
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 28
28
 4
4


Celery介绍、安装、基本使用
什么是Celery
Celery是一个简单、灵活且可靠的,处理消息的分布式系统 。
Celery的运行原理
# 注:会有两个服务同时运行
- 项目服务
- celery服务
项目服务将需要异步处理的任务交给celery服务,celery就会在需要时异步完成项目的需求
'''
人是一个独立运行的服务 | 医院也是一个独立运行的服务
正常情况下,人可以完成所有健康情况的动作,不需要医院的参与;但当人生病时,就会被医院接收,解决人生病问题
人生病的处理方案交给医院来解决,所有人不生病时,医院独立运行,人生病时,医院就来解决人生病的需求
'''
消息中间件: broker 。
任务执行单元: worker 。
结果储存: backend 。
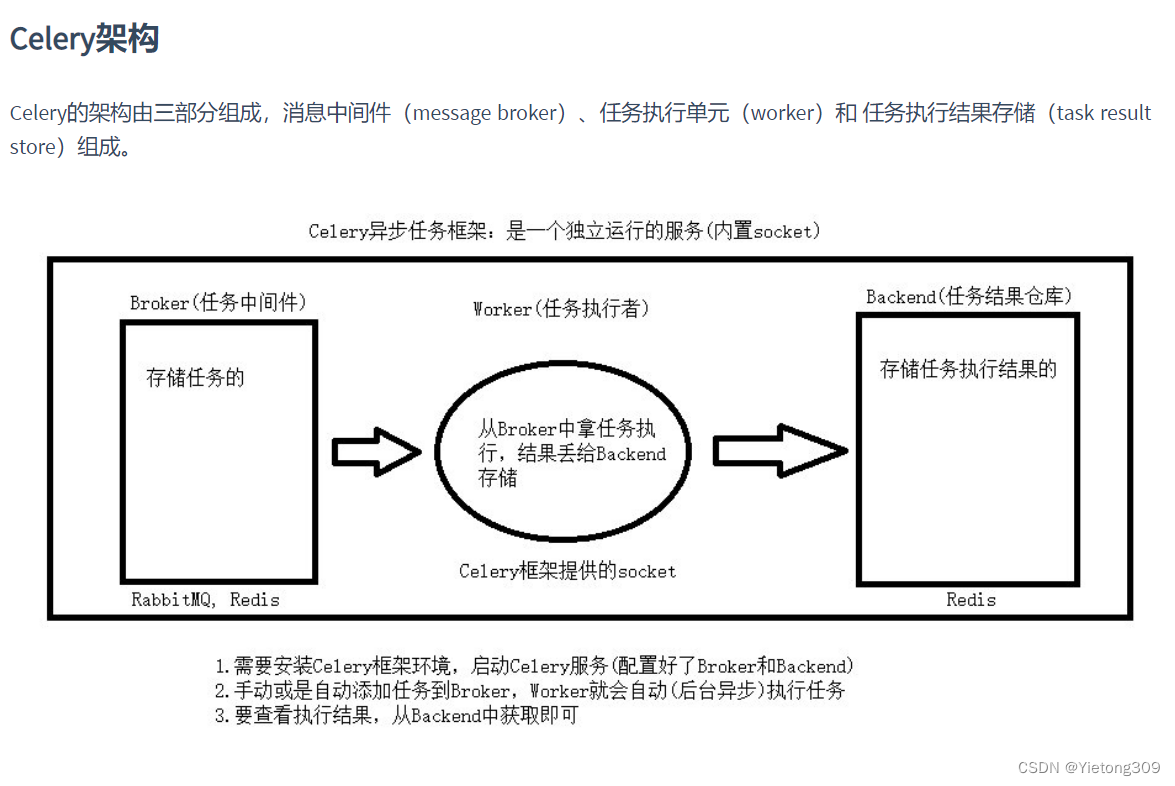
使用场景:
Celery不支持在windows上直接运行,通过eventlet支持在win上运行 。
安装:
pip install celery
pip install eventlet # windows需要安装
快速使用:
- 1、第一步:创建一个py文件(main.py),用于实例化celery对象,编写需要执行的函数
# 1、导入模块
from celery import Celery
# 2、指定briker,用于存放提交的异步任务
broker = 'redis://127.0.0.1:6379/1'
# 3、指定backend,用于存放函数执行结束的结果
backend = 'redis://127.0.0.1:6379/2'
# 实例化celery对象
app = Celery('test', broker=broker, backend=backend)
# 编写一个函数,装饰上celery对象
@app.task
def add(a, b):
import time
time.sleep(3)
print('add函数执行完成')
return a + b
- 2、第二步:再次创建一个py文件(run.py),用于将函数提交给celery
# 1、导入刚才编写的函数
from main import add
# 2、将任务提交给broker,函数需要的参数需要传入
res = add.delay(1, 2)
# 3、提交后可以获得该任务的ID,可通过ID可以查询任务执行结果
print(res) # 0213d2c2-453e-41a8-a171-e31f1f2f4883
- 3、第三步:使用命令开启worker (也可以提前开启,任务提交后就会直接执行)
# 启动worker命令,win需要安装eventlet
# 启动需要进入main.py文件的目录下
win:
-4.x之前版本
celery worker -A main -l info -P eventlet
-4.x之后
celery -A main worker -l info -P eventlet
mac:
celery -A main worker -l info
- 4、第四步:worker会将执行的结果存在之前指定的broker目录下(指定的redis数据库)
- 5、第五步:通过代码查看执行结果(创建新的py文件,专门用于查看执行结果)
# 1、导入celery实例的对象
from main import app
# 2、导入该模块用于查看结果
from celery.result import AsyncResult
# 3、将提交的任务编号拿过来,用于查询结果
id = '0213d2c2-453e-41a8-a171-e31f1f2f4883'
# 4、指定该文件为启动文件
if __name__ == '__main__':
# 实例化对象,将任务的ID和celery实例化对象当作参数传入
a = AsyncResult(id=id, app=app)
# 判断执行结果
if a.successful(): # 执行完了
result = a.get()
print(result)
elif a.failed():
print('任务失败')
elif a.status == 'PENDING':
print('任务等待中被执行')
elif a.status == 'RETRY':
