2.0 nvidia-docker2.0对nvidia-docker1.0进行了很大的优化,不用再映射宿主机GPU驱动了,直接把宿主机的GPU运行时映射到容器即可。启动方式示例:
nvidia-docker run -d -e NVIDIA_VISIBLE_DEVICES=all --name nvidia_docker_test nvidia/cuda:10.0-base /bin/sh -c "while true; do echo hello world; sleep 1; done"
4、安装docker19.03及以上版本,已经内置了nvidia-docker,无需再单独部署nvidia-docker了。安装方式如下:
安装docker:
yum install -y yum-utils
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum-config-manager --enable docker-ce-nightly
yum-config-manager --enable docker-ce-test
yum install docker-ce docker-ce-cli containerd.io
systemctl start docker
安装nvidia-container-toolkit
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
sudo yum install -y nvidia-container-toolkit
sudo systemctl restart docker
启动容器:
docker run --gpus all nvidia/cuda:10.0-base /bin/sh -c "while true; do echo hello world; sleep 1; done"
进入容器并输入nvidia-smi验证。
在容器中重新安装 nvidia driver,容器启动的时候将 nvidia gpu 作为符号设备传递进来。这种方案的问题在于宿主机和容器内安装的 nvidia driver 版本可能不一致,因此 docker image 无法在多机间共享。这就丧失了 docker 的主要优势.
因此,为了在保持 docker image 迁移性的同时可以方便的使用 gpu,nvidia 提出了 nvidia docker 的方案.
参考文献: https://developer.nvidia.com/blog/gpu-containers-runtime/ 。
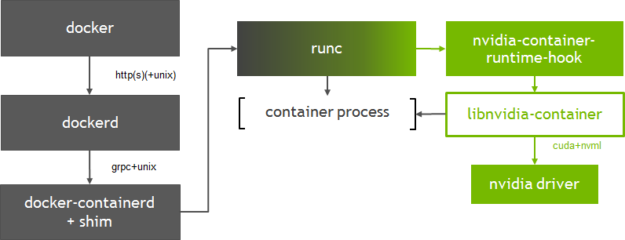
容器启动流程大致为:docker --> dockerd --> docker-containerd-shim --> nvidia-container-runtime-hook --> libnvidia-container--> nvidia-driver.
docker客户端将创建容器的请求发送给dockerd, 当dockerd收到请求任务之后将请求发送给docker-containerd-shim,nvidia-container-runtime创建容器时,先执行nvidia-container-runtime-hook这个hook去检查容器是否需要使用GPU(通过环境变量NVIDIA_VISIBLE_DEVICES来判断)。如果需要则调用libnvidia-container来暴露GPU给容器使用。否则则走默认的runc逻辑.
Nvidia-docker 。
项目地址: https://github.com/NVIDIA/nvidia-docker 。
Nvidia提供Nvidia-docker项目,它是通过修改Docker的Runtime为nvidia runtime工作,当我们执行 nvidia-docker create 或者 nvidia-docker run 时,它会默认加上 --runtime=nvidia 参数。将runtime指定为nvidia.
nvidia-docker是在docker的基础上做了一层封装,通过 nvidia-docker-plugin把硬件设备在docker的启动命令上添加必要的参数.
gpu-containers-runtime 。
gpu-containers-runtime 是一个NVIDIA维护的容器 Runtime,它在runc的基础上,维护了一份 Patch , 在容器启动前,注入一个 prestart 的hook 到容器的Spec中(hook的定义可以查看 OCI规范 )。这个hook 的执行时机是在容器启动后(Namespace已创建完成),容器自定义命令(Entrypoint)启动前.
gpu-containers-runtime-hook 。
gpu-containers-runtime-hook 是一个简单的二进制包,定义在Nvidia container runtime的hook中执行。 目的是将当前容器中的信息收集并处理,转换为参数调用 nvidia-container-cli 。主要处理以下参数:
NVIDIA_VISIBLE_DEVICES 判断是否会分配GPU设备,以及挂载的设备ID。如果是未指定或者是 void ,则认为是非GPU容器,不做任何处理。 否则调用 nvidia-container-cli , GPU设备作为 --devices 参数传入 NVIDIA_DRIVER_CAPABILITIES 判断容器需要被映射的 Nvidia 驱动库。 NVIDIA_REQUIRE_* 判断GPU的约束条件。 例如 cuda>=9.0 等。 作为 --require= 参数传入 gpu-containers-runtime-hook 做的事情,就是将必要的信息整理为参数,传给 nvidia-container-cli configure 并执行.
nvidia-container-cli 。
项目地址: https://github.com/NVIDIA/libnvidia-container,基于c语言 。
nvidia-container-cli 是一个命令行工具,用于配置Linux容器对GPU 硬件的使用。支持 。
docker 19.03之后,默认支持NVIDIA GPU.
