
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 30
30
 4
4


服务监控系列文章 。
服务监控系列视频 。
经过上次redis超时排查,并联系云服务商解决之后,redis超时的现象好了一阵子,但是最近又有超时现象报出,但与上次不同的是,这次超时的现象发生在业务高峰期,在简单看过服务器的各项指标以后,发现只有cpu的使用率在高峰期略高,我们是8核cpu,高峰期能达到90%的使用率,其余指标都相对正常.
但究竟是不是cpu占比高的问题导致redis超时的呢?还有待商榷,因为cpu调度程序慢本质上也是个概率性事件.
有了上次的经验过后,我也是联系了云服务商那边也排查下是否还存在上次超时的原因,但其实还是有直觉,这次的原因和上次超时是不一样的(备注:上次超时是由于云服务商那边对集群的流量隔离做的不够好,导致其他企业机器流量影响到了我们的机器,且发生在业务低峰期),这次发生在业务高峰期.
果然,云服务商得出的结论也是之前出问题的机器以及迁移走了,并且他们也和我同时展开排查.
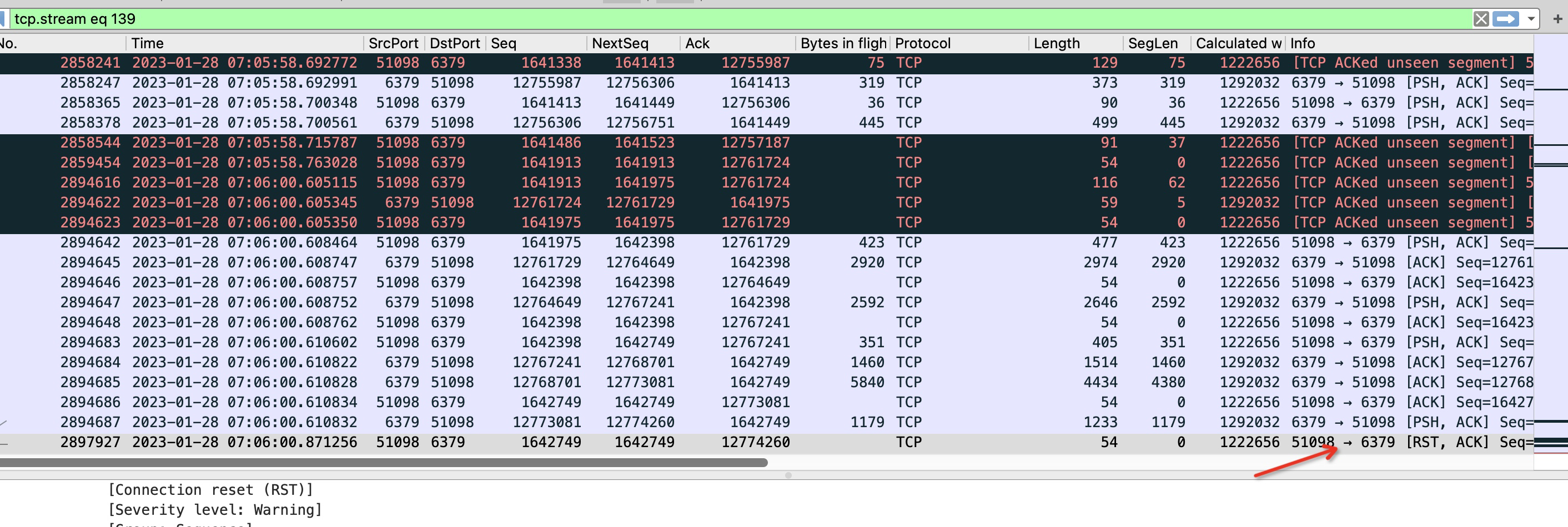
在ecs服务器上进行抓包,当出现超时时,关闭tcpdump进行分析.
在dump下抓包文件后,经过wireshark分析,并没有发现丢包信息,想着应该是tcpdump漏包了.
