
 个人中心
个人中心 文章发布
文章发布
作者热门文章
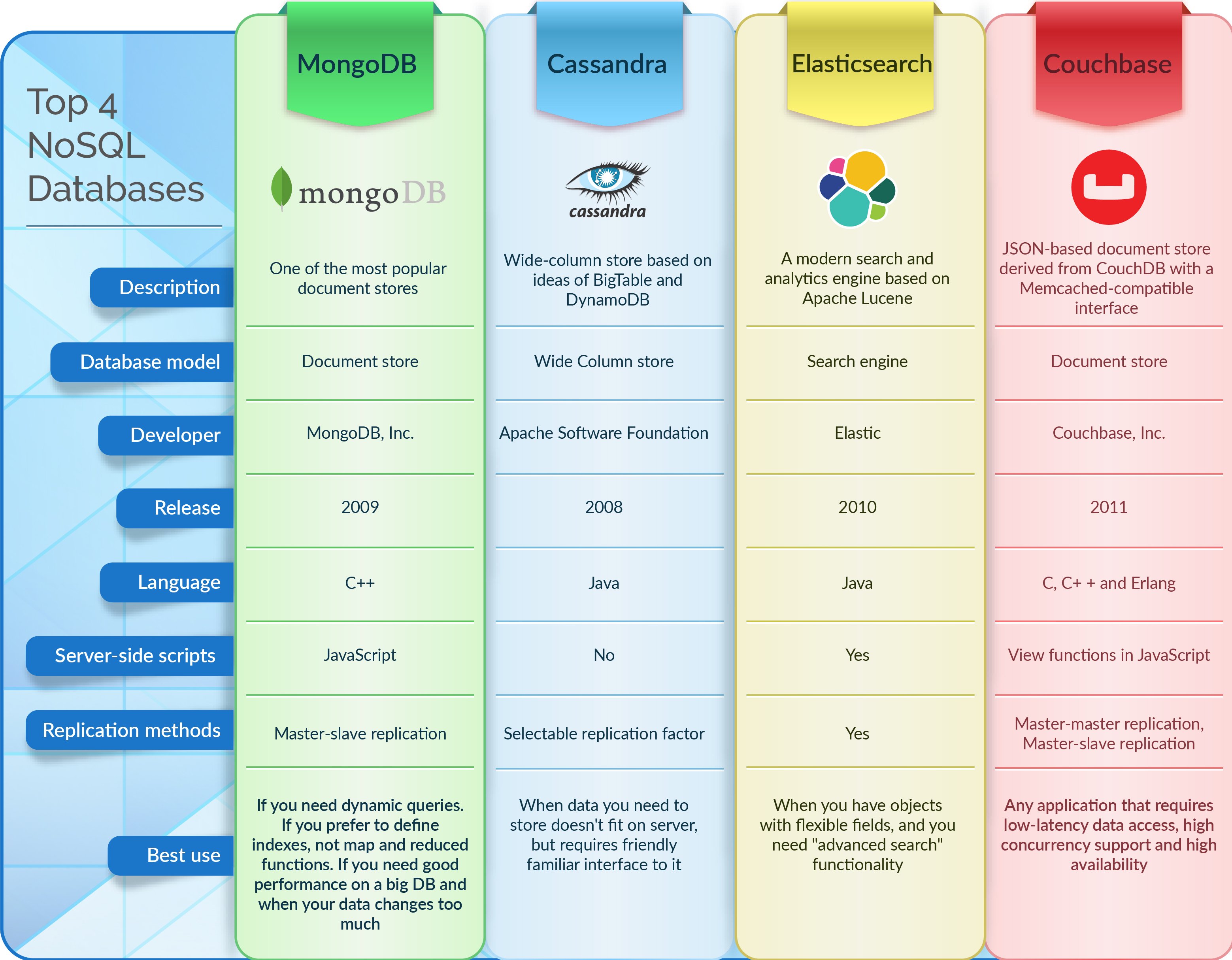
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


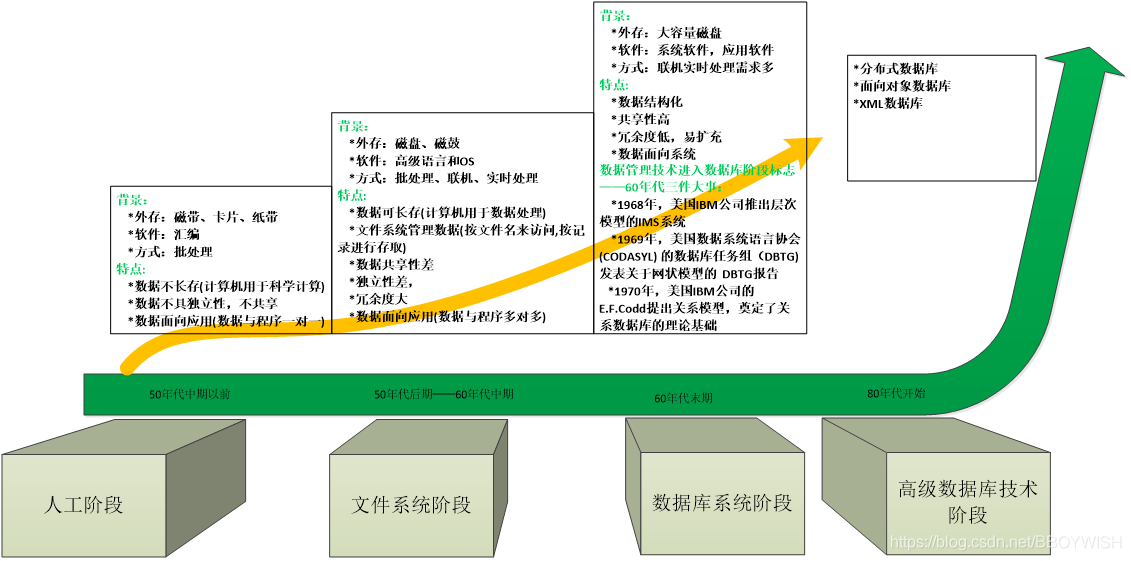
计算机刚开始出现的时候,那时候没有硬盘,只有内存,数据不会进行存储,一般只用于科技计算,计算完输出结果后,程序就撤出内存了。后来随着技术发展,有了硬盘、文件,在文件的基础上有了文件系统。文件系统可以满足数据存放和查找的需求.
