
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 27
27
 4
4


有同事分享 webpack 的代码分割,其中提到了 SplitChunksPlugin ,对于文档上的描述大家有着不一样的理解,所以打算探究一下.
Q:什么是 SplitChunksPlugin ? SplitChunksPlugin 是用来干嘛的?
A: 最初, chunks (以及内部导入的模块)是通过内部 webpack 图谱中的父子关系关联的。 CommonsChunkPlugin 曾被用来避免他们之间的重复依赖,但是不可能再做进一步的优化。从 webpack v4 开始,移除了 CommonsChunkPlugin ,取而代之的是 optimization.splitChunks 。 SplitChunksPlugin 可以去重和分离 chunk 。
webpack 的中文文档,对 SplitChunksPlugin 的描述是这样子的:

针对以上的第二点描述 新的 chunk 体积大于 20kb(在进行 min+gz 之前的体积) ,有同事是这么理解的: chunk 大于 20kb 时, webpack 会对当前的 chunk 进行拆包,一般情况下, 100kb 的包会拆成 5 个包 即 5 * 20kb = 100kb . 如果有并发请求的限制, webpack 会自动把某些包合并,如并发请求数是 2 ,那么这个 100kb 的包将会被拆成 2 个,每个包的大小为 50kb ,即 2 * 50kb = 100kb .
而我对此表示有不同的看法: 既然这个插件是用来对代码进行分割的,那么没有必要再对代码进行合并,这样子会让这个插件变得不纯粹,而且会增加插件逻辑的复杂度,所以这句话的意思应该是分割出来的新 chunk 得大于 20kb .
由于大家都不是三言两语就能被说服的,所以打算去查查资料,动动手验证一下到底是怎么一回事.
首先为了避免中华语言博大精深,导致个人理解有偏差,我先去查看了一下英文文档,英文文档上是这么描述的:

