
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


在单机系统中,所有的数据都存储在同一个服务器下,当数据量越来越多的时候,超过了单机存储容量的上限,就需要使用分布式存储系统,在分布式存储系统重,数据会被拆分到不同的存储服务下,减少单机服务的压力.
在分布式系统中,每个节点存储的数据都是不同的。通过使用分布式存储,将数据水平拆分到不同的节点上,新的数据也会分配到新的节点上,比如使用 取模方式 分配节点,先用 hash 算法算出 hash 值,然后使用 hash/N , N 是节点数,比如三个节点.
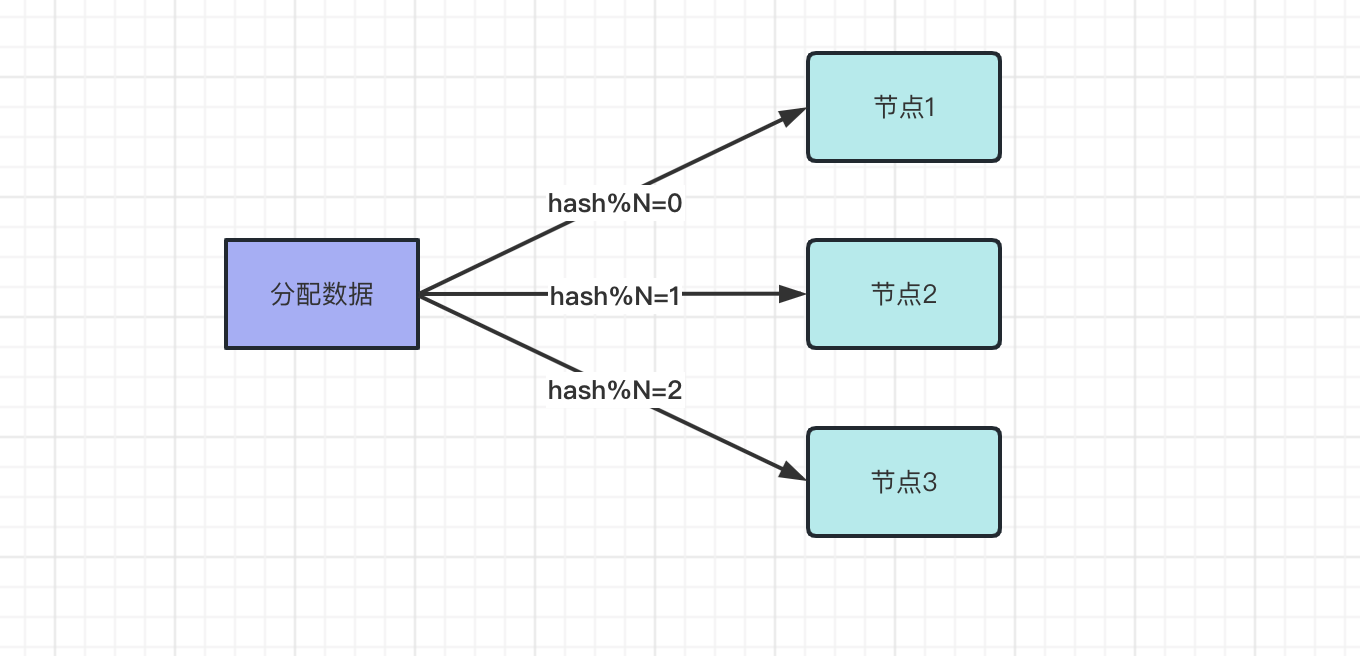
如果节点数量是固定的,数据分配方式是固定的,获取数据的方式也是固定,数据也能正常的获取.
如果节点数量发生了变化,新增或者减少节点时 ,比如新增 节点4 ,原来分配到 节点1 的数据被分配到 节点4 ,原来的数据映射都无效,数据也无法正常获取了。这就需要使用到 一致性哈希算法 .