文件系统作为数据库用了一段时间,当数据越来越多、规模越来越大后,数据查找特别麻烦。数据很容易重复(冗余)、占用存储空间多,数据结构化被迫推进.
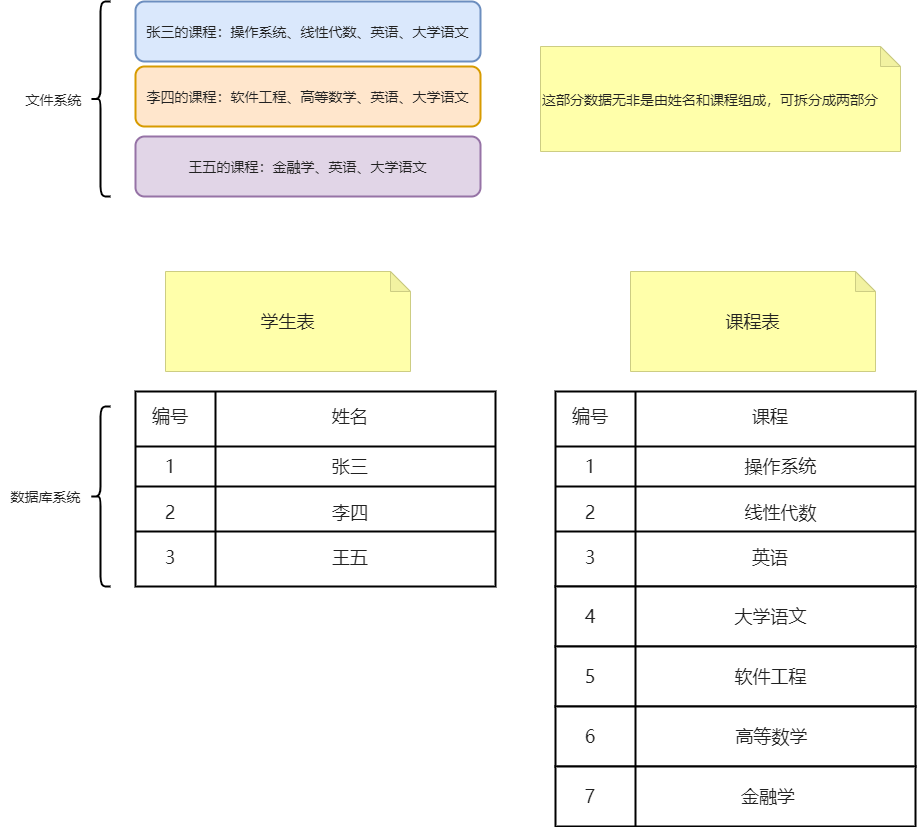
总的来说,数据库顾名思义其实就是存取数据的地方;另外随着时间线的发展产生了不同种类的数据库,但本质技术提升的本质都是为了提升业务性能! 。
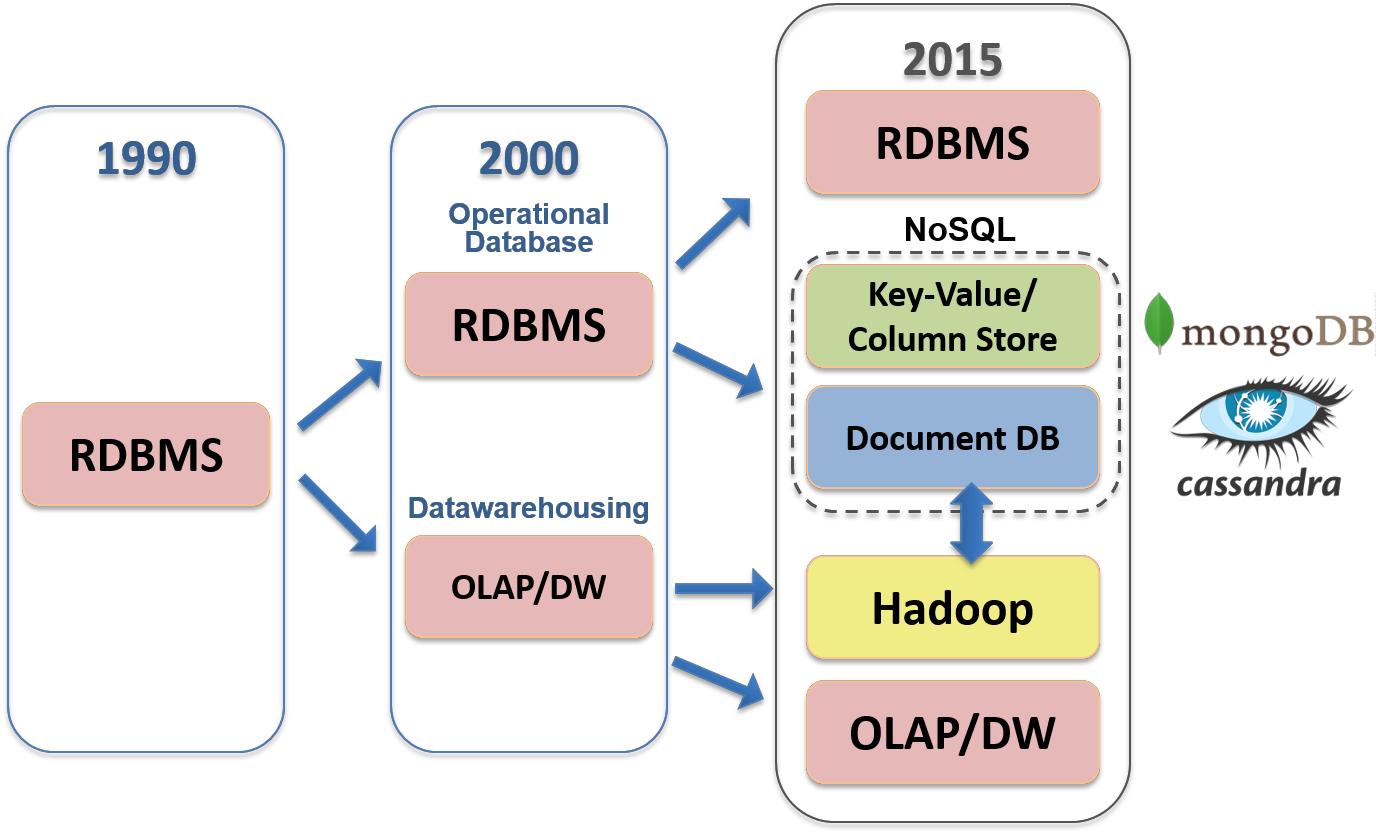

关系型数据库也被称为RDBMS,顾名思义就是信息遵循一种利用表或关系的结构化方法,是一种存储和操作历史数据的经典方法.
