
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


图神经网络(GNN)目前的主流实现方式就是节点之间的信息汇聚,也就是类似于卷积网络的邻域加权和,比如图卷积网络(GCN)、图注意力网络(GAT)等。下面根据GCN的实现原理使用Pytorch张量,和调用torch_geometric包,分别对Cora数据集进行节点分类实验.
Cora是关于科学文献之间引用关系的图结构数据集。数据集包含一个图,图中包括2708篇文献(节点)和10556个引用关系(边)。其中每个节点都有一个1433维的特征向量,即文献内容的嵌入向量。文献被分为七个类别:计算机科学、物理学等.
对于某个GCN层,假设输入图的节点特征为$X\in R^{|V|\times F_{in}}$,边索引表示为序号数组$Ei\in R^{2\times |E|}$,GCN层输出$Y\in R^{|V|\times F_{out}}$。计算流程如下:
0、根据$Ei$获得邻接矩阵$A_0\in R^{|V|\times |V|}$.
1、为了将节点自身信息汇聚进去,每个节点添加指向自己的边,即 $A=A_0+I$,其中$I$为单位矩阵.
2、计算度(出或入)矩阵 $D$,其中 $D_{ii}=\sum_j A_{ij}$ 表示第 $i$ 个节点的度数。$D$为对角阵.
3、计算对称归一化矩阵 $\hat{D}$,其中 $\hat{D}_{ii}=1/\sqrt{D_{ii}}$.
4、构建对称归一化邻接矩阵 $\tilde{A}$,其中 $\tilde{A}= \hat{D} A \hat{D}$.
5、计算节点特征向量的线性变换,即 $Y = \tilde{A} X W$,其中 $X$ 表示输入的节点特征向量,$W\in R^{F_{in}\times F_{out}}$ 为GCN层中待训练的权重矩阵.
即:
$Y=D^{-0.5}(A_0+I)D^{-0.5}XW$ 。
在torch_geometric包中,normalize参数控制是否使用度矩阵$D$归一化;cached控制是否缓存$D$,如果每次输入都是相同结构的图,则可以设置为True,即所谓转导学习(transductive learning)。另外,可以看到GCN的实现只考虑了节点的特征,没有考虑边的特征,仅仅通过聚合引入边的连接信息.
Cora的图数据存放在torch_geometric的Data类中。Data主要包含节点特征$X\in R^{|V|\times F_v}$、边索引$Ei\in R^{2\times |E|}$、边特征$Ea\in R^{|E|\times F_e}$等变量。首先导出Cora数据:
from
torch_geometric.datasets
import
Planetoid
cora
= Planetoid(root=
'
./data
'
, name=
'
Cora
'
)[0]
print
(cora)
构建GCN,训练并测试.
import
torch
from
torch
import
nn
from
torch_geometric.nn
import
GCNConv
import
torch.nn.functional as F
from
torch.optim
import
Adam
class
GCN(nn.Module):
def
__init__
(self, in_channels, hidden_channels, class_n):
super(GCN, self).
__init__
()
self.conv1
=
GCNConv(in_channels, hidden_channels)
self.conv2
=
GCNConv(hidden_channels, class_n)
def
forward(self, x, edge_index):
x
=
torch.relu(self.conv1(x, edge_index))
x
= torch.dropout(x, p=0.5, train=
self.training)
x
=
self.conv2(x, edge_index)
return
torch.log_softmax(x, dim=1
)
model
= GCN(cora.num_features, 16, cora.y.unique().shape[0]).to(
'
cuda
'
)
opt
= Adam(model.parameters(), 0.01, weight_decay=5e-4
)
def
train(its):
model.train()
for
i
in
range(its):
y
=
model(cora.x, cora.edge_index)
loss
=
F.nll_loss(y[cora.train_mask], cora.y[cora.train_mask])
loss.backward()
opt.step()
opt.zero_grad()
def
test():
model.eval()
y
=
model(cora.x, cora.edge_index)
right_n
= torch.argmax(y[cora.test_mask], 1) ==
cora.y[cora.test_mask]
acc
= right_n.sum()/
cora.test_mask.sum()
print
(
"
Acc:
"
, acc)
for
i
in
range(15
):
train(
1
)
test()
仅15次迭代就收敛,测试精度如下:
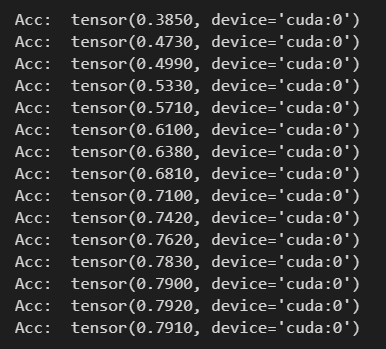
主要区别就是自定义一个My_GCNConv来代替GCNConv,My_GCNConv定义如下:
from
torch
import
nn
from
torch_geometric.utils
import
to_dense_adj
class
My_GCNConv(nn.Module):
def
__init__
(self, in_channels, out_channels):
super(My_GCNConv, self).
