
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4


论文标题:Cross-domain Activity Recognition via Substructural Optimal Transport 论文作者:Wang Lu, Yiqiang Chen, Jindong Wang, Xin Qin 论文来源:Neurocomputing 论文地址: download 论文代码: download 。
使用从传感器收集到的原始信号,学习有关人类活动的高级知识。应用于步态分析、手势识别、睡眠阶段检测等领域 。
跨域活动识别(CDAR):借助辅助数据集,使用领域自适应的方式为无标签的新活动数据集构建模型 。
贝叶斯信息准则(BIC):
最优输运问题(OT):
$\alpha=\sum_{i=1}^{n} \mathbf{a}_{i} \delta_{x_{i}}$ 。
$\mathrm{L}_{\mathbf{C}}(\mathbf{a}, \mathbf{b}) \stackrel{\text { def. }}{=} \min _{\mathbf{P} \in \mathbf{U}(\mathbf{a}, \mathbf{b})}\langle\mathbf{C}, \mathbf{P}\rangle \stackrel{\text { def. }}{=} \sum_{i, j} \mathbf{C}_{i, j} \mathbf{P}_{i, j}$ 。
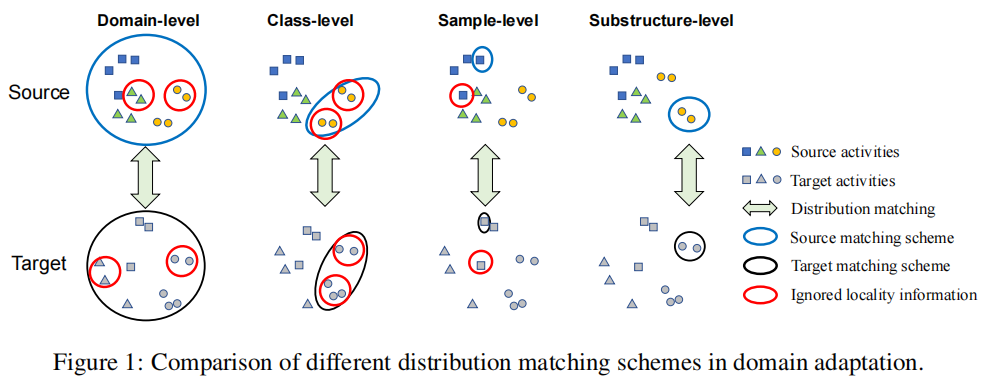
分类 。
局部性: 两个传感器信号之间的细粒度相似度 。
缺陷 。
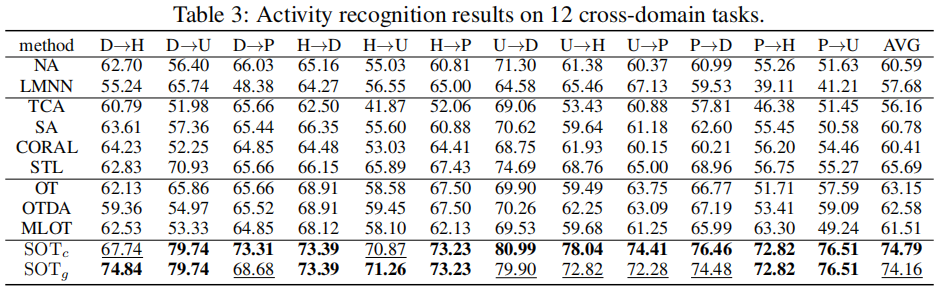
实验分析 。
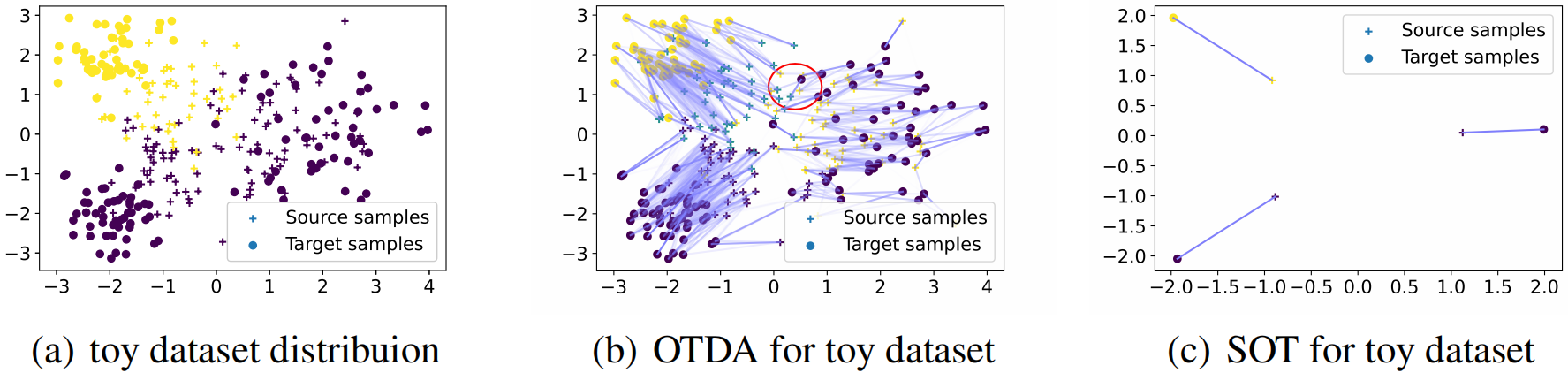
由于其中一个类对应两个簇,使用粗糙匹配将忽略这种局部信息; 。