SQL这个词既是一种语言,也是数据库的类型。SQL代表结构化查询语言,是数据库设计理念的先驱。自80年代中期以来,SQL一直是管理和查询关系数据集的标准;然而,关系模型的早期雏形可以追溯到60年代和70年代,当时出现了区分应用数据和应用代码的迫切需求,使开发人员能够专注于程序开发的其他方面,如访问和操作手头的数据。IBM的IMS是第一个功能齐全的关系型数据库,尽管设计的目的不同,是为了组织阿波罗太空探索计划的数据。关系数据库是各种程度的时间变化的、规范化的关系的集合。可以做出以下直观的对应.
关系数据库管理系统 (RDBMS) 支持关系(面向二维表)数据模型,表(table) 。
表的架构(关系架构)由表名和具有固定数据类型的固定数量的属性/字段定义,列(column) 。
记录(实体)对应于表中的一行,由每个属性的值组成,行(row) 。
表架构是通过数据建模过程中的规范化生成的 。
可以存储通过键链接多个表的信息,从而创建跨多个表的关系 。
在简单的用例中,键用于检索特定行以便于进行检查或修改 。
结构化查询语言,允许用户访问和操作高度结构化表中的数据 。
记录没有特定的顺序 。
每个字段都是单值的 。
记录有一个唯一的识别字段或复合字段,称为主键字段 。
原子性、一致性、隔离性、持久性以保持交易的可靠性.
一个设计高效数据库的过程 。
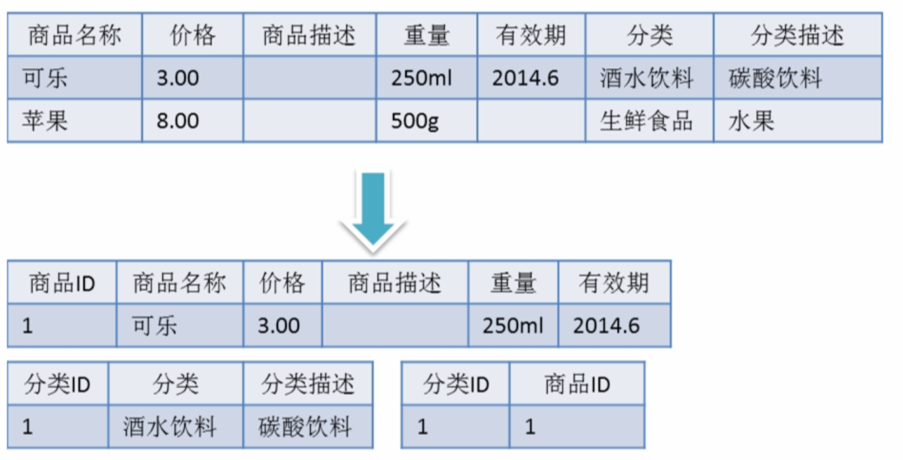
数据库处理不断增长的数据量的能力。垂直扩展有助于增强数据库服务器的现有能力。大多数SQL数据库支持垂直扩展。然而,他们可以扩大规模,而不是缩小规模.
从使用角度来说用户不直接接触数据库,而是通过我们的应用程序与数据库进行交互.
如果用户比较多,发出的请求多了之后,由于我们的数据库是放置在磁盘,而磁盘的性能是比较低的,所以会导致Web应用程序每次到与数据库进行交互之后,用户的响应速度会变慢! 。

解决方案:池化技术,实现资源的复用(降低资源创建销毁的开销) 。

以上是Web应用与数据库连接层面的优化,至于在数据库本身我们也可以进行优化,以提升性能.
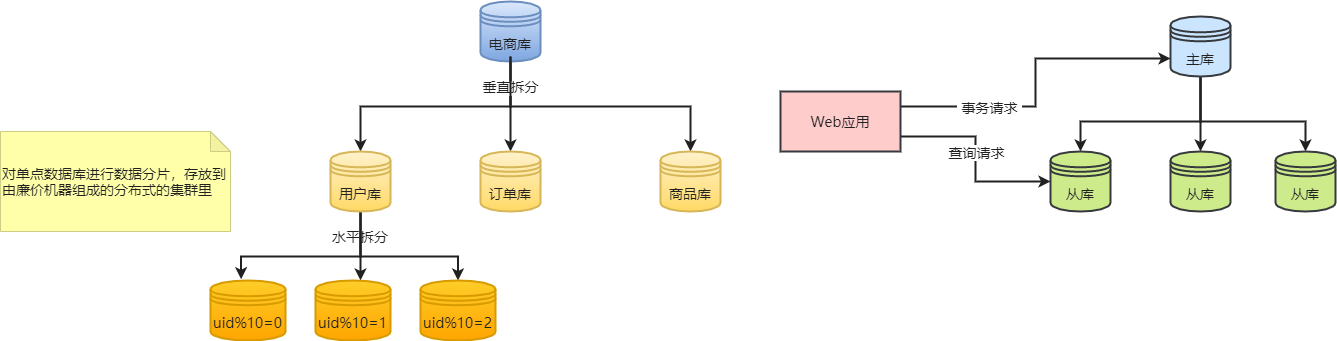
数据分片,使用分布式集群结构等虽然提高了可扩展性更好了,但也带来了新的麻烦 。
1、以前在一个库里的数据,现在跨了多个库,应用系统不能自己去多个库中操作,需要使用数据库分片中间件 。
2、分片中间件做简单的数据操作时还好,但涉及到跨库join、跨库事务时就很头疼了,很多人干脆自己在业务层处理,复杂度较高 。
数据建模的僵化 。
关系型数据库最大的限制之一是将数据组织到表和关系的特定结构中的僵硬性。由于所有的数据都不能方便地装入表格,因此这种方法不能应用于所有的自然数据,也不能以树和图的形式存储,但是,RDBMS通过以父子关系的规范化方式对这些数据进行建模来解决这个限制,这仍然是不够的.