一致性哈希,从名字就能看出来,该算法符合一致性原则,当服务节点数量增加或减少,数据还能正常获取到。那一致性哈希有什么神奇的地方呢?先介绍什么是一致性哈希:
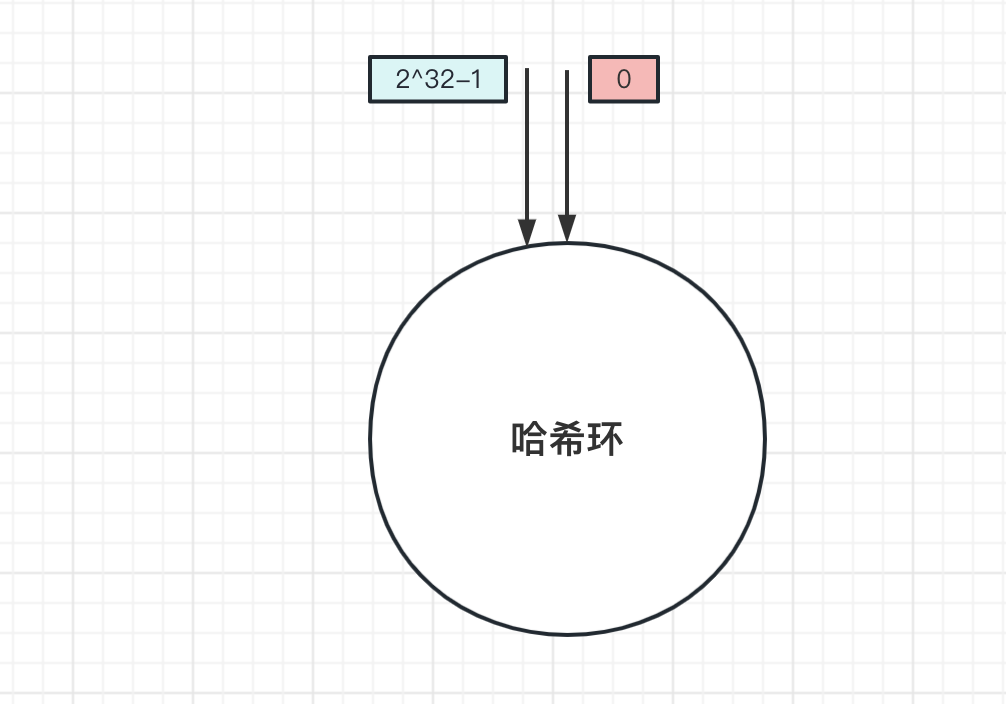
上面是一个 哈希环 ,环上有 2^32 个节点。和上面取模算法一样,一致性哈希算法也是取模算法,不同的是一致哈希算法是对 2^32 个节点取模运算,哈希环的节点是固定的,取模运算结果值也是固定的.
2^32 取模运算。 取模后的值一定是在哈希环上。那是如何找到存储的节点呢?答案 在环上往顺时针方向找到第一个节点 .
比如哈希环上,有三个节点,分别是 节点1 、 节点2 、 节点3 ,平均分布在哈希环上:
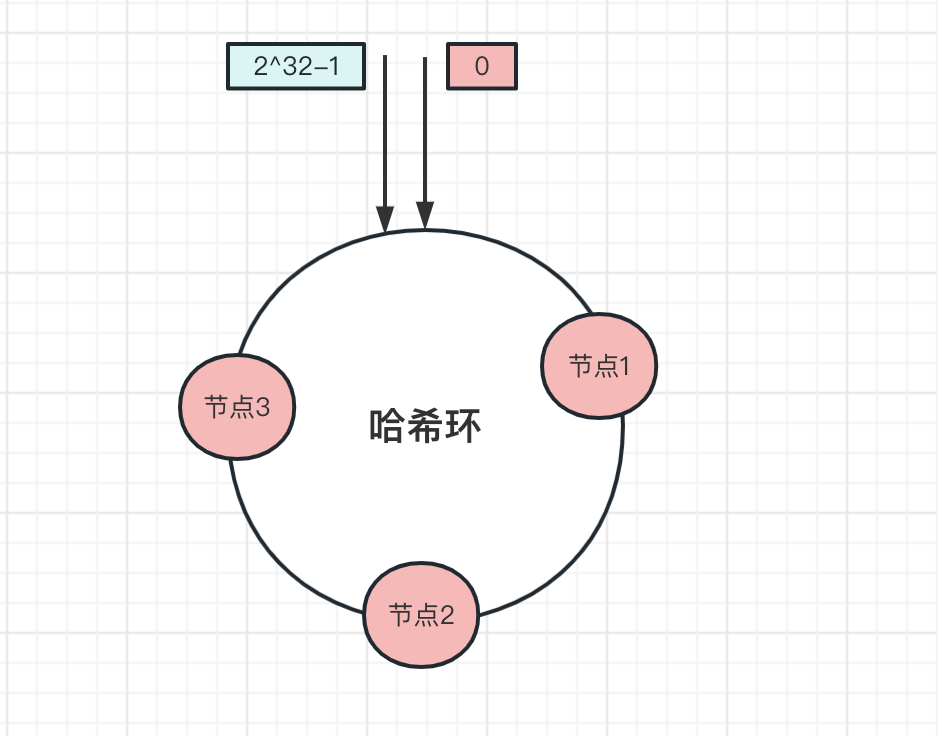
新增一个数据,先算出来哈希值,确定该数据在哈希环上的位置,然后从这个位置顺时针方向找到第一个节点,就是存储数据的节点.