关键词 new chunk :新的 chunk ,只有分离出来的才算是新的 chunk 吧,那么这句话的意思应该就是新的 chunk 将会大于 20kb .
其次为了再次避免个人英文理解有偏差,到网上去翻阅了一些社区文章:
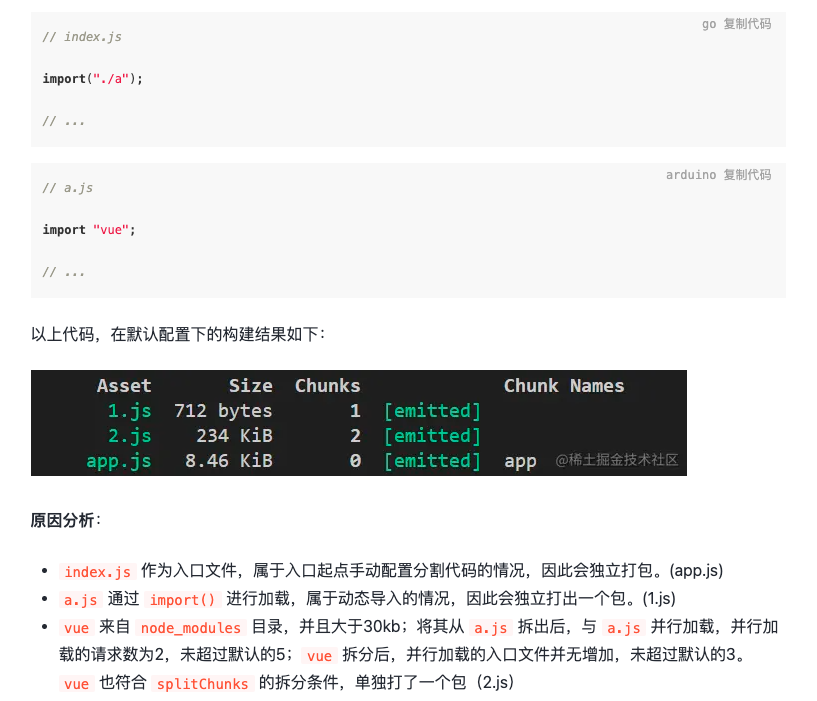
作者:前端论道 链接: https://juejin.cn/post/6844904103848443912 来源:稀土掘金 。
从上图中可以看到,第三方包 vue 已经超过了默认的 20kb ,直接被分割成一个单独的 2.js 的包,并不是按照 20kb 平均分成多个包.
// index.js
import "./a";
console.log("this is index");
// a.js
import "vue";
import "react";
import "jquery";
import "lodash";
console.log("this is a");
// webpack.config.js
const path = require('path');
module.exports = {
mode: "production",
entry: './src/index.js',
output: {
filename: '[name].js',
path: path.resolve(__dirname, 'dist'),
},
optimization: {
splitChunks: {
chunks: 'all',
},
},
};
编译结果:
从编译的结果中可以看到,除了 main.js ,仅仅多出了一个 205kb 的 46.js 。 从上图可以看出, vue 、 jquery 、 lodash 等一起都被打包到 46.js 中,并没有以 20kb 为基础平均分割成很多个 chunk .
新的 chunk 体积大于 20kb(在进行 min+gz 之前的体积) ,指的是引入的依赖中,在进行 min+gz 之前的体积大于 20kb ,这个依赖将会被分割出来成为一个新的 chunk .
到这里还没有结束,因为我还有几个疑问:
webpack 为什么要进行代码分割?
浏览器的并发请求一般不是4~6个吗?为什么文章里提到的按需请求和初始请求都是小于或者等于30?
1、按需加载 首次加载只加载必要的内容,提升用户的首次加载的速度。其他的模块可以根据用户的交互进行按需加载,即用户跳转新路由或者点击的页面的时候再进行加载.
2、有效利用缓存 通过 webpack 在打包是对代码进行分割,可以有效的利用缓存:打包编译的时候,只需要编译需要更新的部分;用户访问的时候只需要下载被修改的文件即可.
场景: 你有一个体积巨大的文件,并且只改了一行代码,用户仍然需要重新下载整个文件。但是如果你把它分为了两个文件,那么用户只需要下载那个被修改的文件,而浏览器则可以从缓存中加载另一个文件.
3、预获取/预加载模块 。
prefetch (预获取):将来某些导航下可能需要的资源:这会生成 <link rel="prefetch" href="login-modal-chunk.js"> 并追加到页面头部,指示着浏览器在闲置时间预取 login-modal-chunk.js 文件。 preload (预加载):当前导航下可能需要资源 preload chunk 会在父 chunk 加载时,以并行方式开始加载。 prefetch chunk 会在父 chunk 加载结束后开始加载。 preload chunk 具有中等优先级,并立即下载。 prefetch chunk 在浏览器闲置时下载。 preload chunk 会在父 chunk 中立即请求,用于当下时刻。 prefetch chunk 会用于未来的某个时刻。 随着 http2.0 的普及,浏览器的并发请求的限制得到了很好的解决。通过 http2.0 的多路复用,理论上可以通过一个 TCP 请求发送无数个请求。然后翻了下 webpack 代码仓库源码,发现了以下注释:
http2.0 支持情况:

所以在webpack的代码分割逻辑里,按需请求和初始请求都超过了之前浏览器对 http1.0 单个域名请求的限制.
参考文档: webpack中文文档 webpack英文文档 如何使用 splitChunks 精细控制代码分割 。
最后此篇关于浅析SplitChunksPlugin及代码分割的意义的文章就讲到这里了,如果你想了解更多关于浅析SplitChunksPlugin及代码分割的意义的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
27
4
 0
0
我正在尝试使用代码拆分,这样我就可以在不复制模块的情况下对生产代码进行单元测试。我希望 webpack 能够识别我的 *.test.ts 文件依赖于与源代码本身相同的模块,并输出包含这些共享依赖项的包
是否可以同时获得动态导入和拆分块( SplitChunksPlugin )的好处? 动态导入 当我使用动态导入时,我会为每个动态导入的库获取一个块。但是,静态导入的任何内容都会添加到同一个(大)包中。
我正在尝试利用 SplitChunksPlugin 为 MPA 中的每个页面/模板生成单独的包。当我使用 HtmlWebpackPlugin 时,我会为每个页面获取一个 html 文件,其中包含指向正
我正在为 NodeJS 8.x (AWS Lambda) 生成 bundle ,并且希望有选择地缩小块(业务代码保持不缩小,第三方库缩小以节省 bundle 大小)。 我已经按如下方式配置了 Webp

我是一名优秀的程序员,十分优秀!