


 26
26
 4
4


作者:京东科技 刘红申 。
事件总线,或称其为数据管道,作为整个风险洞察数据流转的重要一环,它承担着风险实时数据统一标准化的重要职责.
在面对复杂多样的上游数据,事件总线可以将复杂数据进行解析、转换, 富化、分发等操作。底层核心算子抽象为source、transform、sink三层架构, 支持各层算子插件式扩展, 并支持groovy、python等脚本语言自定义配置,以及自定义jar包的上传,拥有将上游数据单向接入多向输出的能力,在数仓与上层应用的开展中,起着承上启下的作用.
风险洞察平台运行初期,业务数据接入完全采用定制化代码处理,通过代码配置消费MQ消息,然后根据业务需求,完成其所需字段的解析,最终数据落入Clickhouse。这种业务接入方式在早期是可以满足业务所需,但是随着风险洞察平台在风控领域的不断推进,业务的发展与数据不断膨胀,面对风控数据的复杂多样性、消息平台的差异性,数据接入定制化成本也越来越高,同时数据转化与计算逻辑的强耦合,大促时期吞吐量已然达到瓶颈,呈现出越来越多的痛点:
1. 数据结构差异性: 随着风险洞察平台使用业务方的的不断增加,业务数据消息体的复杂性也不尽相同,如复杂场景以天盾反欺诈场景为例,消息体结构包含对象、对象字符串而且还有数组;简单场景以内容安全为例,消息体结构就是简单平铺的一层;面对风控数据的复杂多样性,定制数据的统一标准化已然迫在眉睫; 。
2. 代码逻辑重复性: 对消息体的处理绝大多数逃离不了序列化与反序列化操作,然而随着业务量的增多以及开发人员的不尽相同,业务代码是每日剧增且带有参差性的,逻辑重复,维护成本高; 。
3. 解析写入低效性: 同一个MQ消息可能会对应很多的业务方,不同的业务方所需业务数据又千差万别,如以天策MQ为例,实时数据中包含着金白条数据,金条与白条数据又区分着各自的业务线,如果单次订阅MQ消息,会导致逻辑处理极其复杂,不可维护;然而采用多次订阅,又无法复用已有逻辑,且导致数据成倍增长,造成资源浪费,同时吞吐能力成为瓶颈; 。