[webserver@hw-sg1-test-0001 ~]$ sudo tcpdump -i eth0 tcp port 6379 -w p.cap -W 2 -G 3600 -C 2000
tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
可以看到默认的抓包大小262144 bytes,在业务高峰期如果每个包最大长度都在这个值,很可能就导致缓冲区满了,而之前一次抓包分析为什么就没有这个问题呢,因为那是在业务低峰期,tcpdump丢包概率比较小.
sudo tcpdump -i eth0 tcp port 6379 -w p5.cap -W 2 -G 3600 -C 2000
tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
^C147940 packets captured
468554 packets received by filter
318544 packets dropped by kernel
packets dropped by kernel 说明tcpdump丢弃了某些包,因为tcpdump在处理包时,是先将包放到一个缓冲区进行分析,当缓冲区满的时候会直接进行丢弃,这样导致我在用wireshark分析包的时候,就会出现有些包找不到的情况.
[webserver@hw-sg1-backend-0003 ~]$ sudo tcpdump -i eth0 tcp port 6379 -w p5.cap -W 2 -G 3600 -C 2000 -n -s 1520
tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 1520 bytes
^C21334 packets captured
21454 packets received by filter
0 packets dropped by kernel
redis客户端超时时间设置的200ms,可以看到2894687号包是redis服务器发送给客户端的包,然后2897927是客户端发送给redis服务端的rst,正常情况客户端收到redis服务端的psh信号的包应该会回复一个ack的,但是客户端却在200ms以后回复了一个rst,说明了什么问题?
