
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4


谈到java中的并发,我们就避不开线程之间的同步和协作问题,谈到线程同步和协作我们就不能不谈谈jdk中提供的AbstractQueuedSynchronizer(翻译过来就是抽象的队列同步器)机制; 。
(一)、AQS中的state和Node含义:
AQS中提供了一个int volatile state状态的变量用来标识共享资源,AQS定义了两种资源的占用方式:
同时也提供了一个LCH队列,用来存放获取共享资源时候发生阻塞的Node节点,这个节点是对需要获取资源线程的一个封装,包含了线程本身和Node节点的状态waitStatus,一共分为五种:
/**表示当前节点中线程已经被取消调度,当timeout或者interrupt(假如会响应中断的话)会触发节点变更为此状态,此节点的状态再不会发生变化*/ 。
static final int CANCELLED = 1,
/**表示当前节点中线程释放资源后需要唤醒后继节点线程,在采用尾插法将新结点加入到同步队列的时候,会将新结点的前继节点设置为SIGNAL */ static final int SIGNAL = -1; /**表示当前节点中的线程在等待一个Condition唤醒,在其他线程中调用了这个Condition的signal()会将此Node从等待队列的队头转移到同步队列的队尾,尝试竞争共享资源 */ static final int CONDITION = -2; /**共享模式下,当前节点中的线程不仅需要唤醒后继节点,还需要唤醒后继节点的后继节点*/ static final int PROPAGATE = -3,
除了上面这四种还有一个0,表示节点初始状态,可以看出waitStatus<0才代表该节点是一个有效节点( 即结点中的线程可以正常调度 ).
AQS的设计其实是采用了模版方法的设计思想,在AbstractQueuedSynchronizer中这个顶层类中只提供了一些公共的方法实现如:同步队列的维护等,而共享资源的获取和释放只提供了方法的定义,并不提供具体的实现(只是抛出了 unsupportedOperationException异常),通过这种方式就达到让自定义的队列同步器去强制实现的目的.
上面我们提到,AQS定义了资源的两种占用方式:独占和共享,主要也就对应tryAcquire()-tryRelease(),tryAcquireShared()-tryReleaseShared()两组方法需要我们自己去实现了:
1、tryAcquire()独占模式,尝试获取资源,成功为true,失败为false,
2、tryRelease()独占模式,尝试释放资源,成功为true,失败为false,
3、tryAcquireShared()共享模式,尝试获取资源,负数为失败,等于0为成功获取,没有剩余资源,大于0为成功获取,有剩余共享资源; 。
4、tryReleaseShared()共享模式,尝试释放资源,释放之后需要唤醒等待节点为true,否则为false,
(二)、代码剖析:
1、acquire(int)方法:
此方法是获取共享资源的入口方法,代码如下:
public
final
void
acquire(
int
arg) {
/*尝试获取共享资源,尝试成功直接返回
*/
if
(!
tryAcquire(arg)
/*
1、抢占共享资源失败,则将当前节点放入到同步队列的尾部,并标记为独占模式;
* 2、使线程阻塞在同步队列中获取资源,直到获取成功才返回;如果整个过程中被中断过就返回true,否则就返回false;
*/
&&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) {
/*
阻塞获取资源的过程中是不响应线程中断的,内部进行了中断检测,检测到了中断请求,所以这块进行线程中断
*/
selfInterrupt();
}
}
上面代码的大概执行流程是:
1、加塞抢占共享资源(因为同步队列中可能还有其它节点等待),获取成功则直接返回; 。
2、当前线程抢占共享资源失败,调用addWaiter()将当前线程包装成Node节点,加入同步队列的尾部,并将当前节点标记为独占模式(EXCLUSIVE),并返回这个节点,