__init__
()
self.weight
=
torch.nn.Parameter(nn.init.xavier_normal(torch.zeros(in_channels, out_channels)))
self.bias
=
torch.nn.Parameter(torch.zeros([out_channels]))
def
forward(self, x, edge_index):
adj
=
to_dense_adj(edge_index)[0]
adj
+=
torch.eye(x.shape[0]).to(adj)
dgr
= torch.diag(adj.sum(1)**-0.5
)
y
=
torch.matmul(dgr, adj)
y
=
torch.matmul(y, dgr)
y
=
torch.matmul(y, x)
y
= torch.matmul(y, self.weight) +
self.bias
return
y
其它代码仅将GCNConv修改为My_GCNConv.
下面不使用节点之间的引用关系,仅使用节点特征向量在MLP中进行实验,来验证GCN的有效性.
import
torch
from
torch
import
nn
import
torch.nn.functional as F
from
torch.optim
import
Adam
class
MLP(nn.Module):
def
__init__
(self, in_channels, hidden_channels, class_n):
super(MLP, self).
__init__
()
self.l1
=
nn.Linear(in_channels, hidden_channels)
self.l2
=
nn.Linear(hidden_channels, hidden_channels)
self.l3
=
nn.Linear(hidden_channels, class_n)
def
forward(self, x):
x
=
torch.relu(self.l1(x))
x
=
torch.relu(self.l2(x))
x
= torch.dropout(x, p=0.5, train=
self.training)
x
=
self.l3(x)
return
torch.log_softmax(x, dim=1
)
model
= MLP(cora.num_features, 512, cora.y.unique().shape[0]).to(
'
cuda
'
)
opt
= Adam(model.parameters(), 0.01, weight_decay=5e-4
)
def
train(its):
model.train()
for
i
in
range(its):
y
=
model(cora.x[cora.train_mask])
loss
=
F.nll_loss(y, cora.y[cora.train_mask])
loss.backward()
opt.step()
opt.zero_grad()
def
test():
model.eval()
y
=
model(cora.x[cora.test_mask])
right_n
= torch.argmax(y, 1) ==
cora.y[cora.test_mask]
acc
= right_n.sum()/
cora.test_mask.sum()
print
(
"
Acc:
"
, acc)
for
i
in
range(15
):
train(
30
)
test()
可以看出MLP包含了3层,并且隐层参数比GCN多得多。结果如下:
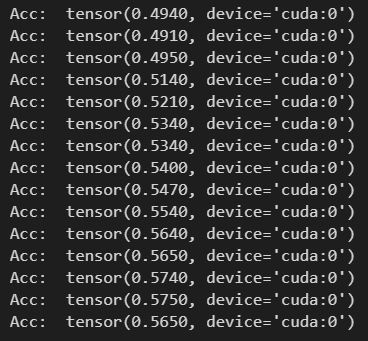
精度收敛在57%左右,效果比GCN的79%差。说明节点之间的链接关系对节点类别的划分有促进作用,以及GCN的有效性.