我们的客户端是golang写的,可以想到的情况是,客户端程序在读取包过程协程会有切换上下文操作,当客户端发现有可读包时并切回go协程的时候,会首先判断当前读操作是否超时,如果超时,则直接调用close方法关闭连接了.
那么close方法是发送rst信号吗,正常不应该是fin信号? 非也,close方法如果关闭的时候,连接读缓冲区的数据还有未被应用程序读取的话,那么此时close方法的调用会发送rst信号.
可见,问题的确是出在客户端了,并且看上去像是客户端来不及读取服务端的消息。看到这里,其实我心里已经百分之八九十确定是cpu的使用率达到瓶颈了.
在分析到上一个步骤的时候,云服务商告诉我,他们知道原因了,是ecs服务的磁盘吞吐量达到瞬时上线,说故障点是和超时的故障点是吻合的.
我知道这个后,第一时间的疑惑是,为啥磁盘吞吐会影响到网络传输,云服务商给的解释是磁盘吞吐达到瞬时上线后,对服务整体是有影响的,我又看了下ecs的监控图标,发现监控图标显示的磁盘吞吐远远没有云服务商提到的那么多.
尽管云服务商坚持是磁盘iops达到了上限,但还是不能说服我 磁盘的iops瞬时上限会那么大影响到网络传输.
于是有了接下来第二天的抓包分析.
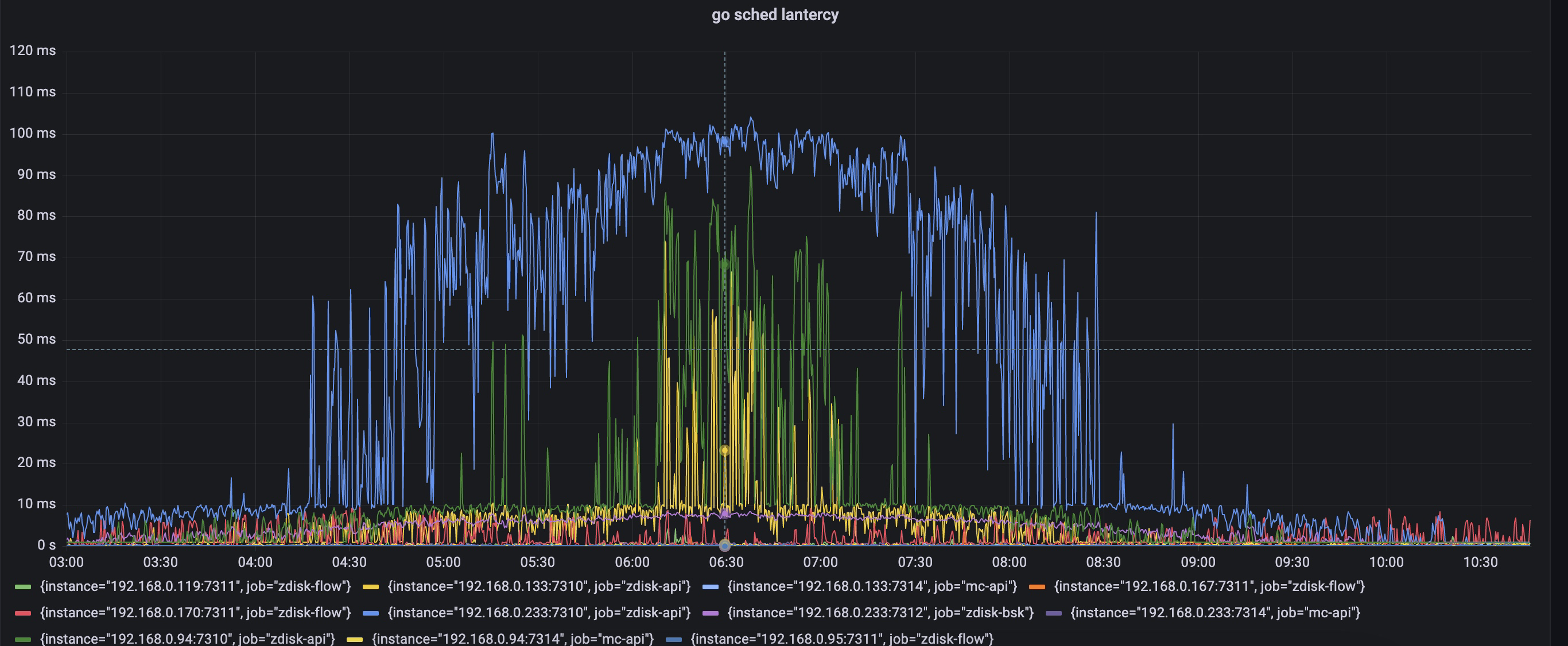
基于对昨天的分析,我怀疑到了cpu头上,如果cpu切换进程缓慢,协程调度缓慢,那么的确是有可能发生超时的。由于目前的监控缺少对协程调度延迟的监控,所以决定加上这一指标.
golang1.17后 runtime包提供了协程调度延迟的直方图统计信息,而go prometheus的client其实以已经支持将这个信息转换为prometheus内置的指标类型,metric名称是go_sched_latencies_seconds,而我们之前试用prometheus的client包注册的collector 是兼容到go1.16以及之前的版本,所以没有当改用到最新的collector后,client如期返回了go_sched_latencies_seconds 直方图信息.
将这个信息展示在grafana里。于是有了第二天协程调度延迟的信息。p999在业务高峰期间达到了100ms,也是与超时时间吻合的。协程调度延迟指的是协程变为可运行状态后到被真正执行这段时间等待被调度的时间,这里都高达100ms了,如果加上cpu线程,进程切换上下文时间,很有可能是超过了redis client端设置的200ms超时上限.