3、当前线程调用acquireQueued()方法阻塞在同步队列上获取共享资源,该方法是一个同步方法,直到成功获取了共享资源才会返回,在这个阻塞获取资源的过程中,如果检测到发生了线程的中断会返回true,否则会返回false,
4、在第3步中阻塞获取资源的过程中也不会响应中断,所以在上个获取共享过程中,检测到了线程中断标记会在acquireQueued()方法返回为true时候,再调用selfInterrupt()中断一次线程; 。
2、addWaiter(Node mode)方法:
private
Node addWaiter(Node mode) {
/*
以给定的模式将当前线程包装成node节点
*/
Node node
=
new
Node(Thread.currentThread(), mode);
/*
快速采用尾插法,将当前节点插入到同步队列的队尾
*/
Node predNode
=
tail;
if
(predNode !=
null
) {
/*
preNode <-- node
*/
node.prev
=
predNode;
/*
采用CAS将node设置阻塞队列的尾节点,设置成功,说明没有并发
*/
if
(compareAndSetTail(tail, node)) {
predNode.next
=
node;
/*
尾插法插入成功,则直接返回当前节点
*/
return
node;
}
}
/*
"自旋"将节点加入到队列的尾部,直到成功为止
*/
enq(node);
return
node;
}
此方法是当前线程首次抢占共享资源不成功,将当前线程以指定的模式(独占或者共享)包装成Node插入到同步队列的尾节点的方法,其执行逻辑也在代码中详细注释了,再概括下:
1、将当前线程包装为一个新的Node节点,并标记为独占模式; 。
2、如果当前同步队列的尾节点不为空( 表示当前队列不为空 ),采用尾插法,将新的Node节点插入到同步队列的尾部,考虑到多线程并发的安全问题采用了CAS方式设置同步队列的尾节点,设置成功则就直接返回这个新结点; 。
3、如果快速插入不成功( 可能有两种情况:1、tail为空,即当前同步队列为空;2、tail不为空,但是在使用CAS设置尾节点的时候出现了线程并发安全问题 ),则就调用enq(Node),采用 “自旋” , 直到 。
将新结点成功插入到同步队列的尾部; 。
3、enq(Node) 方法:
private
Node enq(
final
Node node) {
/*
"自旋",将给定的节点插入到同步队列的尾部
*/
for
(;;) {
Node t
=
tail;
/*
同步队列为空,则创建一个thread为null的Node节点作为同步队列的头结点,并且将尾节点也设置为头结点
*/
if
(t ==
null
) {
/*
CAS操作,设置同步队列的头结点
*/
if
(compareAndSetHead(
new
Node())) {
/*
将尾节点设置为头结点,进入下次"自旋"
*/
tail
=
head;
}
}
else
{
/*
尾部节点不为空,则进行正常添加动作
*/
node.prev
=
t;
/*
CAS操作,设置同步队列的头结点
*/
if
(compareAndSetTail(t, node)) {
t.next
=
node;
return
t;
}
}
}
}
此方法采用了“自旋”操作,并结合CAS操作,在保证多线程并发线程安全的前提下,一定可以安全地将这个新结点插入到同步队列的尾部.
此段代码的执行流程是:
1、判断这个同步队列是否为空(判断tail为空即可),为空则创建一个空节点(不包含任何线程),并向尾节点也指向头结点, 。
2、然后进行下一次的自旋尝试CAS操作,将方法传入的Node节点尝试加入到队列的尾部,也通过一定次数的自旋操作,一定会加入到同步队列的尾部,然后退出; 。
3、如果一开始进入这个方法,队列不为空,则就执行第2步骤不断尝试,直到成功; 。
到此为止addWaiter()方法中的逻辑就分析完了,执行完毕之后返回,就行调用acquireQueued(Node)方法阻塞此线程,等待获取资源了.