最后此篇关于图卷积神经网络分类的pytorch实现的文章就讲到这里了,如果你想了解更多关于图卷积神经网络分类的pytorch实现的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
这与 Payubiz payment gateway sdk 关系不大一体化。但是,主要问题与构建项目有关。 每当我们尝试在模拟器上运行应用程序时。我们得到以下失败: What went wrong:
我有一个现有的应用程序,其中包含在同一主机上运行的 4 个 docker 容器。它们已使用 link 命令链接在一起。 然而,在 docker 升级后,link 行为已被弃用,并且似乎有所改变。我们现
在 Internet 模型中有四层:链路 -> 网络 -> 传输 -> 应用程序。 我真的不知道网络层和传输层之间的区别。当我读到: Transport layer: include congesti
很难说出这里要问什么。这个问题模棱两可、含糊不清、不完整、过于宽泛或夸夸其谈,无法以目前的形式得到合理的回答。如需帮助澄清此问题以便重新打开,visit the help center . 关闭 1
前言: 生活中,我们在上网时,打开一个网页,就可以看到网址,如下: https😕/xhuahua.blog.csdn.net/ 访问网站使用的协议类型:https(基于 http 实现的,只不过在
网络 避免网络问题降低Hadoop和HBase性能的最重要因素可能是所使用的交换硬件,在项目范围的早期做出的决策可能会导致群集大小增加一倍或三倍(或更多)时出现重大问题。 需要考虑的重要事项:
网络 网络峰值 如果您看到定期的网络峰值,您可能需要检查compactionQueues以查看主要压缩是否正在发生。 有关管理压缩的更多信息,请参阅管理压缩部分的内容。 Loopback IP
Pure Data 有一个 loadbang 组件,它按照它说的做:当图形开始运行时发送一个 bang。 NoFlo 的 core/Kick 在其 IN 输入被击中之前不会发送其数据,并且您无法在 n
我有一台 Linux 构建机器,我也安装了 minikube。在 minikube 实例中,我安装了 artifactory,我将使用它来存储各种构建工件 我现在希望能够在我的开发机器上做一些工作(这
我想知道每个视频需要多少种不同的格式才能支持所有主要设备? 在我考虑的主要设备中:安卓手机 + iPhone + iPad . 对具有不同比特率的视频进行编码也是一种好习惯吗? 那里有太多相互矛盾的信
我有一个使用 firebase 的 Flutter Web 应用程序,我有两个 firebase 项目(dev 和 prod)。 我想为这个项目设置 Flavors(只是网络没有移动)。 在移动端,我
我正在读这篇文章Ars article关于密码安全,它提到有一些网站“在传输之前对密码进行哈希处理”? 现在,假设这不使用 SSL 连接 (HTTPS),a.这真的安全吗? b.如果是的话,你会如何在
我试图了解以下之间的关系: eth0在主机上;和 docker0桥;和 eth0每个容器上的接口(interface) 据我了解,Docker: 创建一个 docker0桥接,然后为其分配一个与主机上
我需要编写一个java程序,通过网络将对象发送到客户端程序。问题是一些需要发送的对象是不可序列化的。如何最好地解决这个问题? 最佳答案 发送在客户端重建对象所需的数据。 关于java - 不可序列化对
所以我最近关注了this有关用 Java 制作基本聊天室的教程。它使用多线程,是一个“面向连接”的服务器。我想知道如何使用相同的 Sockets 和 ServerSockets 来发送对象的 3d 位
我想制作一个系统,其中java客户端程序将图像发送到中央服务器。中央服务器保存它们并运行使用这些图像的网站。 我应该如何发送图像以及如何接收它们?我可以使用同一个网络服务器来接收和显示网站吗? 最佳答
我正在尝试设置我的 rails 4 应用程序,以便它发送电子邮件。有谁知道我为什么会得到: Net::SMTPAuthenticationError 534-5.7.9 Application-spe
我正在尝试编写一个简单的客户端-服务器程序,它将客户端计算机连接到服务器计算机。 到目前为止,我的代码在本地主机上运行良好,但是当我将客户端代码中的 IP 地址替换为服务器计算机的本地 IP 地址时,
我需要在服务器上并行启动多个端口,并且所有服务器套接字都应在 socket.accept() 上阻塞。 同一个线程需要启动客户端套接字(许多)来连接到特定的 ServerSocket。 这能实现吗?
我的工作执行了大约 10000 次以下任务: 1) HTTP 请求(1 秒) 2)数据转换(0.3秒) 3)数据库插入(0.7秒) 每次迭代的总时间约为 2 秒,分布如上所述。 我想做多任务处理,但我

我是一名优秀的程序员,十分优秀!