
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 24
24
 4
4


本文介绍基于 Python 中 ArcPy 模块,实现大量 HDF格式 栅格图像文件 批量转换 为 TIFF格式 的方法.
首先,来看看我们想要实现的需求.
在一个名为 HDF 的文件夹下,有五个子文件夹;每一个子文件夹中,都存储了大量的 .hdf 格式的栅格遥感影像数据.
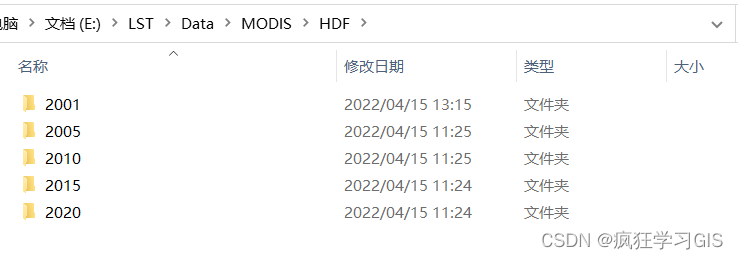
我们在其中任选一个子文件夹,来看看其中所含的文件.
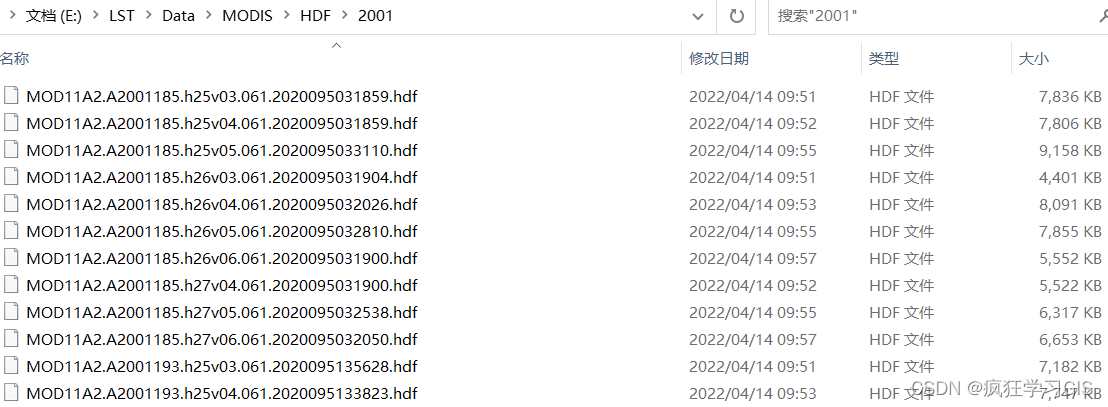
我们要做的,就是将 HDF 文件夹下的 全部子文件夹中 的 全部 .hdf 格式图像文件,一次性转换为 .tif 格式的图像文件,并存储在另一个名为 TIFF 的文件夹中.
知道了具体需求,就可以开始操作了。首先,这里用到的代码如下.
# -*- coding: utf-8 -*-
"""
Created on Fri Apr 15 11:13:27 2022
@author: fkxxgis
"""
import os
import arcpy
hdf_file_path="E:/LST/Data/MODIS/HDF/"
tif_file_path="E:/LST/Data/MODIS/TIFF/"
hdf_file_name_list=os.listdir(hdf_file_path)
for hdf_file in hdf_file_name_list:
if os.path.isdir(hdf_file_path+hdf_file):
file_name_temp=hdf_file
hdf_file_name_list_new=os.listdir(hdf_file_path+hdf_file)
for hdf_file in hdf_file_name_list_new:
tif_file_name=hdf_file[8:23]+".tif"
data=arcpy.ExtractSubDataset_management(hdf_file_path+file_name_temp+'/'+hdf_file,tif_file_path+tif_file_name,"0;4")
else:
tif_file_name=hdf_file[8:23]+".tif"
data=arcpy.ExtractSubDataset_management(hdf_file_path+hdf_file,tif_file_path+tif_file_name,"0;4")
其中, hdf_file_path 是 .hdf 格式文件的存储路径, tif_file_path 是 .tif 格式文件的存储路径,换句话说也就是我们的结果保存路径.
首先,通过 os.listdir() 函数获取 HDF 文件夹下全部文件;由于我们的 .hdf 格式文件并不是直接保存在 HDF 这个大文件夹下的,而是 HDF 下属的多个 子文件夹 下,所以进一步通过 os.path.isdir() 函数进入这些子文件夹,并遍历其中的 .hdf 格式文件,保存在 hdf_file_name_list_new 中;随后,依据每一个 .hdf 格式文件的名称,依次配置之后我们生成的 .tif 格式文件的名称.
接下来,我们就可以通过 arcpy.ExtractSubDataset_management() 函数来实现图像格式的转换了。其中,这一函数的第一个参数是原有 .hdf 文件的路径及名称,第二个参数是我们希望生成的 .tif 文件的路径及名称,第三个参数是我们希望在格式转换时,保存的具体波段.
需要着重说明一下这里 保存波段 的选取。在本文中,我需要转换格式的是 MODIS 的地表温度产品 MOD11A2 ,其第一个波段(编号为 0 )是地表白天的温度,第五个波段(编号为 4 )是地表夜晚的温度,如下图所示.