子结构 :描述数据的细粒度潜在分布,可理解为类内部簇,对应于局部信息; 。
优势 。
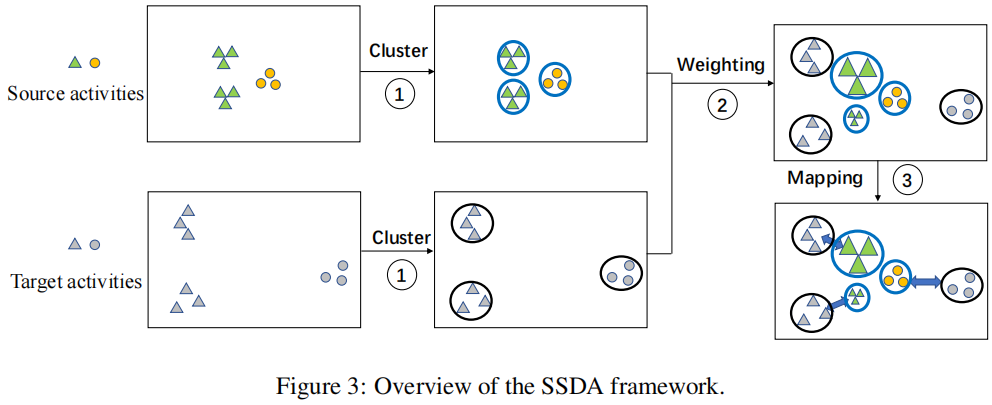
实现 。
基于最优传输,提出子结构最优传输(SOT)方法 。
步骤:
理论分析 。
域级匹配对象 $p(x)$,类级匹配对象 $p(x|y)$,进一步将域划分为更精细的子结构:
$\begin{aligned}p(\mathbf{x}) & =\sum_\limits{y} p(\mathbf{x} \mid y) p(y) \\& =\sum_\limits{y}\left(\sum_\limits{o} p(\mathbf{x}, o \mid y)\right) p(y) \\& =\sum_\limits{y} \sum_\limits{o} p(\mathbf{x} \mid y, o) p(y, o) \text { (For source domain) } \\& =\sum_\limits{o} \sum_\limits{y} p(\mathbf{x} \mid y, o) p(y \mid o) p(o) \\& =\sum_\limits{o} p(\mathbf{x} \mid o) p(o) . \text { (For target domain) }\end{aligned}$ 。

由于类和子结构之间的关系:
$p(y \mid o)=\left\{\begin{array}{ll}1 & o \text { is part of } y \\0 & o . w\end{array}\right.$ 。
统一源域和目标域的匹配对象:
$p(\mathbf{x} \mid o)$ 。
子结构最优运输(SOT) 。
步骤一:子结构生成和表示 。
$X$ 表示所有特征数据,$X_{k} \sim N\left(\mu_{k}, \sigma_{k}\right)$ 表示第 $k$ 个聚类的数据,服从高斯混合分布;可使用特征数据 $X$ 借助期望最大值(EM)算法获得高斯混合模型的参数.