4. 输入输出多样性: 随着风险洞察平台被使用的越来越广,来自于上游数据的生产方式也出现了多样性,如JMQ2、FMQ、Kafka以及JMQ4等等,同时又为了给用户更好的平台使用体验,不同业务数据又会被落入不同存储中,如Clickhouse、R2m、Jes以及消息队列,如何快速支持这些组件成为了挑战; 。
5. 业务需求易变性: 上游业务频繁的策略调整与变更,对应到事件总线就意味着解析字段以及底层表字段频繁的增删改,正如字段解析完全依赖于硬编码且不同业务数据耦合着各自的业务逻辑,导致开发人员维护成本极高,开发周期长、上线影响广; 。
研发一套数据流转服务,用其贯穿数据接入到数仓存储的整个流程,再结合风险洞察平台特性,以数据源组件为基础,作为数据流转的入口与出口,具体方案如下:
• 数据统一标准化能力: 统一标准化入口与出口。上游数据接入时,无论消息体结构如何,经过事件总线处理后,都输出为平铺单层key-value结构; 。
• 代码逻辑规范化能力: 针对风控策略本身易变的特性,采用灵活度更高的消息体解析组件Jsonpath,任何消息体处理第一步就是生成消息体上下文对象,后续字段的提取,都从这个上下文中获取; 。
• 高吞吐解析写入能力: 一次解析,多路复用。MQ主题实现单次接入,根据不同的业务需求通过过滤下沉不同的业务表,如以天策金白条为例,提取金白条各自的INTERFACE_NAME作为条件,下沉到不同的业务表中;又如以高TPS营销反欺诈场景为例,在下沉表的同时,下沉消息队列给Flink计算使用;减少重复解析,同时抽象各种算子,针对不同的数仓写入可做对应的频次、批次、大小设置,提升吞吐量; 。
• 输入输出插件化能力: 输入输出插件化,新的业务需求来时,可以快速扩展相应组件,以应对新需求; 。
• 低代码化热加载能力: 针对业务需求的频繁变更,解决硬编码问题,减少上线频次,那就需要开发一套可配置化系统,支持脚本开发与热加载,同时内置函数插件化,快速扩展共性函数; 。

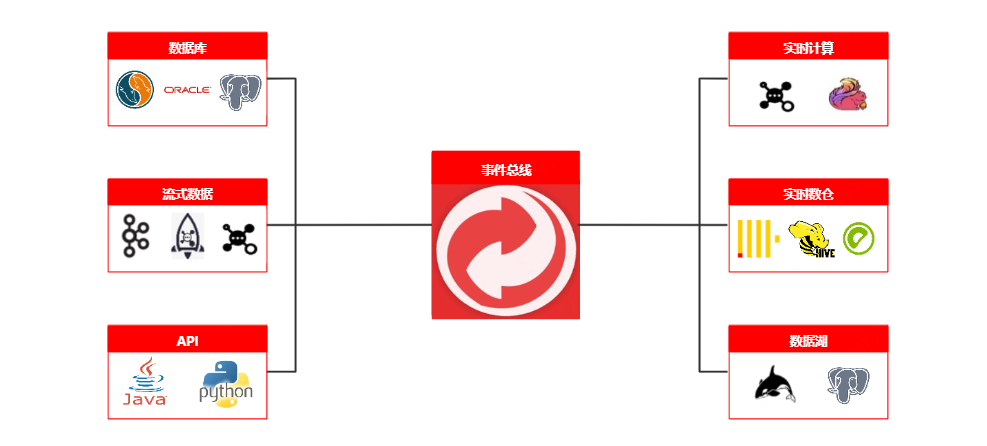