acquireQueued(Node,int)方法:
final
boolean
acquireQueued(
final
Node node,
int
arg) {
/*
标记阻塞获取资源的过程中是否发生了异常
*/
boolean
failed =
true
;
try
{
/*
标记线程阻塞的过程中是否发生了中断
*/
boolean
interrupted =
false
;
/*
线程自旋阻塞
*/
for
(;;){
/*
获取当前节点的前驱结点
*/
final
Node p =
node.predecessor();
/*1、
前驱结点是头结点,则说明当前线程有资格获取共享资源,尝试获取,获取成功,将当前节点设置为头结点
*/
if
(p == head &&
tryAcquire(arg)) {
/*
将当前节点设置为头结点
*/
setHead(node);
p.next
=
null
;
//
help GC
failed =
false
;
/*返回线程在阻塞的过程中是否接受到了中断请求*/
return
interrupted;
}
/*2、3
当前节点的前驱结点不是头结点,判断当前线程是否可以挂起
*/
if
(shouldParkAfterFailedAcquire(p, node)
/*4、
当前线程可以挂起,则挂起线程,并且线程被unpark()或者interrupt()唤醒,检查线程的状态
*/
&&
parkAndCheckInterrupt()) {
interrupted
=
true
;
}
}
}
finally
{
if
(failed) {
/*5、
阻塞获取同步资源的时候,发生了异常,将当前Node节点从同步队列中出队
*/
cancelAcquire(node);
}
}
acquireQueued(Node)这个方法的目的就是使得当前线程阻塞,等待获取资源,获取成功之后才返回。那么如何阻塞呢?看了上面的代码,读到这里我想大家心里都有了答案: 要么自旋,要么主动park() ,此方法中采用了这两种方式结合的方法,其大致的执行流程如下:
1、自旋,首先当前节点的前继节点是头结点(走到这里来了,说明前继节点正在占用共享资源,有可能在这个过程中正好释放了),那么我们当前线程就有资格去尝试获取共享资源,如果获取共享资源成功,则结束自旋阻塞; 。
2、如果前继节点不是头结点,或者争抢共享资源失败,那么我们调用shouldParkAfterFailedAcquire(Node,Node)方法,判断是否可以将此线程暂时挂起( 不能无限制地自旋,会造成CPU占用率飙升,安全的做法是自旋找到一个合适的点,将当前线程park()阻塞挂起 ),
3、当前挂起之前,要向前寻找能将它唤醒的前继节点,待前继节点释放资源之后,unpark()唤醒当前被阻塞的节点; 。
4、线程已经到达安全点,可以调用parkAndCheckInterrupt()阻塞并等待唤醒,唤醒之后再检查下,阻塞的这个过程中是否发生了线程中断请求,由于这个阻塞过程是不响应线程中断的,所以需要将这个中断请求的状态传播出去; 。
5、阻塞获取同步资源的时候,发生了异常,取消当前线程的在同步队列中的排队; 。
shouldParkAfterFailedAcquire(Node, Node )方法:
private
static
boolean
shouldParkAfterFailedAcquire(Node pred, Node node) {
int
ws =
pred.waitStatus;
/*
判断前驱结点的状态,只有前驱结点的状态为SIGNAL,后继节点才能被唤醒,所以其可以安心地挂起来了
*/
if
(ws ==
node.waitStatus) {
return
true
;
}
/*
ws>0表示前驱结点中的线程已经被取消调度了,则认为其是无效节点,继续向前查找,直至找到有效状态的节点
*/
if
(ws > 0
) {
do
{
node.prev
= pred =
pred.prev;
}
while
(pred.waitStatus > 0
);
pred.next
=
node;
}
else
{
/*
前驱结点状态正常,将前驱结点状态设置为SIGNAL,则前驱结点释放资源的时候,就可以尝试唤醒当前这个后继节点了
*/
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return
false
;
}
这个方法是在自旋中用来判断是否可以将线程安全地park(),阻塞自旋的,那么何时才能将当前线程安全地挂起呢?回想下,我们之前提到的节点的五种状态中有一种SIGNAL,表示当前节点的线程释放资源,可以唤醒后继节点,所以我们就在线程挂起之前找到它的有效的前继结点,将它的waitStatus状态设置为SIGNAL,就可以保证前继节点释放资源之后,当前节点中的线程就可以被及时地唤醒,结束阻塞了,当前线程挂起之前的准备工作都做完了,那么接下来就需要调用parkAndCheckInterrupt()方法,进行线程的挂起了.
parkAndCheckInterrupt()方法:
private
final
boolean
parkAndCheckInterrupt() {
LockSupport.park(
this
);
return
Thread.interrupted();
}
执行到这里了,说明线程可以阻塞,调用park()方法阻塞线程,等待其他线程中unpark()或者interrupt()唤醒次线程,唤醒之后执行Thread.interrupted()方法,检测阻塞过程中的线程请求中断,进入下次自旋,尝试获取共享资源。如果在阻塞获取资源的过程中,发生了异常,failed = true,则执行finally中cancelAcquire(Node)方法,取消当前节点中线程的调度.