比如下图中数据 key-01 ,先算出该数据在哈希环的位置,往顺时针方向找到第一个节点,也就是 节点1 ,同理 key-02 、 key-03 顺时针分别找到 节点2 和 节点3 :
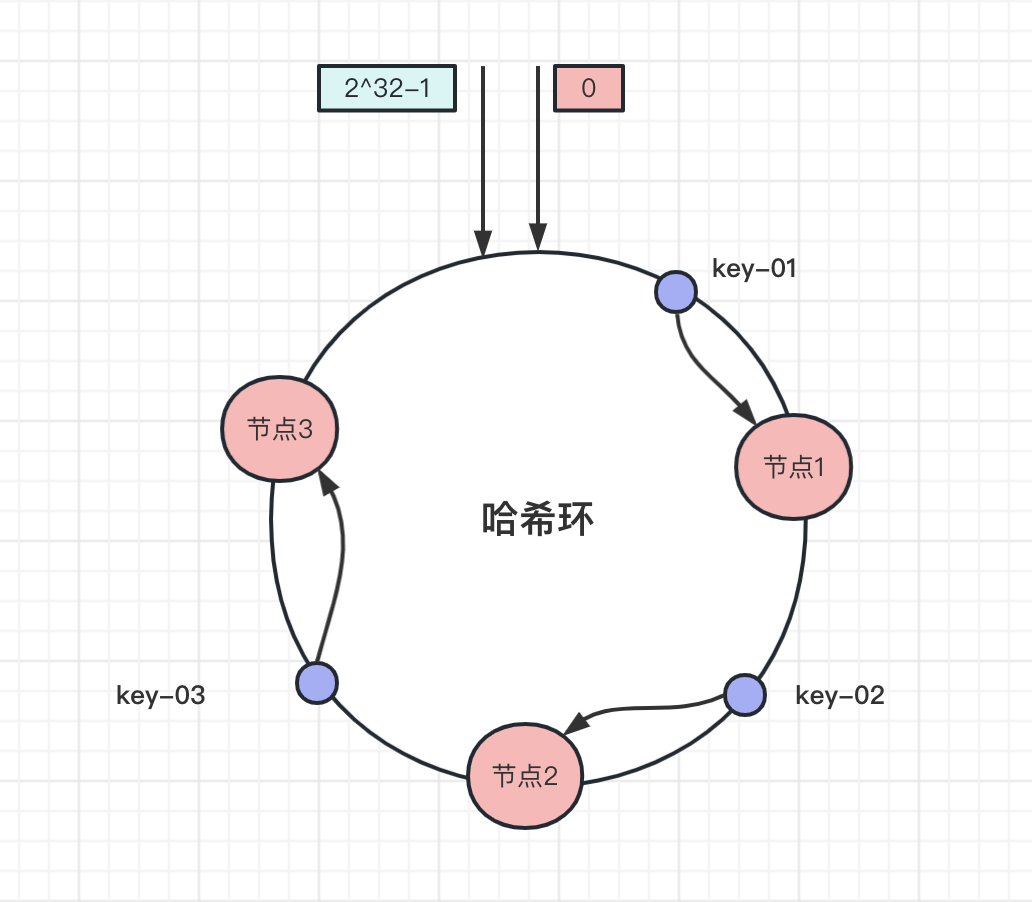