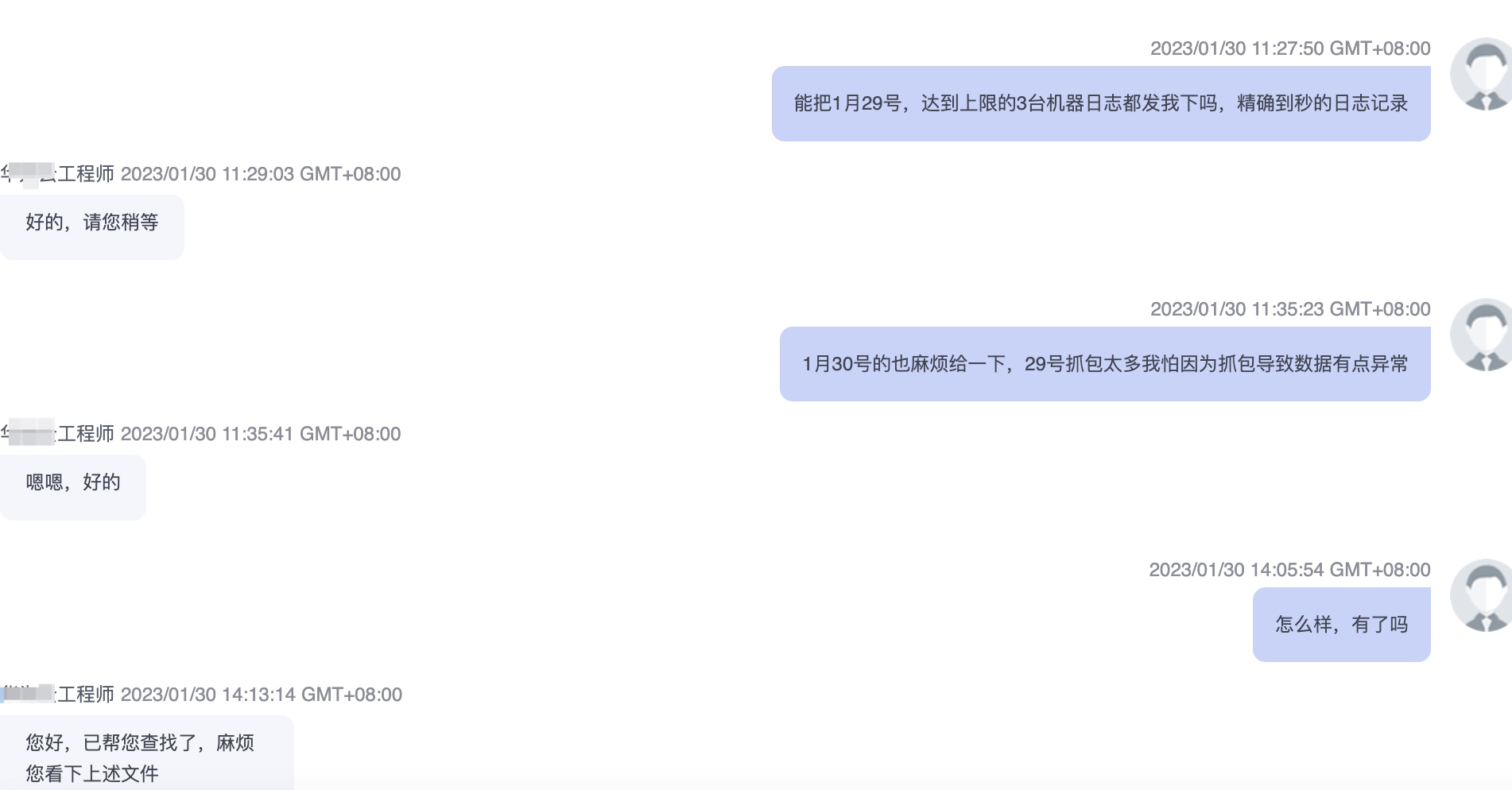
为了排除掉是磁盘原因引起的超时。 我在7点又进行了抓包分析,发现和昨天抓到包的情况是一致的,客户端最后来不及回应服务端的包最后发送rst了。 然后看了下此时机器磁盘吞吐情况,发现图中箭头处也处于高峰期,但是磁盘吞吐量并未上去,而升上去的点正是抓包带来的,怀疑是抓包写入文件导致磁盘吞吐量涨上去了。于是又问了服务商要磁盘达到瞬时峰值的日志.