针对源域为保持标签一致性,将其视为 $C$ 个高斯混合模型的混合分布,每个模型对应一个类,针对每个模型分别完成聚类;针对目标域由于缺少标签,直接对整个目标域完成聚类.
聚类数量由贝叶斯信息准则($BIC$)决定,选取使 $BIC$ 最小的自由参数 $k$ 的数量来决定聚类的数量.
聚类算法可自由定制; 。
子结构表示:中心表示的 $S O T_{c}$ 表示法(只利用聚类中心,计算简单,效率高)与分布表示的 $S O T_{g}$ 表示法(利用更多聚类中心,计算时需近似) 。
$\operatorname{SOT}_{c}$ 表示法 。
目标域分布(源域类似)
$\mu_{c, t}=\sum_{i=1}^{k_{t}} w_{t, i} \delta_{\mathbf{z}_{t, i}}$ 。
其中 $z$ 表示聚类中心, $\delta_{z}$ 表示聚类中心处的 Dirac 函 数, $\omega$ 表示与聚类中心相关的概率质量,和为 $1$.
使用欧式距离的平方作为两个域间聚类中心的距离 度量: $\quad c\left(\mathbf{z}_{s, i}, \mathbf{z}_{t, j}\right)=\left\|\mathbf{z}_{s, i}-\mathbf{z}_{t, j}\right\|_{2}^{2}$ . 。
$\boldsymbol{SOT}_{g}$ 表示法 。
目标域分布(源域类似):
$\mu_{g, t}=\sum_{i=1}^{k_{t}} w_{t, i} \mathcal{N}\left(\mathbf{z}_{t, i}, \boldsymbol{\sigma}_{t, i}\right)$ 。
使用高斯分布代替聚类中心位置的 Dirac 函数 使用 Wasserstein 距离的平方作为两个域间聚类中 心的距离度量
$c\left(\mathcal{N}\left(\mathbf{z}_{s, i}, \boldsymbol{\sigma}_{s, i}\right), \mathcal{N}\left(\mathbf{z}_{t, j}, \boldsymbol{\sigma}_{t, j}\right)\right)=W_{2}^{2}\left(\mathcal{N}\left(\mathbf{z}_{s, i}, \boldsymbol{\sigma}_{s, i}\right), \mathcal{N}\left(\mathbf{z}_{t, j}, \boldsymbol{\sigma}_{t, j}\right)\right)$ 。
距离度量用于计算最优输运中的代价矩阵 $C$ 。
将协方差矩阵强制为对角矩阵,经过转化的距离度量:
$\begin{aligned}c\left(\mathcal{N}\left(\mathbf{z}_{s, i}, \sigma_{s, i}\right), \mathcal{N}\left(\mathbf{z}_{t, j}, \sigma_{t, j}\right)\right) & =\left\|\mathbf{z}_{s, i}-\mathbf{z}_{t, j}\right\|^{2}+\left\|\sqrt{\mathbf{r}_{s, i}}-\sqrt{\mathbf{r}_{t, j}}\right\|_{2}^{2} \\& =\left\|\left(\mathbf{z}_{s, i}, \sqrt{\mathbf{r}_{s, i}}\right)-\left(\mathbf{z}_{t, j}, \sqrt{\mathbf{r}_{t, j}}\right)\right\|_{2}^{2}\end{aligned}$ 。
其中 $r$ 表示簇的协方差矩阵的对角线,聚类中心 $z$ 和 $r$ 共同构成表示子结构的特征.