增加一个节点之后,比如新增加一个 节点4 ,经过哈希计算获取节点的位置:
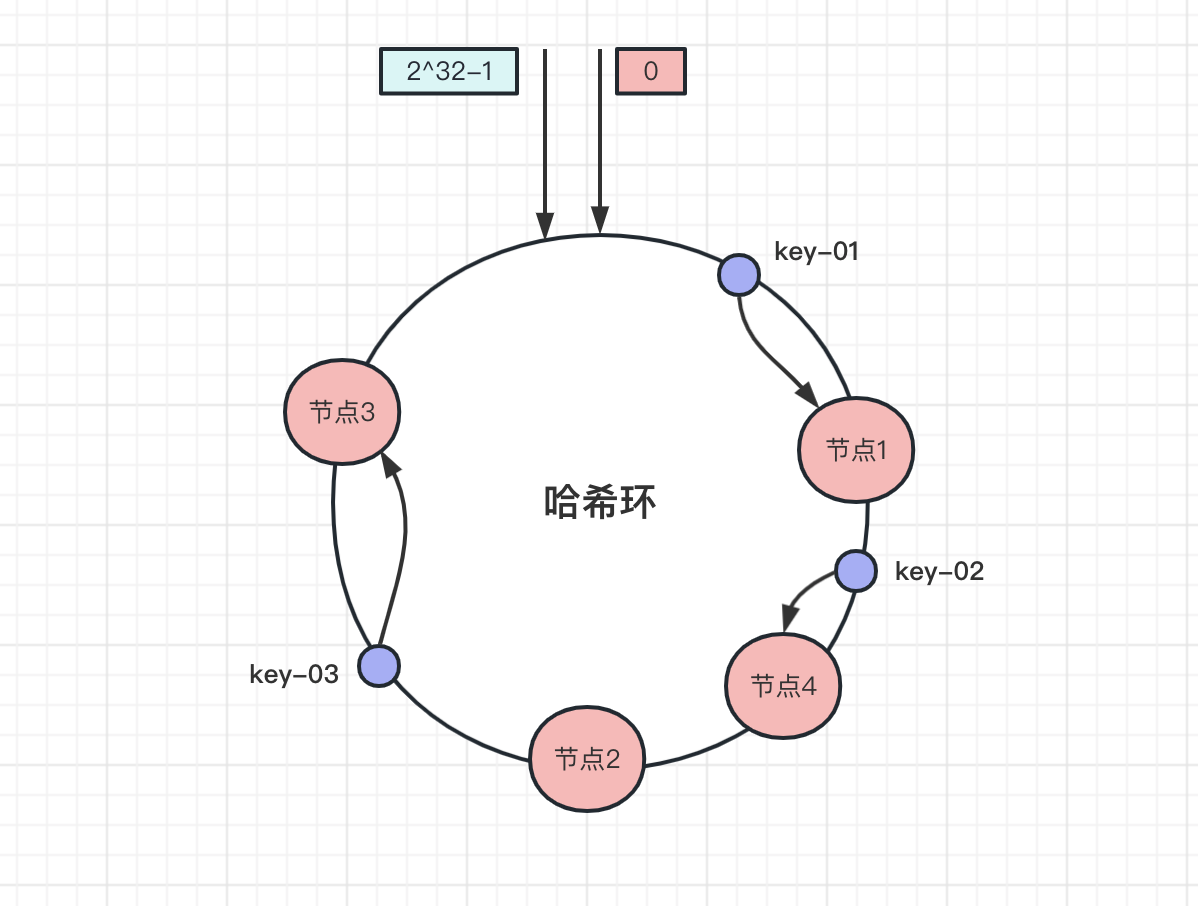
可以看到,此时 key-01 和 key-03 数据不受影响, key-02 存储的节点从 节点2 迁移到了 节点4 .