多样性 。
数据的复杂性也给关系型数据库带来了限制。这些数据库是按共同特征来组织数据的。复杂的数字、图像和多媒体数据很难存储、访问和处理.
空间使用效率低下 。
当我们定义关系的模式时,我们定义所有属性的大小。不是所有的记录都有使用全部空间的数据。一些有很短的长度。每条记录不一定又适合给定的数据类型,造成了空间浪费.
沉重的变化 。
一个记录所需的任何改变都需要应用于所有的记录。因此造成了重量级的改变。根据当时存在的记录的大小和数量,这些改变可能是昂贵的,不可行的。因此,改变一个已经存在的数据库的模式是一个挑战.
对大数据来说效率低下 。
SQL不适合数量大、速度快、种类多的数据,使得它在基于云的应用中效率很低.
总结:随着大数据时代的到来,结构化的方法已经无法满足巨大的信息处理需求,这些信息往往是非结构化的。随着时间的推移,SQL已经经历了许多迭代,以支持大量的数据处理和管道。然而,对于期望快速响应和最高可扩展性的大数据系统来说,它仍然是低效的.
关系数据库近期还是非常广泛使用的模型,它们仍然在许多企业得到了广泛采用。然而,面对当今多样化、高速和海量的数据,有时需要用一个高度不同的数据库来补充关系数据库。这促进了 NoSQL 数据库在某些领域的采用,该数据库也称为“非关系数据库”。由于支持快速横向扩展,因此非关系数据库可以处理高流量,这也使其具有很强的适应性。非关系型数据库也即NoSQL(Not Only SQL),目的总结就是高性能,提升可扩展性! 。