上面说了分析了这么多, 只说了线程间的获取资源时候的同步问题,那么线程间的协作在哪里体现呢? 答案就是在acquireQueued(Node,int)方法中的finally块中,线程在阻塞获取共享资源的时候发生了异常,就会执行此方法将此节点从同步队列中出队,下面我们来分析下cancelAcquire(Node)方法:
cancelAcquire(Node)方法:
1
private
void
cancelAcquire(Node node) {
2
//
当前节点为空,则说明当前线程永远不会被调度到了,所以直接返回
3
if
(node ==
null
) {
4
return
;
5
}
6
7
/**
8
* 接下来将点前Node节点从同步队列出队,主要做以下几件事:
9
* 1、将当前节点不与任何线程绑定,设置当前节点为Node.CANCELLED状态;
10
* 2、将当前取消节点的前置非取消节点和后置非取消节点"链接"起来;
11
* 3、如果前置节点释放了锁,那么当前取消节点承担起后续节点的唤醒职责。
12
*/
13
14
//
1、取消当前节点与线程的绑定
15
node.thread =
null
;
16
17
//
2、找到当前节点的有效前继节点pred
18
Node pred =
node.prev;
19
while
(pred.waitStatus > 0
) {
20
//
为什么双向链表从后往前遍历呢?而不是从前往后遍历呢?
21
node.prev = pred =
pred.prev;
22
}
23
//
用作CAS操作时候的条件判断需要使用的值
24
Node predNext =
pred.next;
25
26
//
3、将当前节点设置为取消状态
27
node.waitStatus =
Node.CANCELLED;
28
29
/**
30
* 接下来就需要将当前取消节点的前后两个有效节点"链接"起来了,"达成让当前node节点出队的目的"。
31
* 这里按照node节点在同步队列中的不同位置分了三种情况:
32
* 1、node节点是同步队列的尾节点tail;
33
* 2、node节点既不是同步队列头结点head的后继节点,也不是尾节点tail;
34
* 3、node节点是同步队列头结点head的后继节点;
35
*/
36
37
//
1、node是尾节点,并且执行过程中没有并发,直接将pred设置为同步队列的tail
38
if
(node == tail &&
compareAndSetTail(node, pred)) {
39
/*
40
* 此时pred已经设置为同步队列的tail,需要通过CAS操作,将pred的next指向null,没有节点再引用node,就完成了node节点的出队
42
*/
43
compareAndSetNext(pred, predNext,
null
);
44
}
else
{
45
/*
46
* 2、node不是尾节点,也不是头结点head的后继节点,那么当前节点node出队以后,node的有效前继结点pred,
47
* 就有义务在它自身释放资源的时候,唤醒node的有效后继节点successor,即将pred的状态设置为Node.SIGNAL;
48
*/
49
int
ws;
50
//
能执行到这里,说明当前node节点不是head的后继节点,也不是同步队列tail节点
51
if
(pred != head &&
52
((ws = pred.waitStatus) == Node.SIGNAL ||
53
//
前继节点状态虽然有效但不是SIGNAL,采用CAS操作设置为SIGNAL确保后继有效节点可以被唤醒
54
(ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) &&
55
pred.thread !=
null
) {
56
Node next =
node.next;
57
//
只负责唤醒有效后继节点
58
if
(next !=
null
&& next.waitStatus <= 0
) {
59
/**
60
* 下面这段代码相当于将pred-->next,我们提到这个同步队列是个双向队列,那么pred<--next这是谁执行的呢?
61
* 答案是其他线程:其它线程在后序的获取共享资源在同步队列中阻塞的时候,调用shouldParkAfterFailedAcquire()方法,
62
* 从后向前遍历队列,寻找能唤醒它的有效前继节点,当找到node的时候,因为它的状态已经是Node.CANCELLED,所以会忽略node节点,
63
* 直到遍历到有效前继节点pred,将next.prev执行pred,即next--->pred,没有节点再引用node节点,所以node节点至此才完成出队。
64
*/
65
compareAndSetNext(pred, predNext, next);
66
}
67
}
else
{
68
//
3、说明node节点是同步队列head的后继节点,调用unparkSuccessor(Node)唤醒其他线程,达到让当前node"出队"。
69
unparkSuccessor(node);
70
}
71
72
node.next = node;
//
help GC
73
}
74
}
这个方法的中的注释写的很详细了,线程间的协作主要体现在第65行的代码中,原因也在注释中写明了,就不再赘述了.