那减少一个节点,移除 节点1
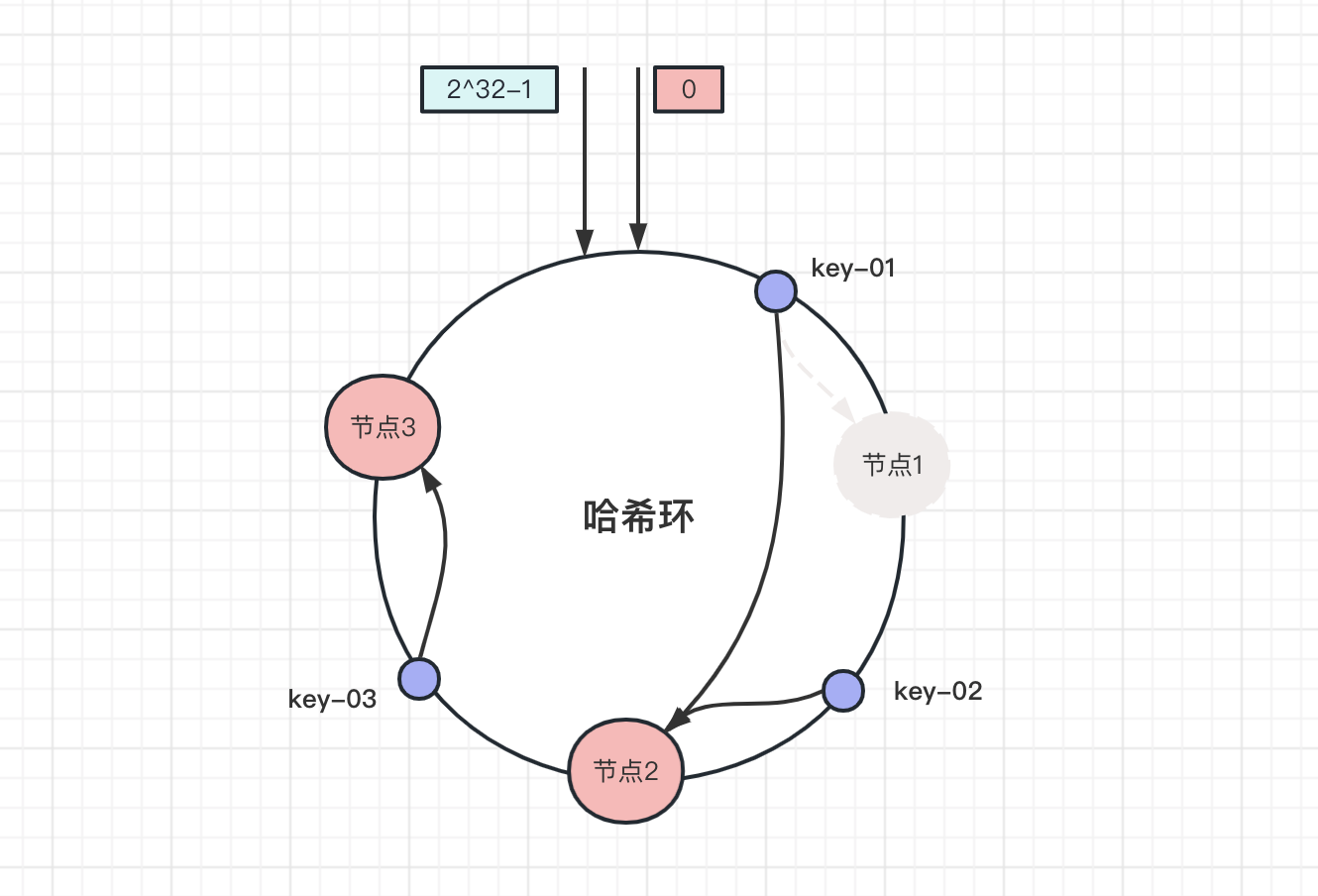
此时 key-02 和 key-03 数据不受影响,只有 key-01 被迁移到 节点2 .
在一致性哈希上,增加或减少节点,影响的节点从新节点逆时针方向到上一个节点的数据.
对服务器节点扩容或者缩容,影响的数据只占整体数据一小部分,对整体系统的影响不大,对于数据准确性要求多的数据则不适用一致性哈希.