优势:
不推荐NoSQL的场景:
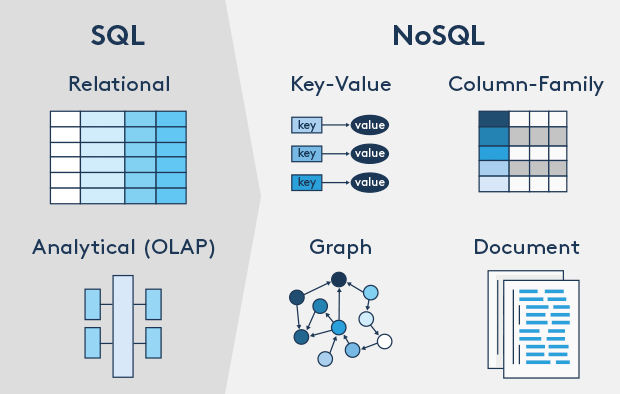
RDBMS 。
NoSQL 。
不仅仅是SQL 。
没有声明性查询语言 。
没有预定义的模式 。
键 - 值对存储,列存储,文档存储,图形数据库 。
最终一致性,而非ACID属性 。
非结构化和不可预知的数据 。
CAP定理 。
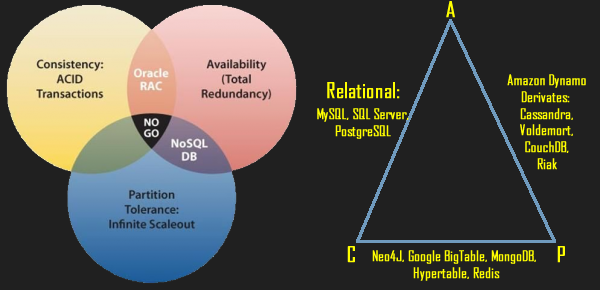
BASE原则 。
高性能,高可用性和可伸缩性 。
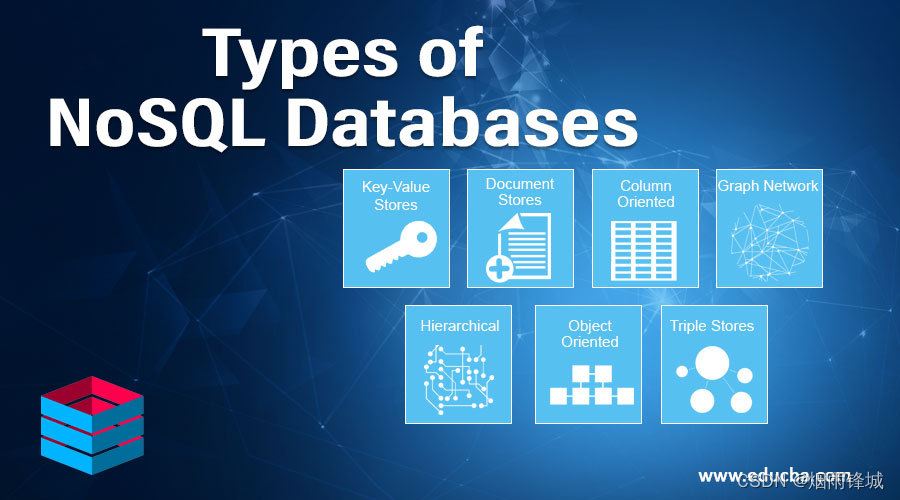
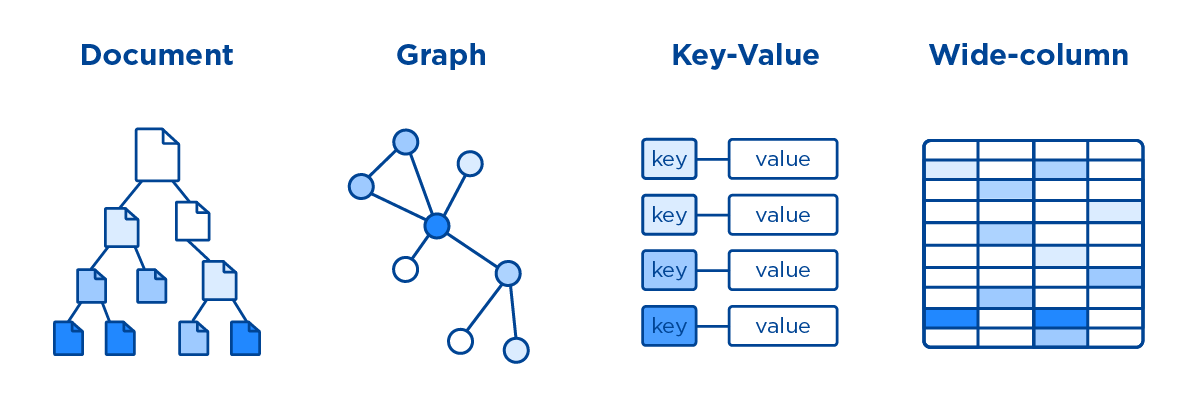
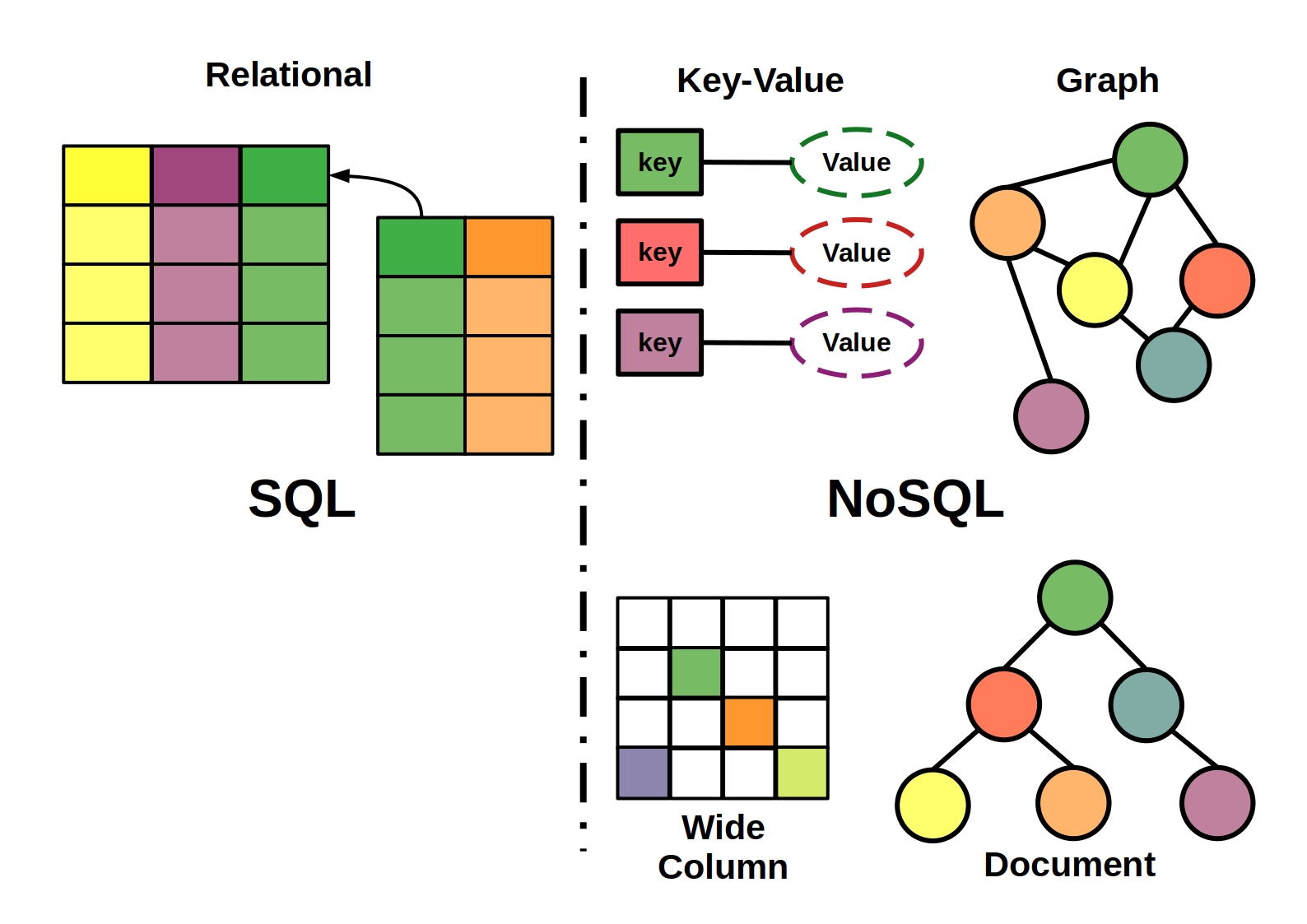
这是极为灵活的 NoSQL 数据库类型,因为应用可以完全控制 value 字段中存储的内容,没有任何限制! 。
典型代表:MemcacheDB、Redis 。
特点:
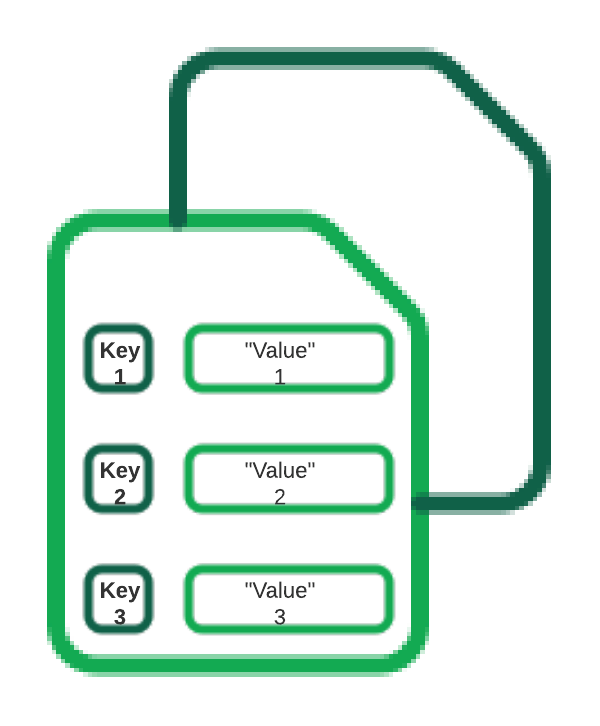
也称为文档存储或面向文档的数据库,这些数据库用于存储、检索和管理半结构化数据。无需指定文档将包含哪些字段.