还有一个非常关键的问题就是: 为什么我们在遍历同步队列的时候是从尾部向前遍历,而不是从头部向尾部遍历呢?我们可以回过头去看看入队时候的enq(Node)方法:
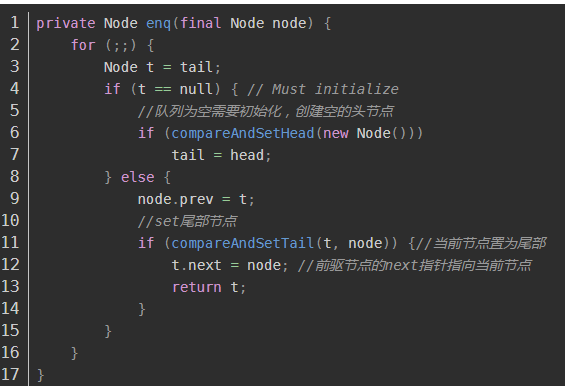
关键在11行-14行这部分代码中,11行保证了多线程环境下,采用自旋可以将当前线程顺利地加入到同步队列的尾部。 假如有线程A执行了满足了if条件,成功将线程A放入了tail节点,还未执行到12行,t.next = null,此时发生了线程切换执行B线程,B线程也执行了此方法,并且执行完毕,尾插法会将B线程节点追加到A线程节点之后,这时候又有个C线程执行了遍历操作,假设从队头向队尾遍历,遍历到A节点时,那么可能会出现t.next = null这种情况,停止遍历,漏掉B线程节点的情况,而采用从同步队列的尾部向头部遍历则可以避免这个问题.
下个 问题就是 u nparkSuccessor(node)方法的原理是什么呢?
unparkSuccessor(node)方法:
1
private
void
unparkSuccessor(Node node) {
2
/*
3
* If status is negative (i.e., possibly needing signal) try
4
* to clear in anticipation of signalling. It is OK if this
5
* fails or if status is changed by waiting thread.
6
*/
7
//
在这里,这个节点其实是同步队列的头结点,头结点唤醒后继节点之后,使命就完成了,所以应该将其状态置为0
8
int
ws =
node.waitStatus;
9
if
(ws < 0
)
10
compareAndSetWaitStatus(node, ws, 0
);
11
12
/*
13
* Thread to unpark is held in successor, which is normally
14
* just the next node. But if cancelled or apparently null,
15
* traverse backwards from tail to find the actual
16
* non-cancelled successor.
17
*/
18
Node s =
node.next;
19
//
因为s.next相当于从同步队列的头部遍历所以可能会出现s == null的情况,上面分析过原因,不再赘述了。
20
if
(s ==
null
|| s.waitStatus > 0
) {
21
s =
null
;
22
//
从同步队列的尾部向前遍历,找到当前node节点(头结点)的最近的有效后继节点
23
for
(Node t = tail; t !=
null
&& t != node; t =
t.prev)
24
if
(t.waitStatus <= 0
)
25
s =
t;
26
}
27
28
/**
29
* 找到最近的有效后继节点,则唤醒后继节点中的线程在parkAndCheckInterrupt()方法上的阻塞,去尝试竞争共享资源,
30
* 这就体现了线程之间的协作,而在这个竞争的过程中也会忽略这个Node.CANCELLED状态的节点,这当前node节点也就放弃了竞争共享资源的机会,相当于出队了。
31
*/
32
if
(s !=
null
)
33
LockSupport.unpark(s.thread);
34
}
以上就是对unparksuccessor(Node)方法的简单分析了。再回过头来,我们在cancelAcquire(Node)将当前要取消Node按照位置关系分为了三种,为什么我们会忽略head位置呢?
从setHead()的实现以及所有调用的地方可以看出,head指向的节点必定是拿到锁(或是竞争资源)的节点,而head的后继节点则是有资格争夺锁的节点,我们不在需要甚至唤醒条件了。再后续的节点,就是阻塞着的了。head指向的节点,曾经关联的线程必定已经获取到资源,在执行了,所以head无需再关联到该线程了。head所指向的节点,也无需再参与任何的竞争操作了。现在再来看node出队时的分类,就好理解了。head既然不会参与任何资源竞争了,自然也就和cancelAquire()无关了.