步骤二:计算子结构权值(概率质量) 。
对两种子结构表示法进行统一表示:
$P_{s}=\sum\limits_{s=1}^{k_{s}} w_{s, i} p_{s, i}$ 。
对信息过少的目标域将 $\omega_{t, i}$ 固定为 $1 / k_{t}$ 自适应计算源域的子结构权值 。
由于 $ \omega$ 本身的特性 (和为 $1$), 可看作概率分布向量,利用部分最优运输问题进行求解,求解最优运输方式对应的优化目标
$\begin{array}{r}\boldsymbol{\pi}_{1}^{*}=\arg \min _{\pi}\langle\boldsymbol{\pi}, \mathbf{C}\rangle_{F}+\lambda_{1} H(\boldsymbol{\pi}) \\\text { s.t }\quad\quad\quad\quad\quad\quad \quad\boldsymbol{\pi}^{T} \mathbf{1}_{k_{s}}=\mathbf{w}_{t} \\\boldsymbol{\pi} \mathbf{1}_{k_{t}} \leq \mathbf{1}_{k_{s}} \\\mathbf{1}_{k_{t}}^{T} \boldsymbol{\pi}^{T} \mathbf{1}_{k_{s}}=1 .\end{array}$ 。
其中 $\pi$ 为两个子结构概率分布函数的朱合合矩阵(co upling matrix),$C$ 为代价矩阵,$\langle\cdot\rangle_{F}$ 为 Frobenius 点积,$\langle\pi, C\rangle_{F}$ 即为部分最优输运总代价,$H(\pi)$ 为便于计算加入的正则化项,定义式 。
$H(\boldsymbol{\pi})=\sum_{i j} \pi_{i j} \log \pi_{i j}$ 。
可保证约束条件后两项必然成立, 因此最终优化目标:$\boldsymbol{\pi}_{1}^{*}=\arg \min _{\boldsymbol{\pi}}\langle\boldsymbol{\pi}, \mathbf{C}\rangle_{F}+\lambda_{1} H(\boldsymbol{\pi})$ 。
$\text { s.t } \quad \boldsymbol{\pi}^{T} \mathbf{1}_{k_{s}}=\mathbf{w}_{t} \text {. }$ 。
由于约束条件为的可行解集为凸集,易得问题的封闭形式,可使用拉格朗日方法解决问题:
$L=\langle\boldsymbol{\pi}, \mathbf{C}\rangle_{F}+\lambda_{1} H(\boldsymbol{\pi})+\boldsymbol{\phi}^{T}\left(\boldsymbol{\pi}^{T} \mathbf{1}_{k_{s}}-\mathbf{w}_{t}\right)$ 。
步骤三:基于最优输运(OT)的子结构映射 。
子结构最优运输 (SOT) 的总体优化目标
$\begin{array}\boldsymbol{\pi}^{*}&=\arg \min _{\boldsymbol{\pi}}\langle\boldsymbol{\pi}, \mathbf{C}\rangle_{F}+\lambda H(\boldsymbol{\pi})+\eta \Omega(\boldsymbol{\pi}) \\\text { s.t } & \boldsymbol{\pi}^{T} \mathbf{1}_{k_{s}}=\mathbf{w}_{t} \\& \boldsymbol{\pi} \mathbf{1}_{k_{t}}=\mathbf{w}_{s} .\end{array}$ 。
其中 $ \Omega(\pi)$ 为群稀疏正则化器,期望每个目标样本只从具有相同标签的源样本接收质量.
通过广义条件梯度 (GCG) 求解最优输运问题得到 最优耦合矩阵 $\pi^{*}$ 后, 可通过重心咉射计算出变换后的 $\boldsymbol{p}_{s, i}$ 的值
$\hat{\mathbf{p}}_{s, i}=\arg \min _{\mathbf{p}} \sum_{j} \pi^{*}(i, j) c\left(\mathbf{p}, \mathbf{p}_{t, j}\right)$ 。
当代价函数为欧式距樆时, 可表示为 。
$\hat{\mathbf{P}}_{s}=\operatorname{diag}\left(\boldsymbol{\pi}^{*} \mathbf{1}_{k_{t}}\right)^{-1} \boldsymbol{\pi}^{*} \mathbf{P}_{t}$ 。
其中 $P_{t}$ 为目标表示,$\widehat{P_{s}}$ 为源映射表示 使用计算出的 $ \widehat{P_{s}}$ 和标签 $ Y_{s}$ 可建立模型以预测 $ P_{t}$ 对 应标签,将预测出的标签拭予目标域中属于对应聚类的 数据即可最终完成目标域的标签预测任务,即实现跨域活动识别任务.