典型代表:MongoDB、CouchDB 。
特点:

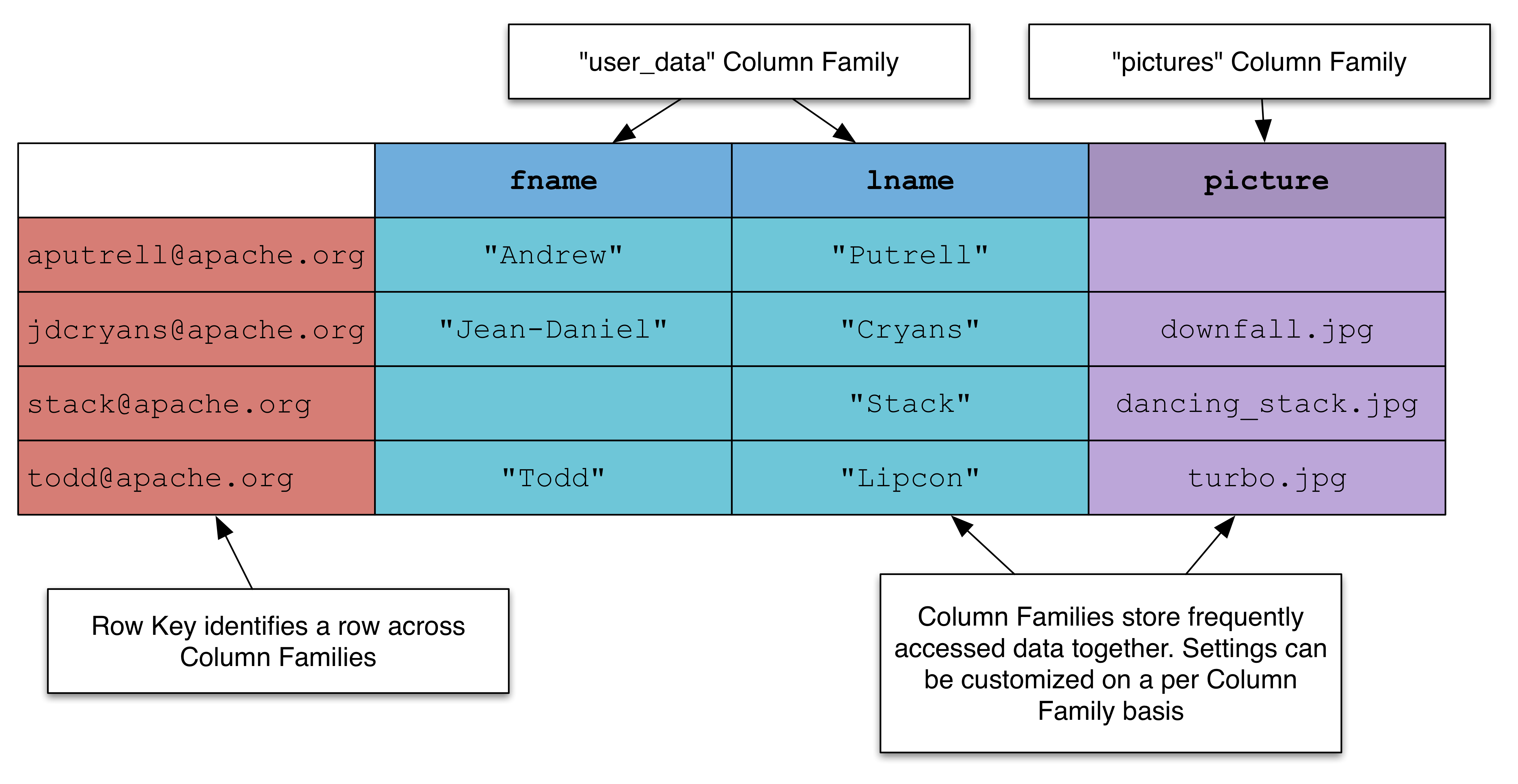
这些数据库以表、行和列的形式来存储和管理数据。它们广泛部署于需要用列格式来捕获无模式数据的应用中.