上面数据是均匀的分布在哈希环上,每个节点的存储压力都比较均衡,但是一致性哈希并不能保证数据会平均的分布在各个节点上,当大量的数据都分布在同一个节点上,如下图所示,大量的节点都分布在 节点3 上:
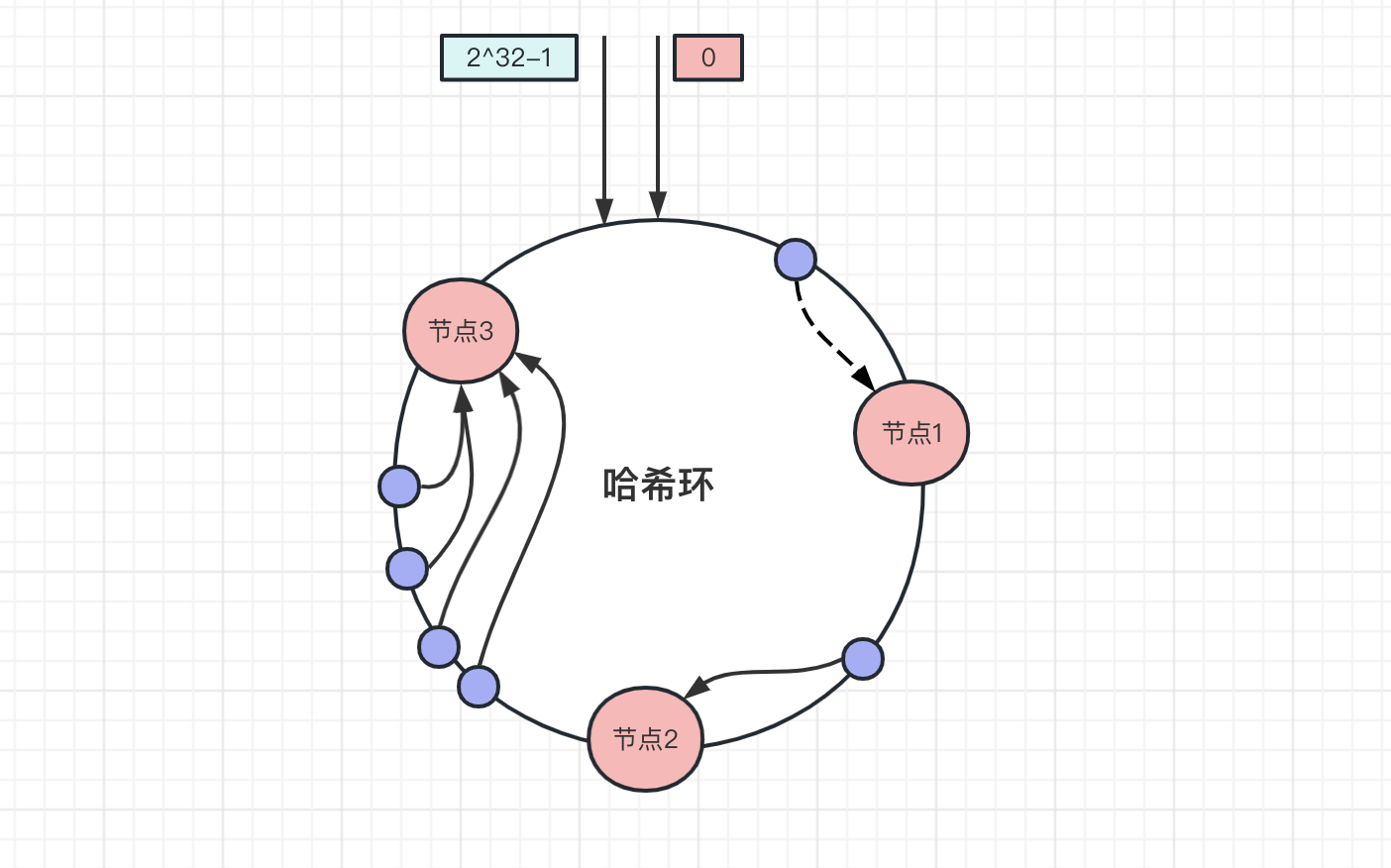
此时请求访问数据主要是集中在 节点3 上,而环上的节点服务器配置基本是一致的,不会因为某个服务器压力大,就单独加大某个服务器的配置。 节点3 数据存储和访问量是其他节点的几倍以上,当请求压力超过了服务处理的上限后,就会导致 节点3 崩溃, 节点3 挂了之后,全部数据压力都会转移到 节点1 , 节点1 也会宕机,最后形成雪崩.
为了解决数据倾斜问题,一致性哈希算法引入了 虚拟节点 ,一个节点对应多个虚拟节点,上面三个真实节点,每个节点引入 3 个虚拟节点
节点1 引入三个虚拟节点:1A、1B、1C 节点2 引入三个虚拟节点:2A、2B、2C 节点3 引入三个虚拟节点:3A、3B、3C 引入虚拟节点之后,环上一共有 9 个节点

节点数量多了之后,数据在哈希环上的分布就更加均匀了,就不容易出现上面数据倾斜的问题,当有数据存储到 1A 虚拟节点,在通过 1A 虚拟节点就能找到真实节点 节点1 了.
在实际应用中,虚拟节点的数量远大于上面虚拟节点数量。虚拟节点越多,对应的数据分布就更加的均匀。比如 Nginx 的一致性哈希算法中的虚拟节点就有 160 个.