https://zhuanlan.zhihu.com/p/356904023 。
https://www.cnblogs.com/liuzhen1995/p/14524932.html 。
。
最后此篇关于迁移学习(SOT)《Cross-domainActivityRecognitionviaSubstructuralOptimalTransport》的文章就讲到这里了,如果你想了解更多关于迁移学习(SOT)《Cross-domainActivityRecognitionviaSubstructuralOptimalTransport》的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
我最近开始从事一个 Sails 项目。它目前在迁移表下具有以下格式的迁移。 20160826122004-create_users_table.js 'use strict'; module.expo
当我尝试迁移时 doctrine:migrations:migrate ,我收到此异常:“元数据存储不是最新的,请运行 sync-metadata-storage 命令来解决此问题。”。这仅在尝试在生
我在 ec2 linux 7 上有一个 MarkLogic 服务器。我想将它迁移到 linux 6。我将 ebs 移动到新的 linux 6 并将其安装在 /var/opt/MarkLogic . 我
我对 OpenID 很好奇。虽然我同意统一凭证的想法很棒,但我有一些保留意见。什么是防止 OpenID 提供商发疯并持有他们拥有的 OpenID 帐户直到您支付 n 美元?如果我决定不喜欢这个提供商,
使用 SQL 很容易做到这一点,但我需要编写一个我不熟悉的 Knex 迁移脚本。以下代码在 order 表中行的末尾添加了 order_id 列。我想在 id 之后添加 order_id。我该怎么做?
使用 SQL 很容易做到这一点,但我需要编写一个我不熟悉的 Knex 迁移脚本。以下代码在 order 表中行的末尾添加了 order_id 列。我想在 id 之后添加 order_id。我该怎么做?
我想通过在 Yii2 中的迁移添加一个新列,使用以下代码: public function up() { $this->addColumn('news', 'priority', $this-
我正在尝试在 SQLDelight 的表中添加更多列。我做了一个迁移文件 1.sqm .在迁移文件中,它给出了找不到表的错误。 我的 build.gradle.kts: sqldelight {
我有一个与 Flyway DB 迁移相关的问题。通常如何管理处理相同 DB 模式的多个项目(微服务)。每个项目中的 Flyway 迁移脚本如果被其他项目修改,则不允许启动。他们是否有任何文档或最佳实践
我是 Laravel 的新手。我做了一份待办事项申请作为一项学校作业。我们必须使用迁移来创建我们的数据库。 我使用迁移创建了 2 个表。我的问题是:如果你第一次在你的电脑上运行这个项目,有没有办法自动
我正在尝试在 Laravel 中创建外键,但是当我使用 artisan 迁移表时,出现以下错误: [Illuminate\Database\QueryException] SQLSTATE[HY000
我从 Django 1.7 升级到 Django 1.9。我有多次迁移。升级后我无法再创建新的数据库。 问题是“django manage.py migrate”运行检查。检查导入应用程序 URL。这
我在创建数据迁移方面遇到了困难。我的应用程序使用两个数据库。我在 settings.py 中配置了数据库,并创建了一个像 Django docs 中一样的路由器. # settings.py DB_H
我有一个像这样的sql结构: CREATE TABLE resources ( id SERIAL PRIMARY KEY, title TEXT NOT NULL, created_at
我正在尝试使用模式构建器向表添加枚举选项(不丢失当前数据集)。 我真正能够找到的关于列更改的唯一信息是 http://www.flipflops.org/2013/05/25/modify-an-ex
我尝试转移到一些 CMake 程序中,并且有一个从 xml 生成头文件的函数。 生成文件.am adaptor_glue.hpp: dbus_introspect.xml $(DBUSXX_X
我想将文件移至我的 iOS 应用程序的 CoreData 存储 ../Library/Application Support/MyApp/ 至 ../Documents/Stores/ 我可以使用 N
有没有人对数据迁移进出 NetSuite 有丰富的经验?我必须将 DB2 表导出到 MySQL,处理数据,然后导出到一个 CSV 文件中。然后获取帐户的 CSV 文件并再次操作数据以使帐户从我们的旧系
我正在尝试在 Django 上建立一个博客。我已经走到了创建模型的地步。他们在这里: from django.db import models import uuid class Users(mode
我最近使用 bluehost 上的 AutoSSL 工具将网站迁移到 HTTPS。我在内容中看到一些失真,例如缺少背景颜色、表格位移、缺少_logos 等。 有谁知道 HTTPS 迁移效果如何影响样式

我是一名优秀的程序员,十分优秀!