典型代表:Hbase、Cassandra、Hypertable 。
特点:将数据按照列进行存储,最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有着极大的IO优势 。
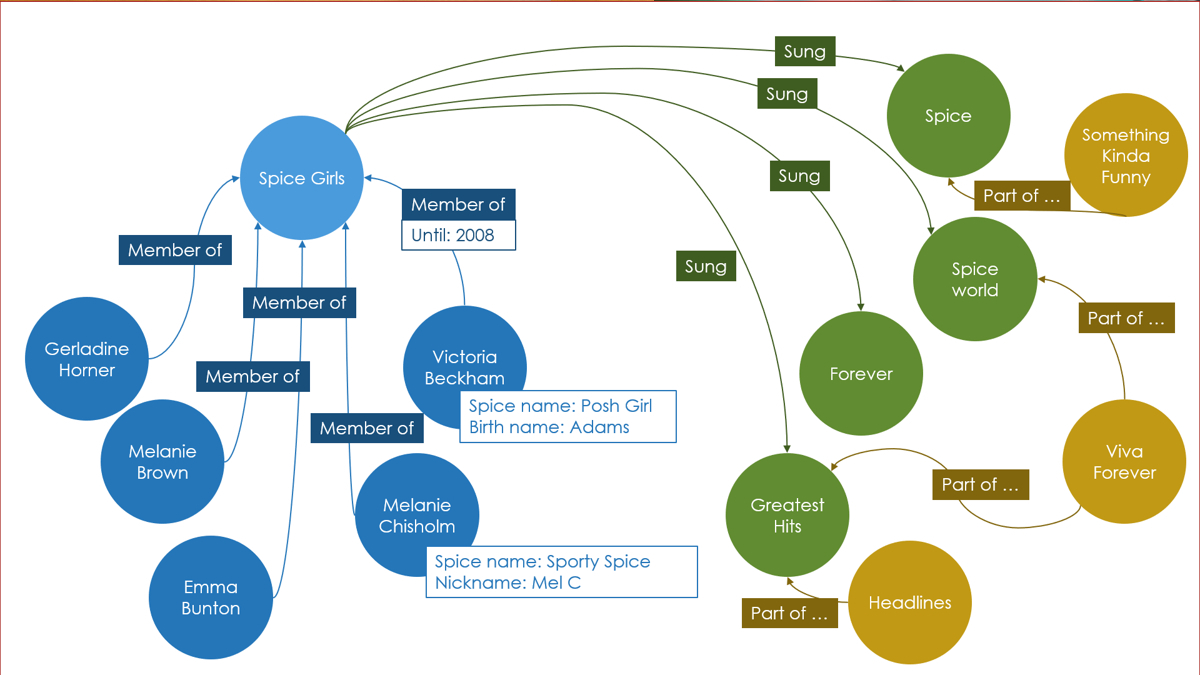
此数据库将数据组织为节点和关系,这将显示节点之间的连接。这支持更加丰富和完整的数据表示。图形数据库应用于社交网络、预订系统和欺诈检测.
典型代表:Neo4J、FlockDB 。
特点:
最典型的例子就是社交网络中人与人的关系,数据模型主要是以节点和边(关系)来实现,特点在于能高效地解决复杂的关系问题 。
如社交网络中人物之间的关系,如果用关系型数据库则非常复杂,用图形数据库将非常简单 。
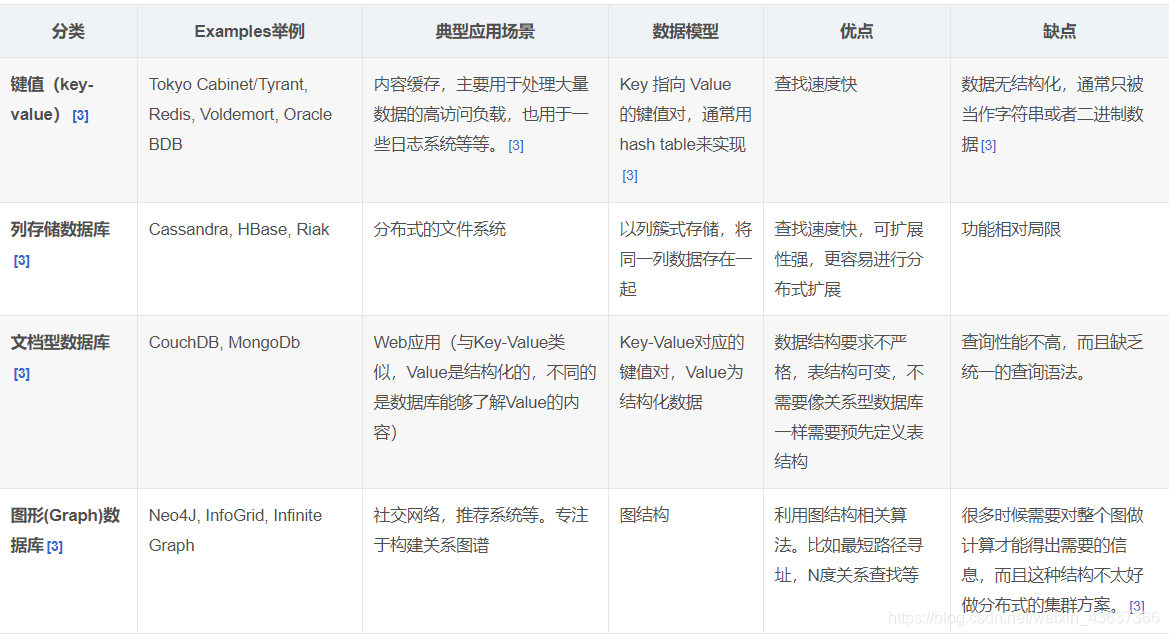
总结:
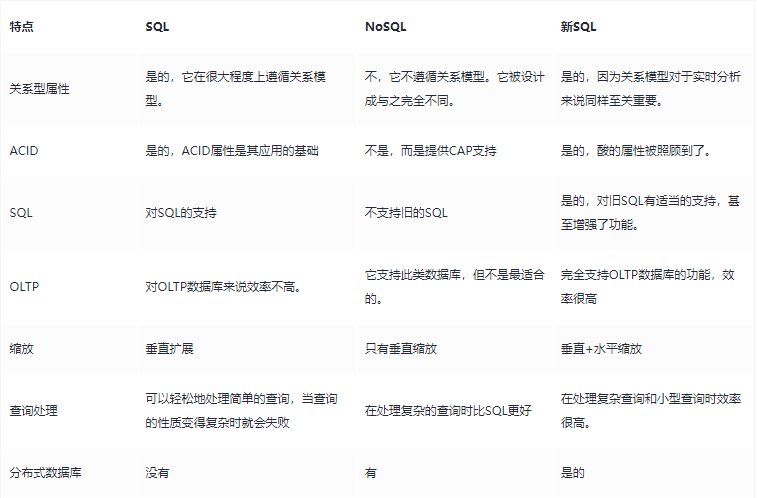
NewSQL 提供了与 NoSQL 相同的可扩展性,而且仍基于关系模型,还保留了极其成熟的 SQL 作为查询语言,保证了ACID事务特性。简单来讲,NewSQL就是在传统关系型数据库上集成了NoSQL 强大的可扩展性.