参考文献: https://collabnix.com/introducing-new-docker-cli-api-support-for-nvidia-gpus-under-docker-engine-19-03-0-beta-release/ 。
参考资源: https://kubernetes.io/zh/docs/tasks/manage-gpus/scheduling-gpus/#deploying-amd-gpu-device-plugin 。
Kubernetes 提供了Device Plugin 的机制,用于异构设备的管理场景。原理是会为每个特殊节点上启动一个针对某个设备的DevicePlugin pod, 这个pod需要启动grpc服务, 给kubelet提供一系列接口.
整个 Device Plugin 的工作流程可以分成两个部分:
Device Plugin 的开发主要包括最关注与最核心的两个事件方法:
为了能够在Kubernetes中管理和调度GPU, Nvidia提供了Nvidia GPU的Device Plugin.
项目地址: https://github.com/NVIDIA/k8s-device-plugin 。
主要功能如下:
整个Kubernetes调度GPU的过程如下:
ListAndWatch 接口,上报注册节点的GPU信息和对应的DeviceID。 nvidia.com/gpu 的GPU Pod创建出现,调度器会综合考虑GPU设备的空闲情况,将Pod调度到有充足GPU设备的节点上。 ListAndWatch 接口收到的Device信息,选取合适的设备,DeviceID 作为参数,调用GPU DevicePlugin的 Allocate 接口。 NVIDIA_VISIBLE_DEVICES 环境变量,返回kubelet。 gpu-container-runtime 调用 gpu-containers-runtime-hook 。 gpu-containers-runtime-hook 根据容器的 NVIDIA_VISIBLE_DEVICES 环境变量,转换为 --devices 参数,调用 nvidia-container-cli prestart 。 nvidia-container-cli 根据 --devices ,将GPU设备映射到容器中。 并且将宿主机的Nvidia Driver Lib 的so文件也映射到容器中。 此时容器可以通过这些so文件,调用宿主机的Nvidia Driver。 必要条件:
$ kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.11.0/nvidia-device-plugin.yml
部署守护程序后,可以使用 nvidia.com/gpu 资源类型请求 NVIDIA GPU:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: cuda-container
image: nvcr.io/nvidia/cuda:9.0-devel
resources:
limits:
nvidia.com/gpu: 2 # requesting 2 GPUs
- name: digits-container
image: nvcr.io/nvidia/digits:20.12-tensorflow-py3
resources:
limits:
nvidia.com/gpu: 2 # requesting 2 GPUs
项目地址: https://github.com/RadeonOpenCompute/k8s-device-plugin 。
必要条件:
--allow-privileged=true 对于 kube-apiserver 和 kubelet(仅当设备插件通过 DaemonSet 部署时才需要,因为设备插件容器需要特权安全上下文才能访问 /dev/kfd 设备健康检查) 部署 AMD 设备插件:
kubectl create -f https://raw.githubusercontent.com/RadeonOpenCompute/k8s-device-plugin/r1.10/k8s-ds-amdgpu-dp.yaml
在kubernetes中运行GPU程序,通常都是将一个GPU卡分配给一个容器。这可以实现比较好的隔离性,确保使用GPU的应用不会被其他应用影响;对于深度学习模型训练的场景非常适合; 。
但是如果对于模型开发和模型预测的场景就会比较浪费。很多诉求是能够让更多的预测服务共享同一个GPU卡上,进而提高集群中Nvidia GPU的利用率.
阿里云开源了一个gpushare项目,实现多个pod共享同一块gpu卡.
核心模块:
工作流程(gpushare): 1)GPU Share Device Plugin利用nvml库查询到GPU卡的数量和每张GPU卡的显存, 通过ListAndWatch()将节点的GPU总显存(数量 *显存)作为另外Extended Resource汇报给Kubelet; Kubelet进一步汇报给Kubernetes API Server。 2)Kubernetes默认调度器在进行完所有过滤(filter)行为后会通过http方式调用GPU Share Scheduler Extender的filter方法,找出单卡满足调度条件的节点和卡。 3)当调度器找到满足条件的节点,就会委托GPU Share Scheduler Extender的bind方法进行节点和Pod的绑定。 4)当Pod和节点绑定的事件被Kubelet接收到后,Kubelet就会在节点上创建真正的Pod实体,在这个过程中, Kubelet会调用GPU Share Device Plugin的Allocate方法, Allocate方法的参数是Pod申请的gpu-mem.