print('任务异常后正在重试')
elif a.status == 'STARTED':
print('任务已经开始被执行')
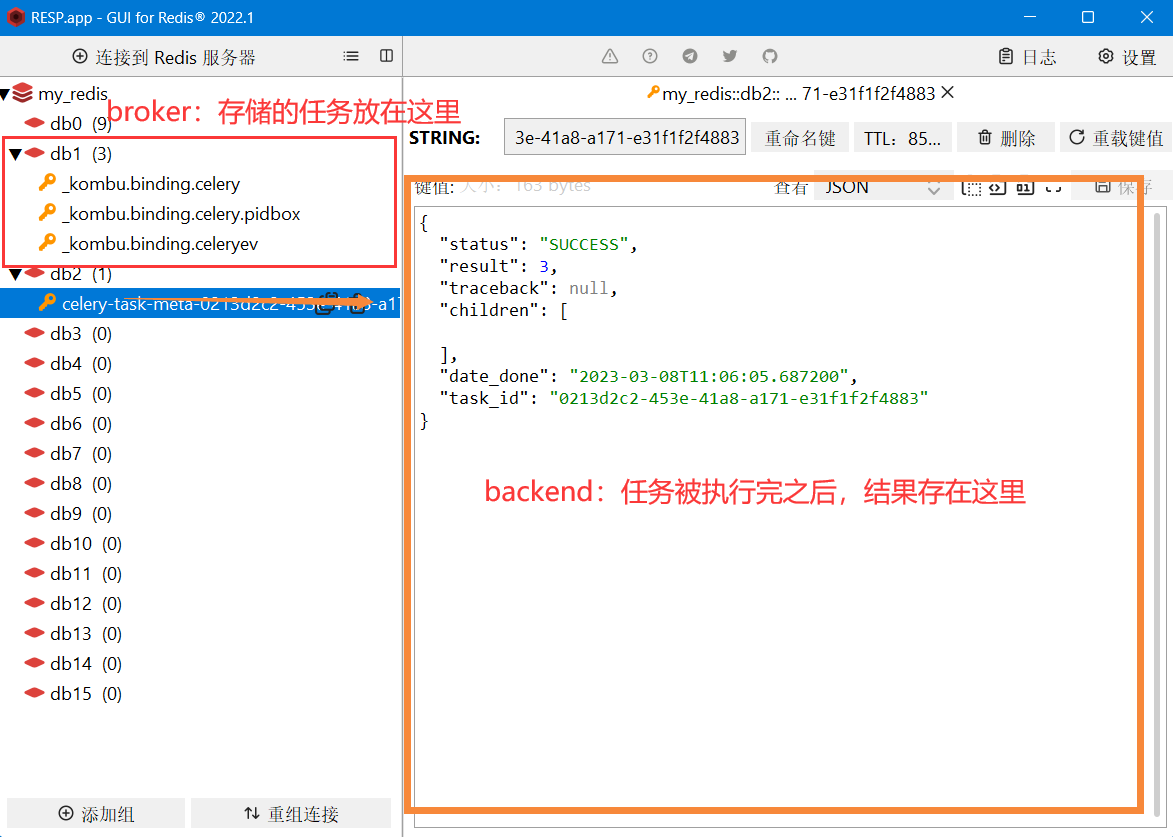
什么是包结构: 通过将celery服务封装成包的形式,放在项目需要使用的时候导入即可 。
project
├── celery_task # celery包
│ ├── __init__.py # 包文件
│ ├── celery.py # celery连接和配置相关文件,且名字必须交celery.py
│ └── tasks.py # 所有任务函数
├── add_task.py # 添加任务
└── get_result.py # 获取结果
创建包:
创建一个包,名为:celery_task 。
- 1、第一步:在包下创建py文件(名字必须为celery.py)
# 导入celery模块
from celery import Celery
# 导入配置broker和backend
from .settings import BACKEND, BROKER
# 实例化celery对象
app = Celery('test',
broker=BROKER,
backend=BACKEND,
include=['celery_task.order_task',
'celery_task.user_task'])
- 2、第二步:创建settings.py,用于存放配置
BROKER = 'redis://127.0.0.1:6379/1'
BACKEND = 'redis://127.0.0.1:6379/2'
- 3、第三步,创建py文件(task.py),用于存放需要执行的异步任务
# 导入celery实例对象
from .celery import app
# 计算函数
@app.task()
def add(a, b):
print('计算结果为:', a + b)
return True
# 模拟发送短信
@app.task()
def send_sms(mobile, code):
print('已向手机号:%s 发送短信,验证码为:%s' % (mobile, code))
return True
- 4、第四步:开启worker
切换到celery所在的目录下,开启worker命令
celery -A celery_task worker -l info -P eventlet
- 5、第五步:提桥任务: # add_task.py 文件下
# 提交任务,这里模拟的是异步任务的提交
res = add.delay(a, b) # 提交后可以接收任务的ID
res1 = send_sms.delay(mobile, code)
- 6、第六步:查看任务执行结果: # get_result.py 文件下
# 导入celery实例
from celery_task.celery import app
from celery.result import AsyncResult
id = res
id1 = res1
# 通过传入任务的ID就可以查询到任务的执行结果
def res_func(id):
id = id
a = AsyncResult(id=id, app=app)
if a.successful(): # 执行完了
result = a.get()
if result: return '执行完成'
elif a.failed():
return '任务失败,失败的原因可能是未开启worker'
elif a.status == 'PENDING':
return '任务等待中被执行,当前任务较多或未开启worker'
elif a.status == 'RETRY':
return '任务异常后正在重试'
elif a.status == 'STARTED':
return '任务已经开始被执行,请稍后查询'
执行异步任务:
# 代码用法:
函数名.delay('函数执行需要的参数')
res = func.delay(*args,**kwargs) # res 用于接收提交任务的ID
执行延迟任务:
# 代码用法:
# 1、执行延迟任务
from datetime import datetime, timedelta
# 设置延迟后的时间,一分钟后执行
eat = datetime.utcnow() + timedelta(minutes=1)