事件总线整体架构抽象为三层,source、transform 和sink。 通过连接器扩展机制实现数据引擎扩展, 并采用责任链模式处理数据链路, 插件化管理函数、脚本,实现实时消息接入、过滤、富化、转换、分发标准化处理, 并通过分组消费、降级机制保证架构高可用.
• 实时数据 : 风险核心场景,目前事件总线业务数据的主要来源; 。
• 事件总线
◦ Source: 数据输入层,风险业务数据的主要来源方式,目前大多数来源于JMQ2、JMQ4、FMQ等; 。
◦ Transform: 事件总线的核心处理层,同时也是自定义函数与自定义脚本的解析层,该层抽象了大量的算子,如,数据解析算子、过滤算子、富化算子、转换算子等等当复杂消息体数据经过一系列算子之后,最终会转化为单层key-value标准结构; 。
◦ Sink: 数据输出层,经Transform组件转换后,此时的数据可以发实时消息给各个消息队列,也可以存储到Clickhouse、Es、R2m等数据库; 。
• 数据服务 : 基于事件总线标准化后沉淀的数据所支撑的平台应用; 。
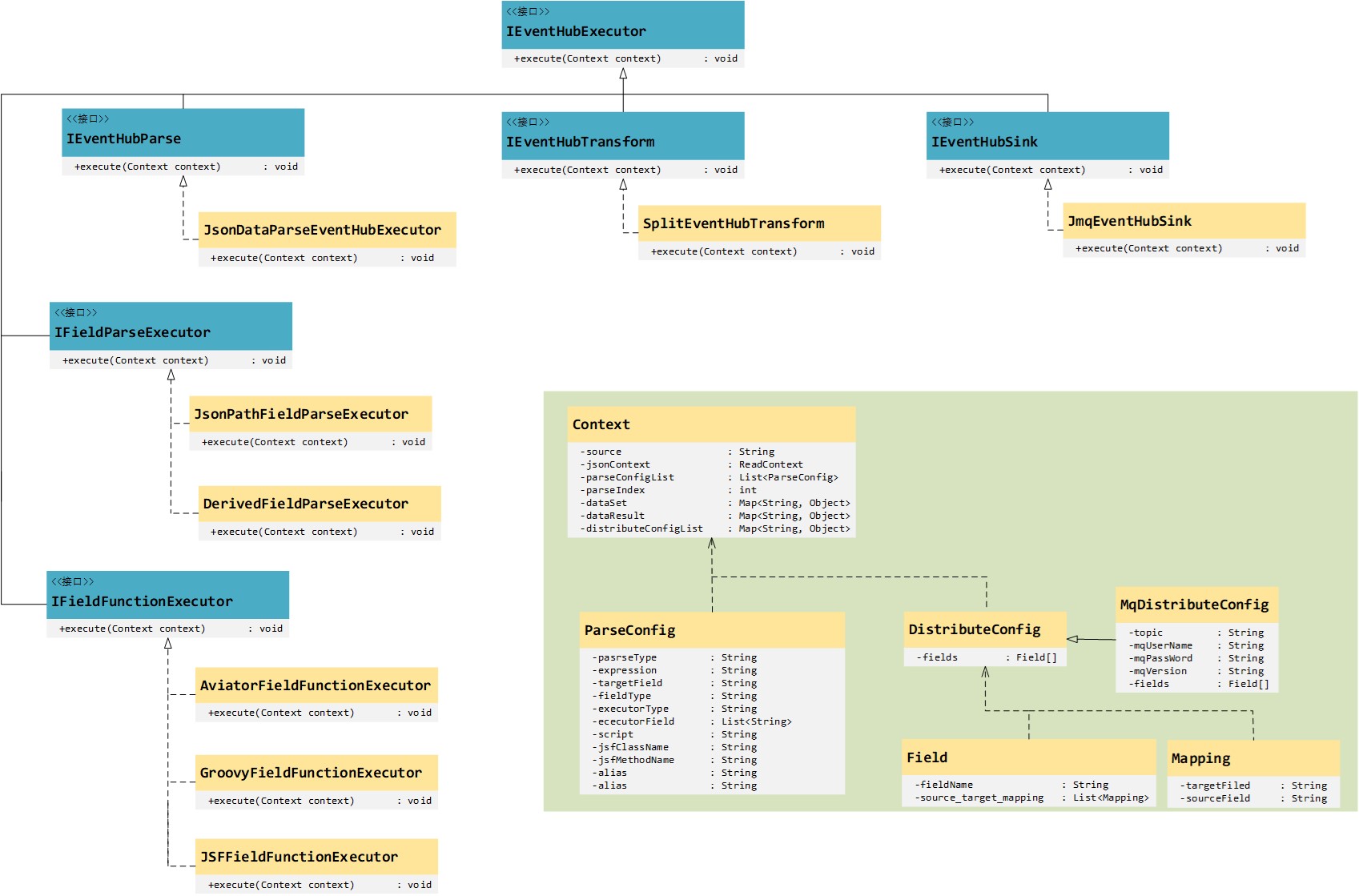
事件总线定义了一个顶层父接口IEventHubExecutor,并定义了一个execute方法,其三个主要子接口,IEventHubParse、IEventHubTransform与IEventHubSink分别对应于事件总线的三个组成部分,source、transform和sink。通过实现这三个子接口,便可以完成对不同中间件的适配问题。比如,目前事件总线仅支持解析的数据写入到Clickhouse,但业务需求需要做检索,那么很显然数据存储在Es要优于存储在Clickhouse,所以此时需要扩展一个JesEventHubSink来实现IEventHubSink即可.
其中Context作为上下文,贯穿了整个事件总线的执行过程,上下文中包含了解析过程中所需要的一起信息,比如,从哪里来的数据、要解析哪些字段、解析好的数据送到那里去等等.