最后此篇关于kubernetes集成GPU原理的文章就讲到这里了,如果你想了解更多关于kubernetes集成GPU原理的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
27
4
 0
0
core@core-1-94 ~ $ kubectl exec -it busybox -- nslookup kubernetesServer: 10.100.0.10Address 1: 1
我有一个节点错误地注册在集群 B 上,而它实际上为集群 A 服务。 这里“在集群 B 上注册”意味着我可以从 kubectl get node 看到节点来自集群 B。 我想从集群 B 中取消注册这个节
据我所知,Kubernetes 是一个用于部署和管理容器的编排框架。另一方面,Kubernetes Engine 负责集群的伸缩,以及管理容器镜像。 从上面看,它们似乎是同一件事或非常相似。从上面的定
我正在学习 Kubernetes 和 Docker,以启动一个简单的 Python 网络应用程序。我对上述所有技术都不熟悉。 下面是我计划的方法: 安装 Kubernetes。 在本地启动并运行集群。
我了解如何在 kubernetes 中设置就绪探测器,但是是否有任何关于在调用就绪探测器时微服务应实际检查哪些内容的最佳实践?两个具体例子: 一个面向数据库的微服务,如果没有有效的数据库连接,几乎所有
Kubernetes 调度程序是仅根据请求的资源和节点在服务器当前快照中的可用资源将 Pod 放置在节点上,还是同时考虑节点的历史资源利用率? 最佳答案 在官方Kubernetes documenta
我们有多个环境,如 dev、qa、prepod 等。我们有基于环境的命名空间。现在我们将服务命名为 environment 作为后缀。例如。, apiVersion: apps/v1
我有一个关于命名空间的问题,并寻求您的专业知识来消除我的疑虑。 我对命名空间的理解是,它们用于在团队和项目之间引入逻辑边界。 当然,我在某处读到命名空间可用于在同一集群中引入/定义不同的环境。 例如测
我知道角色用于授予用户或服务帐户在特定命名空间中执行操作的权限。 一个典型的角色定义可能是这样的 kind: Role apiVersion: rbac.authorization.k8s.io/v1
我正在学习 Kubernetes,目前正在深入研究高可用性,虽然我知道我可以使用本地(或远程)etcd 以及一组高可用性的控制平面(API 服务器、 Controller 、调度程序)来设置minio
两者之间有什么实际区别?我什么时候应该选择一个? 例如,如果我想让我的项目中的开发人员仅查看 pod 的日志。似乎可以通过 RoleBinding 为服务帐户或上下文分配这些权限。 最佳答案 什么是服
根据基于时间的计划执行容器或 Pod 的推荐方法是什么?例如,每天凌晨 2 点运行 10 分钟的任务。 在传统的 linux 服务器上,crontab 很容易工作,而且显然在容器内部仍然是可能的。然而
有人可以帮助我了解服务网格本身是否是一种入口,或者服务网格和入口之间是否有任何区别? 最佳答案 “入口”负责将流量路由到集群中(来自 Docs:管理对集群中服务的外部访问的 API 对象,通常是 HT
我是 kubernetes 集群的新手。我有一个简单的问题。 我在多个 kubernetes 集群中。 kubernetes 中似乎有多个集群可用。所以 kubernetes 中的“多集群”意味着:
我目前正在使用Deployments管理我的K8S集群中的Pod。 我的某些部署需要2个Pod /副本,一些部署需要3个Pod /副本,而有些部署只需要1个Pod /副本。我遇到的问题是只有一个 po
我看过官方文档:https://kubernetes.io/docs/tasks/setup-konnectivity/setup-konnectivity/但我还是没明白它的意思。 我有几个问题:
这里的任何人都有在 kubernetes 上进行批处理(例如 spring 批处理)的经验?这是个好主意吗?如果我们使用 kubernetes 自动缩放功能,如何防止批处理处理相同的数据?谢谢你。 最
我有一个具有 4 个节点和一个主节点的 Kubernetes 集群。我正在尝试在所有节点中运行 5 个 nginx pod。目前,调度程序有时在一台机器上运行所有 pod,有时在不同的机器上运行。 如
我在运行 Raspbian Stretch 的 Raspberry PI 3 上使用以下命令安装最新版本的 Kubernetes。 $ curl -s https://packages.cloud.g
container port 与 Kubernetes 容器中的 targetports 有何不同? 它们是否可以互换使用,如果可以,为什么? 我遇到了下面的代码片段,其中 containerPort

我是一名优秀的程序员,十分优秀!