虚拟节点除了使数据分布更加均衡之外,也会极大的提高数据的稳定性,当节点的数量变化时,会有不同的节点分担数据的请求压力,而不会像上面一样,当一个节点挂了,数据全都转到另一个节点上,导致雪崩发生.
hash%N 方式都失效了,数据也无法正常的获取了。 2^32 节点,新增一个数据,先算出来哈希值,然后取模,算出来在环上的位置, 往顺时针找到第一个服务节点 ,就是存储的服务节点。 数据倾斜 ,就需要引入 虚拟节点 ,一个服务节点对应多个虚拟节点,访问数据请求到虚拟节点,再找到对应的真实服务节点。虚拟节点越多,数据的分布就越均衡。同时,新增或者减少节点,会有不同的服务节点分摊压力,使服务更加稳定。 最后此篇关于详解一致性哈希的文章就讲到这里了,如果你想了解更多关于详解一致性哈希的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
GhostScript PDF/A 生成好像有错误 当您通过 GhostScript 生成 PDF/A 文档时,当您单击 Adobe Reader 时,会出现一个一致性选项卡,其中显示: “一致性
我有一个需要测试的 XPath 引擎实现。 是否有一组标准的一致性测试可以用来验证是否符合 XPath 规范(与 XSLT 相关)。 什么将是完美的 XML 文档 XPath 表达式和预期的结果。 最
帮助我了解在这种情况下我可以期望与 MongoDB 的一致性级别。 我们正在运行一个副本集,其中 Mongoid 中的 consistency 标志设置为 strong,这意味着只读到 master。
假设我有一个采用一个参数的方法。 此参数应满足以下要求: 'of type':方法需要知道参数属于特定类(或子类)。 'implements interface':方法需要知道参数实现了特定的接口(i
当协议(protocol)将属性声明为可选而具体类型将其声明为非可选时,如何使具体类型符合协议(protocol)? 这是问题所在: protocol Track { var trackNum
我正在考虑使用浏览器的 navigator.mimeTypes 数组作为第三级用户/浏览器标识符。例如,当我在 Chrome 上运行时... console.log(navigator.mimeTyp
我有以下协议(protocol): protocol ProtoAInput { func funcA() } protocol ProtoA { var input: ProtoAI
如果选择“最终”一致性,则发生写入的区域内的一致性是什么? 如果我只需要区域强一致性,应该选择哪个选项? 最佳答案 如果您需要在主要区域内进行强读取,则应该选择强一致性或有界过时一致性。 关于azur
您好,我是一名初学者,目前正在尝试学习 java 编程。课本上的问题: 编写一个程序来帮助人们决定是否购买混合动力汽车。你的程序的输入应该是:•新车的成本•预计每年行驶里程•预计汽油价格 •每加仑英里
我正在尝试制作一个可以在 UILabel 上使用的 Swift 协议(protocol), UITextField , 和 UITextView包含他们的text , attributedText ,
我有一个类扩展: extension UICollectionViewCell { class func registerFromNibInCollectionView(collectionV
为了在 Swift 中模拟对象进行测试,我通常遵循这样的模式:编写一个协议(protocol)来描述我想要的对象的行为,然后使用 Cuckoo 为其生成模拟以进行测试。 通常,这些协议(protoco
假设我有两个非通用协议(protocol)(1) protocol StringValue { var asString: String {get} } protocol StringProv
我有一组协议(protocol)可以在 UITableView 中显示一个元素: protocol TableRepresentableRow { var title: String { get
关闭。这个问题是not reproducible or was caused by typos .它目前不接受答案。 这个问题是由于错别字或无法再重现的问题引起的。虽然类似的问题可能是on-topi
用“class”标记 CacheManager 解决了我的问题。 案例:一个简单的缓存器,mutating get 不是我想要的,那么对于引用类型或类类型应该怎么做? protocol Cacher
我想要一个符合协议(protocol)的变量,但是 swift 编译器告诉我协议(protocol)没有确认。 protocol A {} protocol B { var a : A { g
如果我有一个类 Christmas 和一个协议(protocol) Merry,要使 Christmas 符合 Merry,很多人会这样做: class Christmas { ... } e
@objc public protocol P1 { func p1foo() } @objc public protocol P2 { func p2foo() } class A: NSO
我有一些结构符合的基本协议(protocol)(模型)。它们也符合 Hashable protocol Model {} struct Contact: Model, Hashable { v

我是一名优秀的程序员,十分优秀!