仔细分析这个acquire()方法流程非常复杂,找了个一张网上一个博主画的流程图非常棒,这里借鉴一下:
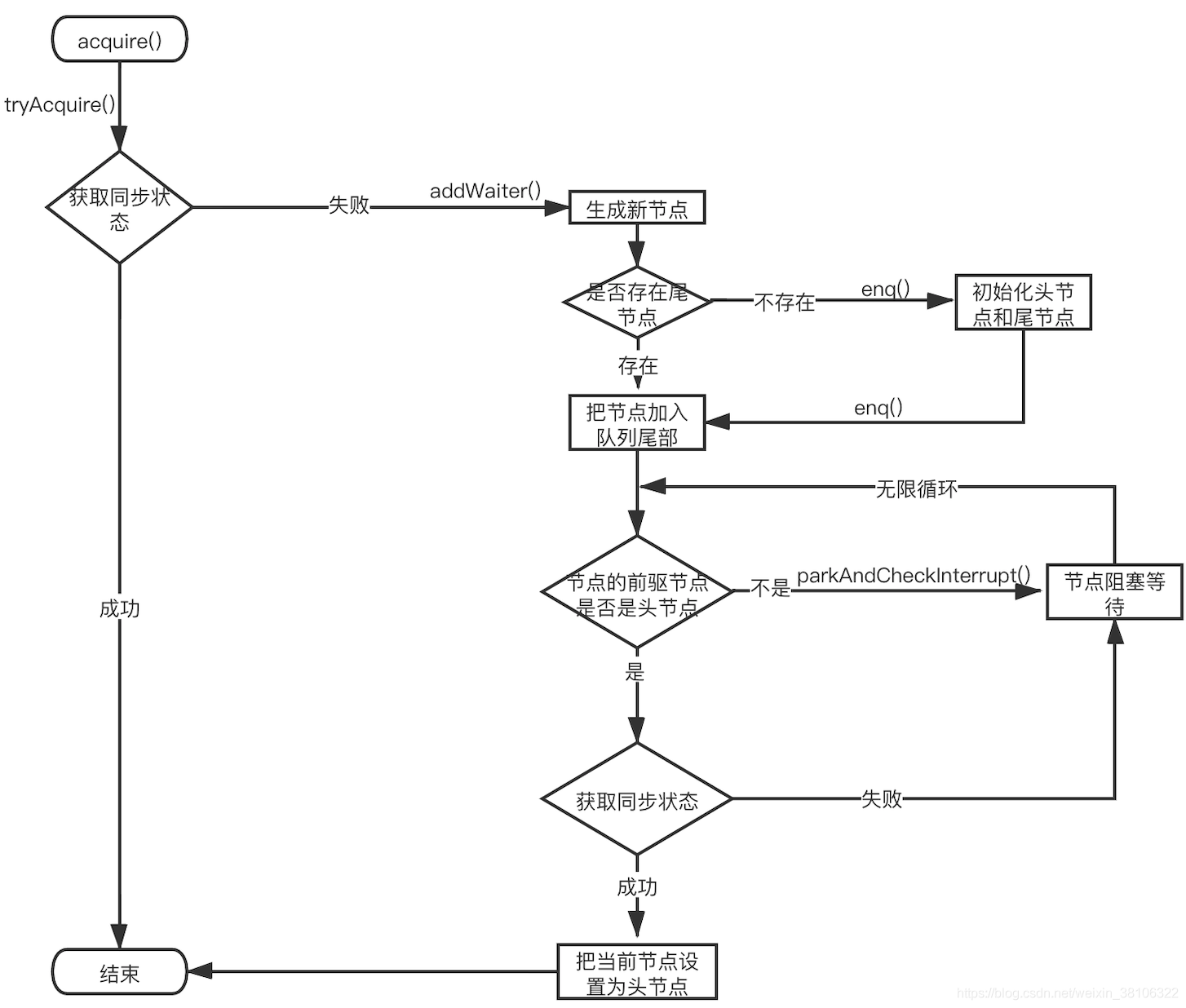
好了文章就写到这里了,鉴于水平有限,有说的不对的地方欢迎大家批评指正.