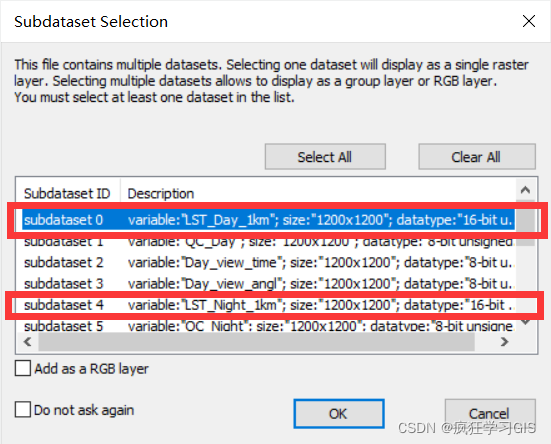
假如在后续处理中,我只需要白天、夜晚这两个波段,也就是编号为 0 和 4 的这两个波段,那么我就只需要在 arcpy.ExtractSubDataset_management() 函数的第三个参数中输入 "0;4" 就好了;其他情况以此类推.
以上便是本次操作的全部代码。我们这里选择在 IDLE (Python GUI) 中运行代码.
得到结果文件如下图;可以看到,所有图像都已经以 .tif 的格式保存了.
至此,大功告成.
最后此篇关于HDF格式遥感影像批量转为TIFF格式:ArcPy实现的文章就讲到这里了,如果你想了解更多关于HDF格式遥感影像批量转为TIFF格式:ArcPy实现的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
24
4
 0
0
背景: 我最近一直在使用 JPA,我为相当大的关系数据库项目生成持久层的轻松程度给我留下了深刻的印象。 我们公司使用大量非 SQL 数据库,特别是面向列的数据库。我对可能对这些数据库使用 JPA 有一
我已经在我的 maven pom 中添加了这些构建配置,因为我希望将 Apache Solr 依赖项与 Jar 捆绑在一起。否则我得到了 SolarServerException: ClassNotF
interface ITurtle { void Fight(); void EatPizza(); } interface ILeonardo : ITurtle {
我希望可用于 Java 的对象/关系映射 (ORM) 工具之一能够满足这些要求: 使用 JPA 或 native SQL 查询获取大量行并将其作为实体对象返回。 允许在行(实体)中进行迭代,并在对当前
好像没有,因为我有实现From for 的代码, 我可以转换 A到 B与 .into() , 但同样的事情不适用于 Vec .into()一个Vec . 要么我搞砸了阻止实现派生的事情,要么这不应该发
在 C# 中,如果 A 实现 IX 并且 B 继承自 A ,是否必然遵循 B 实现 IX?如果是,是因为 LSP 吗?之间有什么区别吗: 1. Interface IX; Class A : IX;
就目前而言,这个问题不适合我们的问答形式。我们希望答案得到事实、引用资料或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visit the
我正在阅读标准haskell库的(^)的实现代码: (^) :: (Num a, Integral b) => a -> b -> a x0 ^ y0 | y0 a -> b ->a expo x0
我将把国际象棋游戏表示为 C++ 结构。我认为,最好的选择是树结构(因为在每个深度我们都有几个可能的移动)。 这是一个好的方法吗? struct TreeElement{ SomeMoveType
我正在为用户名数据库实现字符串匹配算法。我的方法采用现有的用户名数据库和用户想要的新用户名,然后检查用户名是否已被占用。如果采用该方法,则该方法应该返回带有数据库中未采用的数字的用户名。 例子: “贾
我正在尝试实现 Breadth-first search algorithm , 为了找到两个顶点之间的最短距离。我开发了一个 Queue 对象来保存和检索对象,并且我有一个二维数组来保存两个给定顶点
我目前正在 ika 中开发我的 Python 游戏,它使用 python 2.5 我决定为 AI 使用 A* 寻路。然而,我发现它对我的需要来说太慢了(3-4 个敌人可能会落后于游戏,但我想供应 4-
我正在寻找 Kademlia 的开源实现C/C++ 中的分布式哈希表。它必须是轻量级和跨平台的(win/linux/mac)。 它必须能够将信息发布到 DHT 并检索它。 最佳答案 OpenDHT是
我在一本书中读到这一行:-“当我们要求 C++ 实现运行程序时,它会通过调用此函数来实现。” 而且我想知道“C++ 实现”是什么意思或具体是什么。帮忙!? 最佳答案 “C++ 实现”是指编译器加上链接
我正在尝试使用分支定界的 C++ 实现这个背包问题。此网站上有一个 Java 版本:Implementing branch and bound for knapsack 我试图让我的 C++ 版本打印
在很多情况下,我需要在 C# 中访问合适的哈希算法,从重写 GetHashCode 到对数据执行快速比较/查找。 我发现 FNV 哈希是一种非常简单/好/快速的哈希算法。但是,我从未见过 C# 实现的
目录 LRU缓存替换策略 核心思想 不适用场景 算法基本实现 算法优化
1. 绪论 在前面文章中提到 空间直角坐标系相互转换 ,测绘坐标转换时,一般涉及到的情况是:两个直角坐标系的小角度转换。这个就是我们经常在测绘数据处理中,WGS-84坐标系、54北京坐标系
在软件开发过程中,有时候我们需要定时地检查数据库中的数据,并在发现新增数据时触发一个动作。为了实现这个需求,我们在 .Net 7 下进行一次简单的演示. PeriodicTimer .
二分查找 二分查找算法,说白了就是在有序的数组里面给予一个存在数组里面的值key,然后将其先和数组中间的比较,如果key大于中间值,进行下一次mid后面的比较,直到找到相等的,就可以得到它的位置。

我是一名优秀的程序员,十分优秀!