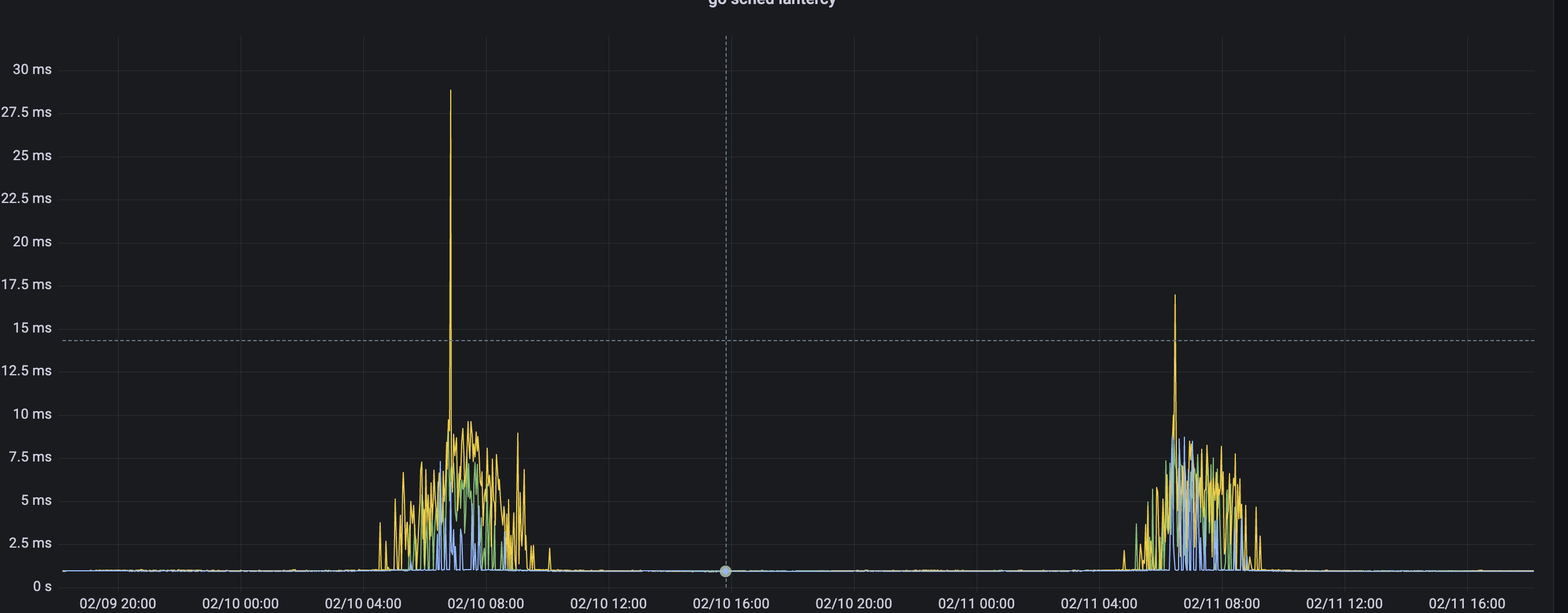
发现报瞬时峰值的日志也和抓包时间吻合,所以已经确认磁盘吞吐达到上限是抓包导致的,网络超时是和磁盘吞吐无关的,反而应该是cpu使用率达到上限了,虽然没有100%,也是8核,但毕竟cpu某个核达到上限是概率性事件,而对于redis这种时延敏感性应用,一但发生,那么超时是有可能的.
于是,在业务低峰期将我们三台ecs服务进行了cpu配置提升,提升后效果很明显,超时在高峰期不见了,协程调度延迟也大大减少.
1,对于抓包分析,还是疏忽了,加上包限制大小,能很好的防止tcpdump抓包时丢包的情况。 2,对于任何第三方的说法要有自己的判断力,像这次如果中途去将磁盘扩容显然是不能解决问题的。 3,性能问题分析真是像一个侦探破案的过程,不断列出证据,不断排除掉干扰因素,不断论证的过程也是性能分析的魅力所在吧,就像这次看到cpu的确比较高了,但是究竟是不是客户端问题呢?我又抓包论证了的确是客户端问题,那究竟是不是协程调度问题呢?我又列出协程调度延迟.