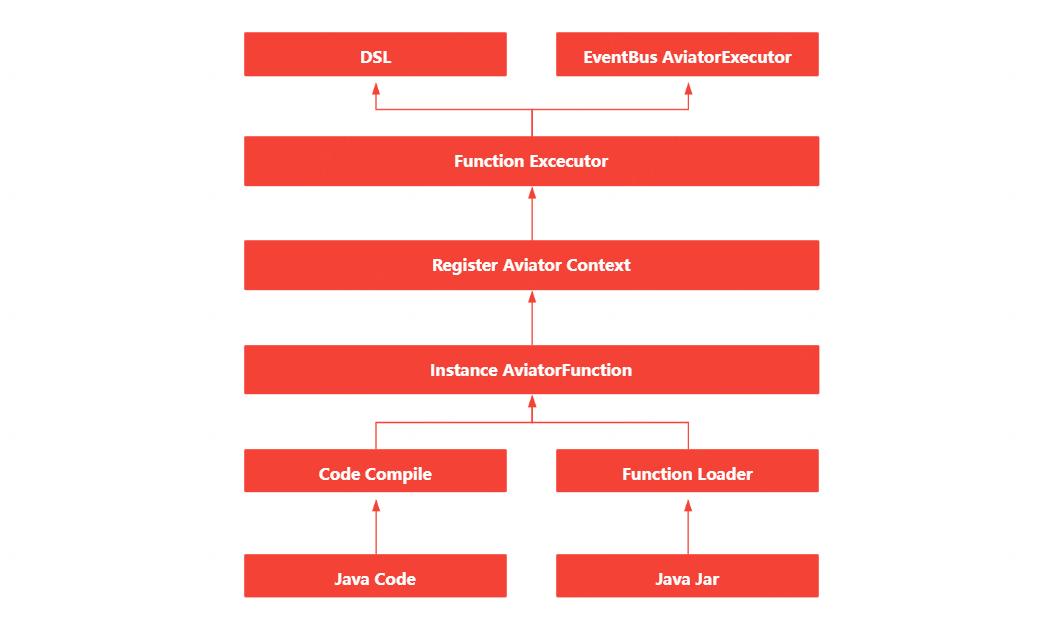
自定义函数的实现,其实借助了开源框架Avaitor表达式,Aviator是一个轻量级、高性能的Java表达式执行引擎, 它动态地将表达式编译成字节码并运行,主要用于各种表达式的动态求值。相比Groovy这样的重量级脚本语言,Aviator是非常轻量级的表达式执行引擎.
• 函数解析器:自定义函数支持脚本编写(脚本采用groovy,同时为了更加“亲民”,采用Java语法)与Jar包上传两种方式; 。
• 函数编译器:编译脚本与解析jar包,生成对应的AvaitorFunction实例; 。
• 函数注册器:将生成的AvaitorFunction实例注册到Avaitor的上下文中; 。