# 提交任务
res = send_sms.apply_async(args=['13855411111', '123'], eta=eta)
执行定时任务:
执行定时任务需要启动beat和worker 。
- 第一步:在celery的py文件中写入
# 导入定时需要的模块
from celery.schedules import crontab
# 第一步:在celery的py文件中写入
app.conf.timezone = 'Asia/Shanghai'
# 是否使用UTC
app.conf.enable_utc = False
# celery的配置文件#####
# 任务的定时配置
app.conf.beat_schedule = {
'send_sms': { # 配置执行函数的名字
'task': 'celery_task.task.send_sms', # 导入任务的位置
# 'schedule': timedelta(seconds=3), # 时间对象
# 'schedule': crontab(hour=8, day_of_week=1), # 每周一早八点
'schedule': crontab(hour=9, minute=43), # 每天9点43
'args': ('18888888', '6666'), # 配置执行函数需要的参数
},
}
- 第二步:启动beat # 启动后配配置的任务会自动提交
celery -A celery_task beat -l info
- 第三步:启动worker # beat提交的任务被被执行
celery -A celery_task worker -l info -P eventlet
补充:
如果在公司中,只做定时任务有一个框架更简单一点 。
使用步骤:
-1 把咱们写的包,复制到项目目录下
-luffy_api
-celery_task #celery的包路径
-luffy_api #源代码路径
-2 在使用提交异步任务的位置,导入使用即可
-视图函数中使用,导入任务
-任务.delay() # 提交任务
-3 启动worker,如果有定时任务,启动beat
-4 等待任务被worker执行
-5 在视图函数中,查询任务执行的结果
后端 。
view.py 。
from celery.result import AsyncResult
from celery_task.celery import app
from celery_task.task import sckill_task
# 秒杀接口
class SeckillView(ViewSet):
# 开启秒杀
@action(methods=['GET'], detail=False)
def seckill(self, request):
# 获取商品链接
goods_id = request.query_params.get('goods_id')
# 将任务提交给worker
res = sckill_task.delay(goods_id)
# 将任务的ID反馈给前端
return APIResponse(task_id=str(res))
# 查询秒杀结果
@action(methods=['GET'], detail=False)
def get_result(self, request):
# 前端将任务ID产过来,用于接收结果
task_id = request.query_params.get('task_id')
# 调用接口,查询结果
a = AsyncResult(id=task_id, app=app)
if a.successful():
result = a.get()
if result:
return APIResponse(msg='秒杀成功')
else:
return APIResponse(code=101, msg='手速满了,秒杀失败')
elif a.status == 'PENDING':
return APIResponse(code=666, msg='加速秒杀中')
return APIResponse(msg='错误')
celery.py ---->秒杀任务 。
import random
# 秒杀函数
@app.task()
def sckill_task(goods_id):
print('商品正在秒杀中')