最后此篇关于我又和redis超时杠上了的文章就讲到这里了,如果你想了解更多关于我又和redis超时杠上了的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
30
4
 0
0
我有一个关于 Redis Pubsub 的练习,如下所示: 如果发布者发布消息但订阅者没有收到服务器崩溃。订阅者如何在重启服务器时收到该消息? 请帮帮我,谢谢! 最佳答案 在这种情况下,消息将永远消失
我们正在使用 Service Stack 的 RedisClient 的 BlockingDequeue 来保存一些数据,直到它可以被处理。调用代码看起来像 using (var client =
我有一个 Redis 服务器和多个 Redis 客户端。每个 Redis 客户端都是一个 WebSocket+HTTP 服务器,其中包括管理 WebSocket 连接。这些 WebSocket+HTT
我有多个 Redis 实例。我使用不同的端口创建了一个集群。现在我想将数据从预先存在的 redis 实例传输到集群。我知道如何将数据从一个实例传输到集群,但是当实例多于一个时,我无法做到这一点。 最佳
配置:三个redis集群分区,跨三组一主一从。当 Master 宕机时,Lettuce 会立即检测到中断并开始重试。但是,Lettuce 没有检测到关联的 slave 已经将自己提升为 master
我想根据从指定集合中检索这些键来删除 Redis 键(及其数据集),例如: HMSET id:1 password 123 category milk HMSET id:2 password 456
我正在编写一个机器人(其中包含要禁用的命令列表),用于监视 Redis。它通过执行禁用命令,例如 (rename-command ZADD "")当我重新启动我的机器人时,如果要禁用的命令列表发生变化
我的任务是为大量听众使用发布/订阅。这是来自 docs 的订阅的简化示例: r = redis.StrictRedis(...) p = r.pubsub() p.subscribe('my-firs
我一直在阅读有关使用 Redis 哨兵进行故障转移的内容。我打算有1个master+1个slave,如果master宕机超过1分钟,就把slave变成master。我知道这在 Sentinel 中是
与仅使用常规 Redis 和创建分片相比,使用 Redis 集群有哪些优势? 在我看来,Redis Cluster 更注重数据安全(让主从架构解决故障)。 最佳答案 我认为当您需要在不丢失任何数据的情
由于 Redis 以被动和主动方式使 key 过期, 有没有办法得到一个 key ,即使它的过期时间已过 (但 在 Redis 中仍然存在 )? 最佳答案 DEBUG OBJECT myKey 将返回
我想用redis lua来实现monitor命令,而不是redis-cli monitor。但我不知道怎么办。 redis.call('monitor') 不起作用。 最佳答案 您不能从 Redis
我读过 https://github.com/redisson/redisson 我发现有几个 Redis 复制设置(包括对 AWS ElastiCache 和 Azure Redis 缓存的支持)
Microsoft.AspNet.SignalR.Redis 和 StackExchange.Redis.Extensions.Core 在同一个项目中使用。前者需要StackExchange.Red
1. 认识 Redis Redis(Remote Dictionary Server)远程词典服务器,是一个基于内存的键值对型 NoSQL 数据库。 特征: 键值(key-value)型,value
1. Redis 数据结构介绍 Redis 是一个 key-value 的数据库,key 一般是 String 类型,但 value 类型多种多样,下面就举了几个例子: value 类型 示例 Str
1. 什么是缓存 缓存(Cache) 就是数据交换的缓冲区,是存贮数据的临时地方,一般读写性能较高。 缓存的作用: 降低后端负载 提高读写效率,降低响应时间 缓存的成本: 数据一致性成本 代码维护成本
我有一份记录 list 。对于我的每条记录,我都需要进行一些繁重的计算,因为我要在Redis中创建反向索引。为了达到到达记录,需要在管道中执行多个redis命令(sadd为100 s + set为1
我有一个三节点Redis和3节点哨兵,一切正常,所有主服务器和从属服务器都经过验证,并且哨兵配置文件已与所有Redis和哨兵节点一起更新,但是问题是当Redis主服务器关闭并且哨兵希望选举失败者时再次
我正在尝试计算Redis中存储的消息之间的响应时间。但是我不知道该怎么做。 首先,我必须像这样存储chat_messages的时间流 ZADD conversation:CONVERSATION_ID

我是一名优秀的程序员,十分优秀!