参考文章地址:
1、 https://blog.csdn.net/weixin_38106322/article/details/107121149 。
2、https://www.jianshu.com/p/01f2046aab64 。
3、 https://blog.csdn.net/foxException/article/details/108917338 。
最后此篇关于多线程并发:以AQS中acquire()方法为例来分析多线程间的同步与协作的文章就讲到这里了,如果你想了解更多关于多线程并发:以AQS中acquire()方法为例来分析多线程间的同步与协作的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
我需要将文本放在 中在一个 Div 中,在另一个 Div 中,在另一个 Div 中。所以这是它的样子: #document Change PIN
奇怪的事情发生了。 我有一个基本的 html 代码。 html,头部, body 。(因为我收到了一些反对票,这里是完整的代码) 这是我的CSS: html { backgroun
我正在尝试将 Assets 中的一组图像加载到 UICollectionview 中存在的 ImageView 中,但每当我运行应用程序时它都会显示错误。而且也没有显示图像。 我在ViewDidLoa
我需要根据带参数的 perl 脚本的输出更改一些环境变量。在 tcsh 中,我可以使用别名命令来评估 perl 脚本的输出。 tcsh: alias setsdk 'eval `/localhome/
我使用 Windows 身份验证创建了一个新的 Blazor(服务器端)应用程序,并使用 IIS Express 运行它。它将显示一条消息“Hello Domain\User!”来自右上方的以下 Ra
这是我的方法 void login(Event event);我想知道 Kotlin 中应该如何 最佳答案 在 Kotlin 中通配符运算符是 * 。它指示编译器它是未知的,但一旦知道,就不会有其他类
看下面的代码 for story in book if story.title.length < 140 - var story
我正在尝试用 C 语言学习字符串处理。我写了一个程序,它存储了一些音乐轨道,并帮助用户检查他/她想到的歌曲是否存在于存储的轨道中。这是通过要求用户输入一串字符来完成的。然后程序使用 strstr()
我正在学习 sscanf 并遇到如下格式字符串: sscanf("%[^:]:%[^*=]%*[*=]%n",a,b,&c); 我理解 %[^:] 部分意味着扫描直到遇到 ':' 并将其分配给 a。:
def char_check(x,y): if (str(x) in y or x.find(y) > -1) or (str(y) in x or y.find(x) > -1):
我有一种情况,我想将文本文件中的现有行包含到一个新 block 中。 line 1 line 2 line in block line 3 line 4 应该变成 line 1 line 2 line
我有一个新项目,我正在尝试设置 Django 调试工具栏。首先,我尝试了快速设置,它只涉及将 'debug_toolbar' 添加到我的已安装应用程序列表中。有了这个,当我转到我的根 URL 时,调试
在 Matlab 中,如果我有一个函数 f,例如签名是 f(a,b,c),我可以创建一个只有一个变量 b 的函数,它将使用固定的 a=a1 和 c=c1 调用 f: g = @(b) f(a1, b,
我不明白为什么 ForEach 中的元素之间有多余的垂直间距在 VStack 里面在 ScrollView 里面使用 GeometryReader 时渲染自定义水平分隔线。 Scrol
我想知道,是否有关于何时使用 session 和 cookie 的指南或最佳实践? 什么应该和什么不应该存储在其中?谢谢! 最佳答案 这些文档很好地了解了 session cookie 的安全问题以及
我在 scipy/numpy 中有一个 Nx3 矩阵,我想用它制作一个 3 维条形图,其中 X 轴和 Y 轴由矩阵的第一列和第二列的值、高度确定每个条形的 是矩阵中的第三列,条形的数量由 N 确定。
假设我用两种不同的方式初始化信号量 sem_init(&randomsem,0,1) sem_init(&randomsem,0,0) 现在, sem_wait(&randomsem) 在这两种情况下
我怀疑该值如何存储在“WORD”中,因为 PStr 包含实际输出。? 既然Pstr中存储的是小写到大写的字母,那么在printf中如何将其给出为“WORD”。有人可以吗?解释一下? #include
我有一个 3x3 数组: var my_array = [[0,1,2], [3,4,5], [6,7,8]]; 并想获得它的第一个 2
我意识到您可以使用如下方式轻松检查焦点: var hasFocus = true; $(window).blur(function(){ hasFocus = false; }); $(win

我是一名优秀的程序员,十分优秀!