• 函数执行器:通过实现FunctionExecutor,便可以对函数方便的调用; 。
事件总线解析能力的提升,也很大一部分归结于分组消费的设计,对流量做到灵活分流,对机器做到物尽其用。动态分组,又分为物理分组与逻辑分组,如下图:
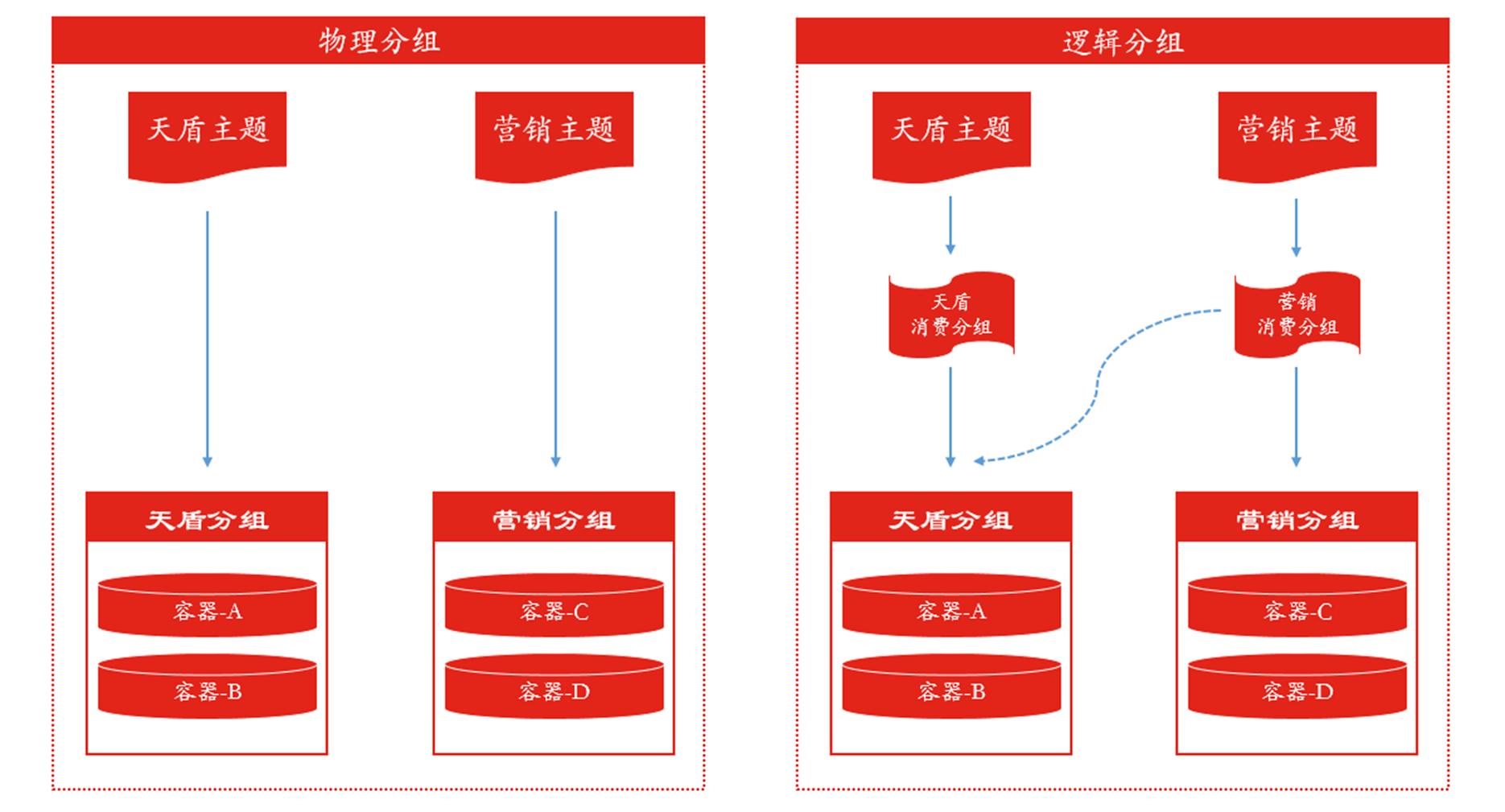
• 物理分组:单纯依靠机器划分,规定好哪些机器消费哪些主题,如,天盾分组就消费天盾主题,营销分组就消费营销主题.
• 逻辑分组:逻辑分组与物理分组的区别在于,逻辑分组在物理分组之上,又抽象出一个消费组的概念,用机器与消费组绑定,而非直接与主题绑定,这样带来的好处就是,可以更加方便的调配流量,如,营销流量非常大,那么可以直接动态调配,使天盾分组也去消费营销主题,既能充分利用天盾分组机器,又能提高营销主题消费能力.