time.sleep(random.choice([6, 7, 8, 9]))
print('商品秒杀结束')
return random.choice([True, False])
前端:
<template>
<div>
<button @click="clickHandle">点击秒杀</button>
</div>
</template>
<script>
export default {
name: "Template",
data() {
return {
// 用于接收任务ID
task_id: '',
// 用户存放定时任务
t: ''
}
},
methods: {
// 用户点击秒杀后发送请求
clickHandle() {
// 向厚点提交秒杀任务
this.$axios.get(this.$settings.BASE_URL + '/user/seckill/seckill/?goods_id=1').then(res => {
// 判断任务是否提交成功
if (res.data.code == 100) {
// 提交成功会获取到任务ID
this.task_id = res.data.task_id
// 告知用户商品正在秒杀中
this.$message('正在秒杀中')
// 启动一个定时任务,每隔3秒向后端发送请求,获取任务是否提交成功
this.t = setInterval(res => {
// 定时向后端发送请求,判断秒杀结果
this.$axios.get(this.$settings.BASE_URL + '/user/seckill/get_result/?task_id=' + this.task_id).then(res => {
// 判断任务是否结束
if (res.data.code == 666) {
this.$message(res.data.msg)
// 任务结束反馈结果,关闭定时器
} else {
this.$message(res.data.msg)
// 关闭定时器
clearInterval(this.t)
this.t = ''
}
})
}, 3000)
}
})
}
}
}
</script>
-luffy_api
-celery_task #celery的包路径
celery.py # 一定不要忘了一句话
import os
# 重点:celery中使用djagno,任务中可能会使用django的orm,缓存,表模型。。。。一定要加
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'luffy_api.settings.dev')
-luffy_api #源代码路径
-视图函数中使用,导入任务
-任务.delay() # 提交任务
第三步:启动worker,如果有定时任务,启动beat 。
第四步: 等待任务被worker执行 。
第五步:在视图函数中,查询任务结果 。
最后此篇关于Celery框架从入门到精通的文章就讲到这里了,如果你想了解更多关于Celery框架从入门到精通的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
28
4
 0
0
正则表达式可以: •测试字符串的某个模式。例如,可以对一个输入字符串进行测试,看在该字符串是否存在一个电话号码模式或一个信用卡号码模式。这称为数据有效性验证 •替换文本。可以在文档中使用一个正则表达
我正在上 udemy 的类(class),我偶然发现了这段更改窗口背景的代码。问题是函数 randColor 失去了我。我想知道到底发生了什么。 我知道声明了一个名为 randColor 的函数,然后
我是一名本科生,最近受雇于今年夏天和明年秋天的合作社。据我所知,我将编写很多我觉得很舒服的 C++,但我并没有特别多的实际编写 C++ 的经验。 我想花时间真正深入研究 C++ 并更加熟练地使用它。在
我是一名使用 ASP.NET、C# 等的 .NET webdev...我 5 多年前在大学里“学习”了 javascript,可以用它做基本的工作。但是我想知道精通它是否有用。 我为什么要学习 Jav
我在 jQuery 方面非常高效,已经在我公司的多个项目中实现了它。然而,当我阅读诸如 node.js 之类的东西时,我发现自己有点迷茫。 我是否必须回到基础学习 JavaScript 语言,还是应该

我是一名优秀的程序员,十分优秀!