传统的SQL架构设计基因中是没有分布式的,而NewSQL 生于云时代,天生就是分布式架构.
NewSQL 的主要特性:
总的来说数据库产品演进就是分为三代:
- 第一代数据库架构产品:传统的关系型数据库主导
- 第二代数据库架构产品:传统关系型数据库 + NoSQL多厂家产品配合使用
- 第三代数据库架构产品:NewSQL(关系型+NoSQL+大数据+分布式架构完整解决方案)
主流数据库产品:
RDBMS:Oracle,MySQL,PG,MSSQL,DB2,SQLLite NoSQL:MongoDB,Redis,ElasticSearch,Cassandra,Neo4j,Solr NewSQL: Google Spanner,PinCAP TiDB 云数据库:Aliyun RDS,DRDS,PolarDB,腾讯云 TDSQL 。
参考文章:
最后此篇关于明解数据库------数据库存储演变史的文章就讲到这里了,如果你想了解更多关于明解数据库------数据库存储演变史的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
我正在运行一个辅助角色,并检查 Azure 上托管的存储中是否存在数据。当我将连接字符串用于经典类型的存储时,我的代码可以正常工作,但是当我连接到 V2 Azure 存储时,它会抛出此异常。 “远程服
在我的应用程序的主页上,我正在进行 AJAX 调用以获取应用程序各个部分所需的大量数据。该调用如下所示: var url = "/Taxonomy/GetTaxonomyList/" $.getJSO
大家好,我正在尝试将我的商店导入我的 Vuex Route-Gard。 路由器/auth-guard.js import {store} from '../store' export default
我正在使用 C# 控制台应用程序 (.NET Core 3.1) 从 Azure Blob 存储读取大量图像文件并生成这些图像的缩略图。新图像将保存回 Azure,并将 Blob ID 存储在我们的数
我想将 Mlflow 设置为具有以下组件: 后端存储(本地):在本地使用 SQLite 数据库存储 Mlflow 实体(run_id、params、metrics...) 工件存储(远程):使用 Az
我正在使用 C# 控制台应用程序 (.NET Core 3.1) 从 Azure Blob 存储读取大量图像文件并生成这些图像的缩略图。新图像将保存回 Azure,并将 Blob ID 存储在我们的数
我想将 Mlflow 设置为具有以下组件: 后端存储(本地):在本地使用 SQLite 数据库存储 Mlflow 实体(run_id、params、metrics...) 工件存储(远程):使用 Az
我的 Windows 计算机上的本地文件夹中有一些图像。我想将所有图像上传到同一容器中的同一 blob。 我知道如何使用 Azure Storage SDKs 上传单个文件BlockBlobServi
我尝试发出 GET 请求来获取我的 Azure Blob 存储帐户的帐户详细信息,但每次都显示身份验证失败。谁能判断形成的 header 或签名字符串是否正确或是否存在其他问题? 代码如下: cons
这是用于编写 JSON 的 NeutralinoJS 存储 API。是否可以更新 JSON 文件(推送数据),而不仅仅是用新的 JS 对象覆盖数据。怎么做到的??? // Javascript
我有一个并行阶段设置,想知道是否可以在嵌套阶段之前运行脚本,所以像这样: stage('E2E-PR-CYPRESS') { when { allOf {
我想从命令行而不是从GUI列出VirtualBox VM的详细信息。我对存储细节特别感兴趣。 当我在GUI中单击VM时,可以看到包括存储部分在内的详细信息: 但是到目前为止,我还没有找到通过命令行执行
我有大约 3500 个防洪设施,我想将它们表示为一个网络来确定流动路径(本质上是一个有向图)。我目前正在使用 SqlServer 和 CTE 来递归检查所有节点及其上游组件,只要上游路径没有 fork
谁能告诉我 jquery data() 在哪里存储数据以及何时删除以及如何删除? 如果我用它来存储ajax调用结果,会有性能问题吗? 例如: $("body").data("test", { myDa
有人可以建议如何为 Firebase 存储中的文件设置备份。我能够备份数据库,但不确定如何为 firebase 存储中的文件(我有图像)设置定期备份。 最佳答案 如何进行 Firebase 存储的本地
我最近开始使用 firebase 存储和 firebase 功能。现在我一直在开发从功能到存储的文件上传。 我已经让它工作了(上传完成并且文件出现在存储部分),但是,图像永远保持这样(永远在右侧加载)
我想只允许用户将文件上传到他们自己的存储桶中,最大文件大小为 1MB,仍然允许他们删除文件。我添加了以下内容: match /myusers/{userId}/{allPaths=**} { al
使用生命周期管理策略将容器的内容从冷访问层移动到存档。我正在尝试以下策略,希望它能在一天后将该容器中的所有文件移动到存档层,但事实并非如此在职的。我设置了选择标准“一天未使用后”。 这是 json 代
对于连接到 Azure 存储端点,有 http 和 https 两个选项。 第一。 https 会带来开销,可能是 5%-10%,但我不支付同一个数据中心的费用。 第二。 http 更快,但 Auth
有人可以帮我理解这一点吗?我创建了Virtual Machine in Azure running Windows Server 2012 。我注意到 Azure 自动创建了一个存储帐户。当我进入该存

我是一名优秀的程序员,十分优秀!