一键降级更多的用于大促期间,但是为了降的更加“人性化”,一键降级我们也做了分类:丢弃降级与积压降级,如下图:
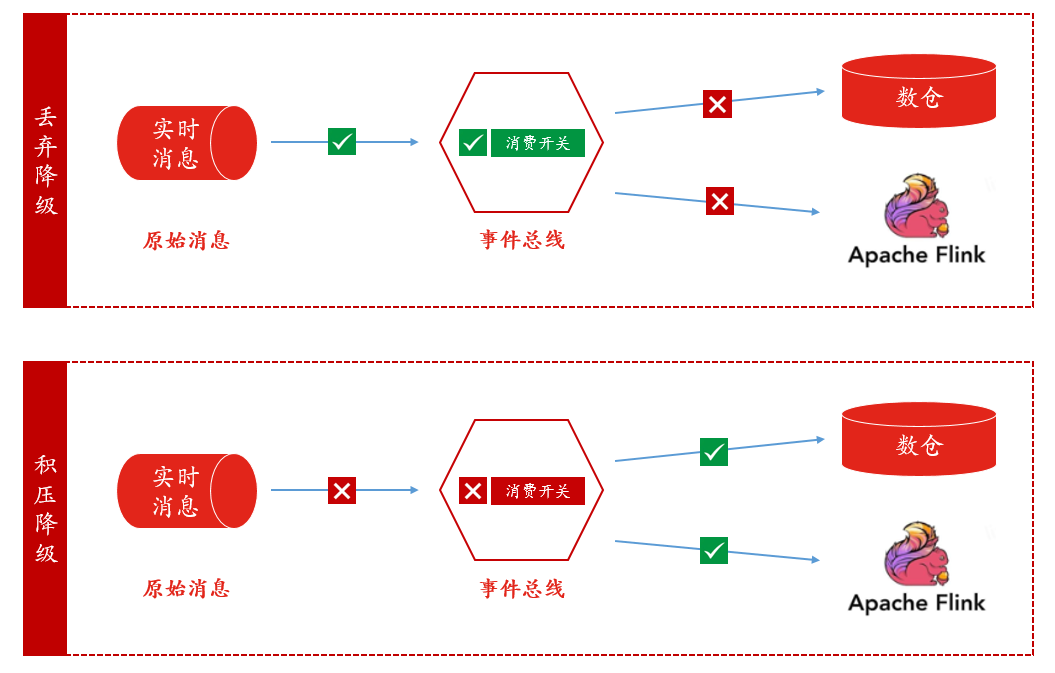
• 丢弃降级:所降级主题处于消费状态,顾名思义,事件总线拿到了数据,就直接将数据丢弃,降级期间数据是不可找回的;丢弃降级可用于业务方并不在意一时数据的丢失或者压测场景.
• 积压降级:所降级主题处于非消费状态,降级期间数据积压在消息平台,降级过后,再开启消费;积压降级可用于业务方允许降级期间内没有新数据,但是降级过后数据又可查场景.
事件总线的流量监控现依赖于ump,对单个主题以及所有主题的入口都设有埋点,数据在每个关键流转位置解析性能以及流量都能被监控,代码片段如下:
Profiler.registerInfo(this.getClass().getSimpleName(), UmpUtil.UMP_APP_NAME, false, true);
自事件总线上线以来,已经经历了多次大促考验,大促解析量已达5000w/min,日常解析量也已2000w/min,伴随着风险洞察平台被越来越多的部门所使用,事件总线已然成为其重要组成部分,为了更好的提高解析性能,就需要去做更多的探索。同时,目前事件总线做的更多的是对实时数据的处理,未来我们也将推进flink-cdc等技术在事件总线中的应用.
最后此篇关于风险洞察之事件总线的探索与演进的文章就讲到这里了,如果你想了解更多关于风险洞察之事件总线的探索与演进的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
多年来,这一直是令人困惑和沮丧的根源。假设您导入了一个文档记录特别差的模块,并且您需要的某个方法只有 **kwargs 作为其参数,您应该如何知道该方法正在检查哪些键? def test(**kwar
一:背景 1. 讲故事 前几天写了一篇 如何洞察 .NET程序 非托管句柄泄露 的文章,文中使用 WinDbg 的 !htrace 命令实现了句柄泄露的洞察,在文末我也说了,Wi
所以我正在尝试使用 Facebook Python API提取我们的参与数据(点赞、分享等,基本上是 Facebook 网站上“洞察”选项卡下的所有内容)。 我已设法通过 API 建立连接并使访问 t
我注意到从 facebook insights 返回的数据在从 API 获取数据时与从 CSV 导出数据中获取时存在一致的差异。例如,对于某个指标 (page_impressions_unique_d
我用 Python 创建了一个 XGBoost 模型,并使用以下代码来更好地理解该模型: xgb.plot_importance(model) 或 xgb.plot_importance(model,
谁能告诉我 Visual Studio 的内存转储中概述的行为类型 正常吗?例如,StackExchange.Redis.PhysicalConnection 在包含大小(字节)上运行得那么高吗?还是
谁能告诉我 Visual Studio 的内存转储中概述的行为类型 正常吗?例如,StackExchange.Redis.PhysicalConnection 在包含大小(字节)上运行得那么高吗?还是

 个人中心
个人中心 文章发布
文章发布